 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiT-Flow: Speech Enhancement Robust to Multiple Distortions based on Flow Matching in Latent Space and Diffusion Transformers
Mar 23, 2026Recent advances in generative models, such as diffusion and flow matching, have shown strong performance in audio tasks. However, speech enhancement (SE) models are typically trained on limited datasets and evaluated under narrow conditions, limiting real-world applicability. To address this, we propose DiT-Flow, a flow matching-based SE framework built on the latent Diffusion Transformer (DiT) backbone and trained for robustness across diverse distortions, including noise, reverberation, and compression. DiT-Flow operates on compact variational auto-encoders (VAEs)-derived latent features. We validated our approach on StillSonicSet, a synthetic yet acoustically realistic dataset composed of LibriSpeech, FSD50K, FMA, and 90 Matterport3D scenes. Experiments show that DiT-Flow consistently outperforms state-of-the-art generative SE models, demonstrating the effectiveness of flow matching in multi-condition speech enhancement. Despite ongoing efforts to expand synthetic data realism, a persistent bottleneck in SE is the inevitable mismatch between training and deployment conditions. By integrating LoRA with the MoE framework, we achieve both parameter-efficient and high-performance training for DiT-Flow robust to multiple distortions with using 4.9% percentage of the total parameters to obtain a better performance on five unseen distortions.
Spoken DialogSum: An Emotion-Rich Conversational Dataset for Spoken Dialogue Summarization
Dec 17, 2025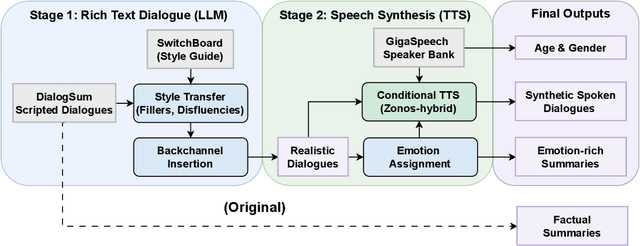

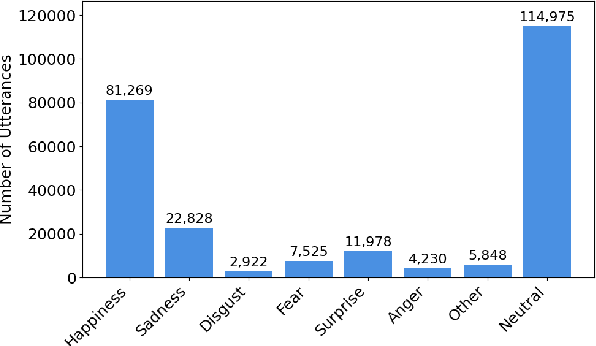
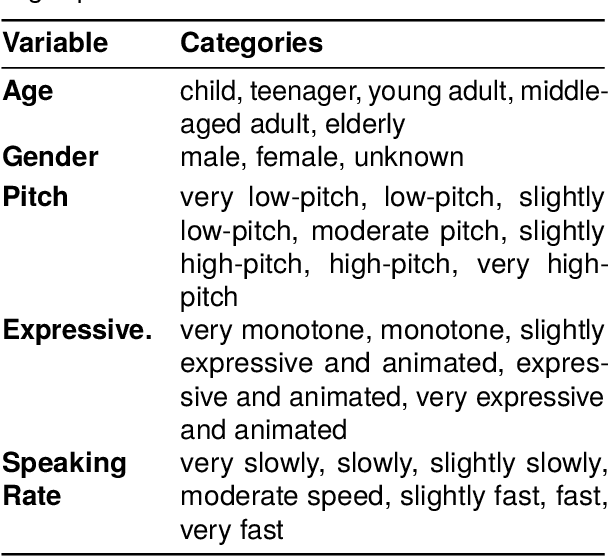
Recent audio language models can follow long conversations. However, research on emotion-aware or spoken dialogue summarization is constrained by the lack of data that links speech, summaries, and paralinguistic cues. We introduce Spoken DialogSum, the first corpus aligning raw conversational audio with factual summaries, emotion-rich summaries, and utterance-level labels for speaker age, gender, and emotion. The dataset is built in two stages: first, an LLM rewrites DialogSum scripts with Switchboard-style fillers and back-channels, then tags each utterance with emotion, pitch, and speaking rate. Second, an expressive TTS engine synthesizes speech from the tagged scripts, aligned with paralinguistic labels. Spoken DialogSum comprises 13,460 emotion-diverse dialogues, each paired with both a factual and an emotion-focused summary. We release an online demo at https://fatfat-emosum.github.io/EmoDialog-Sum-Audio-Samples/, with plans to release the full dataset in the near future. Baselines show that an Audio-LLM raises emotional-summary ROUGE-L by 28% relative to a cascaded ASR-LLM system, confirming the value of end-to-end speech modeling.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
Detecting Neurodegenerative Diseases using Frame-Level Handwriting Embeddings
Feb 10, 2025In this study, we explored the use of spectrograms to represent handwriting signals for assessing neurodegenerative diseases, including 42 healthy controls (CTL), 35 subjects with Parkinson's Disease (PD), 21 with Alzheimer's Disease (AD), and 15 with Parkinson's Disease Mimics (PDM). We applied CNN and CNN-BLSTM models for binary classification using both multi-channel fixed-size and frame-based spectrograms. Our results showed that handwriting tasks and spectrogram channel combinations significantly impacted classification performance. The highest F1-score (89.8%) was achieved for AD vs. CTL, while PD vs. CTL reached 74.5%, and PD vs. PDM scored 77.97%. CNN consistently outperformed CNN-BLSTM. Different sliding window lengths were tested for constructing frame-based spectrograms. A 1-second window worked best for AD, longer windows improved PD classification, and window length had little effect on PD vs. PDM.
CA-SSLR: Condition-Aware Self-Supervised Learning Representation for Generalized Speech Processing
Dec 05, 2024We introduce Condition-Aware Self-Supervised Learning Representation (CA-SSLR), a generalist conditioning model broadly applicable to various speech-processing tasks. Compared to standard fine-tuning methods that optimize for downstream models, CA-SSLR integrates language and speaker embeddings from earlier layers, making the SSL model aware of the current language and speaker context. This approach reduces the reliance on input audio features while preserving the integrity of the base SSLR. CA-SSLR improves the model's capabilities and demonstrates its generality on unseen tasks with minimal task-specific tuning. Our method employs linear modulation to dynamically adjust internal representations, enabling fine-grained adaptability without significantly altering the original model behavior. Experiments show that CA-SSLR reduces the number of trainable parameters, mitigates overfitting, and excels in under-resourced and unseen tasks. Specifically, CA-SSLR achieves a 10% relative reduction in LID errors, a 37% improvement in ASR CER on the ML-SUPERB benchmark, and a 27% decrease in SV EER on VoxCeleb-1, demonstrating its effectiveness.
Clean Label Attacks against SLU Systems
Sep 13, 2024



Poisoning backdoor attacks involve an adversary manipulating the training data to induce certain behaviors in the victim model by inserting a trigger in the signal at inference time. We adapted clean label backdoor (CLBD)-data poisoning attacks, which do not modify the training labels, on state-of-the-art speech recognition models that support/perform a Spoken Language Understanding task, achieving 99.8% attack success rate by poisoning 10% of the training data. We analyzed how varying the signal-strength of the poison, percent of samples poisoned, and choice of trigger impact the attack. We also found that CLBD attacks are most successful when applied to training samples that are inherently hard for a proxy model. Using this strategy, we achieved an attack success rate of 99.3% by poisoning a meager 1.5% of the training data. Finally, we applied two previously developed defenses against gradient-based attacks, and found that they attain mixed success against poisoning.
Noise-robust Speech Separation with Fast Generative Correction
Jun 11, 2024Speech separation, the task of isolating multiple speech sources from a mixed audio signal, remains challenging in noisy environments. In this paper, we propose a generative correction method to enhance the output of a discriminative separator. By leveraging a generative corrector based on a diffusion model, we refine the separation process for single-channel mixture speech by removing noises and perceptually unnatural distortions. Furthermore, we optimize the generative model using a predictive loss to streamline the diffusion model's reverse process into a single step and rectify any associated errors by the reverse process. Our method achieves state-of-the-art performance on the in-domain Libri2Mix noisy dataset, and out-of-domain WSJ with a variety of noises, improving SI-SNR by 22-35% relative to SepFormer, demonstrating robustness and strong generalization capabilities.
DuTa-VC: A Duration-aware Typical-to-atypical Voice Conversion Approach with Diffusion Probabilistic Model
Jun 18, 2023



We present a novel typical-to-atypical voice conversion approach (DuTa-VC), which (i) can be trained with nonparallel data (ii) first introduces diffusion probabilistic model (iii) preserves the target speaker identity (iv) is aware of the phoneme duration of the target speaker. DuTa-VC consists of three parts: an encoder transforms the source mel-spectrogram into a duration-modified speaker-independent mel-spectrogram, a decoder performs the reverse diffusion to generate the target mel-spectrogram, and a vocoder is applied to reconstruct the waveform. Objective evaluations conducted on the UASpeech show that DuTa-VC is able to capture severity characteristics of dysarthric speech, reserves speaker identity, and significantly improves dysarthric speech recognition as a data augmentation. Subjective evaluations by two expert speech pathologists validate that DuTa-VC can preserve the severity and type of dysarthria of the target speakers in the synthesized speech.
Stabilized training of joint energy-based models and their practical applications
Mar 07, 2023



The recently proposed Joint Energy-based Model (JEM) interprets discriminatively trained classifier $p(y|x)$ as an energy model, which is also trained as a generative model describing the distribution of the input observations $p(x)$. The JEM training relies on "positive examples" (i.e. examples from the training data set) as well as on "negative examples", which are samples from the modeled distribution $p(x)$ generated by means of Stochastic Gradient Langevin Dynamics (SGLD). Unfortunately, SGLD often fails to deliver negative samples of sufficient quality during the standard JEM training, which causes a very unbalanced contribution from the positive and negative examples when calculating gradients for JEM updates. As a consequence, the standard JEM training is quite unstable requiring careful tuning of hyper-parameters and frequent restarts when the training starts diverging. This makes it difficult to apply JEM to different neural network architectures, modalities, and tasks. In this work, we propose a training procedure that stabilizes SGLD-based JEM training (ST-JEM) by balancing the contribution from the positive and negative examples. We also propose to add an additional "regularization" term to the training objective -- MI between the input observations $x$ and output labels $y$ -- which encourages the JEM classifier to make more certain decisions about output labels. We demonstrate the effectiveness of our approach on the CIFAR10 and CIFAR100 tasks. We also consider the task of classifying phonemes in a speech signal, for which we were not able to train JEM without the proposed stabilization. We show that a convincing speech can be generated from the trained model. Alternatively, corrupted speech can be de-noised by bringing it closer to the modeled speech distribution using a few SGLD iterations. We also propose and discuss additional applications of the trained model.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
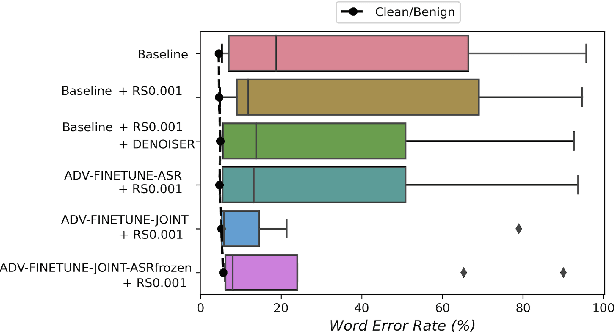

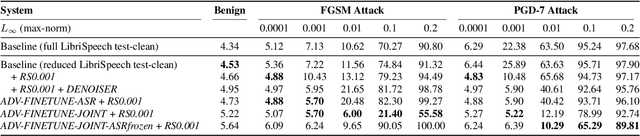
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.