 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
LongFNT: Long-form Speech Recognition with Factorized Neural Transducer
Nov 17, 2022
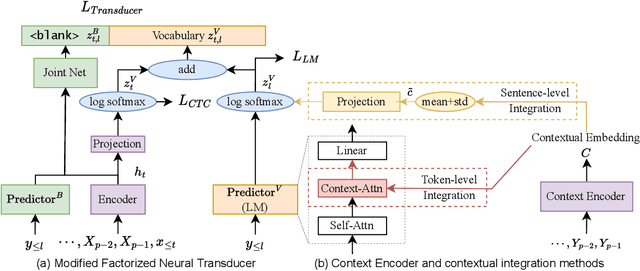
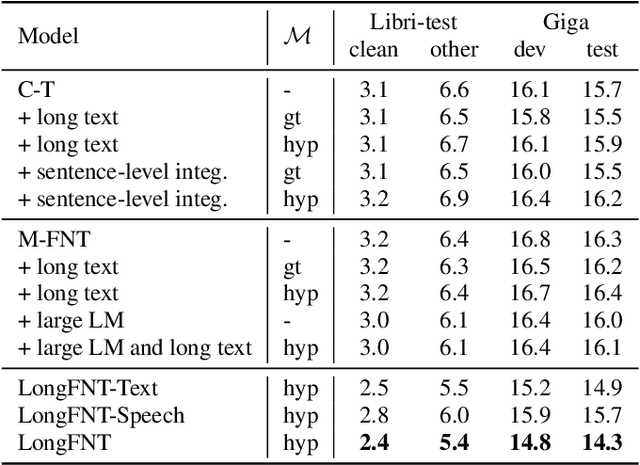
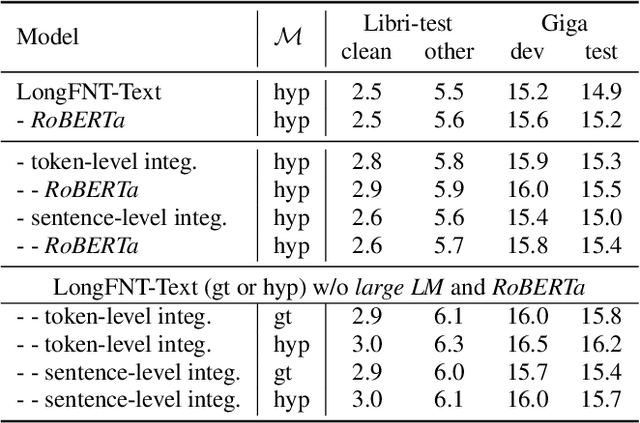

Traditional automatic speech recognition~(ASR) systems usually focus on individual utterances, without considering long-form speech with useful historical information, which is more practical in real scenarios. Simply attending longer transcription history for a vanilla neural transducer model shows no much gain in our preliminary experiments, since the prediction network is not a pure language model. This motivates us to leverage the factorized neural transducer structure, containing a real language model, the vocabulary predictor. We propose the {LongFNT-Text} architecture, which fuses the sentence-level long-form features directly with the output of the vocabulary predictor and then embeds token-level long-form features inside the vocabulary predictor, with a pre-trained contextual encoder RoBERTa to further boost the performance. Moreover, we propose the {LongFNT} architecture by extending the long-form speech to the original speech input and achieve the best performance. The effectiveness of our LongFNT approach is validated on LibriSpeech and GigaSpeech corpora with 19% and 12% relative word error rate~(WER) reduction, respectively.
LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT
Jul 07, 2023

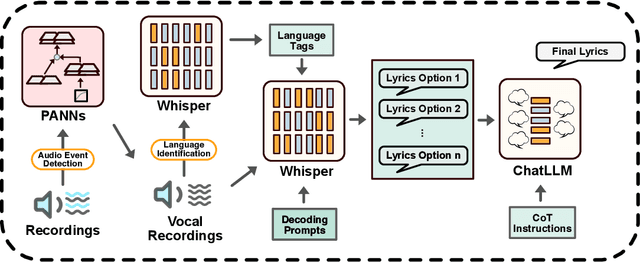
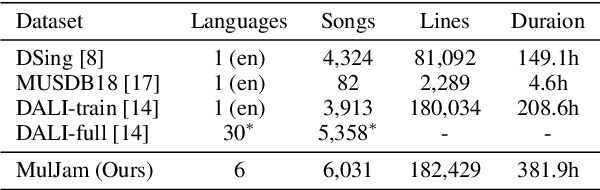
We introduce LyricWhiz, a robust, multilingual, and zero-shot automatic lyrics transcription method achieving state-of-the-art performance on various lyrics transcription datasets, even in challenging genres such as rock and metal. Our novel, training-free approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, today's most performant chat-based large language model. In the proposed method, Whisper functions as the "ear" by transcribing the audio, while GPT-4 serves as the "brain," acting as an annotator with a strong performance for contextualized output selection and correction. Our experiments show that LyricWhiz significantly reduces Word Error Rate compared to existing methods in English and can effectively transcribe lyrics across multiple languages. Furthermore, we use LyricWhiz to create the first publicly available, large-scale, multilingual lyrics transcription dataset with a CC-BY-NC-SA copyright license, based on MTG-Jamendo, and offer a human-annotated subset for noise level estimation and evaluation. We anticipate that our proposed method and dataset will advance the development of multilingual lyrics transcription, a challenging and emerging task.
Speech-dependent Modeling of Own Voice Transfer Characteristics for In-ear Microphones in Hearables
Sep 15, 2023Many hearables contain an in-ear microphone, which may be used to capture the own voice of its user in noisy environments. Since the in-ear microphone mostly records body-conducted speech due to ear canal occlusion, it suffers from band-limitation effects while only capturing a limited amount of external noise. To enhance the quality of the in-ear microphone signal using algorithms aiming at joint bandwidth extension, equalization, and noise reduction, it is desirable to have an accurate model of the own voice transfer characteristics between the entrance of the ear canal and the in-ear microphone. Such a model can be used, e.g., to simulate a large amount of in-ear recordings to train supervised learning-based algorithms. Since previous research on ear canal occlusion suggests that own voice transfer characteristics depend on speech content, in this contribution we propose a speech-dependent system identification model based on phoneme recognition. We assess the accuracy of simulating own voice speech by speech-dependent and speech-independent modeling and investigate how well modeling approaches are able to generalize to different talkers. Simulation results show that using the proposed speech-dependent model is preferable for simulating in-ear recordings compared to using a speech-independent model.
End-to-End Integration of Speech Recognition, Speech Enhancement, and Self-Supervised Learning Representation
Apr 01, 2022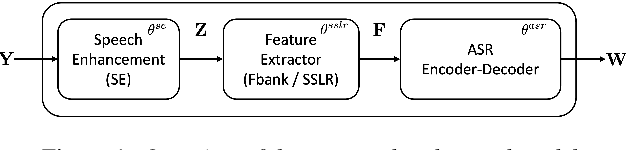
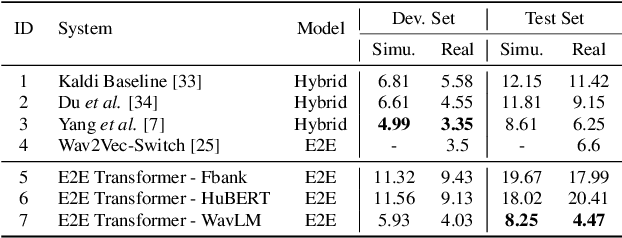
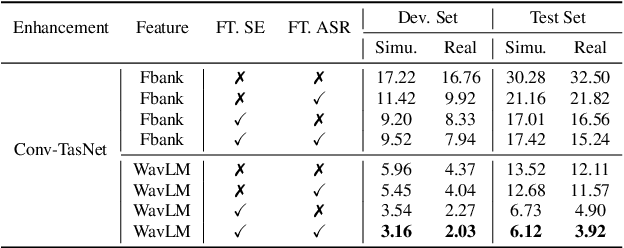
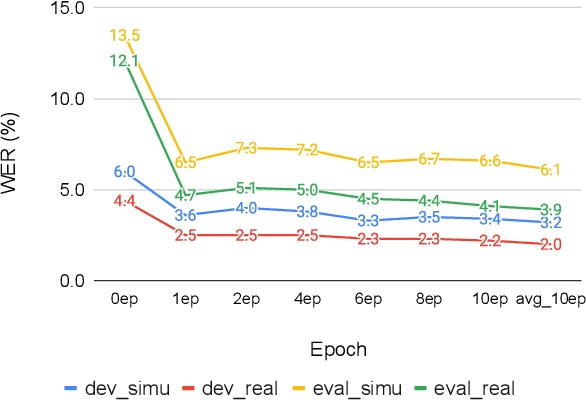
This work presents our end-to-end (E2E) automatic speech recognition (ASR) model targetting at robust speech recognition, called Integraded speech Recognition with enhanced speech Input for Self-supervised learning representation (IRIS). Compared with conventional E2E ASR models, the proposed E2E model integrates two important modules including a speech enhancement (SE) module and a self-supervised learning representation (SSLR) module. The SE module enhances the noisy speech. Then the SSLR module extracts features from enhanced speech to be used for speech recognition (ASR). To train the proposed model, we establish an efficient learning scheme. Evaluation results on the monaural CHiME-4 task show that the IRIS model achieves the best performance reported in the literature for the single-channel CHiME-4 benchmark (2.0% for the real development and 3.9% for the real test) thanks to the powerful pre-trained SSLR module and the fine-tuned SE module.
Don't Stop Self-Supervision: Accent Adaptation of Speech Representations via Residual Adapters
Jul 02, 2023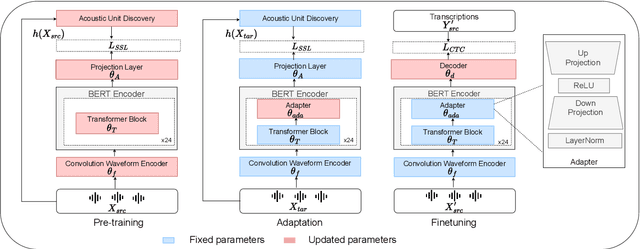
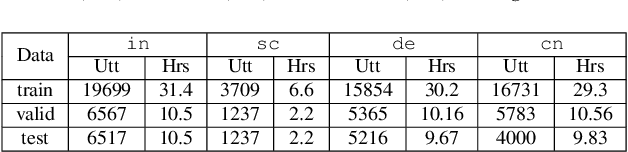
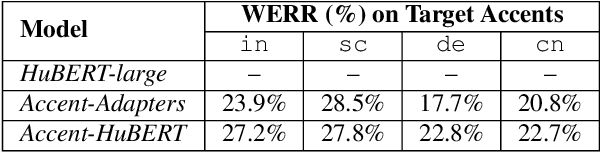
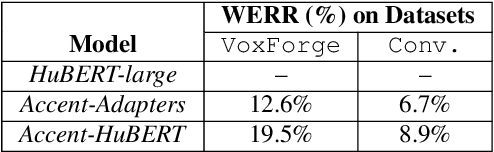
Speech representations learned in a self-supervised fashion from massive unlabeled speech corpora have been adapted successfully toward several downstream tasks. However, such representations may be skewed toward canonical data characteristics of such corpora and perform poorly on atypical, non-native accented speaker populations. With the state-of-the-art HuBERT model as a baseline, we propose and investigate self-supervised adaptation of speech representations to such populations in a parameter-efficient way via training accent-specific residual adapters. We experiment with 4 accents and choose automatic speech recognition (ASR) as the downstream task of interest. We obtain strong word error rate reductions (WERR) over HuBERT-large for all 4 accents, with a mean WERR of 22.7% with accent-specific adapters and a mean WERR of 25.1% if the entire encoder is accent-adapted. While our experiments utilize HuBERT and ASR as the downstream task, our proposed approach is both model and task-agnostic.
FOOCTTS: Generating Arabic Speech with Acoustic Environment for Football Commentator
Jun 07, 2023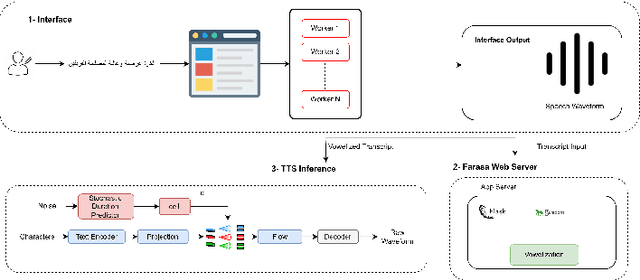
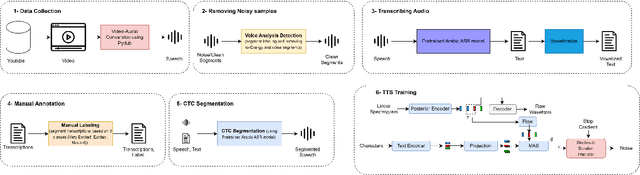
This paper presents FOOCTTS, an automatic pipeline for a football commentator that generates speech with background crowd noise. The application gets the text from the user, applies text pre-processing such as vowelization, followed by the commentator's speech synthesizer. Our pipeline included Arabic automatic speech recognition for data labeling, CTC segmentation, transcription vowelization to match speech, and fine-tuning the TTS. Our system is capable of generating speech with its acoustic environment within limited 15 minutes of football commentator recording. Our prototype is generalizable and can be easily applied to different domains and languages.
Accented Speech Recognition: Benchmarking, Pre-training, and Diverse Data
May 16, 2022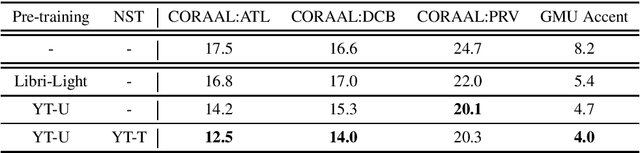

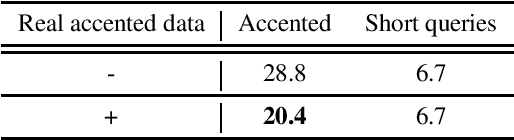
Building inclusive speech recognition systems is a crucial step towards developing technologies that speakers of all language varieties can use. Therefore, ASR systems must work for everybody independently of the way they speak. To accomplish this goal, there should be available data sets representing language varieties, and also an understanding of model configuration that is the most helpful in achieving robust understanding of all types of speech. However, there are not enough data sets for accented speech, and for the ones that are already available, more training approaches need to be explored to improve the quality of accented speech recognition. In this paper, we discuss recent progress towards developing more inclusive ASR systems, namely, the importance of building new data sets representing linguistic diversity, and exploring novel training approaches to improve performance for all users. We address recent directions within benchmarking ASR systems for accented speech, measure the effects of wav2vec 2.0 pre-training on accented speech recognition, and highlight corpora relevant for diverse ASR evaluations.
Adaptive Multi-Corpora Language Model Training for Speech Recognition
Nov 09, 2022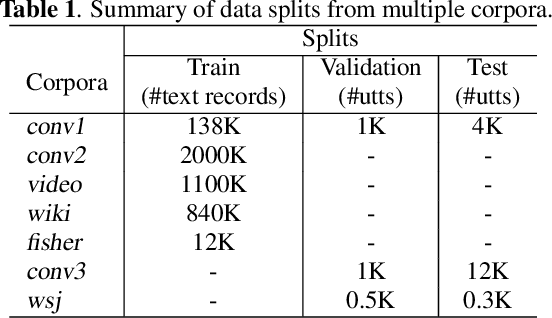
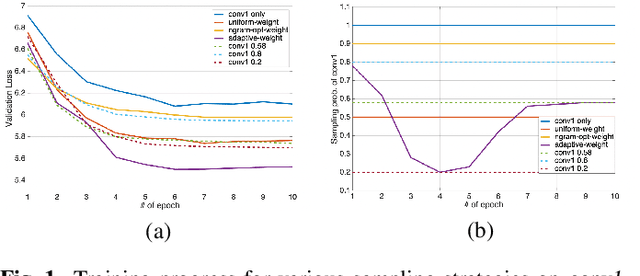
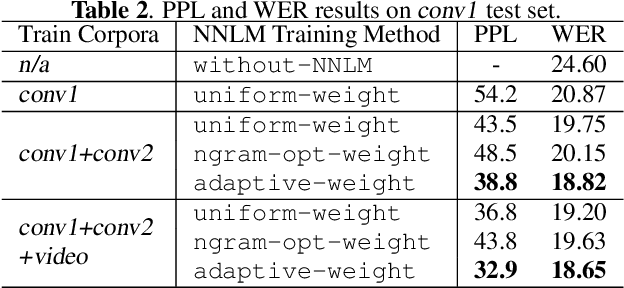

Neural network language model (NNLM) plays an essential role in automatic speech recognition (ASR) systems, especially in adaptation tasks when text-only data is available. In practice, an NNLM is typically trained on a combination of data sampled from multiple corpora. Thus, the data sampling strategy is important to the adaptation performance. Most existing works focus on designing static sampling strategies. However, each corpus may show varying impacts at different NNLM training stages. In this paper, we introduce a novel adaptive multi-corpora training algorithm that dynamically learns and adjusts the sampling probability of each corpus along the training process. The algorithm is robust to corpora sizes and domain relevance. Compared with static sampling strategy baselines, the proposed approach yields remarkable improvement by achieving up to relative 7% and 9% word error rate (WER) reductions on in-domain and out-of-domain adaptation tasks, respectively.
Continual Learning for End-to-End ASR by Averaging Domain Experts
May 12, 2023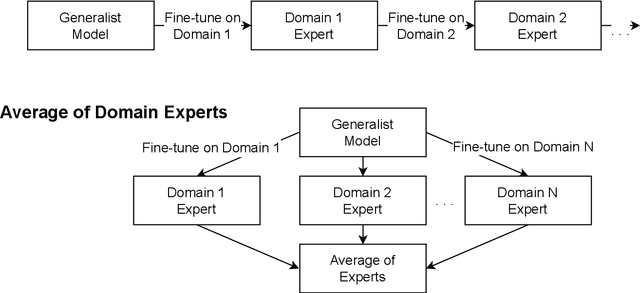
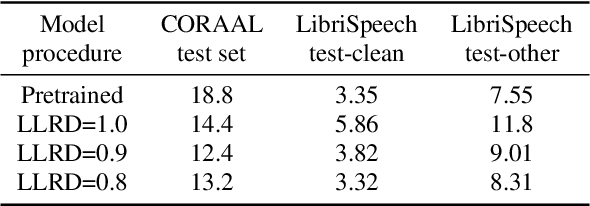
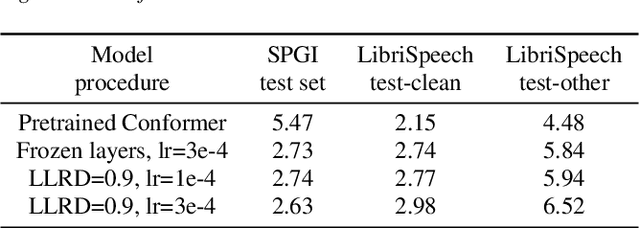
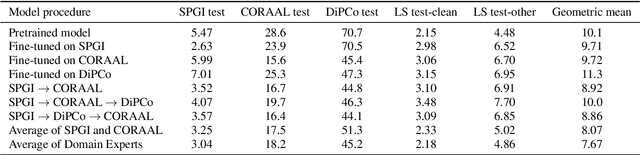
Continual learning for end-to-end automatic speech recognition has to contend with a number of difficulties. Fine-tuning strategies tend to lose performance on data already seen, a process known as catastrophic forgetting. On the other hand, strategies that freeze parameters and append tunable parameters must maintain multiple models. We suggest a strategy that maintains only a single model for inference and avoids catastrophic forgetting. Our experiments show that a simple linear interpolation of several models' parameters, each fine-tuned from the same generalist model, results in a single model that performs well on all tested data. For our experiments we selected two open-source end-to-end speech recognition models pre-trained on large datasets and fine-tuned them on 3 separate datasets: SGPISpeech, CORAAL, and DiPCo. The proposed average of domain experts model performs well on all tested data, and has almost no loss in performance on data from the domain of original training.
Towards the Transferable Audio Adversarial Attack via Ensemble Methods
Apr 18, 2023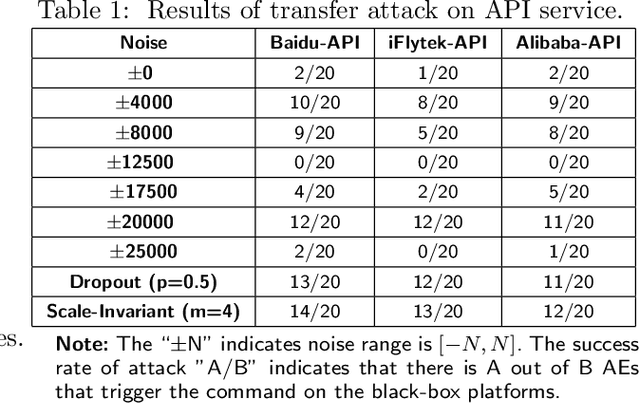
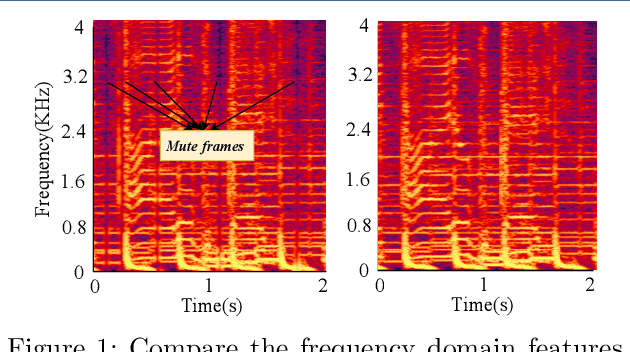
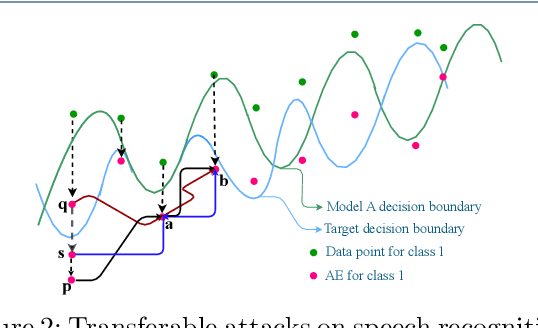
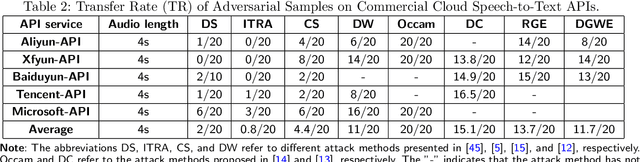
In recent years, deep learning (DL) models have achieved significant progress in many domains, such as autonomous driving, facial recognition, and speech recognition. However, the vulnerability of deep learning models to adversarial attacks has raised serious concerns in the community because of their insufficient robustness and generalization. Also, transferable attacks have become a prominent method for black-box attacks. In this work, we explore the potential factors that impact adversarial examples (AEs) transferability in DL-based speech recognition. We also discuss the vulnerability of different DL systems and the irregular nature of decision boundaries. Our results show a remarkable difference in the transferability of AEs between speech and images, with the data relevance being low in images but opposite in speech recognition. Motivated by dropout-based ensemble approaches, we propose random gradient ensembles and dynamic gradient-weighted ensembles, and we evaluate the impact of ensembles on the transferability of AEs. The results show that the AEs created by both approaches are valid for transfer to the black box API.