 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Canary-1B-v2 & Parakeet-TDT-0.6B-v3: Efficient and High-Performance Models for Multilingual ASR and AST
Sep 17, 2025



This report introduces Canary-1B-v2, a fast, robust multilingual model for Automatic Speech Recognition (ASR) and Speech-to-Text Translation (AST). Built with a FastConformer encoder and Transformer decoder, it supports 25 languages primarily European. The model was trained on 1.7M hours of total data samples, including Granary and NeMo ASR Set 3.0, with non-speech audio added to reduce hallucinations for ASR and AST. We describe its two-stage pre-training and fine-tuning process with dynamic data balancing, as well as experiments with an nGPT encoder. Results show nGPT scales well with massive data, while FastConformer excels after fine-tuning. For timestamps, Canary-1B-v2 uses the NeMo Forced Aligner (NFA) with an auxiliary CTC model, providing reliable segment-level timestamps for ASR and AST. Evaluations show Canary-1B-v2 outperforms Whisper-large-v3 on English ASR while being 10x faster, and delivers competitive multilingual ASR and AST performance against larger models like Seamless-M4T-v2-large and LLM-based systems. We also release Parakeet-TDT-0.6B-v3, a successor to v2, offering multilingual ASR across the same 25 languages with just 600M parameters.
NeKo: Toward Post Recognition Generative Correction Large Language Models with Task-Oriented Experts
Nov 08, 2024
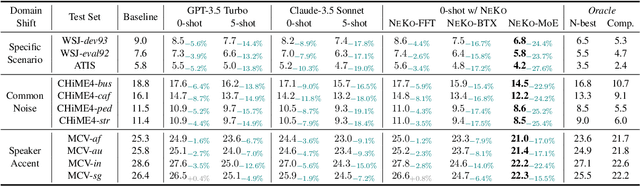
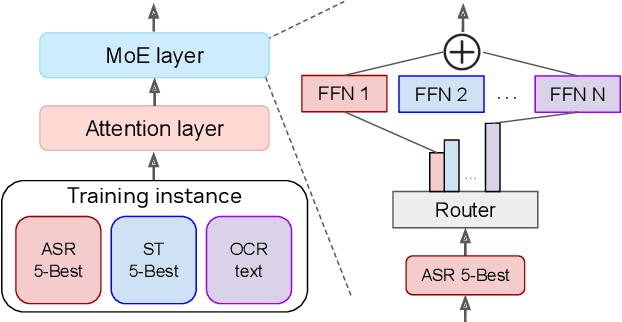
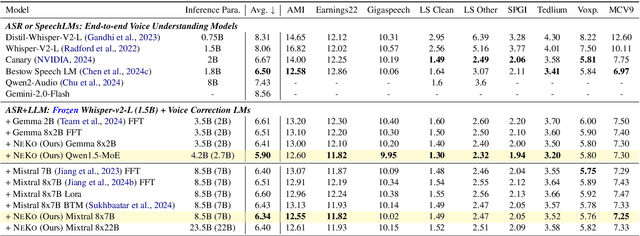
Construction of a general-purpose post-recognition error corrector poses a crucial question: how can we most effectively train a model on a large mixture of domain datasets? The answer would lie in learning dataset-specific features and digesting their knowledge in a single model. Previous methods achieve this by having separate correction language models, resulting in a significant increase in parameters. In this work, we present Mixture-of-Experts as a solution, highlighting that MoEs are much more than a scalability tool. We propose a Multi-Task Correction MoE, where we train the experts to become an ``expert'' of speech-to-text, language-to-text and vision-to-text datasets by learning to route each dataset's tokens to its mapped expert. Experiments on the Open ASR Leaderboard show that we explore a new state-of-the-art performance by achieving an average relative $5.0$% WER reduction and substantial improvements in BLEU scores for speech and translation tasks. On zero-shot evaluation, NeKo outperforms GPT-3.5 and Claude-Opus with $15.5$% to $27.6$% relative WER reduction in the Hyporadise benchmark. NeKo performs competitively on grammar and post-OCR correction as a multi-task model.
VoiceTextBlender: Augmenting Large Language Models with Speech Capabilities via Single-Stage Joint Speech-Text Supervised Fine-Tuning
Oct 23, 2024



Recent studies have augmented large language models (LLMs) with speech capabilities, leading to the development of speech language models (SpeechLMs). Earlier SpeechLMs focused on single-turn speech-based question answering (QA), where user input comprised a speech context and a text question. More recent studies have extended this to multi-turn conversations, though they often require complex, multi-stage supervised fine-tuning (SFT) with diverse data. Another critical challenge with SpeechLMs is catastrophic forgetting-where models optimized for speech tasks suffer significant degradation in text-only performance. To mitigate these issues, we propose a novel single-stage joint speech-text SFT approach on the low-rank adaptation (LoRA) of the LLM backbone. Our joint SFT combines text-only SFT data with three types of speech-related data: speech recognition and translation, speech-based QA, and mixed-modal SFT. Compared to previous SpeechLMs with 7B or 13B parameters, our 3B model demonstrates superior performance across various speech benchmarks while preserving the original capabilities on text-only tasks. Furthermore, our model shows emergent abilities of effectively handling previously unseen prompts and tasks, including multi-turn, mixed-modal inputs.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022



Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Defense against Adversarial Attacks on Hybrid Speech Recognition using Joint Adversarial Fine-tuning with Denoiser
Apr 08, 2022
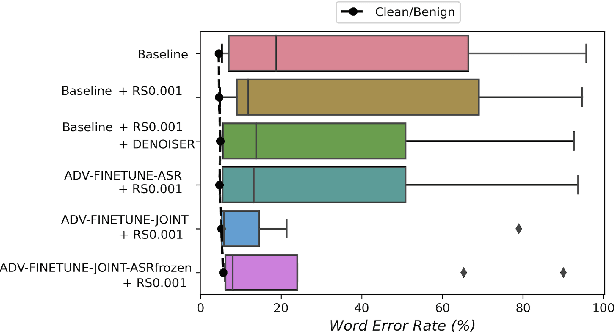

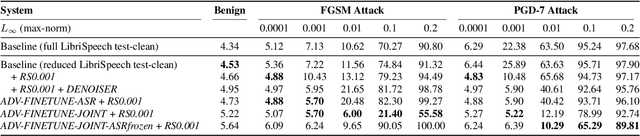
Adversarial attacks are a threat to automatic speech recognition (ASR) systems, and it becomes imperative to propose defenses to protect them. In this paper, we perform experiments to show that K2 conformer hybrid ASR is strongly affected by white-box adversarial attacks. We propose three defenses--denoiser pre-processor, adversarially fine-tuning ASR model, and adversarially fine-tuning joint model of ASR and denoiser. Our evaluation shows denoiser pre-processor (trained on offline adversarial examples) fails to defend against adaptive white-box attacks. However, adversarially fine-tuning the denoiser using a tandem model of denoiser and ASR offers more robustness. We evaluate two variants of this defense--one updating parameters of both models and the second keeping ASR frozen. The joint model offers a mean absolute decrease of 19.3\% ground truth (GT) WER with reference to baseline against fast gradient sign method (FGSM) attacks with different $L_\infty$ norms. The joint model with frozen ASR parameters gives the best defense against projected gradient descent (PGD) with 7 iterations, yielding a mean absolute increase of 22.3\% GT WER with reference to baseline; and against PGD with 500 iterations, yielding a mean absolute decrease of 45.08\% GT WER and an increase of 68.05\% adversarial target WER.
Earnings-21: A Practical Benchmark for ASR in the Wild
Apr 28, 2021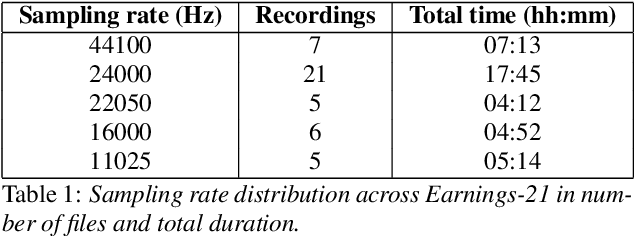
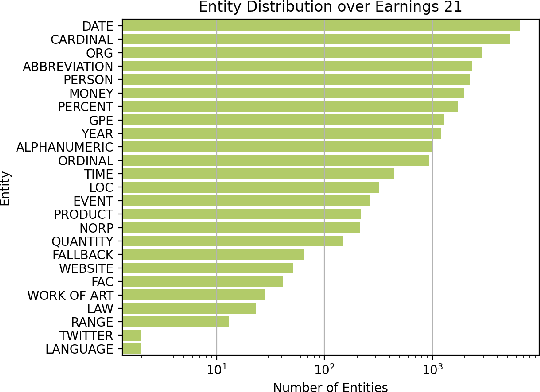
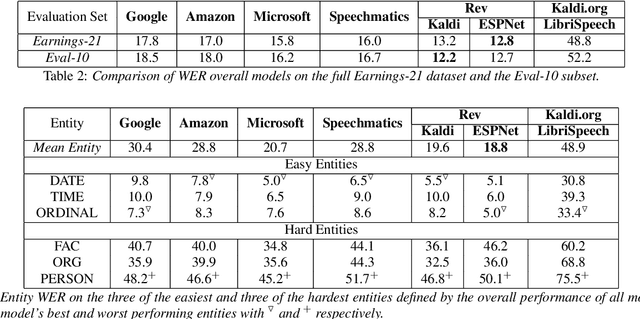
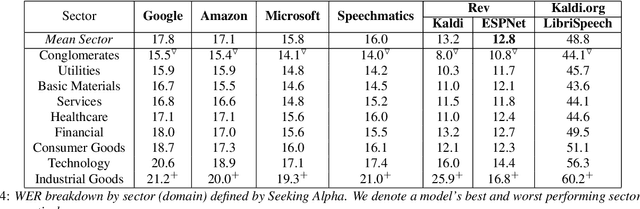
Commonly used speech corpora inadequately challenge academic and commercial ASR systems. In particular, speech corpora lack metadata needed for detailed analysis and WER measurement. In response, we present Earnings-21, a 39-hour corpus of earnings calls containing entity-dense speech from nine different financial sectors. This corpus is intended to benchmark ASR systems in the wild with special attention towards named entity recognition. We benchmark four commercial ASR models, two internal models built with open-source tools, and an open-source LibriSpeech model and discuss their differences in performance on Earnings-21. Using our recently released fstalign tool, we provide a candid analysis of each model's recognition capabilities under different partitions. Our analysis finds that ASR accuracy for certain NER categories is poor, presenting a significant impediment to transcript comprehension and usage. Earnings-21 bridges academic and commercial ASR system evaluation and enables further research on entity modeling and WER on real world audio.
Learning Speaker Embedding from Text-to-Speech
Oct 21, 2020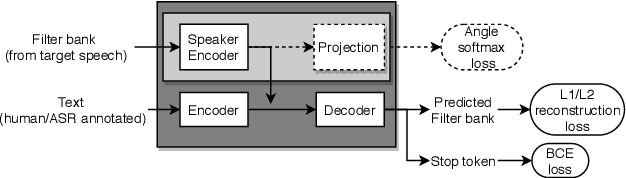

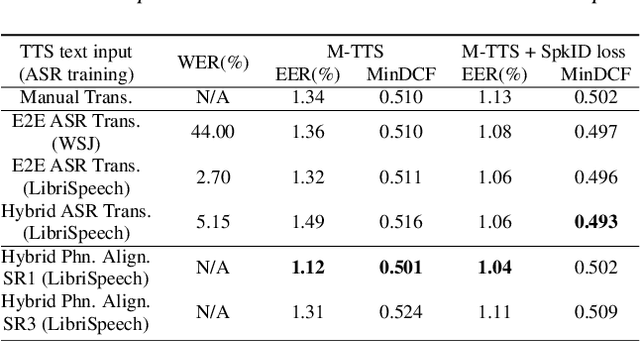
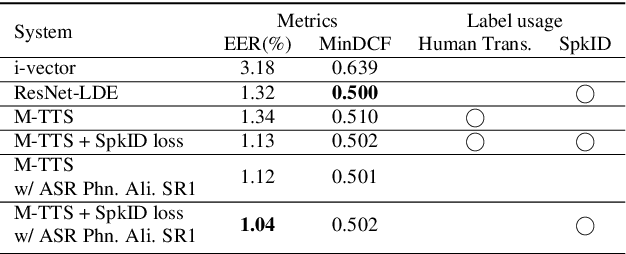
Zero-shot multi-speaker Text-to-Speech (TTS) generates target speaker voices given an input text and the corresponding speaker embedding. In this work, we investigate the effectiveness of the TTS reconstruction objective to improve representation learning for speaker verification. We jointly trained end-to-end Tacotron 2 TTS and speaker embedding networks in a self-supervised fashion. We hypothesize that the embeddings will contain minimal phonetic information since the TTS decoder will obtain that information from the textual input. TTS reconstruction can also be combined with speaker classification to enhance these embeddings further. Once trained, the speaker encoder computes representations for the speaker verification task, while the rest of the TTS blocks are discarded. We investigated training TTS from either manual or ASR-generated transcripts. The latter allows us to train embeddings on datasets without manual transcripts. We compared ASR transcripts and Kaldi phone alignments as TTS inputs, showing that the latter performed better due to their finer resolution. Unsupervised TTS embeddings improved EER by 2.06\% absolute with regard to i-vectors for the LibriTTS dataset. TTS with speaker classification loss improved EER by 0.28\% and 0.73\% absolutely from a model using only speaker classification loss in LibriTTS and Voxceleb1 respectively.
Punctuation Prediction in Spontaneous Conversations: Can We Mitigate ASR Errors with Retrofitted Word Embeddings?
Apr 13, 2020
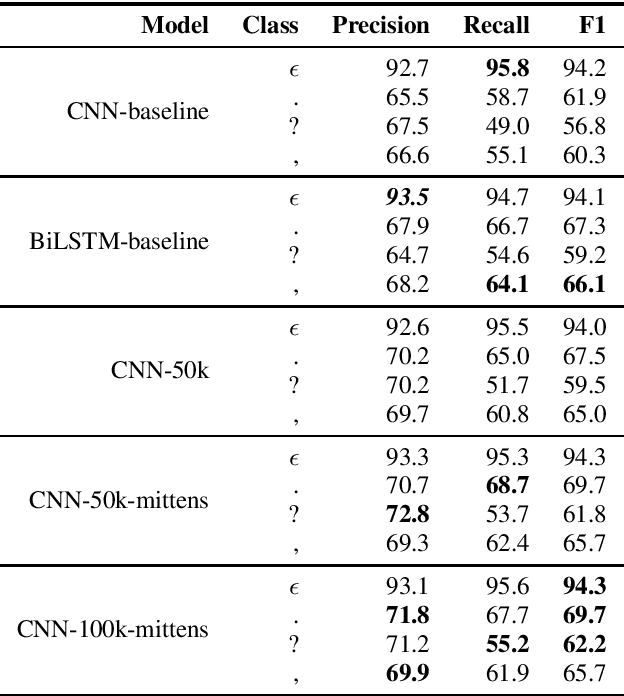
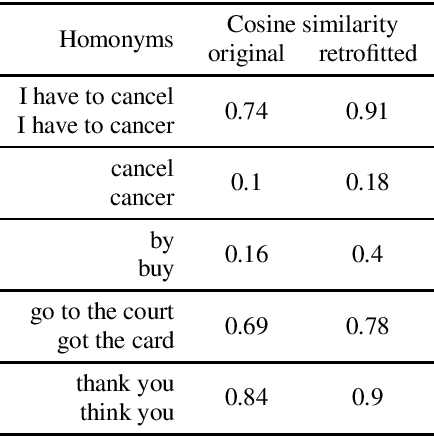

Automatic Speech Recognition (ASR) systems introduce word errors, which often confuse punctuation prediction models, turning punctuation restoration into a challenging task. These errors usually take the form of homonyms. We show how retrofitting of the word embeddings on the domain-specific data can mitigate ASR errors. Our main contribution is a method for better alignment of homonym embeddings and the validation of the presented method on the punctuation prediction task. We record the absolute improvement in punctuation prediction accuracy between 6.2% (for question marks) to 9% (for periods) when compared with the state-of-the-art model.