 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProPS: Prompted Profile Synthesis for Natural Language-Conditioned Speaker Embedding Distributions
Jul 06, 2026Speaker embeddings, or x-vectors, are widely used to represent speaker identity and speaker-related attributes, but existing embedding extractors are typically descriptive rather than generative: they map an observed speech segment to an x-vector, which is then used for downstream applications. We introduce ProPS, Prompted Profile Synthesis, a framework for generating distributions of speaker embeddings conditioned on natural language prompts such as "a thirties male speaker with an Indian accent". ProPS converts human-written profile descriptions into sentence embeddings and uses a mixture density network trained on a large-scale dataset to predict a Gaussian mixture model in the x-vector space. The model is trained by maximizing the likelihood that real speaker embeddings match the requested profile, and its generated distributions are evaluated by negative log-likelihood on held-out x-vectors and by attribute classification accuracies on sampled synthetic x-vectors. Experiments show that ProPS produces profile-conditioned distributions and generates x-vectors that preserve requested speaker attributes such as age, gender, accent, and prosodic characteristics. This design enables controllable speaker-profile synthesis for speech generation systems like Text-To-Speech (TTS) or Voice Conversion (VC) while anchoring generated distributions in observed speaker-embedding structure.
Clustering Unsupervised Representations as Defense against Poisoning Attacks on Speech Commands Classification System
Jun 27, 2026Poisoning attacks entail attackers intentionally tampering with training data. In this paper, we consider a dirty-label poisoning attack scenario on a speech commands classification system. The threat model assumes that certain utterances from one of the classes (source class) are poisoned by superimposing a trigger on it, and its label is changed to another class selected by the attacker (target class). We propose a filtering defense against such an attack. First, we use DIstillation with NO labels (DINO) to learn unsupervised representations for all the training examples. Next, we use K-means and LDA to cluster these representations. Finally, we keep the utterances with the most repeated label in their cluster for training and discard the rest. For a 10% poisoned source class, we demonstrate a drop in attack success rate from 99.75% to 0.25%. We test our defense against a variety of threat models, including different target and source classes, as well as trigger variations.
GENFIG1: Visual Summaries of Scholarly Work as a Challenge for Vision-Language Models
Apr 05, 2026In many science papers, "Figure 1" serves as the primary visual summary of the core research idea. These figures are visually simple yet conceptually rich, often requiring significant effort and iteration by human authors to get right, highlighting the difficulty of science visual communication. With this intuition, we introduce GENFIG1, a benchmark for generative AI models (e.g., Vision-Language Models). GENFIG1 evaluates models for their ability to produce figures that clearly express and motivate the central idea of a paper (title, abstract, introduction, and figure caption) as input. Solving GENFIG1 requires more than producing visually appealing graphics: the task entails reasoning for text-to-image generation that couples scientific understanding with visual synthesis. Specifically, models must (i) comprehend and grasp the technical concepts of the paper, (ii) identify the most salient ones, and (iii) design a coherent and aesthetically effective graphic that conveys those concepts visually and is faithful to the input. We curate the benchmark from papers published at top deep-learning conferences, apply stringent quality control, and introduce an automatic evaluation metric that correlates well with expert human judgments. We evaluate a suite of representative models on GENFIG1 and demonstrate that the task presents significant challenges, even for the best-performing systems. We hope this benchmark serves as a foundation for future progress in multimodal AI.
DiT-Flow: Speech Enhancement Robust to Multiple Distortions based on Flow Matching in Latent Space and Diffusion Transformers
Mar 23, 2026Recent advances in generative models, such as diffusion and flow matching, have shown strong performance in audio tasks. However, speech enhancement (SE) models are typically trained on limited datasets and evaluated under narrow conditions, limiting real-world applicability. To address this, we propose DiT-Flow, a flow matching-based SE framework built on the latent Diffusion Transformer (DiT) backbone and trained for robustness across diverse distortions, including noise, reverberation, and compression. DiT-Flow operates on compact variational auto-encoders (VAEs)-derived latent features. We validated our approach on StillSonicSet, a synthetic yet acoustically realistic dataset composed of LibriSpeech, FSD50K, FMA, and 90 Matterport3D scenes. Experiments show that DiT-Flow consistently outperforms state-of-the-art generative SE models, demonstrating the effectiveness of flow matching in multi-condition speech enhancement. Despite ongoing efforts to expand synthetic data realism, a persistent bottleneck in SE is the inevitable mismatch between training and deployment conditions. By integrating LoRA with the MoE framework, we achieve both parameter-efficient and high-performance training for DiT-Flow robust to multiple distortions with using 4.9% percentage of the total parameters to obtain a better performance on five unseen distortions.
Speaker Verification with Speech-Aware LLMs: Evaluation and Augmentation
Mar 11, 2026Speech-aware large language models (LLMs) can accept speech inputs, yet their training objectives largely emphasize linguistic content or specific fields such as emotions or the speaker's gender, leaving it unclear whether they encode speaker identity. First, we propose a model-agnostic scoring protocol that produces continuous verification scores for both API-only and open-weight models, using confidence scores or log-likelihood ratios from the Yes/No token probabilities. Using this protocol, we benchmark recent speech-aware LLMs and observe weak speaker discrimination (EERs above 20% on VoxCeleb1). Second, we introduce a lightweight augmentation that equips an LLM with ASV capability by injecting frozen ECAPA-TDNN speaker embeddings through a learned projection and training only LoRA adapters. On TinyLLaMA-1.1B, the resulting ECAPA-LLM achieves 1.03% EER on VoxCeleb1-E, approaching a dedicated speaker verification system while preserving a natural-language interface.
SAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
Jan 27, 2026The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
Spoken DialogSum: An Emotion-Rich Conversational Dataset for Spoken Dialogue Summarization
Dec 17, 2025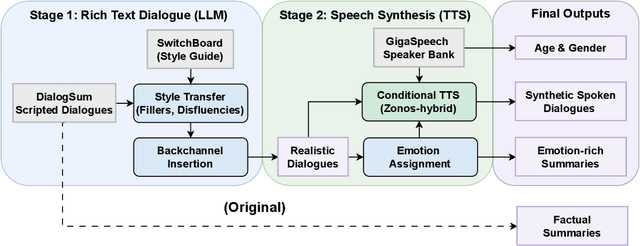

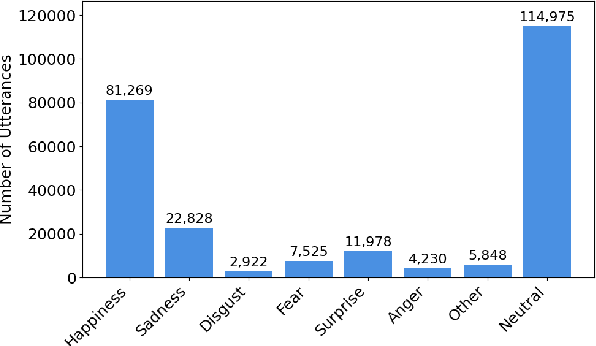
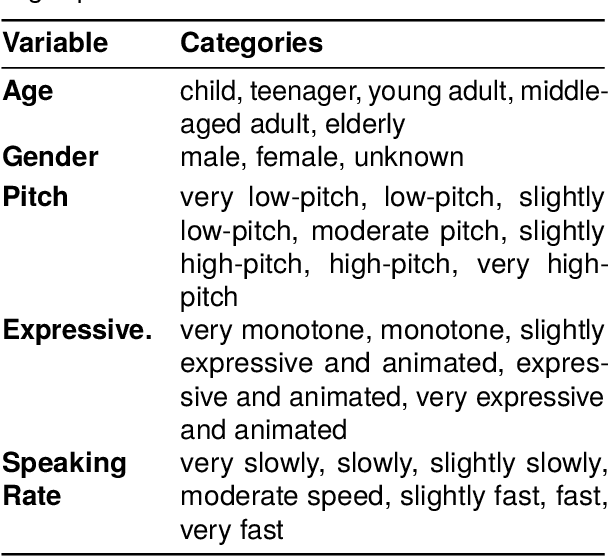
Recent audio language models can follow long conversations. However, research on emotion-aware or spoken dialogue summarization is constrained by the lack of data that links speech, summaries, and paralinguistic cues. We introduce Spoken DialogSum, the first corpus aligning raw conversational audio with factual summaries, emotion-rich summaries, and utterance-level labels for speaker age, gender, and emotion. The dataset is built in two stages: first, an LLM rewrites DialogSum scripts with Switchboard-style fillers and back-channels, then tags each utterance with emotion, pitch, and speaking rate. Second, an expressive TTS engine synthesizes speech from the tagged scripts, aligned with paralinguistic labels. Spoken DialogSum comprises 13,460 emotion-diverse dialogues, each paired with both a factual and an emotion-focused summary. We release an online demo at https://fatfat-emosum.github.io/EmoDialog-Sum-Audio-Samples/, with plans to release the full dataset in the near future. Baselines show that an Audio-LLM raises emotional-summary ROUGE-L by 28% relative to a cascaded ASR-LLM system, confirming the value of end-to-end speech modeling.
Multi-Target Backdoor Attacks Against Speaker Recognition
Aug 13, 2025In this work, we propose a multi-target backdoor attack against speaker identification using position-independent clicking sounds as triggers. Unlike previous single-target approaches, our method targets up to 50 speakers simultaneously, achieving success rates of up to 95.04%. To simulate more realistic attack conditions, we vary the signal-to-noise ratio between speech and trigger, demonstrating a trade-off between stealth and effectiveness. We further extend the attack to the speaker verification task by selecting the most similar training speaker - based on cosine similarity - as a proxy target. The attack is most effective when target and enrolled speaker pairs are highly similar, reaching success rates of up to 90% in such cases.
Enhancing Dialogue Annotation with Speaker Characteristics Leveraging a Frozen LLM
Aug 06, 2025In dialogue transcription pipelines, Large Language Models (LLMs) are frequently employed in post-processing to improve grammar, punctuation, and readability. We explore a complementary post-processing step: enriching transcribed dialogues by adding metadata tags for speaker characteristics such as age, gender, and emotion. Some of the tags are global to the entire dialogue, while some are time-variant. Our approach couples frozen audio foundation models, such as Whisper or WavLM, with a frozen LLAMA language model to infer these speaker attributes, without requiring task-specific fine-tuning of either model. Using lightweight, efficient connectors to bridge audio and language representations, we achieve competitive performance on speaker profiling tasks while preserving modularity and speed. Additionally, we demonstrate that a frozen LLAMA model can compare x-vectors directly, achieving an Equal Error Rate of 8.8% in some scenarios.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.