 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Alzheimer's Disease Detection from Spontaneous Speech through Combining Linguistic Complexity and (Dis)Fluency Features with Pretrained Language Models
Jun 16, 2021
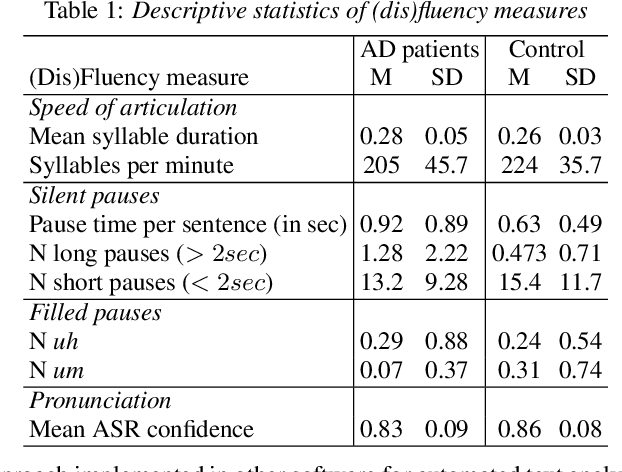
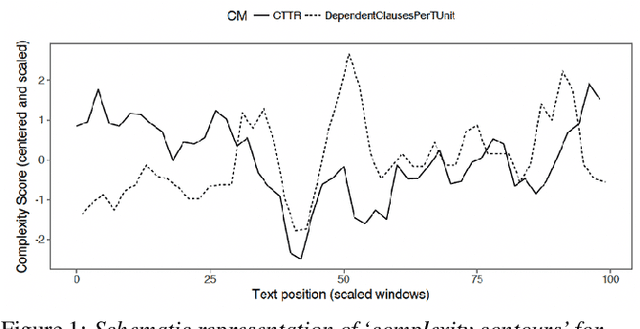
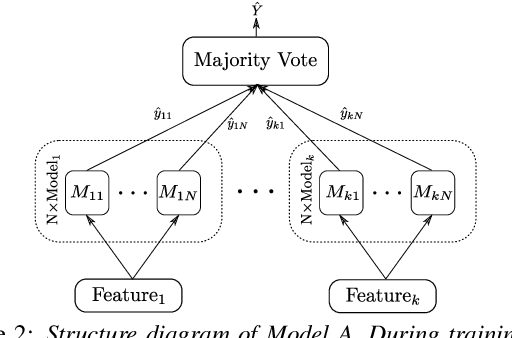
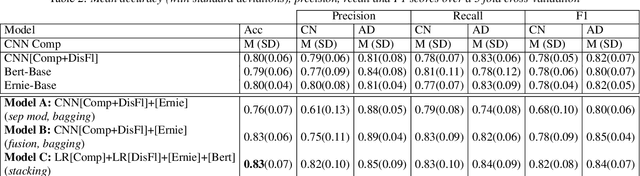
In this paper, we combined linguistic complexity and (dis)fluency features with pretrained language models for the task of Alzheimer's disease detection of the 2021 ADReSSo (Alzheimer's Dementia Recognition through Spontaneous Speech) challenge. An accuracy of 83.1% was achieved on the test set, which amounts to an improvement of 4.23% over the baseline model. Our best-performing model that integrated component models using a stacking ensemble technique performed equally well on cross-validation and test data, indicating that it is robust against overfitting.
AV Speech Enhancement Challenge using a Real Noisy Corpus
Sep 30, 2019

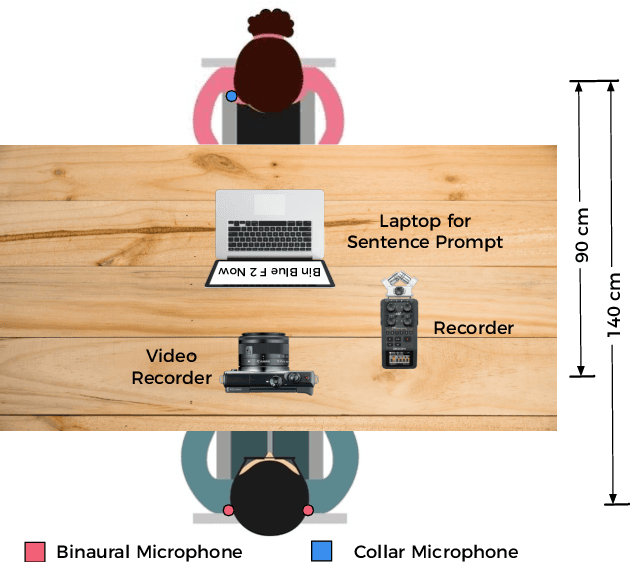
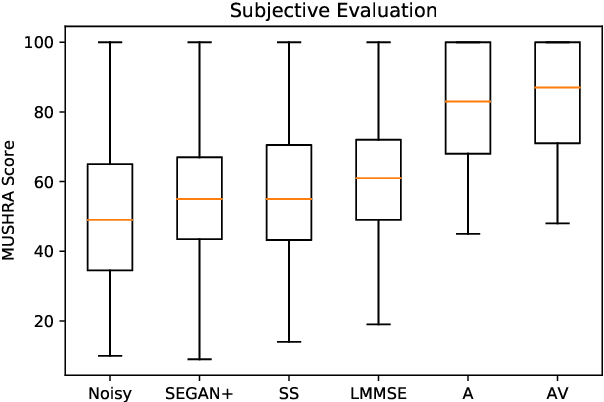
This paper presents, a first of its kind, audio-visual (AV) speech enhacement challenge in real-noisy settings. A detailed description of the AV challenge, a novel real noisy AV corpus (ASPIRE), benchmark speech enhancement task, and baseline performance results are outlined. The latter are based on training a deep neural architecture on a synthetic mixture of Grid corpus and ChiME3 noises (consisting of bus, pedestrian, cafe, and street noises) and testing on the ASPIRE corpus. Subjective evaluations of five different speech enhancement algorithms (including SEAGN, spectrum subtraction (SS) , log-minimum mean-square error (LMMSE), audio-only CochleaNet, and AV CochleaNet) are presented as baseline results. The aim of the multi-modal challenge is to provide a timely opportunity for comprehensive evaluation of novel AV speech enhancement algorithms, using our new benchmark, real-noisy AV corpus and specified performance metrics. This will promote AV speech processing research globally, stimulate new ground-breaking multi-modal approaches, and attract interest from companies, academics and researchers working in AV speech technologies and applications. We encourage participants (through a challenge website sign-up) from both the speech and hearing research communities, to benefit from their complementary approaches to AV speech in noise processing.
FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition
Oct 01, 2021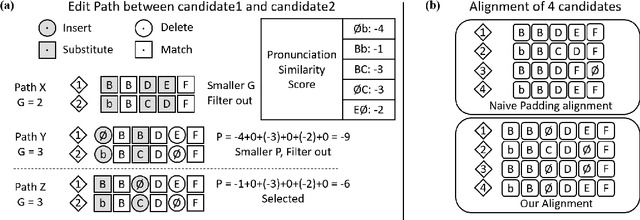
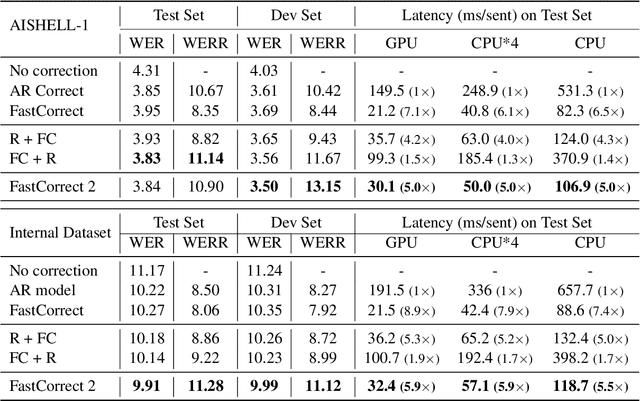
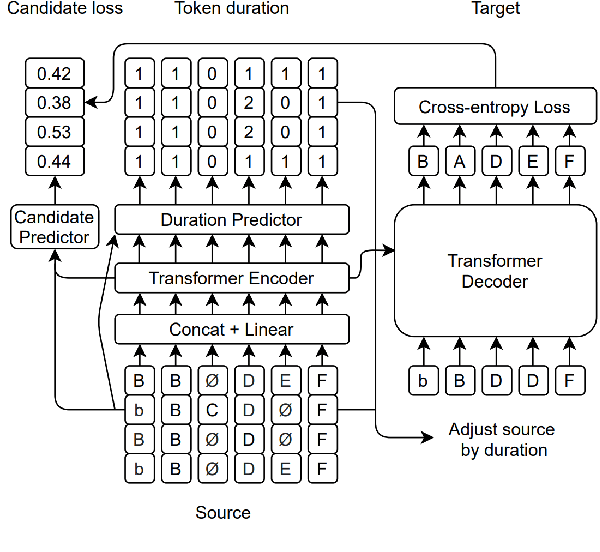
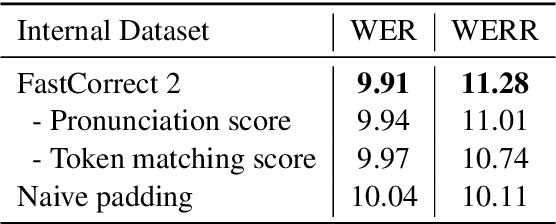
Error correction is widely used in automatic speech recognition (ASR) to post-process the generated sentence, and can further reduce the word error rate (WER). Although multiple candidates are generated by an ASR system through beam search, current error correction approaches can only correct one sentence at a time, failing to leverage the voting effect from multiple candidates to better detect and correct error tokens. In this work, we propose FastCorrect 2, an error correction model that takes multiple ASR candidates as input for better correction accuracy. FastCorrect 2 adopts non-autoregressive generation for fast inference, which consists of an encoder that processes multiple source sentences and a decoder that generates the target sentence in parallel from the adjusted source sentence, where the adjustment is based on the predicted duration of each source token. However, there are some issues when handling multiple source sentences. First, it is non-trivial to leverage the voting effect from multiple source sentences since they usually vary in length. Thus, we propose a novel alignment algorithm to maximize the degree of token alignment among multiple sentences in terms of token and pronunciation similarity. Second, the decoder can only take one adjusted source sentence as input, while there are multiple source sentences. Thus, we develop a candidate predictor to detect the most suitable candidate for the decoder. Experiments on our inhouse dataset and AISHELL-1 show that FastCorrect 2 can further reduce the WER over the previous correction model with single candidate by 3.2% and 2.6%, demonstrating the effectiveness of leveraging multiple candidates in ASR error correction. FastCorrect 2 achieves better performance than the cascaded re-scoring and correction pipeline and can serve as a unified post-processing module for ASR.
SimulMT to SimulST: Adapting Simultaneous Text Translation to End-to-End Simultaneous Speech Translation
Nov 03, 2020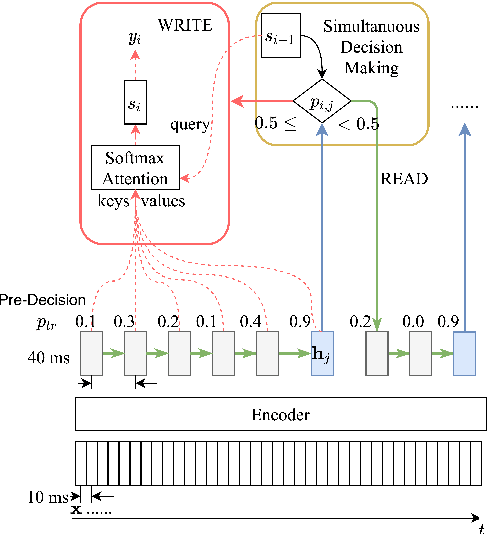
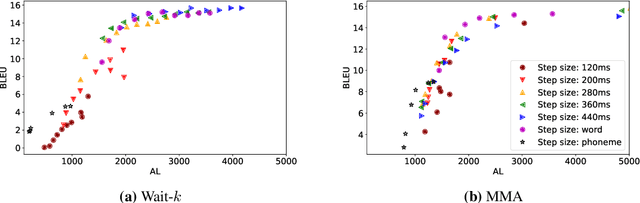
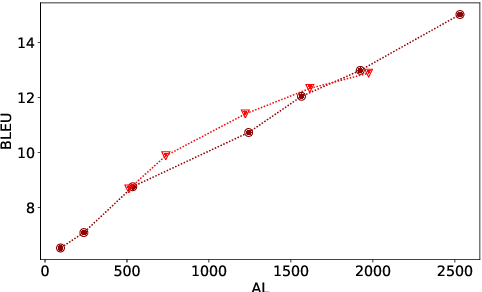
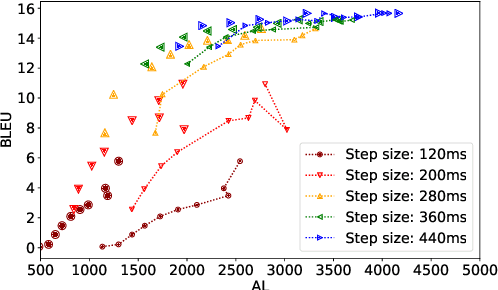
Simultaneous text translation and end-to-end speech translation have recently made great progress but little work has combined these tasks together. We investigate how to adapt simultaneous text translation methods such as wait-k and monotonic multihead attention to end-to-end simultaneous speech translation by introducing a pre-decision module. A detailed analysis is provided on the latency-quality trade-offs of combining fixed and flexible pre-decision with fixed and flexible policies. We also design a novel computation-aware latency metric, adapted from Average Lagging.
Memory-efficient Speech Recognition on Smart Devices
Feb 23, 2021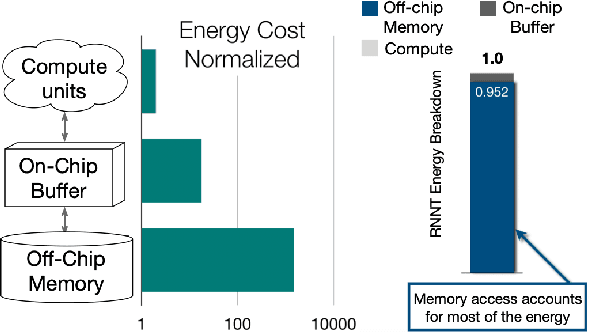
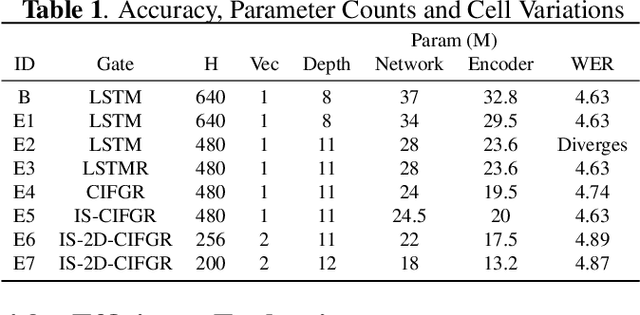
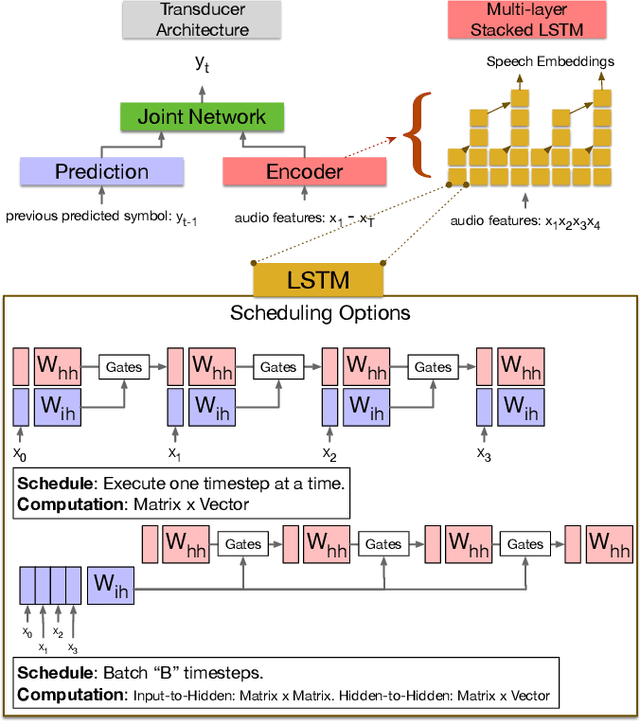
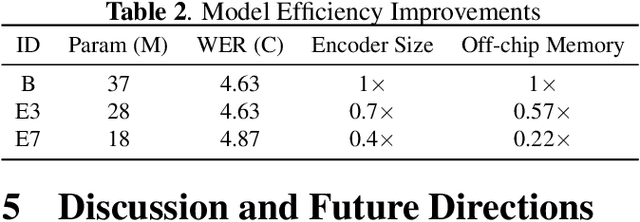
Recurrent transducer models have emerged as a promising solution for speech recognition on the current and next generation smart devices. The transducer models provide competitive accuracy within a reasonable memory footprint alleviating the memory capacity constraints in these devices. However, these models access parameters from off-chip memory for every input time step which adversely effects device battery life and limits their usability on low-power devices. We address transducer model's memory access concerns by optimizing their model architecture and designing novel recurrent cell designs. We demonstrate that i) model's energy cost is dominated by accessing model weights from off-chip memory, ii) transducer model architecture is pivotal in determining the number of accesses to off-chip memory and just model size is not a good proxy, iii) our transducer model optimizations and novel recurrent cell reduces off-chip memory accesses by 4.5x and model size by 2x with minimal accuracy impact.
Deep Residual-Dense Lattice Network for Speech Enhancement
Feb 27, 2020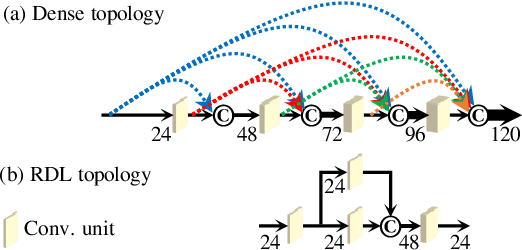
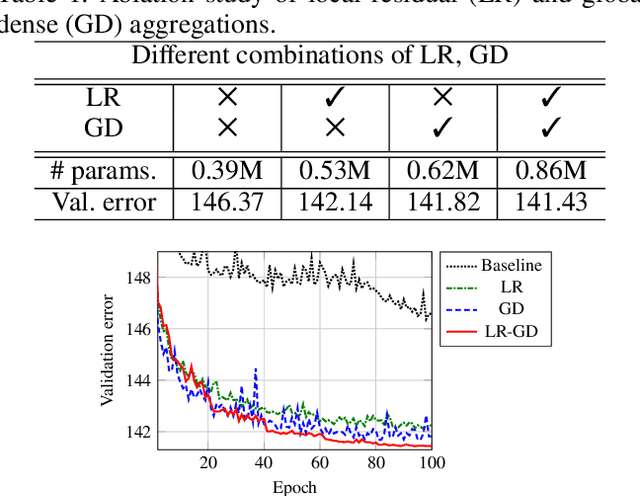
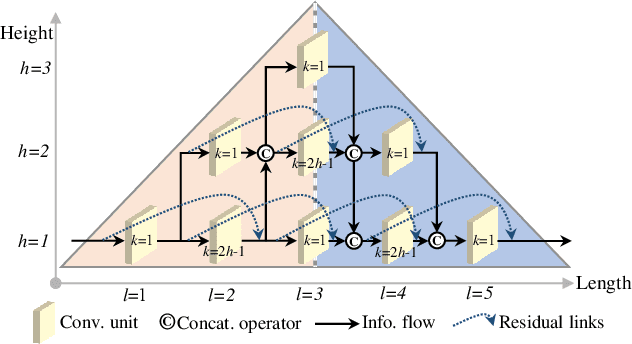
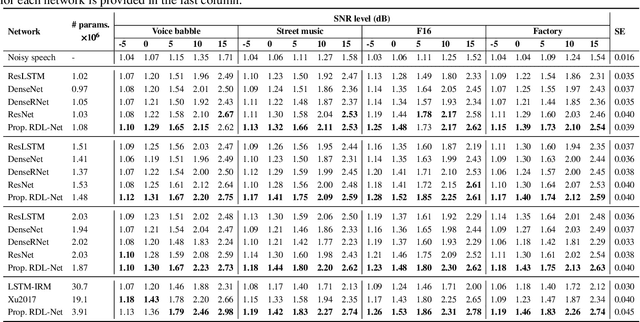
Convolutional neural networks (CNNs) with residual links (ResNets) and causal dilated convolutional units have been the network of choice for deep learning approaches to speech enhancement. While residual links improve gradient flow during training, feature diminution of shallow layer outputs can occur due to repetitive summations with deeper layer outputs. One strategy to improve feature re-usage is to fuse both ResNets and densely connected CNNs (DenseNets). DenseNets, however, over-allocate parameters for feature re-usage. Motivated by this, we propose the residual-dense lattice network (RDL-Net), which is a new CNN for speech enhancement that employs both residual and dense aggregations without over-allocating parameters for feature re-usage. This is managed through the topology of the RDL blocks, which limit the number of outputs used for dense aggregations. Our extensive experimental investigation shows that RDL-Nets are able to achieve a higher speech enhancement performance than CNNs that employ residual and/or dense aggregations. RDL-Nets also use substantially fewer parameters and have a lower computational requirement. Furthermore, we demonstrate that RDL-Nets outperform many state-of-the-art deep learning approaches to speech enhancement.
Learning to Rank Microphones for Distant Speech Recognition
Apr 13, 2021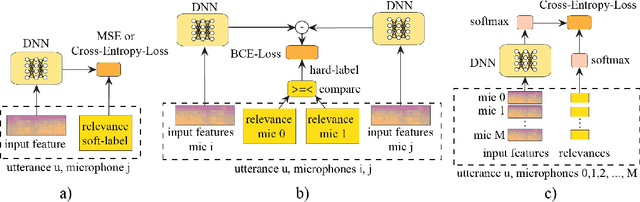
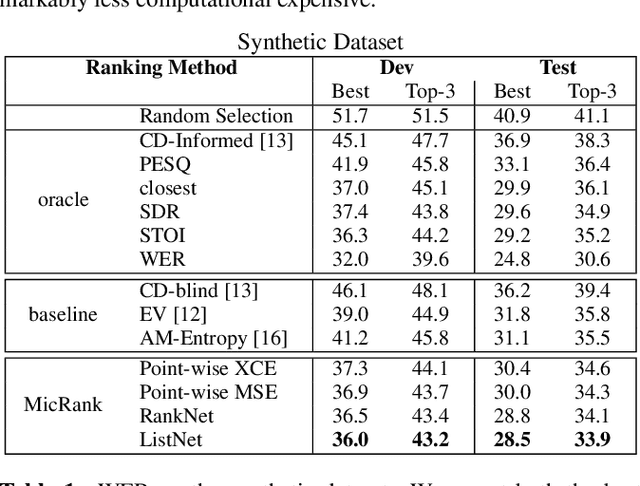
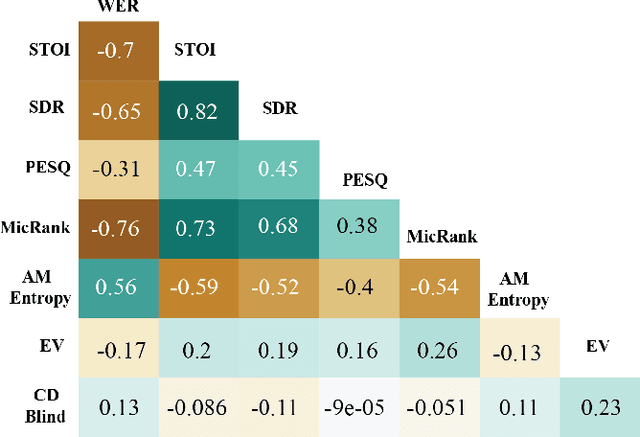
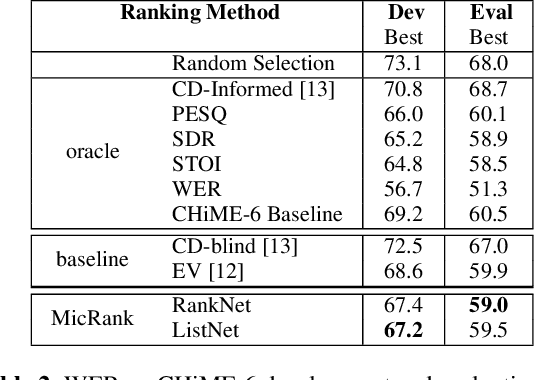
Fully exploiting ad-hoc microphone networks for distant speech recognition is still an open issue. Empirical evidence shows that being able to select the best microphone leads to significant improvements in recognition without any additional effort on front-end processing. Current channel selection techniques either rely on signal, decoder or posterior-based features. Signal-based features are inexpensive to compute but do not always correlate with recognition performance. Instead decoder and posterior-based features exhibit better correlation but require substantial computational resources. In this work, we tackle the channel selection problem by proposing MicRank, a learning to rank framework where a neural network is trained to rank the available channels using directly the recognition performance on the training set. The proposed approach is agnostic with respect to the array geometry and type of recognition back-end. We investigate different learning to rank strategies using a synthetic dataset developed on purpose and the CHiME-6 data. Results show that the proposed approach is able to considerably improve over previous selection techniques, reaching comparable and in some instances better performance than oracle signal-based measures.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jul 22, 2021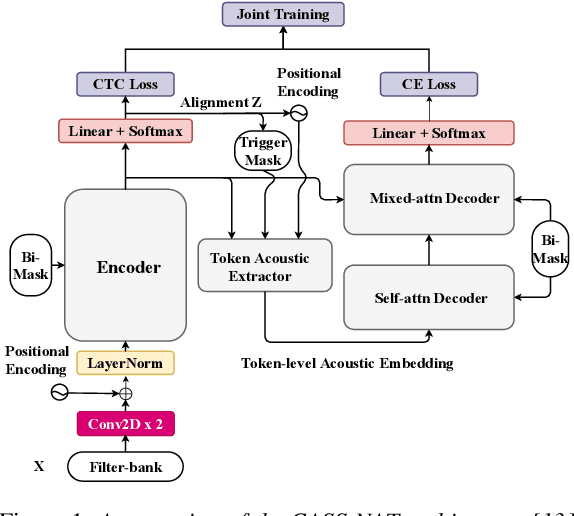
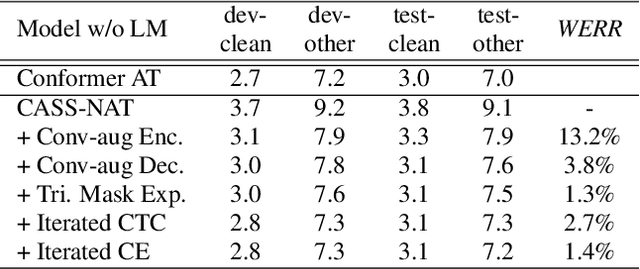
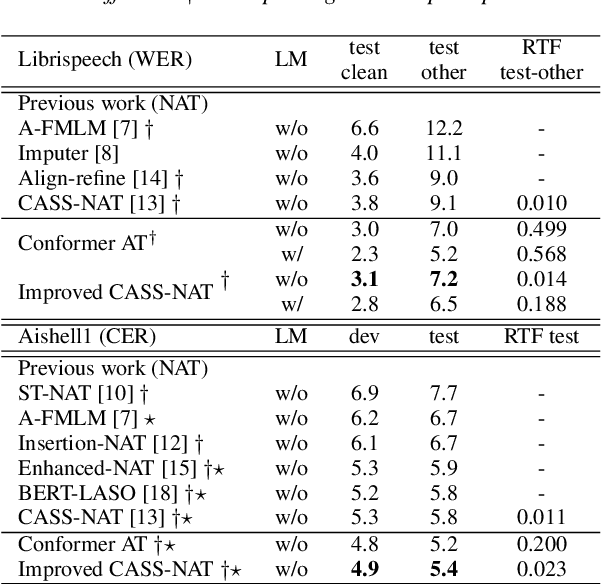
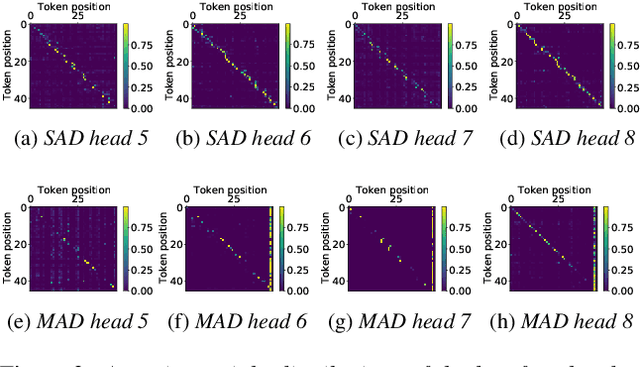
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
Towards the Objective Speech Assessment of Smoking Status based on Voice Features: A Review of the Literature
Jun 15, 2021
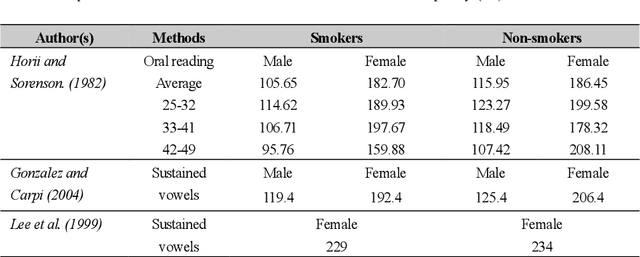
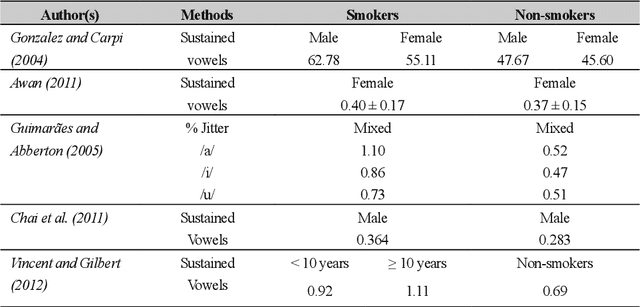
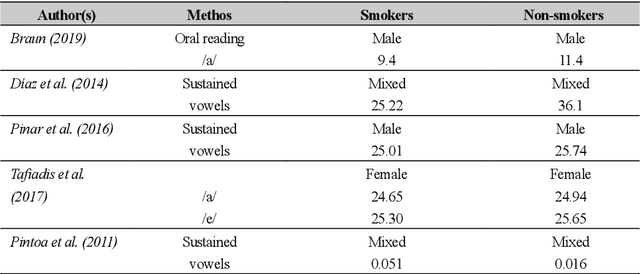
In smoking cessation clinical research and practice, objective validation of self-reported smoking status is crucial for ensuring the reliability of the primary outcome, that is, smoking abstinence. Speech signals convey important information about a speaker, such as age, gender, body size, emotional state, and health state. We investigated (1) if smoking could measurably alter voice features, (2) if smoking cessation could lead to changes in voice, and therefore (3) if the voice-based smoking status assessment has the potential to be used as an objective smoking cessation validation method.
Deficient Basis Estimation of Noise Spatial Covariance Matrix for Rank-Constrained Spatial Covariance Matrix Estimation Method in Blind Speech Extraction
May 06, 2021
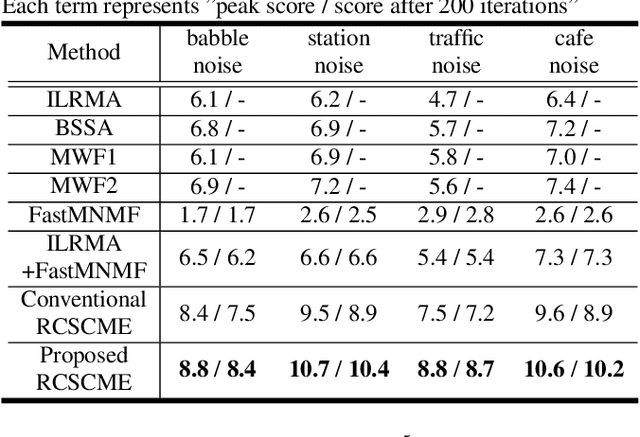
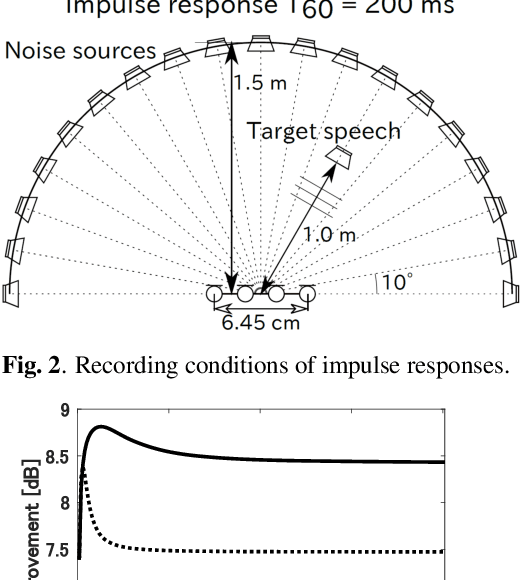
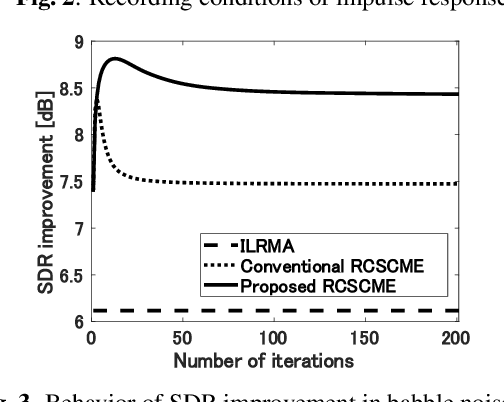
Rank-constrained spatial covariance matrix estimation (RCSCME) is a state-of-the-art blind speech extraction method applied to cases where one directional target speech and diffuse noise are mixed. In this paper, we proposed a new algorithmic extension of RCSCME. RCSCME complements a deficient one rank of the diffuse noise spatial covariance matrix, which cannot be estimated via preprocessing such as independent low-rank matrix analysis, and estimates the source model parameters simultaneously. In the conventional RCSCME, a direction of the deficient basis is fixed in advance and only the scale is estimated; however, the candidate of this deficient basis is not unique in general. In the proposed RCSCME model, the deficient basis itself can be accurately estimated as a vector variable by solving a vector optimization problem. Also, we derive new update rules based on the EM algorithm. We confirm that the proposed method outperforms conventional methods under several noise conditions.