 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Clinically Acceptable Chest X-ray Report Generation: A Qualitative Retrospective Pilot Study of CXRMate-2
Apr 21, 2026Chest X-ray (CXR) radiology report generation (RRG) models have shown rapid progress, yet their clinical utility remains uncertain due to limited evaluation by radiologists. We present CXRMate-2, a state-of-the-art CXR RRG model that integrates structured multimodal conditioning and reinforcement learning with a composite reward for semantic alignment with radiologist reports. Across the MIMIC-CXR, CheXpert Plus, and ReXgradient datasets, CXRMate-2 achieves statistically significant improvements over strong benchmarks, including gains of 11.2% and 24.4% in GREEN and RadGraph-XL, respectively, on MIMIC-CXR relative to MedGemma 1.5 (4B). To directly compare CXRMate-2 against radiologist reporting, we conduct a blinded, randomised qualitative retrospective evaluation. Three consultant radiologists compare generated and radiologist reports across 120 studies from the MIMIC-CXR test set. Generated reports were deemed acceptable (defined as preferred or rated equally to radiologist reports) in 45% of ratings, with no statistically significant difference in preference rates between radiologist reports and acceptable generated reports for seven of the eight analysed findings. Preference for radiologist reports was driven primarily by higher recall, while generated reports were often preferred for readability. Together, these results suggest a credible pathway to clinically acceptable CXR RRG. Improvements in recall, alongside better detection of subtle findings (e.g., pulmonary congestion), are likely sufficient to achieve non-inferiority to radiologist reporting. With these targeted advances, CXR RRG systems may be ready for prospective evaluation in assistive roles within radiologist-led workflows.
Anatomical grounding pre-training for medical phrase grounding
Feb 23, 2025Medical Phrase Grounding (MPG) maps radiological findings described in medical reports to specific regions in medical images. The primary obstacle hindering progress in MPG is the scarcity of annotated data available for training and validation. We propose anatomical grounding as an in-domain pre-training task that aligns anatomical terms with corresponding regions in medical images, leveraging large-scale datasets such as Chest ImaGenome. Our empirical evaluation on MS-CXR demonstrates that anatomical grounding pre-training significantly improves performance in both a zero-shot learning and fine-tuning setting, outperforming state-of-the-art MPG models. Our fine-tuned model achieved state-of-the-art performance on MS-CXR with an mIoU of 61.2, demonstrating the effectiveness of anatomical grounding pre-training for MPG.
e-Health CSIRO at RRG24: Entropy-Augmented Self-Critical Sequence Training for Radiology Report Generation
Aug 07, 2024The Shared Task on Large-Scale Radiology Report Generation (RRG24) aims to expedite the development of assistive systems for interpreting and reporting on chest X-ray (CXR) images. This task challenges participants to develop models that generate the findings and impression sections of radiology reports from CXRs from a patient's study, using five different datasets. This paper outlines the e-Health CSIRO team's approach, which achieved multiple first-place finishes in RRG24. The core novelty of our approach lies in the addition of entropy regularisation to self-critical sequence training, to maintain a higher entropy in the token distribution. This prevents overfitting to common phrases and ensures a broader exploration of the vocabulary during training, essential for handling the diversity of the radiology reports in the RRG24 datasets. Our model is available on Hugging Face https://huggingface.co/aehrc/cxrmate-rrg24.
e-Health CSIRO at "Discharge Me!" 2024: Generating Discharge Summary Sections with Fine-tuned Language Models
Jul 03, 2024Clinical documentation is an important aspect of clinicians' daily work and often demands a significant amount of time. The BioNLP 2024 Shared Task on Streamlining Discharge Documentation (Discharge Me!) aims to alleviate this documentation burden by automatically generating discharge summary sections, including brief hospital course and discharge instruction, which are often time-consuming to synthesize and write manually. We approach the generation task by fine-tuning multiple open-sourced language models (LMs), including both decoder-only and encoder-decoder LMs, with various configurations on input context. We also examine different setups for decoding algorithms, model ensembling or merging, and model specialization. Our results show that conditioning on the content of discharge summary prior to the target sections is effective for the generation task. Furthermore, we find that smaller encoder-decoder LMs can work as well or even slightly better than larger decoder based LMs fine-tuned through LoRA. The model checkpoints from our team (aehrc) are openly available.
The Impact of Auxiliary Patient Data on Automated Chest X-Ray Report Generation and How to Incorporate It
Jun 19, 2024This study investigates the integration of diverse patient data sources into multimodal language models for automated chest X-ray (CXR) report generation. Traditionally, CXR report generation relies solely on CXR images and limited radiology data, overlooking valuable information from patient health records, particularly from emergency departments. Utilising the MIMIC-CXR and MIMIC-IV-ED datasets, we incorporate detailed patient information such as aperiodic vital signs, medications, and clinical history to enhance diagnostic accuracy. We introduce a novel approach to transform these heterogeneous data sources into embeddings that prompt a multimodal language model, significantly enhancing the diagnostic accuracy of generated radiology reports. Our comprehensive evaluation demonstrates the benefits of using a broader set of patient data, underscoring the potential for enhanced diagnostic capabilities and better patient outcomes through the integration of multimodal data in CXR report generation.
Longitudinal Data and a Semantic Similarity Reward for Chest X-Ray Report Generation
Jul 19, 2023



Chest X-Ray (CXR) report generation is a promising approach to improving the efficiency of CXR interpretation. However, a significant increase in diagnostic accuracy is required before that can be realised. Motivated by this, we propose a framework that is more inline with a radiologist's workflow by considering longitudinal data. Here, the decoder is additionally conditioned on the report from the subject's previous imaging study via a prompt. We also propose a new reward for reinforcement learning based on CXR-BERT, which computes the similarity between reports. We conduct experiments on the MIMIC-CXR dataset. The results indicate that longitudinal data improves CXR report generation. CXR-BERT is also shown to be a promising alternative to the current state-of-the-art reward based on RadGraph. This investigation indicates that longitudinal CXR report generation can offer a substantial increase in diagnostic accuracy. Our Hugging Face model is available at: https://huggingface.co/aehrc/cxrmate and code is available at: https://github.com/aehrc/cxrmate.
Improving Chest X-Ray Report Generation by Leveraging Warm-Starting
Jan 24, 2022
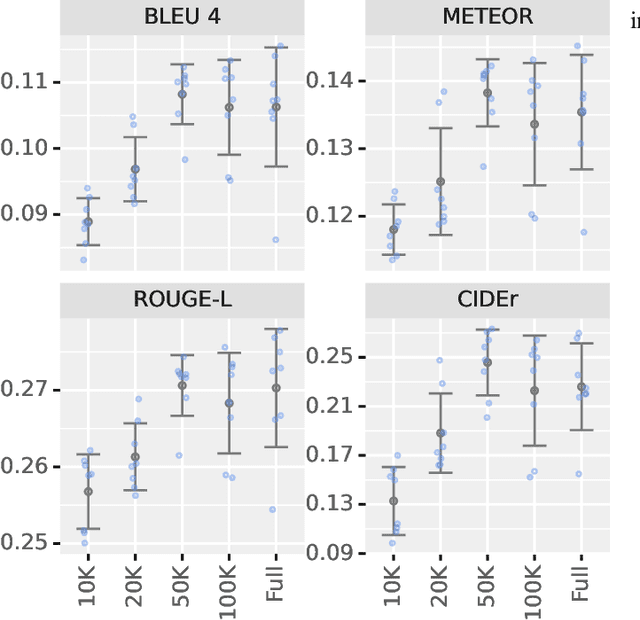
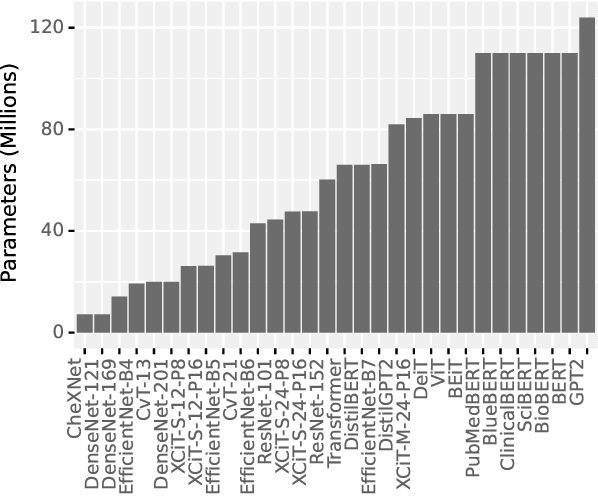
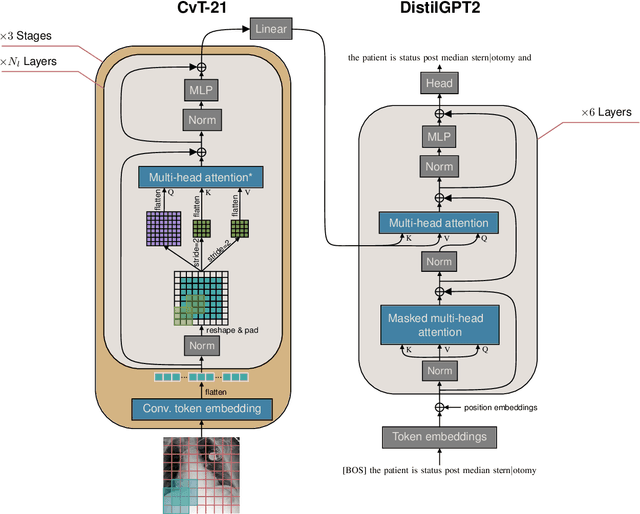
Automatically generating a report from a patient's Chest X-Rays (CXRs) is a promising solution to reducing clinical workload and improving patient care. However, current CXR report generators, which are predominantly encoder-to-decoder models, lack the diagnostic accuracy to be deployed in a clinical setting. To improve CXR report generation, we investigate warm-starting the encoder and decoder with recent open-source computer vision and natural language processing checkpoints, such as the Vision Transformer (ViT) and PubMedBERT. To this end, each checkpoint is evaluated on the MIMIC-CXR and IU X-Ray datasets using natural language generation and Clinical Efficacy (CE) metrics. Our experimental investigation demonstrates that the Convolutional vision Transformer (CvT) ImageNet-21K and the Distilled Generative Pre-trained Transformer 2 (DistilGPT2) checkpoints are best for warm-starting the encoder and decoder, respectively. Compared to the state-of-the-art (M2 Transformer Progressive), CvT2DistilGPT2 attained an improvement of 8.3% for CE F-1, 1.8% for BLEU-4, 1.6% for ROUGE-L, and 1.0% for METEOR. The reports generated by CvT2DistilGPT2 are more diagnostically accurate and have a higher similarity to radiologist reports than previous approaches. By leveraging warm-starting, CvT2DistilGPT2 brings automatic CXR report generation one step closer to the clinical setting. CvT2DistilGPT2 and its MIMIC-CXR checkpoint are available at https://github.com/aehrc/cvt2distilgpt2.
Time-Frequency Attention for Monaural Speech Enhancement
Nov 17, 2021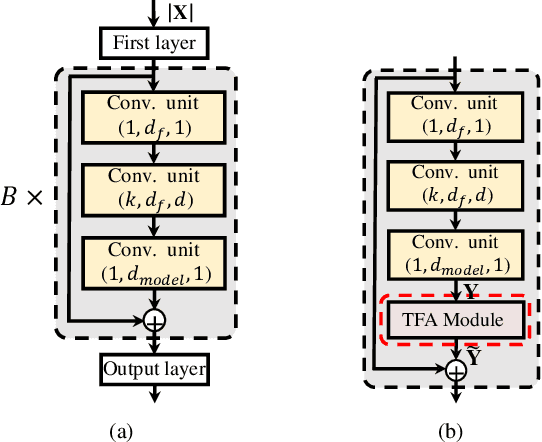
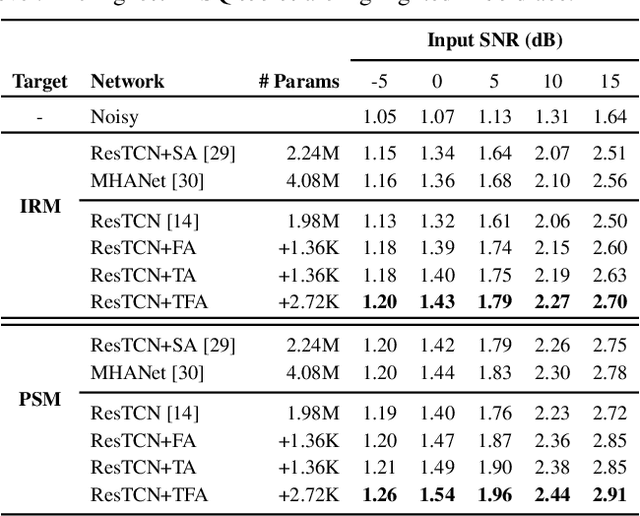
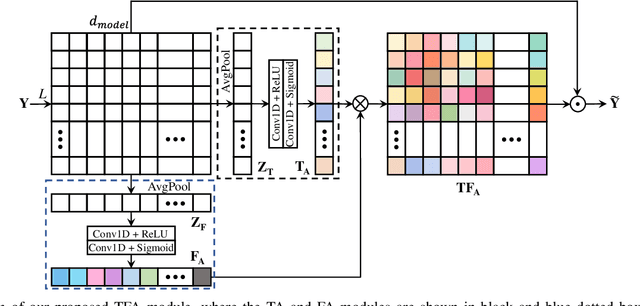
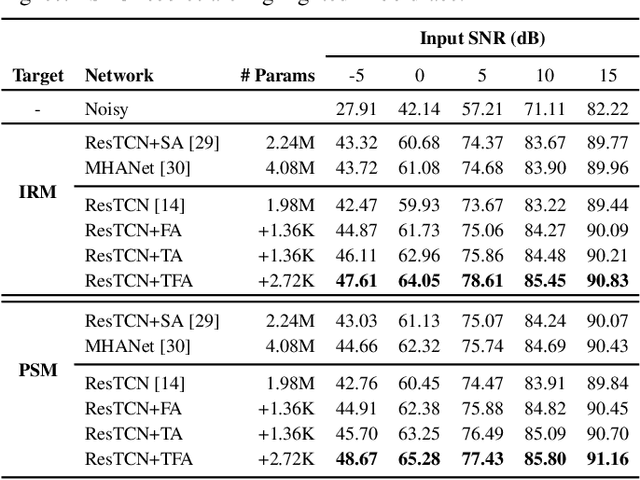
Most studies on speech enhancement generally don't consider the energy distribution of speech in time-frequency (T-F) representation, which is important for accurate prediction of mask or spectra. In this paper, we present a simple yet effective T-F attention (TFA) module, where a 2-D attention map is produced to provide differentiated weights to the spectral components of T-F representation. To validate the effectiveness of our proposed TFA module, we use the residual temporal convolution network (ResTCN) as the backbone network and conduct extensive experiments on two commonly used training targets. Our experiments demonstrate that applying our TFA module significantly improves the performance in terms of five objective evaluation metrics with negligible parameter overhead. The evaluation results show that the proposed ResTCN with the TFA module (ResTCN+TFA) consistently outperforms other baselines by a large margin.
Deep Residual-Dense Lattice Network for Speech Enhancement
Feb 27, 2020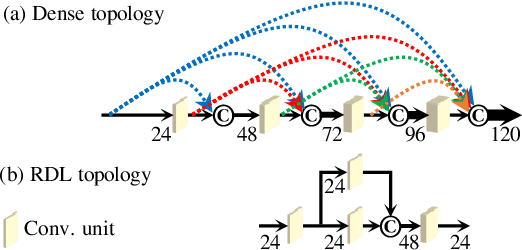
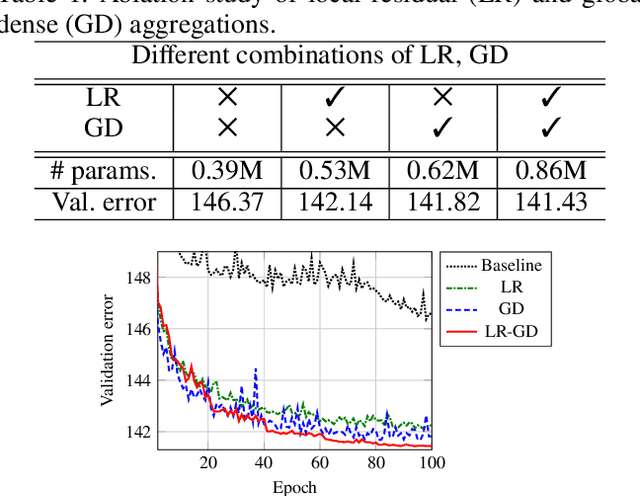
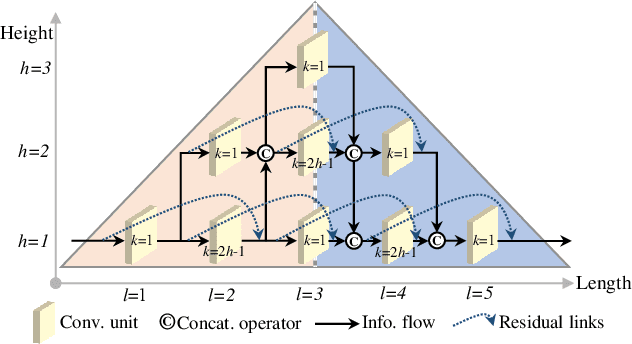
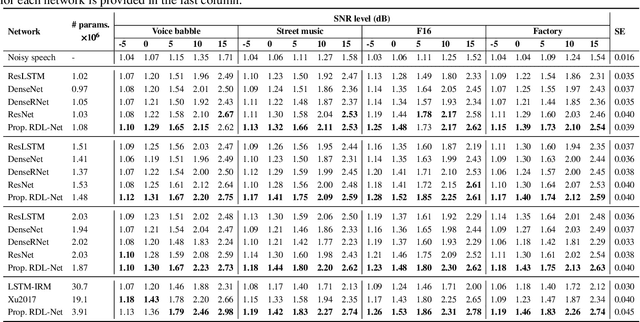
Convolutional neural networks (CNNs) with residual links (ResNets) and causal dilated convolutional units have been the network of choice for deep learning approaches to speech enhancement. While residual links improve gradient flow during training, feature diminution of shallow layer outputs can occur due to repetitive summations with deeper layer outputs. One strategy to improve feature re-usage is to fuse both ResNets and densely connected CNNs (DenseNets). DenseNets, however, over-allocate parameters for feature re-usage. Motivated by this, we propose the residual-dense lattice network (RDL-Net), which is a new CNN for speech enhancement that employs both residual and dense aggregations without over-allocating parameters for feature re-usage. This is managed through the topology of the RDL blocks, which limit the number of outputs used for dense aggregations. Our extensive experimental investigation shows that RDL-Nets are able to achieve a higher speech enhancement performance than CNNs that employ residual and/or dense aggregations. RDL-Nets also use substantially fewer parameters and have a lower computational requirement. Furthermore, we demonstrate that RDL-Nets outperform many state-of-the-art deep learning approaches to speech enhancement.