 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Multiple Datasets for Improved Appearance-Based Gaze Estimation
Sep 02, 2024Multiple datasets have been created for training and testing appearance-based gaze estimators. Intuitively, more data should lead to better performance. However, combining datasets to train a single esti-mator rarely improves gaze estimation performance. One reason may be differences in the experimental protocols used to obtain the gaze sam-ples, resulting in differences in the distributions of head poses, gaze an-gles, illumination, etc. Another reason may be the inconsistency between methods used to define gaze angles (label mismatch). We propose two innovations to improve the performance of gaze estimation by leveraging multiple datasets, a change in the estimator architecture and the intro-duction of a gaze adaptation module. Most state-of-the-art estimators merge information extracted from images of the two eyes and the entire face either in parallel or combine information from the eyes first then with the face. Our proposed Two-stage Transformer-based Gaze-feature Fusion (TTGF) method uses transformers to merge information from each eye and the face separately and then merge across the two eyes. We argue that this improves head pose invariance since changes in head pose affect left and right eye images in different ways. Our proposed Gaze Adaptation Module (GAM) method handles annotation inconsis-tency by applying a Gaze Adaption Module for each dataset to correct gaze estimates from a single shared estimator. This enables us to combine information across datasets despite differences in labeling. Our experi-ments show that these innovations improve gaze estimation performance over the SOTA both individually and collectively (by 10% - 20%). Our code is available at https://github.com/HKUST-NISL/GazeSetMerge.
Survey of Design Paradigms for Social Robots
Jul 30, 2024The demand for social robots in fields like healthcare, education, and entertainment increases due to their emotional adaptation features. These robots leverage multimodal communication, incorporating speech, facial expressions, and gestures to enhance user engagement and emotional support. The understanding of design paradigms of social robots is obstructed by the complexity of the system and the necessity to tune it to a specific task. This article provides a structured review of social robot design paradigms, categorizing them into cognitive architectures, role design models, linguistic models, communication flow, activity system models, and integrated design models. By breaking down the articles on social robot design and application based on these paradigms, we highlight the strengths and areas for improvement in current approaches. We further propose our original integrated design model that combines the most important aspects of the design of social robots. Our approach shows the importance of integrating operational, communicational, and emotional dimensions to create more adaptive and empathetic interactions between robots and humans.
Hallucinations in Neural Automatic Speech Recognition: Identifying Errors and Hallucinatory Models
Jan 03, 2024



Hallucinations are a type of output error produced by deep neural networks. While this has been studied in natural language processing, they have not been researched previously in automatic speech recognition. Here, we define hallucinations in ASR as transcriptions generated by a model that are semantically unrelated to the source utterance, yet still fluent and coherent. The similarity of hallucinations to probable natural language outputs of the model creates a danger of deception and impacts the credibility of the system. We show that commonly used metrics, such as word error rates, cannot differentiate between hallucinatory and non-hallucinatory models. To address this, we propose a perturbation-based method for assessing the susceptibility of an automatic speech recognition (ASR) model to hallucination at test time, which does not require access to the training dataset. We demonstrate that this method helps to distinguish between hallucinatory and non-hallucinatory models that have similar baseline word error rates. We further explore the relationship between the types of ASR errors and the types of dataset noise to determine what types of noise are most likely to create hallucinatory outputs. We devise a framework for identifying hallucinations by analysing their semantic connection with the ground truth and their fluency. Finally, we discover how to induce hallucinations with a random noise injection to the utterance.
Automatic Speech Recognition Datasets in Cantonese: A Survey and New Dataset
Jan 17, 2022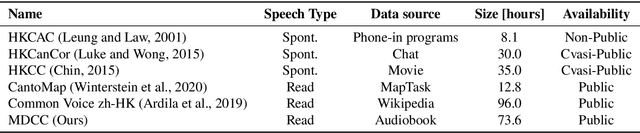
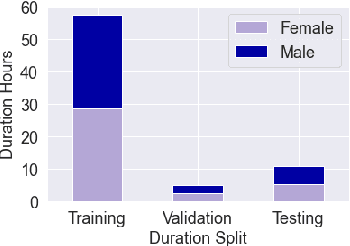
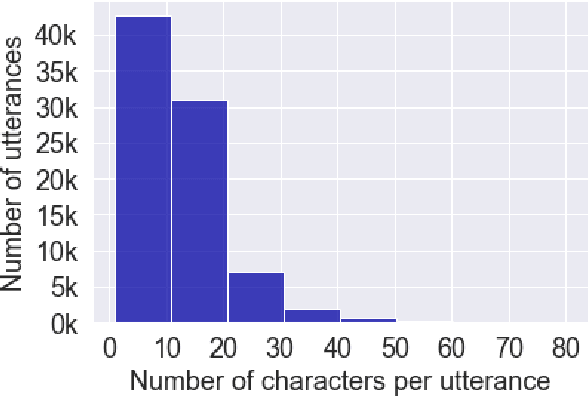
Automatic speech recognition (ASR) on low resource languages improves the access of linguistic minorities to technological advantages provided by artificial intelligence (AI). In this paper, we address the problem of data scarcity for the Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It comprises philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and analyze them according to their speech type, data source, total size and availability. We further conduct experiments with Fairseq S2T Transformer, a state-of-the-art ASR model, on the biggest existing dataset, Common Voice zh-HK, and our proposed MDCC, and the results show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022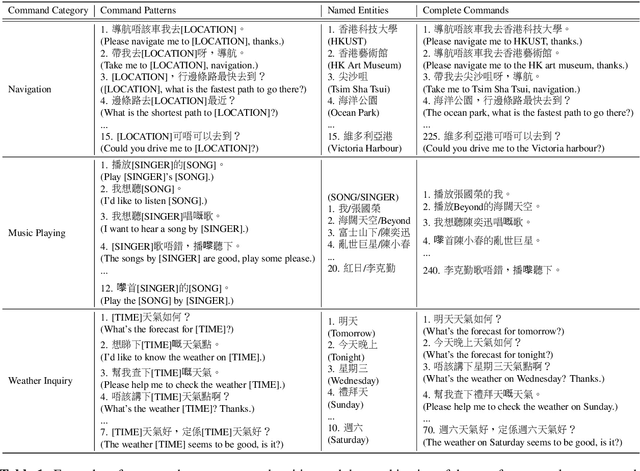
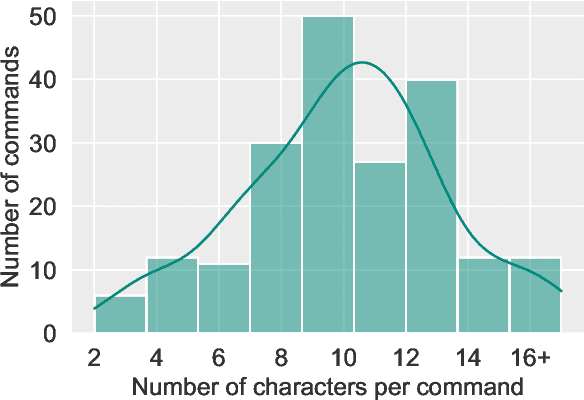
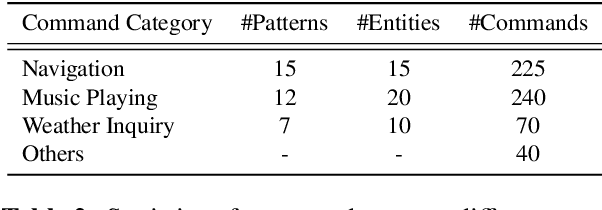
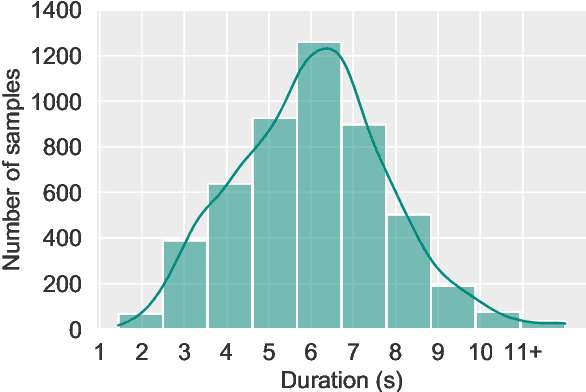
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.
ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation
Jan 07, 2022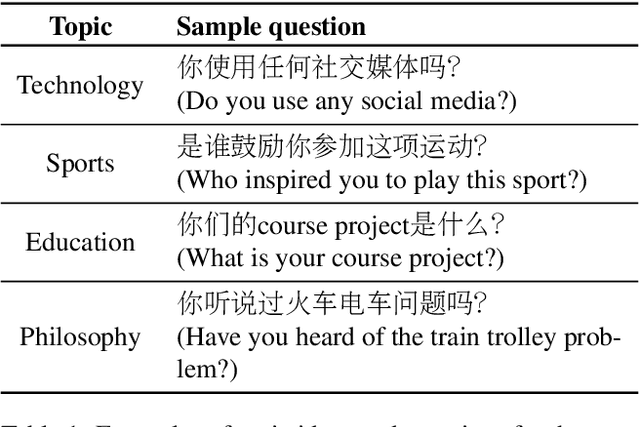

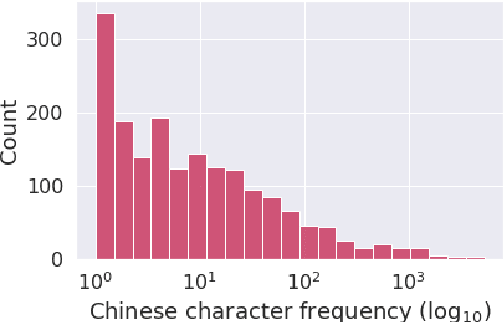
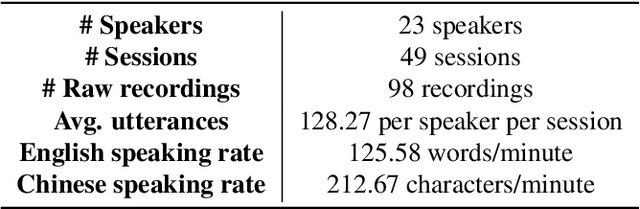
Code-switching is a speech phenomenon when a speaker switches language during a conversation. Despite the spontaneous nature of code-switching in conversational spoken language, most existing works collect code-switching data through read speech instead of spontaneous speech. ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong. We report ASCEND's design and procedure of collecting the speech data, including the annotations in this work. ASCEND includes 23 bilinguals that are fluent in both Chinese and English and consists of 10.62 hours clean speech corpus. We also conduct a baseline experiment using pre-trained wav2vec 2.0 models, achieving the best performance of 22.69% character error rate and 27.05% mixed error rate.
Towards Better Uncertainty: Iterative Training of Efficient Networks for Multitask Emotion Recognition
Jul 21, 2021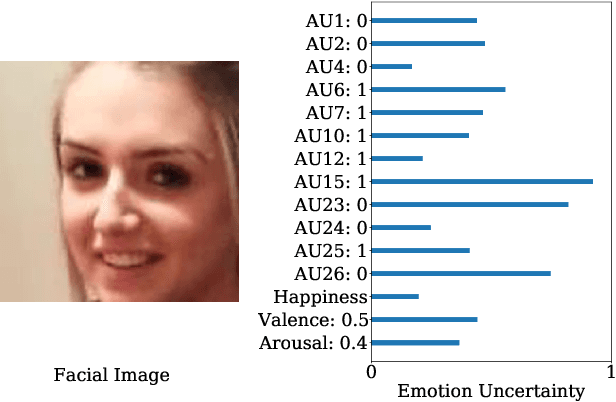
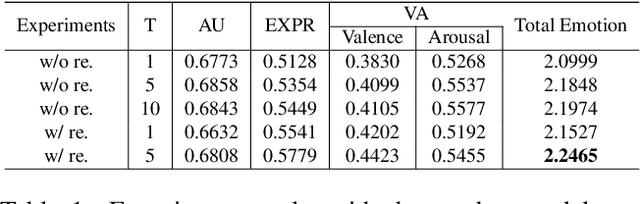
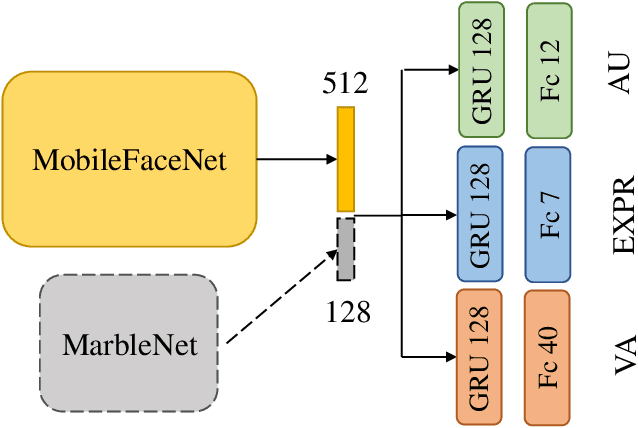
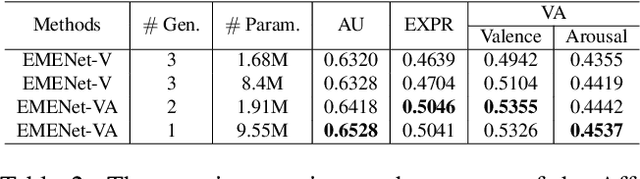
When recognizing emotions, subtle nuances of emotion displays often cause ambiguity or uncertainty in emotion perception. Unfortunately, the ambiguity or uncertainty cannot be reflected in hard emotion labels. Emotion predictions with uncertainty can be useful for risk controlling, but they are relatively scarce in current deep models for emotion recognition. To address this issue, we propose to apply the multi-generational self-distillation algorithm to emotion recognition task towards better uncertainty estimation performance. We firstly use deep ensembles to capture uncertainty, as an approximation to Bayesian methods. Secondly, the deep ensemble provides soft labels to its student models, while the student models can learn from the uncertainty embedded in those soft labels. Thirdly, we iteratively train deep ensembles to further improve the performance of emotion recognition and uncertainty estimation. In the end, our algorithm results in a single student model that can estimate in-domain uncertainty and a student ensemble that can detect out-of-domain samples. We trained our Efficient Multitask Emotion Networks (EMENet) on the Aff-wild2 dataset, and conducted extensive experiments on emotion recognition and uncertainty estimation. Our algorithm gives more reliable uncertainty estimates than Temperature Scaling and Monte Carol Dropout.
Self-Calibrating Active Binocular Vision via Active Efficient Coding with Deep Autoencoders
Jan 27, 2021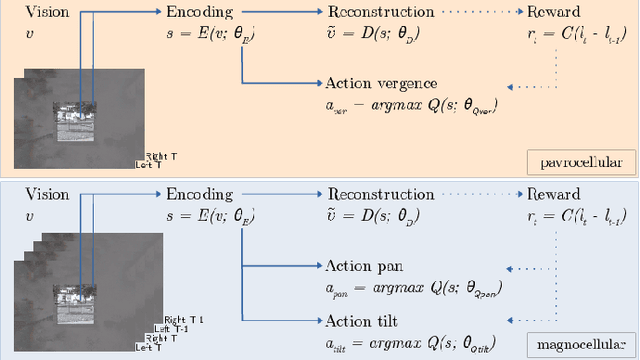
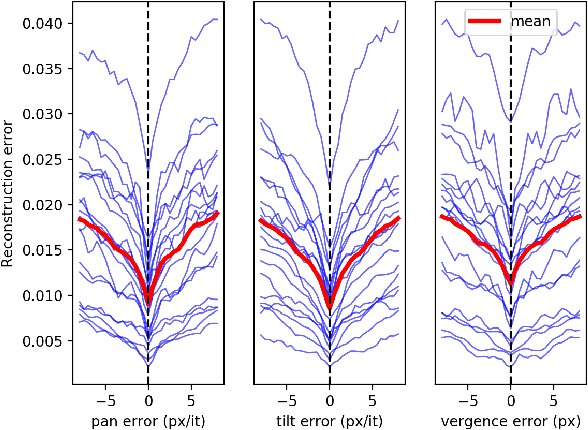
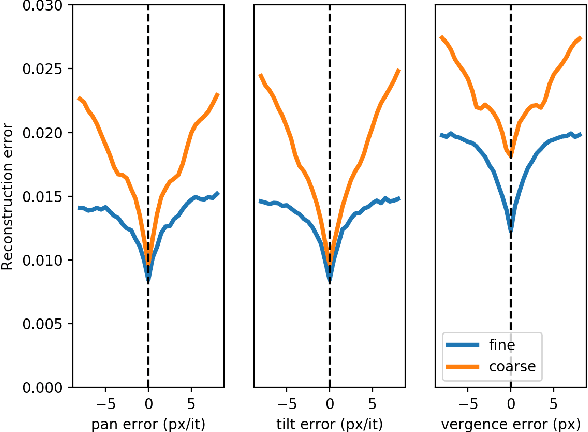
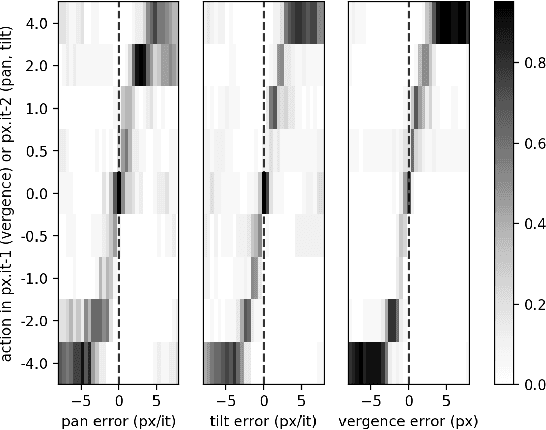
We present a model of the self-calibration of active binocular vision comprising the simultaneous learning of visual representations, vergence, and pursuit eye movements. The model follows the principle of Active Efficient Coding (AEC), a recent extension of the classic Efficient Coding Hypothesis to active perception. In contrast to previous AEC models, the present model uses deep autoencoders to learn sensory representations. We also propose a new formulation of the intrinsic motivation signal that guides the learning of behavior. We demonstrate the performance of the model in simulations.
AVGCN: Trajectory Prediction using Graph Convolutional Networks Guided by Human Attention
Jan 14, 2021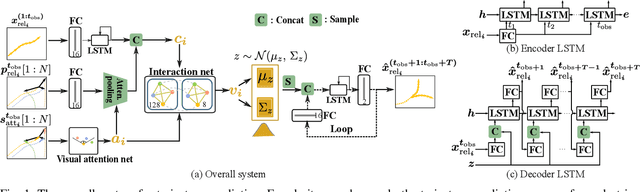
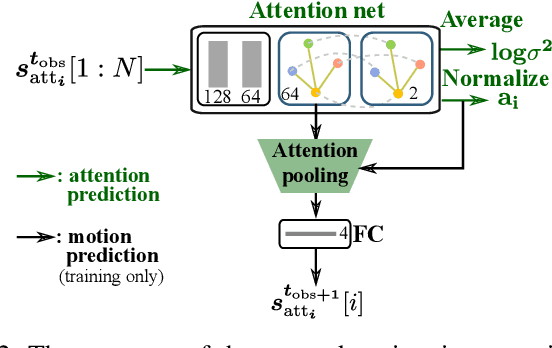
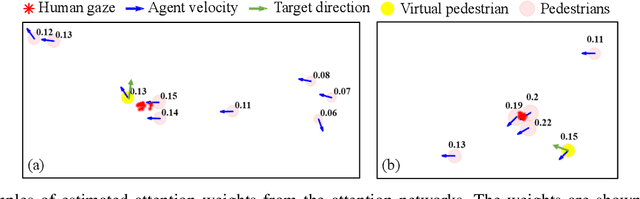
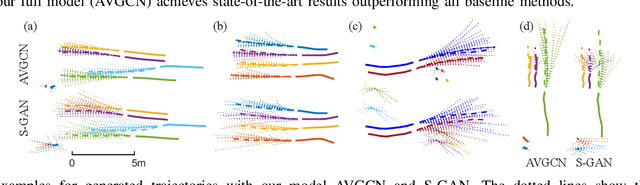
Pedestrian trajectory prediction is a critical yet challenging task, especially for crowded scenes. We suggest that introducing an attention mechanism to infer the importance of different neighbors is critical for accurate trajectory prediction in scenes with varying crowd size. In this work, we propose a novel method, AVGCN, for trajectory prediction utilizing graph convolutional networks (GCN) based on human attention (A denotes attention, V denotes visual field constraints). First, we train an attention network that estimates the importance of neighboring pedestrians, using gaze data collected as subjects perform a bird's eye view crowd navigation task. Then, we incorporate the learned attention weights modulated by constraints on the pedestrian's visual field into a trajectory prediction network that uses a GCN to aggregate information from neighbors efficiently. AVGCN also considers the stochastic nature of pedestrian trajectories by taking advantage of variational trajectory prediction. Our approach achieves state-of-the-art performance on several trajectory prediction benchmarks, and the lowest average prediction error over all considered benchmarks.
HGCN-GJS: Hierarchical Graph Convolutional Network with Groupwise Joint Sampling for Trajectory Prediction
Sep 15, 2020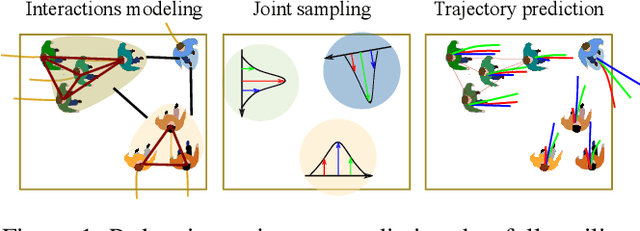
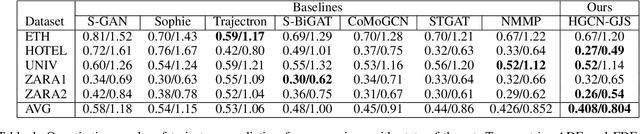
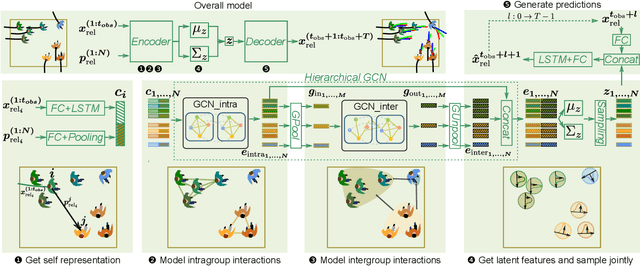
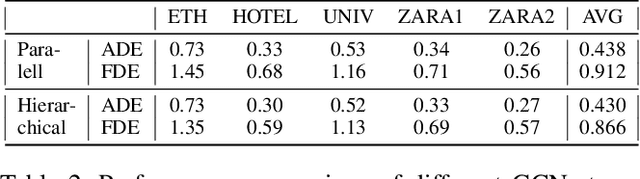
Accurate pedestrian trajectory prediction is of great importance for downstream tasks such as autonomous driving and mobile robot navigation. Fully investigating the social interactions within the crowd is crucial for accurate pedestrian trajectory prediction. However, most existing methods do not capture group level interactions well, focusing only on pairwise interactions and neglecting group-wise interactions. In this work, we propose a hierarchical graph convolutional network, HGCN-GJS, for trajectory prediction which well leverages group level interactions within the crowd. Furthermore, we introduce a novel joint sampling scheme for modeling the joint distribution of multiple pedestrians in the future trajectories. Based on the group information, this scheme associates the trajectory of one person with the trajectory of other people in the group, but maintains the independence of the trajectories of outsiders. We demonstrate the performance of our network on several trajectory prediction datasets, achieving state-of-the-art results on all datasets considered.