 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Unmixing with Material Prompts for Hyperspectral Object Tracking
May 20, 2026Hyperspectral imagery encodes rich material properties that can improve tracking robustness under appearance ambiguity, illumination change, and background clutter. However, due to the limited availability of hyperspectral video data, many existing methods adapt pretrained RGB trackers via spatial or channel fusion strategies, largely neglecting the intrinsic material information in hyperspectral imagery. Moreover, the few material-aware approaches typically rely on external spectral unmixing pipelines that are decoupled from the tracking objective, limiting effective optimization of material representations for target localization. To address these limitations, we formulate hyperspectral object tracking as a joint optimization problem of material decomposition and target localization, coupling the two tasks via a weighted target-oriented unmixing loss that explicitly aligns material representations with localization accuracy. Specifically, we propose a material representation decomposition module for deep learning-based spectral unmixing with adaptive frequency decomposition. Building on the decomposed material representations, we further introduce a dual-branch wavelet-enhanced material prompt module that learns low- and high-frequency material prompts through efficient spatial-material interactions in the frequency domain. The framework is model-agnostic and can be seamlessly generalized to different unmixing backbones. Extensive experiments on standard hyperspectral tracking benchmarks demonstrate state-of-the-art performance and validate the effectiveness of the proposed end-to-end material-aware tracking framework. Code is available at https://github.com/han030927/E2EMPT.
Hy-Tracker: A Novel Framework for Enhancing Efficiency and Accuracy of Object Tracking in Hyperspectral Videos
Nov 30, 2023



Hyperspectral object tracking has recently emerged as a topic of great interest in the remote sensing community. The hyperspectral image, with its many bands, provides a rich source of material information of an object that can be effectively used for object tracking. While most hyperspectral trackers are based on detection-based techniques, no one has yet attempted to employ YOLO for detecting and tracking the object. This is due to the presence of multiple spectral bands, the scarcity of annotated hyperspectral videos, and YOLO's performance limitation in managing occlusions, and distinguishing object in cluttered backgrounds. Therefore, in this paper, we propose a novel framework called Hy-Tracker, which aims to bridge the gap between hyperspectral data and state-of-the-art object detection methods to leverage the strengths of YOLOv7 for object tracking in hyperspectral videos. Hy-Tracker not only introduces YOLOv7 but also innovatively incorporates a refined tracking module on top of YOLOv7. The tracker refines the initial detections produced by YOLOv7, leading to improved object-tracking performance. Furthermore, we incorporate Kalman-Filter into the tracker, which addresses the challenges posed by scale variation and occlusion. The experimental results on hyperspectral benchmark datasets demonstrate the effectiveness of Hy-Tracker in accurately tracking objects across frames.
Deep Residual-Dense Lattice Network for Speech Enhancement
Feb 27, 2020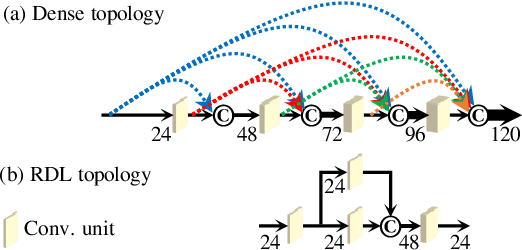
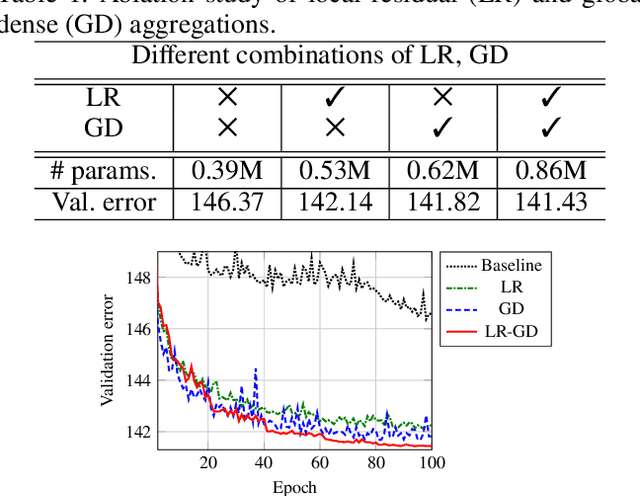
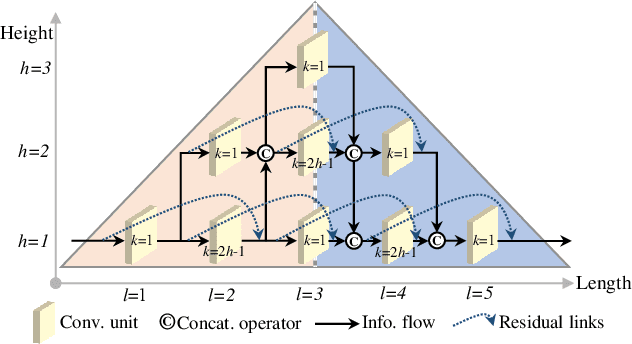
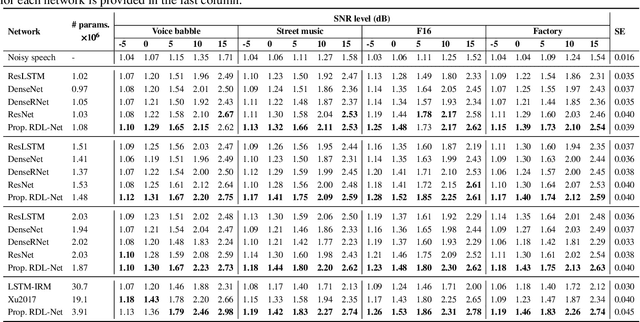
Convolutional neural networks (CNNs) with residual links (ResNets) and causal dilated convolutional units have been the network of choice for deep learning approaches to speech enhancement. While residual links improve gradient flow during training, feature diminution of shallow layer outputs can occur due to repetitive summations with deeper layer outputs. One strategy to improve feature re-usage is to fuse both ResNets and densely connected CNNs (DenseNets). DenseNets, however, over-allocate parameters for feature re-usage. Motivated by this, we propose the residual-dense lattice network (RDL-Net), which is a new CNN for speech enhancement that employs both residual and dense aggregations without over-allocating parameters for feature re-usage. This is managed through the topology of the RDL blocks, which limit the number of outputs used for dense aggregations. Our extensive experimental investigation shows that RDL-Nets are able to achieve a higher speech enhancement performance than CNNs that employ residual and/or dense aggregations. RDL-Nets also use substantially fewer parameters and have a lower computational requirement. Furthermore, we demonstrate that RDL-Nets outperform many state-of-the-art deep learning approaches to speech enhancement.