 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Automatic Speech Recognition Datasets in Cantonese Language: A Survey and a New Dataset
Jan 07, 2022
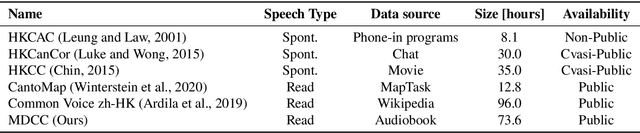
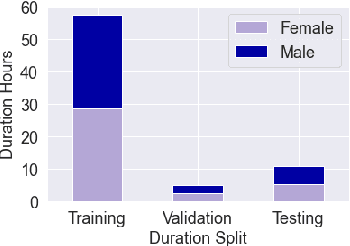
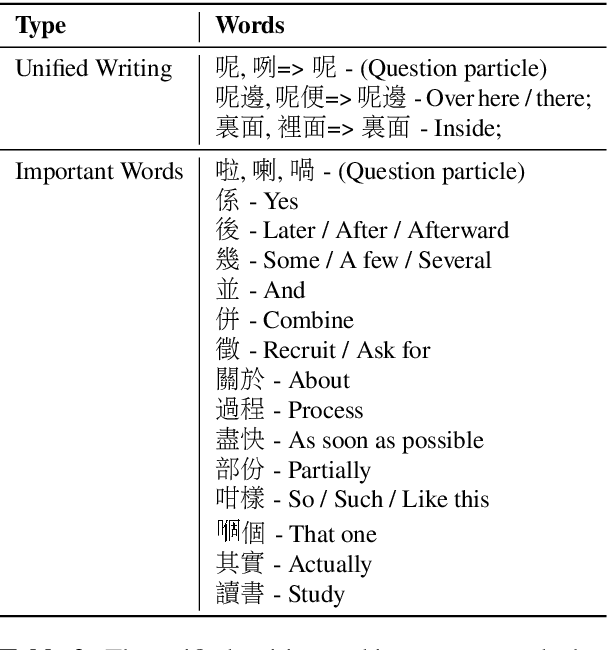
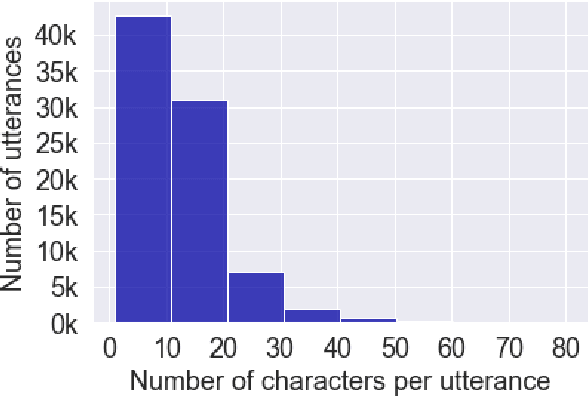
Automatic speech recognition (ASR) on low resource languages improves access of linguistic minorities to technological advantages provided by Artificial Intelligence (AI). In this paper, we address a problem of data scarcity of Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It combines philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and perform experiments on the two biggest datasets (MDCC and Common Voice zh-HK). We analyze the existing datasets according to their speech type, data source, total size and availability. The results of experiments conducted with Fairseq S2T Transformer, a state-of-the-art ASR model, show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
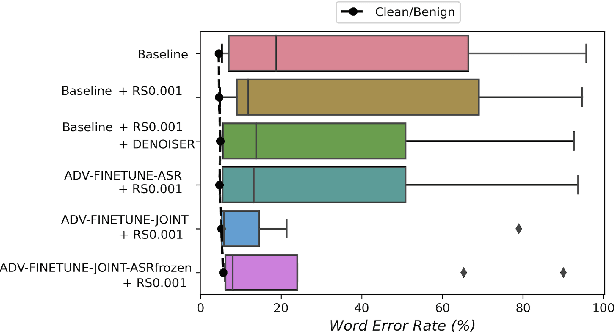

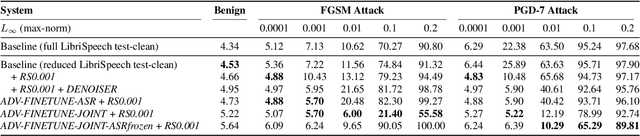
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
Effects of Number of Filters of Convolutional Layers on Speech Recognition Model Accuracy
Feb 03, 2021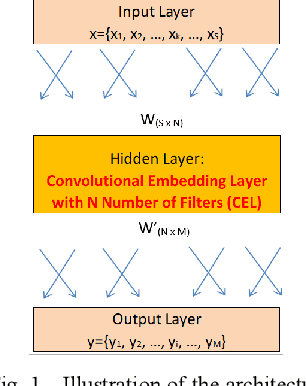
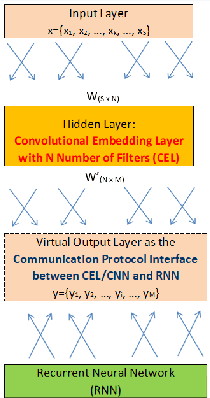
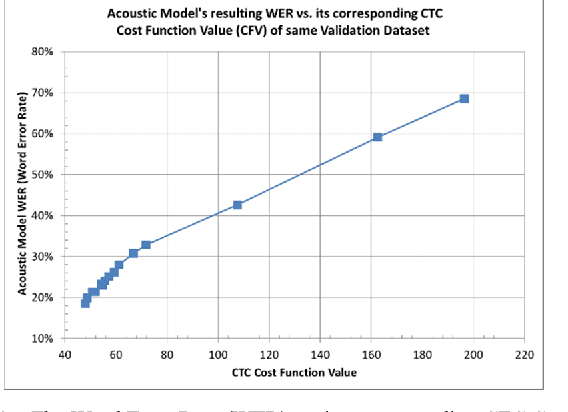
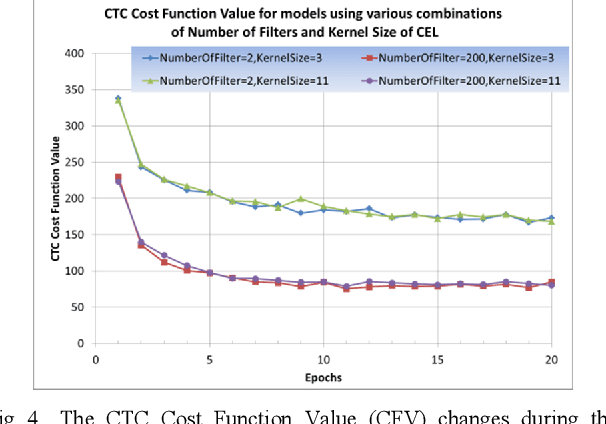
Inspired by the progress of the End-to-End approach [1], this paper systematically studies the effects of Number of Filters of convolutional layers on the model prediction accuracy of CNN+RNN (Convolutional Neural Networks adding to Recurrent Neural Networks) for ASR Models (Automatic Speech Recognition). Experimental results show that only when the CNN Number of Filters exceeds a certain threshold value is adding CNN to RNN able to improve the performance of the CNN+RNN speech recognition model, otherwise some parameter ranges of CNN can render it useless to add the CNN to the RNN model. Our results show a strong dependency of word accuracy on the Number of Filters of convolutional layers. Based on the experimental results, the paper suggests a possible hypothesis of Sound-2-Vector Embedding (Convolutional Embedding) to explain the above observations. Based on this Embedding hypothesis and the optimization of parameters, the paper develops an End-to-End speech recognition system which has a high word accuracy but also has a light model-weight. The developed LVCSR (Large Vocabulary Continuous Speech Recognition) model has achieved quite a high word accuracy of 90.2% only by its Acoustic Model alone, without any assistance from intermediate phonetic representation and any Language Model. Its acoustic model contains only 4.4 million weight parameters, compared to the 35~68 million acoustic-model weight parameters in DeepSpeech2 [2] (one of the top state-of-the-art LVCSR models) which can achieve a word accuracy of 91.5%. The light-weighted model is good for improving the transcribing computing efficiency and also useful for mobile devices, Driverless Vehicles, etc. Our model weight is reduced to ~10% the size of DeepSpeech2, but our model accuracy remains close to that of DeepSpeech2. If combined with a Language Model, our LVCSR system is able to achieve 91.5% word accuracy.
Transformer-based end-to-end speech recognition with residual Gaussian-based self-attention
Apr 02, 2021Self-attention (SA), which encodes vector sequences according to their pairwise similarity, is widely used in speech recognition due to its strong context modeling ability. However, when applied to long sequence data, its accuracy is reduced. This is caused by the fact that its weighted average operator may lead to the dispersion of the attention distribution, which results in the relationship between adjacent signals ignored. To address this issue, in this paper, we introduce relative-position-awareness self-attention (RPSA). It not only maintains the global-range dependency modeling ability of self-attention, but also improves the localness modeling ability. Because the local window length of the original RPSA is fixed and sensitive to different test data, here we propose Gaussian-based self-attention (GSA) whose window length is learnable and adaptive to the test data automatically. We further generalize GSA to a new residual Gaussian self-attention (resGSA) for the performance improvement. We apply RPSA, GSA, and resGSA to Transformer-based speech recognition respectively. Experimental results on the AISHELL-1 Mandarin speech recognition corpus demonstrate the effectiveness of the proposed methods. For example, the resGSA-Transformer achieves a character error rate (CER) of 5.86% on the test set, which is relative 7.8% lower than that of the SA-Transformer. Although the performance of the proposed resGSA-Transformer is only slightly better than that of the RPSA-Transformer, it does not have to tune the window length manually.
SRU++: Pioneering Fast Recurrence with Attention for Speech Recognition
Oct 11, 2021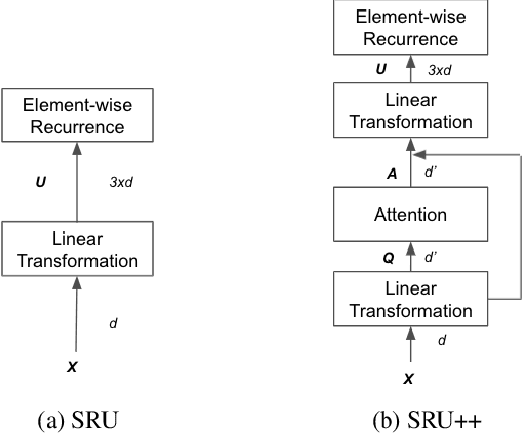



The Transformer architecture has been well adopted as a dominant architecture in most sequence transduction tasks including automatic speech recognition (ASR), since its attention mechanism excels in capturing long-range dependencies. While models built solely upon attention can be better parallelized than regular RNN, a novel network architecture, SRU++, was recently proposed. By combining the fast recurrence and attention mechanism, SRU++ exhibits strong capability in sequence modeling and achieves near-state-of-the-art results in various language modeling and machine translation tasks with improved compute efficiency. In this work, we present the advantages of applying SRU++ in ASR tasks by comparing with Conformer across multiple ASR benchmarks and study how the benefits can be generalized to long-form speech inputs. On the popular LibriSpeech benchmark, our SRU++ model achieves 2.0% / 4.7% WER on test-clean / test-other, showing competitive performances compared with the state-of-the-art Conformer encoder under the same set-up. Specifically, SRU++ can surpass Conformer on long-form speech input with a large margin, based on our analysis.
Relaxed Attention: A Simple Method to Boost Performance of End-to-End Automatic Speech Recognition
Jul 02, 2021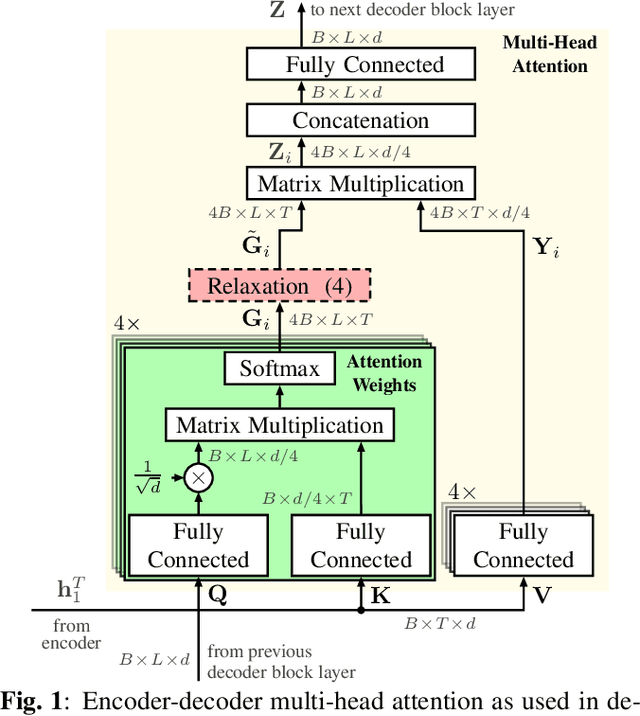
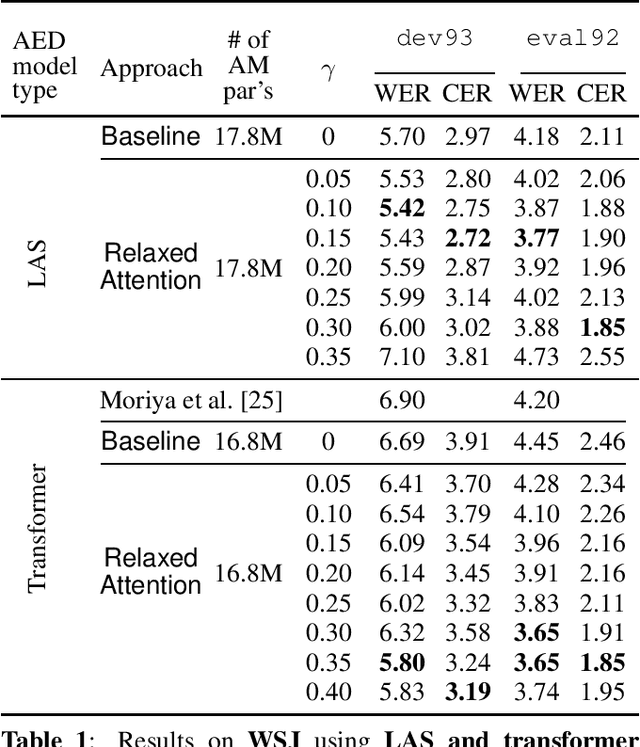
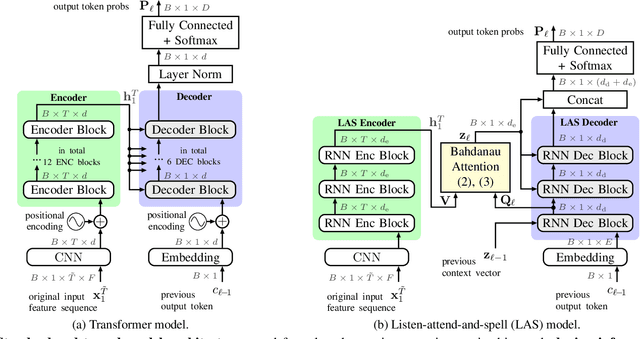
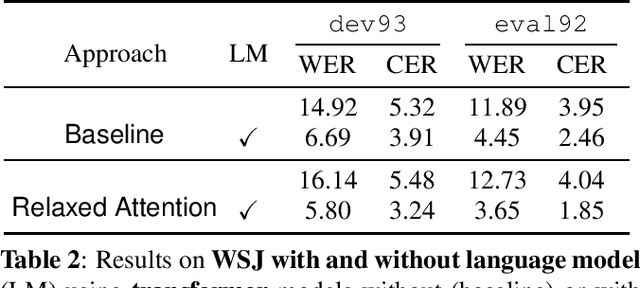
Recently, attention-based encoder-decoder (AED) models have shown high performance for end-to-end automatic speech recognition (ASR) across several tasks. Addressing overconfidence in such models, in this paper we introduce the concept of relaxed attention, which is a simple gradual injection of a uniform distribution to the encoder-decoder attention weights during training that is easily implemented with two lines of code. We investigate the effect of relaxed attention across different AED model architectures and two prominent ASR tasks, Wall Street Journal (WSJ) and Librispeech. We found that transformers trained with relaxed attention outperform the standard baseline models consistently during decoding with external language models. On WSJ, we set a new benchmark for transformer-based end-to-end speech recognition with a word error rate of 3.65%, outperforming state of the art (4.20%) by 13.1% relative, while introducing only a single hyperparameter. Upon acceptance, models will be published on github.
Simple and Effective Unsupervised Speech Translation
Oct 18, 2022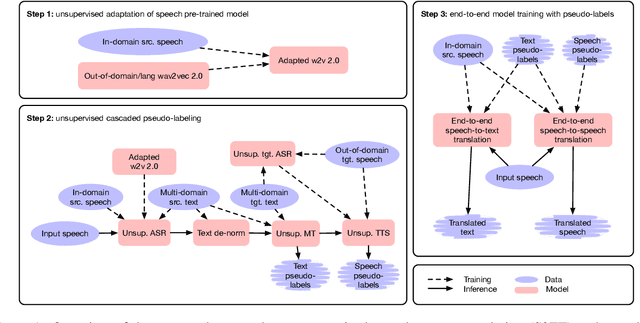
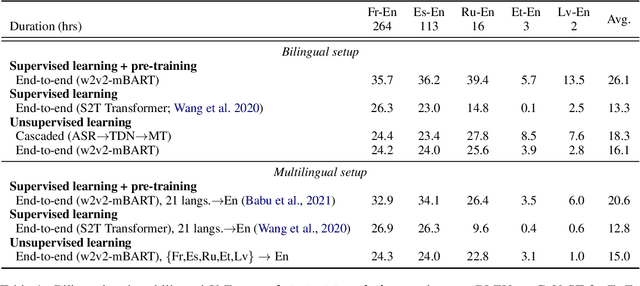
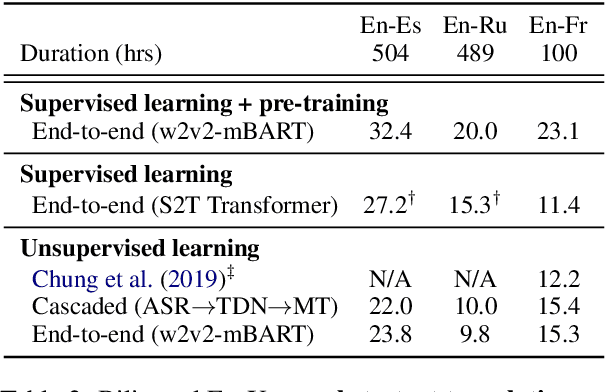
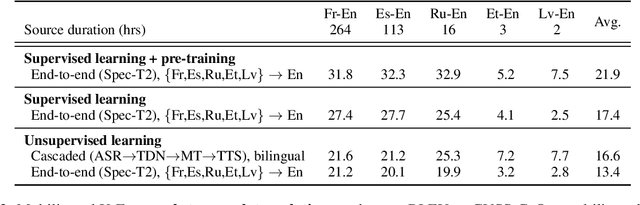
The amount of labeled data to train models for speech tasks is limited for most languages, however, the data scarcity is exacerbated for speech translation which requires labeled data covering two different languages. To address this issue, we study a simple and effective approach to build speech translation systems without labeled data by leveraging recent advances in unsupervised speech recognition, machine translation and speech synthesis, either in a pipeline approach, or to generate pseudo-labels for training end-to-end speech translation models. Furthermore, we present an unsupervised domain adaptation technique for pre-trained speech models which improves the performance of downstream unsupervised speech recognition, especially for low-resource settings. Experiments show that unsupervised speech-to-text translation outperforms the previous unsupervised state of the art by 3.2 BLEU on the Libri-Trans benchmark, on CoVoST 2, our best systems outperform the best supervised end-to-end models (without pre-training) from only two years ago by an average of 5.0 BLEU over five X-En directions. We also report competitive results on MuST-C and CVSS benchmarks.
Towards Contextual Spelling Correction for Customization of End-to-end Speech Recognition Systems
Mar 02, 2022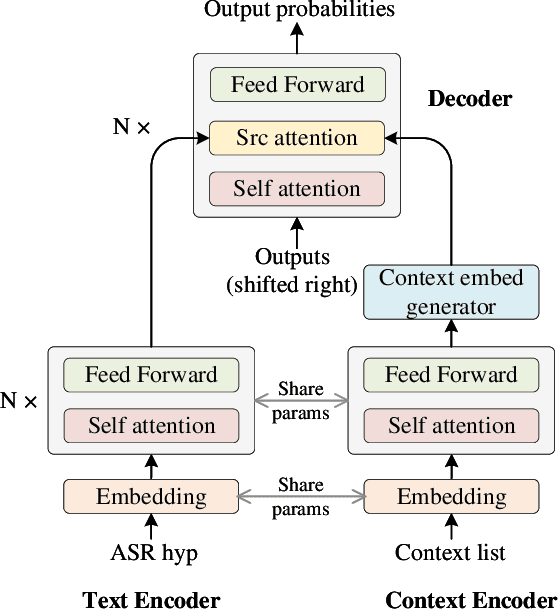
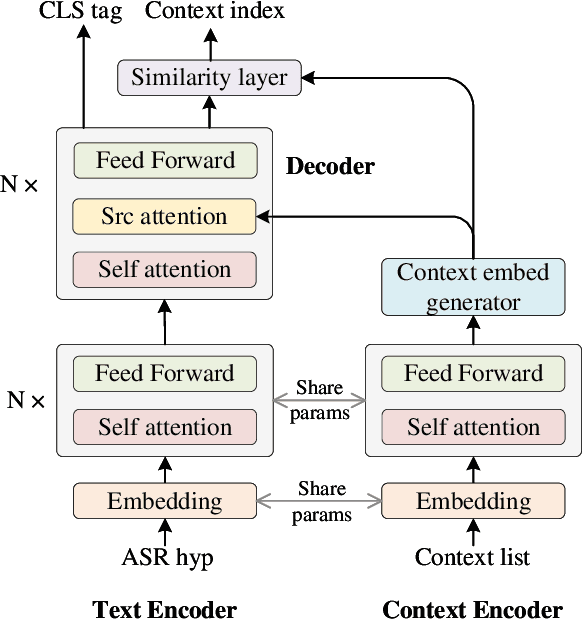
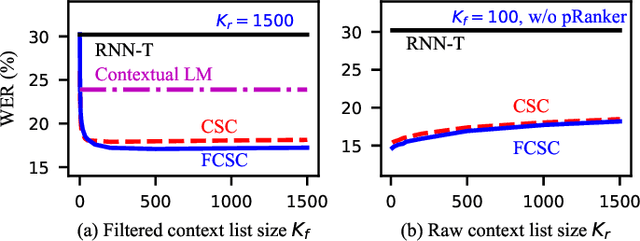
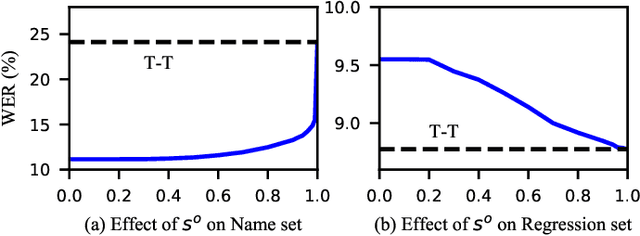
Contextual biasing is an important and challenging task for end-to-end automatic speech recognition (ASR) systems, which aims to achieve better recognition performance by biasing the ASR system to particular context phrases such as person names, music list, proper nouns, etc. Existing methods mainly include contextual LM biasing and adding bias encoder into end-to-end ASR models. In this work, we introduce a novel approach to do contextual biasing by adding a contextual spelling correction model on top of the end-to-end ASR system. We incorporate contextual information into a sequence-to-sequence spelling correction model with a shared context encoder. Our proposed model includes two different mechanisms: autoregressive (AR) and non-autoregressive (NAR). We propose filtering algorithms to handle large-size context lists, and performance balancing mechanisms to control the biasing degree of the model. We demonstrate the proposed model is a general biasing solution which is domain-insensitive and can be adopted in different scenarios. Experiments show that the proposed method achieves as much as 51% relative word error rate (WER) reduction over ASR system and outperforms traditional biasing methods. Compared to the AR solution, the proposed NAR model reduces model size by 43.2% and speeds up inference by 2.1 times.
Arabic Code-Switching Speech Recognition using Monolingual Data
Jul 04, 2021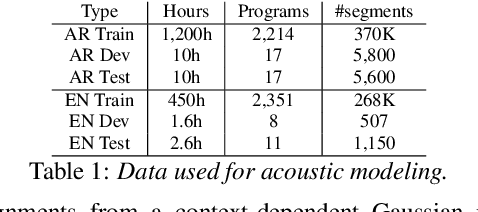
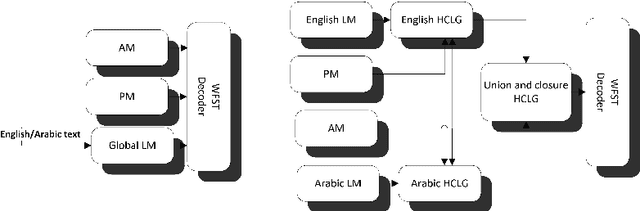
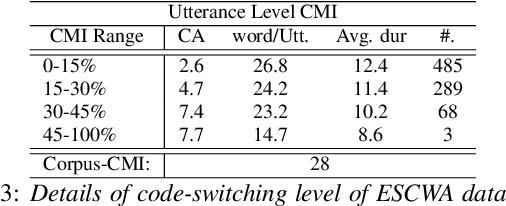
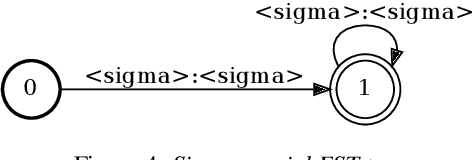
Code-switching in automatic speech recognition (ASR) is an important challenge due to globalization. Recent research in multilingual ASR shows potential improvement over monolingual systems. We study key issues related to multilingual modeling for ASR through a series of large-scale ASR experiments. Our innovative framework deploys a multi-graph approach in the weighted finite state transducers (WFST) framework. We compare our WFST decoding strategies with a transformer sequence to sequence system trained on the same data. Given a code-switching scenario between Arabic and English languages, our results show that the WFST decoding approaches were more suitable for the intersentential code-switching datasets. In addition, the transformer system performed better for intrasentential code-switching task. With this study, we release an artificially generated development and test sets, along with ecological code-switching test set, to benchmark the ASR performance.