 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
SpellMapper: A non-autoregressive neural spellchecker for ASR customization with candidate retrieval based on n-gram mappings
Jun 04, 2023
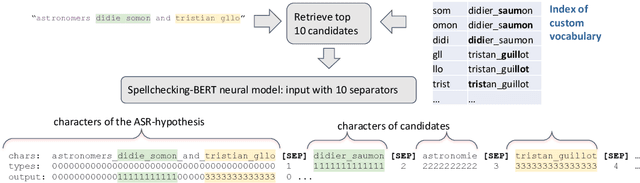
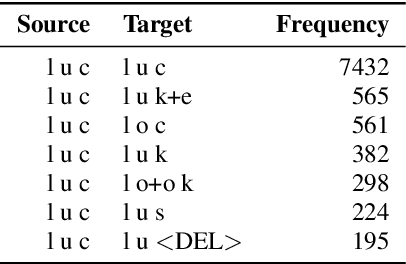

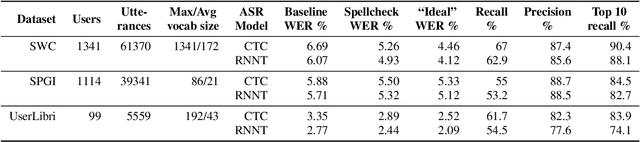
Contextual spelling correction models are an alternative to shallow fusion to improve automatic speech recognition (ASR) quality given user vocabulary. To deal with large user vocabularies, most of these models include candidate retrieval mechanisms, usually based on minimum edit distance between fragments of ASR hypothesis and user phrases. However, the edit-distance approach is slow, non-trainable, and may have low recall as it relies only on common letters. We propose: 1) a novel algorithm for candidate retrieval, based on misspelled n-gram mappings, which gives up to 90% recall with just the top 10 candidates on Spoken Wikipedia; 2) a non-autoregressive neural model based on BERT architecture, where the initial transcript and ten candidates are combined into one input. The experiments on Spoken Wikipedia show 21.4% word error rate improvement compared to a baseline ASR system.
Acoustic absement in detail: Quantifying acoustic differences across time-series representations of speech data
Apr 14, 2023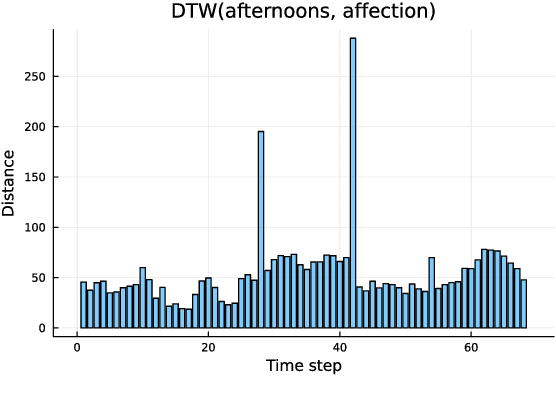
The speech signal is a consummate example of time-series data. The acoustics of the signal change over time, sometimes dramatically. Yet, the most common type of comparison we perform in phonetics is between instantaneous acoustic measurements, such as formant values. In the present paper, I discuss the concept of absement as a quantification of differences between two time-series. I then provide an experimental example of absement applied to phonetic analysis for human and/or computer speech recognition. The experiment is a template-based speech recognition task, using dynamic time warping to compare the acoustics between recordings of isolated words. A recognition accuracy of 57.9% was achieved. The results of the experiment are discussed in terms of using absement as a tool, as well as the implications of using acoustics-only models of spoken word recognition with the word as the smallest discrete linguistic unit.
DiscoverPath: A Knowledge Refinement and Retrieval System for Interdisciplinarity on Biomedical Research
Sep 04, 2023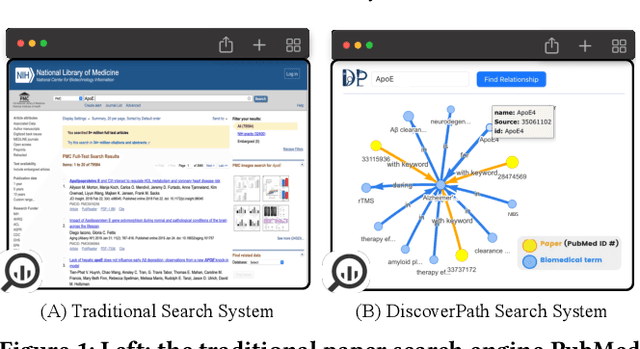
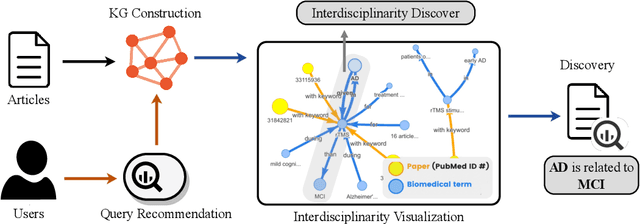
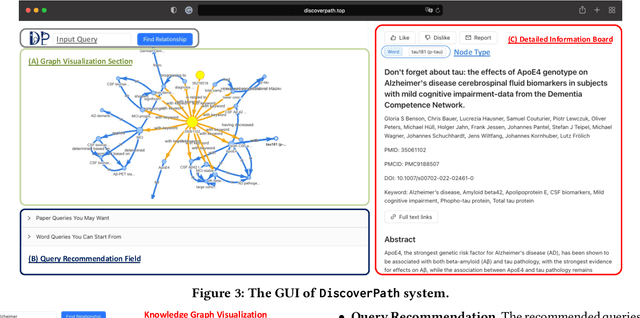
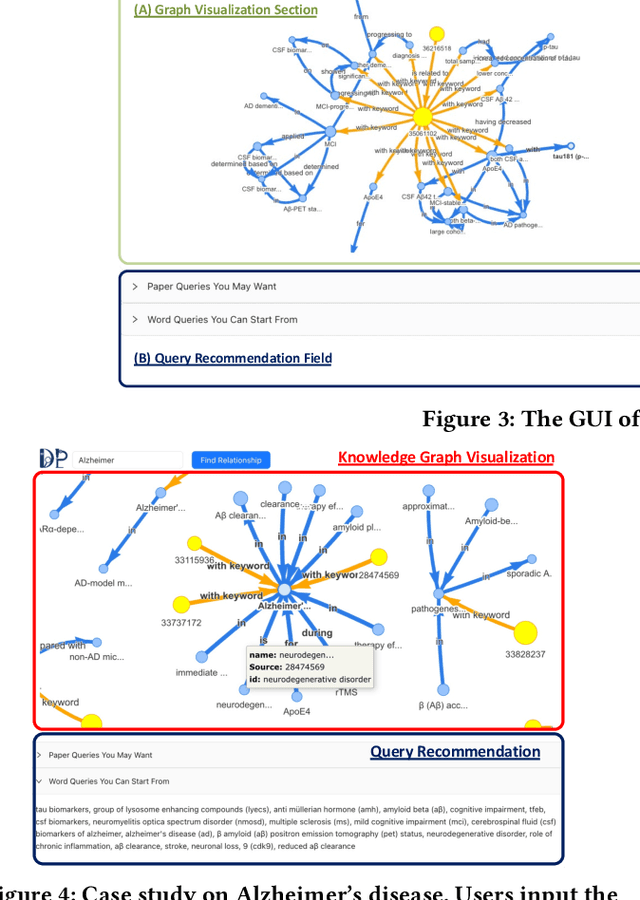
The exponential growth in scholarly publications necessitates advanced tools for efficient article retrieval, especially in interdisciplinary fields where diverse terminologies are used to describe similar research. Traditional keyword-based search engines often fall short in assisting users who may not be familiar with specific terminologies. To address this, we present a knowledge graph-based paper search engine for biomedical research to enhance the user experience in discovering relevant queries and articles. The system, dubbed DiscoverPath, employs Named Entity Recognition (NER) and part-of-speech (POS) tagging to extract terminologies and relationships from article abstracts to create a KG. To reduce information overload, DiscoverPath presents users with a focused subgraph containing the queried entity and its neighboring nodes and incorporates a query recommendation system, enabling users to iteratively refine their queries. The system is equipped with an accessible Graphical User Interface that provides an intuitive visualization of the KG, query recommendations, and detailed article information, enabling efficient article retrieval, thus fostering interdisciplinary knowledge exploration. DiscoverPath is open-sourced at https://github.com/ynchuang/DiscoverPath.
Improving Language Model Integration for Neural Machine Translation
Jun 08, 2023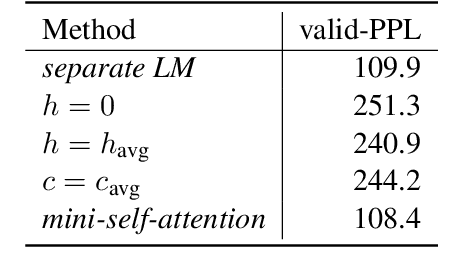
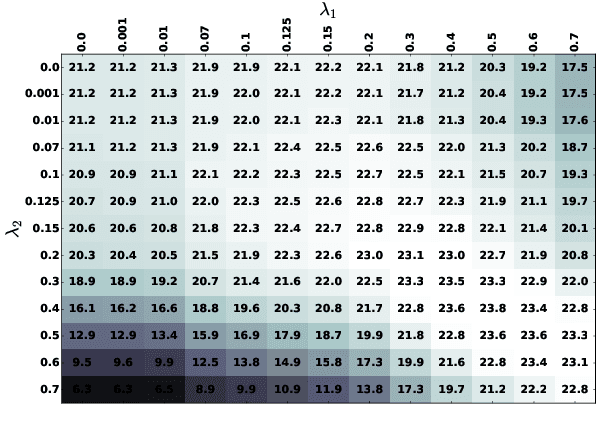
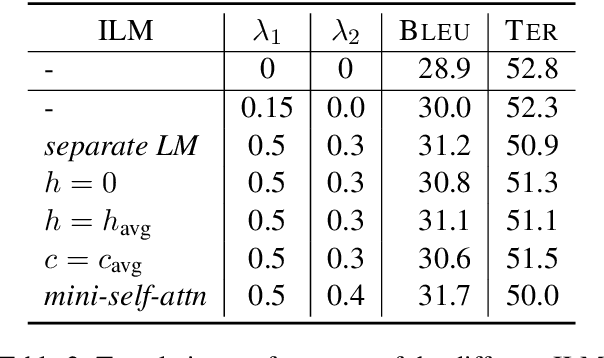
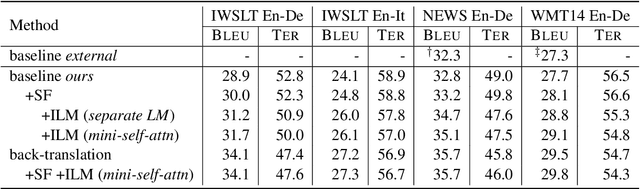
The integration of language models for neural machine translation has been extensively studied in the past. It has been shown that an external language model, trained on additional target-side monolingual data, can help improve translation quality. However, there has always been the assumption that the translation model also learns an implicit target-side language model during training, which interferes with the external language model at decoding time. Recently, some works on automatic speech recognition have demonstrated that, if the implicit language model is neutralized in decoding, further improvements can be gained when integrating an external language model. In this work, we transfer this concept to the task of machine translation and compare with the most prominent way of including additional monolingual data - namely back-translation. We find that accounting for the implicit language model significantly boosts the performance of language model fusion, although this approach is still outperformed by back-translation.
SoftCorrect: Error Correction with Soft Detection for Automatic Speech Recognition
Dec 02, 2022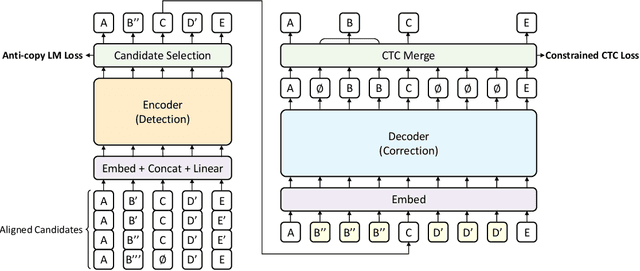
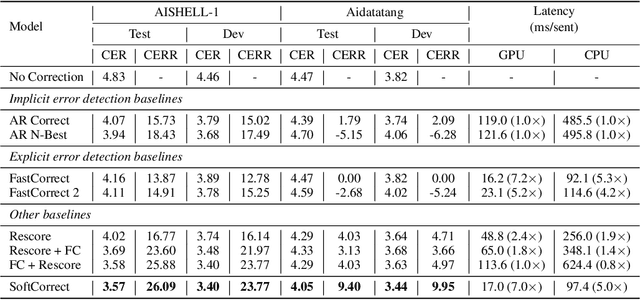
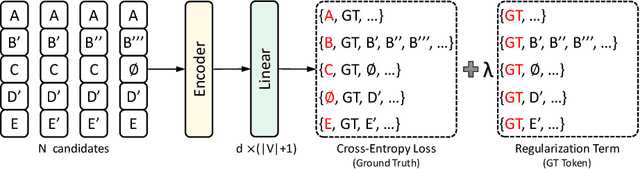
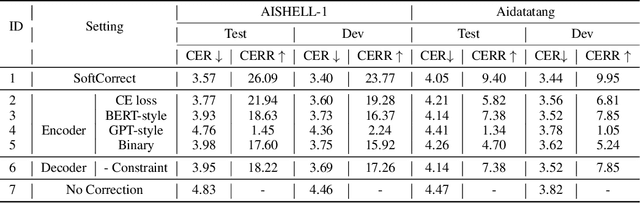
Error correction in automatic speech recognition (ASR) aims to correct those incorrect words in sentences generated by ASR models. Since recent ASR models usually have low word error rate (WER), to avoid affecting originally correct tokens, error correction models should only modify incorrect words, and therefore detecting incorrect words is important for error correction. Previous works on error correction either implicitly detect error words through target-source attention or CTC (connectionist temporal classification) loss, or explicitly locate specific deletion/substitution/insertion errors. However, implicit error detection does not provide clear signal about which tokens are incorrect and explicit error detection suffers from low detection accuracy. In this paper, we propose SoftCorrect with a soft error detection mechanism to avoid the limitations of both explicit and implicit error detection. Specifically, we first detect whether a token is correct or not through a probability produced by a dedicatedly designed language model, and then design a constrained CTC loss that only duplicates the detected incorrect tokens to let the decoder focus on the correction of error tokens. Compared with implicit error detection with CTC loss, SoftCorrect provides explicit signal about which words are incorrect and thus does not need to duplicate every token but only incorrect tokens; compared with explicit error detection, SoftCorrect does not detect specific deletion/substitution/insertion errors but just leaves it to CTC loss. Experiments on AISHELL-1 and Aidatatang datasets show that SoftCorrect achieves 26.1% and 9.4% CER reduction respectively, outperforming previous works by a large margin, while still enjoying fast speed of parallel generation.
Quilt-1M: One Million Image-Text Pairs for Histopathology
Jun 22, 2023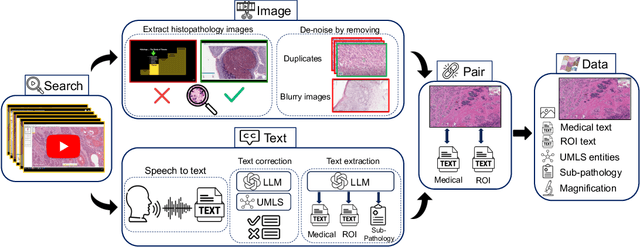
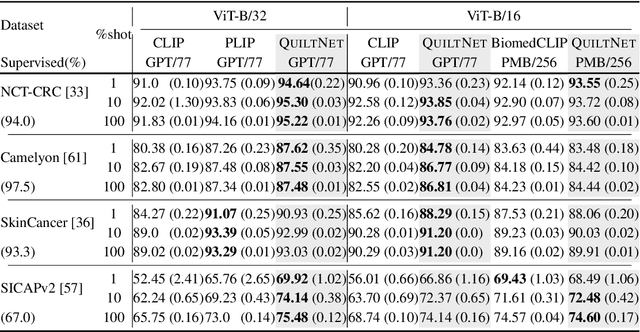
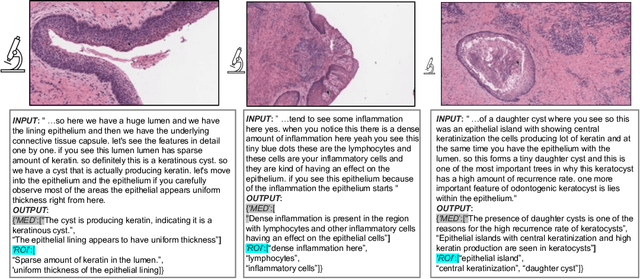
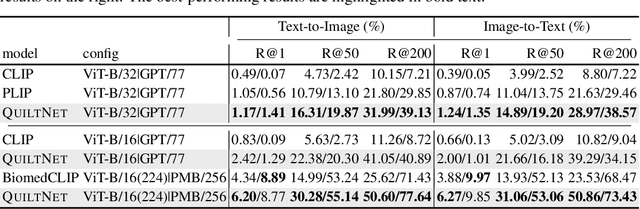
Recent accelerations in multi-modal applications have been made possible with the plethora of image and text data available online. However, the scarcity of analogous data in the medical field, specifically in histopathology, has halted comparable progress. To enable similar representation learning for histopathology, we turn to YouTube, an untapped resource of videos, offering $1,087$ hours of valuable educational histopathology videos from expert clinicians. From YouTube, we curate Quilt: a large-scale vision-language dataset consisting of $768,826$ image and text pairs. Quilt was automatically curated using a mixture of models, including large language models, handcrafted algorithms, human knowledge databases, and automatic speech recognition. In comparison, the most comprehensive datasets curated for histopathology amass only around $200$K samples. We combine Quilt with datasets from other sources, including Twitter, research papers, and the internet in general, to create an even larger dataset: Quilt-1M, with $1$M paired image-text samples, marking it as the largest vision-language histopathology dataset to date. We demonstrate the value of Quilt-1M by fine-tuning a pre-trained CLIP model. Our model outperforms state-of-the-art models on both zero-shot and linear probing tasks for classifying new histopathology images across $13$ diverse patch-level datasets of $8$ different sub-pathologies and cross-modal retrieval tasks.
DistilXLSR: A Light Weight Cross-Lingual Speech Representation Model
Jun 02, 2023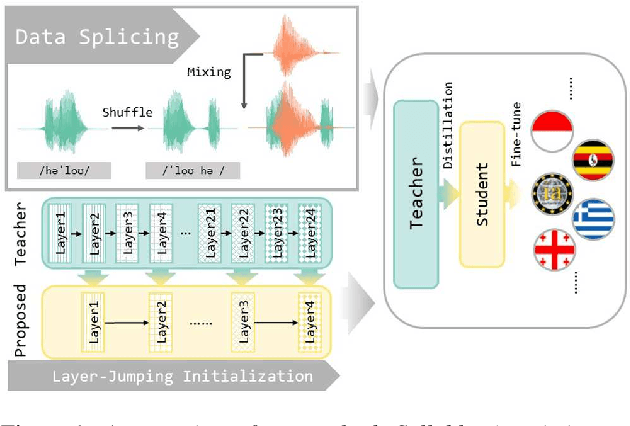
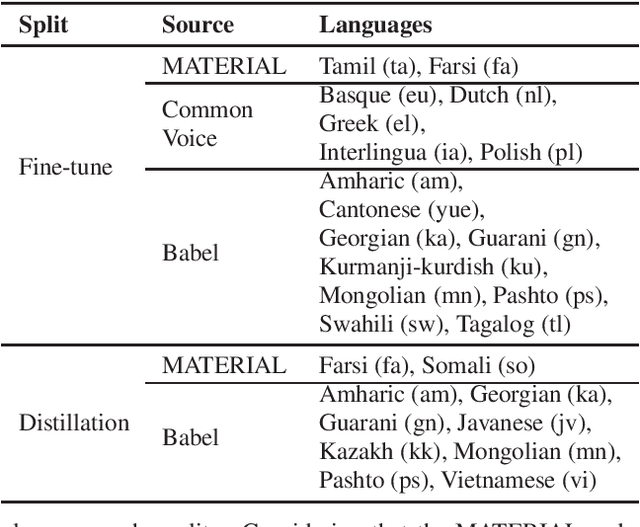
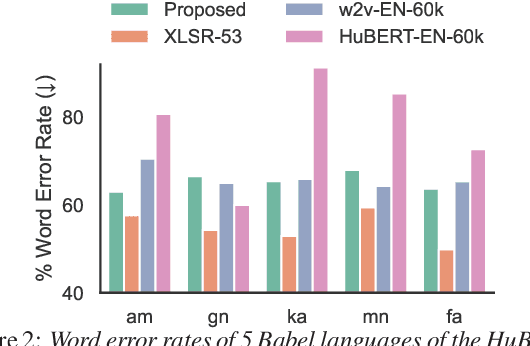
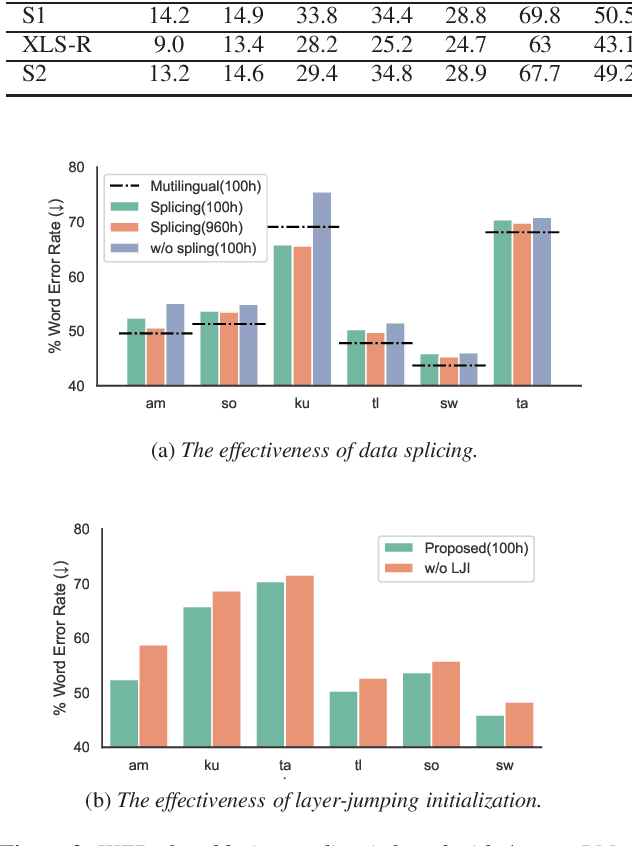
Multilingual self-supervised speech representation models have greatly enhanced the speech recognition performance for low-resource languages, and the compression of these huge models has also become a crucial prerequisite for their industrial application. In this paper, we propose DistilXLSR, a distilled cross-lingual speech representation model. By randomly shuffling the phonemes of existing speech, we reduce the linguistic information and distill cross-lingual models using only English data. We also design a layer-jumping initialization method to fully leverage the teacher's pre-trained weights. Experiments on 2 kinds of teacher models and 15 low-resource languages show that our method can reduce the parameters by 50% while maintaining cross-lingual representation ability. Our method is proven to be generalizable to various languages/teacher models and has the potential to improve the cross-lingual performance of the English pre-trained models.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 26, 2023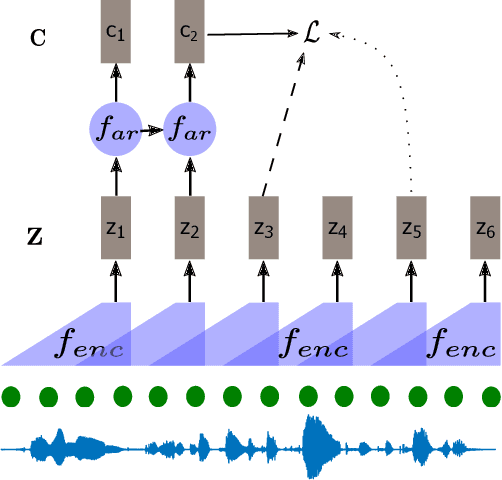
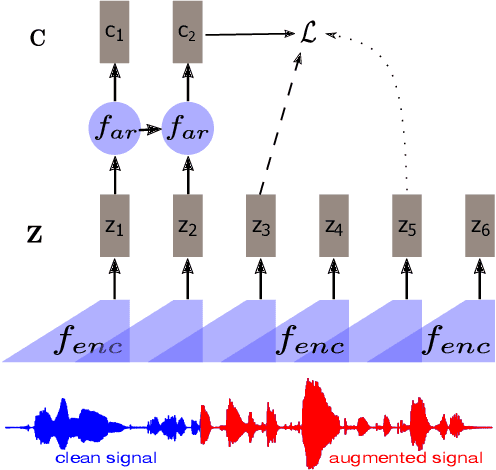
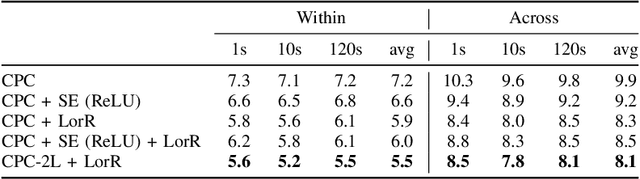
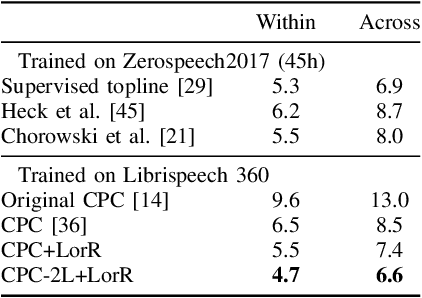
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-Right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models on the ABX task.
Auditory-Based Data Augmentation for End-to-End Automatic Speech Recognition
Apr 08, 2022

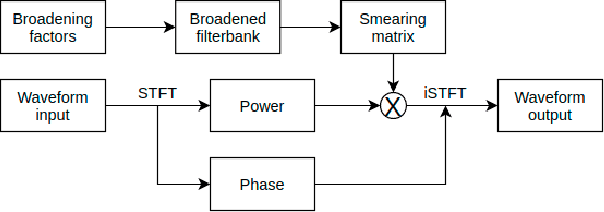
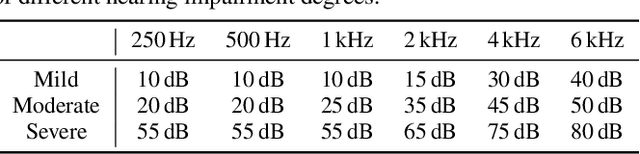
End-to-end models have achieved significant improvement on automatic speech recognition. One common method to improve performance of these models is expanding the data-space through data augmentation. Meanwhile, human auditory inspired front-ends have also demonstrated improvement for automatic speech recognisers. In this work, a well-verified auditory-based model, which can simulate various hearing abilities, is investigated for the purpose of data augmentation for end-to-end speech recognition. By introducing the auditory model into the data augmentation process, end-to-end systems are encouraged to ignore variation from the signal that cannot be heard and thereby focus on robust features for speech recognition. Two mechanisms in the auditory model, spectral smearing and loudness recruitment, are studied on the LibriSpeech dataset with a transformer-based end-to-end model. The results show that the proposed augmentation methods can bring statistically significant improvement on the performance of the state-of-the-art SpecAugment.
Transfer Learning from Pre-trained Language Models Improves End-to-End Speech Summarization
Jun 07, 2023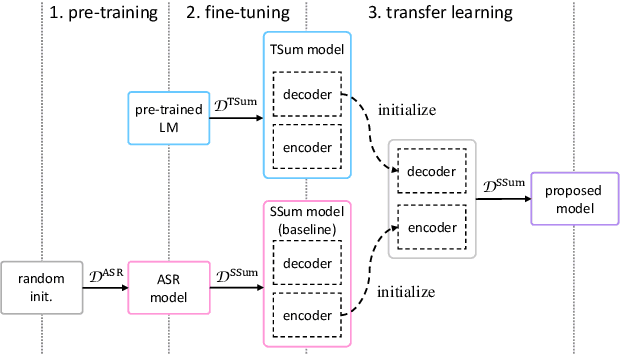
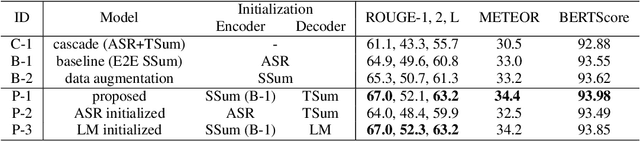
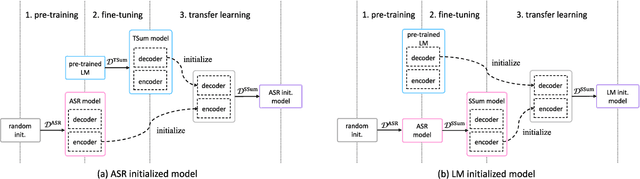

End-to-end speech summarization (E2E SSum) directly summarizes input speech into easy-to-read short sentences with a single model. This approach is promising because it, in contrast to the conventional cascade approach, can utilize full acoustical information and mitigate to the propagation of transcription errors. However, due to the high cost of collecting speech-summary pairs, an E2E SSum model tends to suffer from training data scarcity and output unnatural sentences. To overcome this drawback, we propose for the first time to integrate a pre-trained language model (LM), which is highly capable of generating natural sentences, into the E2E SSum decoder via transfer learning. In addition, to reduce the gap between the independently pre-trained encoder and decoder, we also propose to transfer the baseline E2E SSum encoder instead of the commonly used automatic speech recognition encoder. Experimental results show that the proposed model outperforms baseline and data augmented models.