 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEARBench: A Benchmark for Naturalness Evaluation in Streaming Speech-to-Speech Language Models
Jul 06, 2026Streaming speech-to-speech language models aim to answer spoken queries directly with synthetic speech. However, standard speech and text benchmarks do not capture whether these systems behave naturally in conversations, where timing, turn-taking, prosody, interpersonal stance, language and dialect consistency, and relationship-aware appropriateness jointly shape perceived quality. We introduce SPEARBench, a benchmark for evaluating naturalness in speech-to-speech language models from question-answer interactions. SPEARBench constructs controlled dialogue prompts from the Seamless Interaction corpus, runs inference across multiple models, and evaluates generated answers using a multidimensional protocol that covers response latency, interruptions, speech quality, ASR robustness, language and dialect consistency, emotional naturalness, interpersonal stance, and explainable distributional baselines. The benchmark includes original human answers as a reference condition and reports results for several contemporary models. Results show that current models can achieve high signal-level quality and low ASR error while still differing from human conversational behavior in latency, overlap, dialect preservation, emotional adaptation, and interpersonal stance dynamics.
ProPS: Prompted Profile Synthesis for Natural Language-Conditioned Speaker Embedding Distributions
Jul 06, 2026Speaker embeddings, or x-vectors, are widely used to represent speaker identity and speaker-related attributes, but existing embedding extractors are typically descriptive rather than generative: they map an observed speech segment to an x-vector, which is then used for downstream applications. We introduce ProPS, Prompted Profile Synthesis, a framework for generating distributions of speaker embeddings conditioned on natural language prompts such as "a thirties male speaker with an Indian accent". ProPS converts human-written profile descriptions into sentence embeddings and uses a mixture density network trained on a large-scale dataset to predict a Gaussian mixture model in the x-vector space. The model is trained by maximizing the likelihood that real speaker embeddings match the requested profile, and its generated distributions are evaluated by negative log-likelihood on held-out x-vectors and by attribute classification accuracies on sampled synthetic x-vectors. Experiments show that ProPS produces profile-conditioned distributions and generates x-vectors that preserve requested speaker attributes such as age, gender, accent, and prosodic characteristics. This design enables controllable speaker-profile synthesis for speech generation systems like Text-To-Speech (TTS) or Voice Conversion (VC) while anchoring generated distributions in observed speaker-embedding structure.
TurnNat: Automatic Evaluation of Turn-Taking Naturalness in Dyadic Spoken Dialogue
Jul 01, 2026Turn-taking naturalness is central to full-duplex spoken dialogue systems, yet its automatic evaluation remains limited. Existing evaluations often rely on human judgments or behavior-specific timing metrics, making it difficult to compare heterogeneous timing failures within a unified framework. We propose TurnNat, a likelihood-based framework for automatic turn-taking naturalness evaluation in two-channel spoken dialogue. A causal turn-taking prediction model trained on natural conversations estimates future two-speaker voice-activity states, and the negative log-likelihood (NLL) of the observed future activity measures timing atypicality. TurnNat pools frame-level NLLs over turn-taking boundary units (TBUs) extracted from utterance onsets and offsets, and aggregates mean and tail TBU scores into a dialogue-level naturalness score. We further construct a controlled perturbation benchmark of paired natural and perturbed dialogue clips, validated by human naturalness judgments. Experiments on this benchmark show that TurnNat successfully identifies unnatural turn-taking perturbations across heterogeneous timing failures.
Reference-Based Prosody and Rhythm Evaluation for Spoken Dialogue Systems
Jun 30, 2026Speech-to-speech (S2S) AI agents are advancing rapidly, yet evaluation lacks interpretable speech-native measures for conversational prosody and rhythm. Because $F_0$, speaking rate, articulation rate, and pausing shift with model-predicted speaker traits and interaction state, pooled human statistics can be poorly calibrated for evaluating a particular output. Using 4000+ hours of dyadic English conversation from the Seamless Interaction dataset, we construct matched reference regimes for $F_0$ mean, $F_0$ expressivity, speech rate, articulation rate, pause ratio, and mean pause duration. We then define a percentile-based evaluation protocol: extract the same metrics from an S2S output waveform, compare them to the closest matched human reference stratum, and report percentile deviations or 5th-95th percentile out-of-regime flags. On held-out human rows, pooled references over-flag state-conditioned $F_0$ expressivity and rhythm, while matched references return flag rates closer to the nominal 10% and make deviation direction interpretable. These outputs serve as behavioral plausibility checks that complement, rather than replace, perceptual and user-centered evaluation.
Speaker Verification with Speech-Aware LLMs: Evaluation and Augmentation
Mar 11, 2026Speech-aware large language models (LLMs) can accept speech inputs, yet their training objectives largely emphasize linguistic content or specific fields such as emotions or the speaker's gender, leaving it unclear whether they encode speaker identity. First, we propose a model-agnostic scoring protocol that produces continuous verification scores for both API-only and open-weight models, using confidence scores or log-likelihood ratios from the Yes/No token probabilities. Using this protocol, we benchmark recent speech-aware LLMs and observe weak speaker discrimination (EERs above 20% on VoxCeleb1). Second, we introduce a lightweight augmentation that equips an LLM with ASV capability by injecting frozen ECAPA-TDNN speaker embeddings through a learned projection and training only LoRA adapters. On TinyLLaMA-1.1B, the resulting ECAPA-LLM achieves 1.03% EER on VoxCeleb1-E, approaching a dedicated speaker verification system while preserving a natural-language interface.
Spoken DialogSum: An Emotion-Rich Conversational Dataset for Spoken Dialogue Summarization
Dec 17, 2025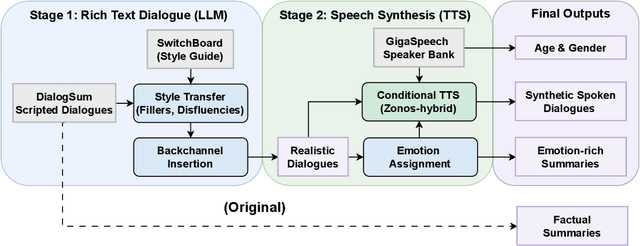

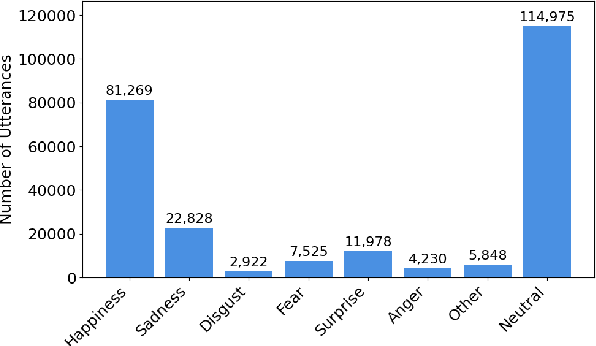
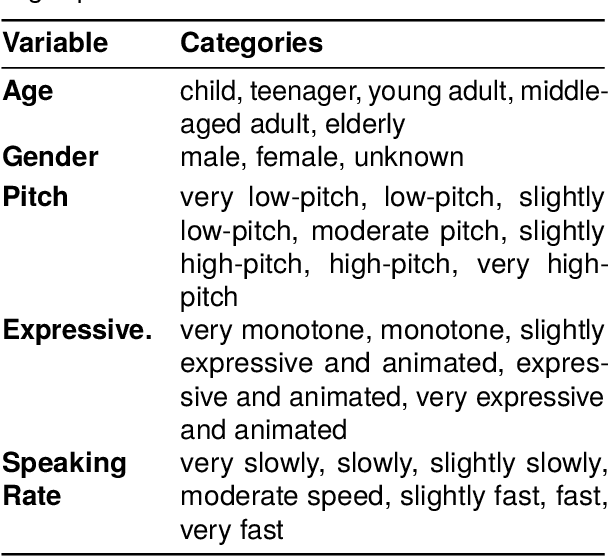
Recent audio language models can follow long conversations. However, research on emotion-aware or spoken dialogue summarization is constrained by the lack of data that links speech, summaries, and paralinguistic cues. We introduce Spoken DialogSum, the first corpus aligning raw conversational audio with factual summaries, emotion-rich summaries, and utterance-level labels for speaker age, gender, and emotion. The dataset is built in two stages: first, an LLM rewrites DialogSum scripts with Switchboard-style fillers and back-channels, then tags each utterance with emotion, pitch, and speaking rate. Second, an expressive TTS engine synthesizes speech from the tagged scripts, aligned with paralinguistic labels. Spoken DialogSum comprises 13,460 emotion-diverse dialogues, each paired with both a factual and an emotion-focused summary. We release an online demo at https://fatfat-emosum.github.io/EmoDialog-Sum-Audio-Samples/, with plans to release the full dataset in the near future. Baselines show that an Audio-LLM raises emotional-summary ROUGE-L by 28% relative to a cascaded ASR-LLM system, confirming the value of end-to-end speech modeling.
Vox-Profile: A Speech Foundation Model Benchmark for Characterizing Diverse Speaker and Speech Traits
May 20, 2025We introduce Vox-Profile, a comprehensive benchmark to characterize rich speaker and speech traits using speech foundation models. Unlike existing works that focus on a single dimension of speaker traits, Vox-Profile provides holistic and multi-dimensional profiles that reflect both static speaker traits (e.g., age, sex, accent) and dynamic speech properties (e.g., emotion, speech flow). This benchmark is grounded in speech science and linguistics, developed with domain experts to accurately index speaker and speech characteristics. We report benchmark experiments using over 15 publicly available speech datasets and several widely used speech foundation models that target various static and dynamic speaker and speech properties. In addition to benchmark experiments, we showcase several downstream applications supported by Vox-Profile. First, we show that Vox-Profile can augment existing speech recognition datasets to analyze ASR performance variability. Vox-Profile is also used as a tool to evaluate the performance of speech generation systems. Finally, we assess the quality of our automated profiles through comparison with human evaluation and show convergent validity. Vox-Profile is publicly available at: https://github.com/tiantiaf0627/vox-profile-release.
Automatic Proficiency Assessment in L2 English Learners
May 05, 2025Second language proficiency (L2) in English is usually perceptually evaluated by English teachers or expert evaluators, with the inherent intra- and inter-rater variability. This paper explores deep learning techniques for comprehensive L2 proficiency assessment, addressing both the speech signal and its correspondent transcription. We analyze spoken proficiency classification prediction using diverse architectures, including 2D CNN, frequency-based CNN, ResNet, and a pretrained wav2vec 2.0 model. Additionally, we examine text-based proficiency assessment by fine-tuning a BERT language model within resource constraints. Finally, we tackle the complex task of spontaneous dialogue assessment, managing long-form audio and speaker interactions through separate applications of wav2vec 2.0 and BERT models. Results from experiments on EFCamDat and ANGLISH datasets and a private dataset highlight the potential of deep learning, especially the pretrained wav2vec 2.0 model, for robust automated L2 proficiency evaluation.
Detecting Neurodegenerative Diseases using Frame-Level Handwriting Embeddings
Feb 10, 2025In this study, we explored the use of spectrograms to represent handwriting signals for assessing neurodegenerative diseases, including 42 healthy controls (CTL), 35 subjects with Parkinson's Disease (PD), 21 with Alzheimer's Disease (AD), and 15 with Parkinson's Disease Mimics (PDM). We applied CNN and CNN-BLSTM models for binary classification using both multi-channel fixed-size and frame-based spectrograms. Our results showed that handwriting tasks and spectrogram channel combinations significantly impacted classification performance. The highest F1-score (89.8%) was achieved for AD vs. CTL, while PD vs. CTL reached 74.5%, and PD vs. PDM scored 77.97%. CNN consistently outperformed CNN-BLSTM. Different sliding window lengths were tested for constructing frame-based spectrograms. A 1-second window worked best for AD, longer windows improved PD classification, and window length had little effect on PD vs. PDM.
CA-SSLR: Condition-Aware Self-Supervised Learning Representation for Generalized Speech Processing
Dec 05, 2024We introduce Condition-Aware Self-Supervised Learning Representation (CA-SSLR), a generalist conditioning model broadly applicable to various speech-processing tasks. Compared to standard fine-tuning methods that optimize for downstream models, CA-SSLR integrates language and speaker embeddings from earlier layers, making the SSL model aware of the current language and speaker context. This approach reduces the reliance on input audio features while preserving the integrity of the base SSLR. CA-SSLR improves the model's capabilities and demonstrates its generality on unseen tasks with minimal task-specific tuning. Our method employs linear modulation to dynamically adjust internal representations, enabling fine-grained adaptability without significantly altering the original model behavior. Experiments show that CA-SSLR reduces the number of trainable parameters, mitigates overfitting, and excels in under-resourced and unseen tasks. Specifically, CA-SSLR achieves a 10% relative reduction in LID errors, a 37% improvement in ASR CER on the ML-SUPERB benchmark, and a 27% decrease in SV EER on VoxCeleb-1, demonstrating its effectiveness.