 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving acoustic drone detection generalization through pretraining and data augmentation
May 29, 2026Detecting unauthorized UAV flights is critical for surveillance, security, and airspace management. Acoustic drone detection, which relies on the distinctive propeller and motor sounds of UAVs, provides a low-cost, passive solution that requires no line of sight. A central challenge is generalization: reliably distinguishing drone signatures from ambient noise across unseen recording setups, environments, and UAV types (out-of-domain). Inspired by advances in large-scale audio pretraining, we develop a compact DNN-based detector and improve its generalization by (1) pretraining the model for broad sound-event classification before fine-tuning on diverse in-house and public drone recordings, and (2) applying on-the-fly augmentations (pitch shifting, noise mixing, microphone transfer function simulation, spectrogram augmentation) to expose the model to varied acoustic conditions. An ablation study quantifies the impact of each augmentation. For evaluation, we set target false-positive rates (FPR) aligned with real-world surveillance needs and report true-positive rates (TPR) on both in-domain data (public IDMT Berne 2022) and out-of-domain data (public AuDroK). Our results show that pretraining is the dominant factor for robust detection, yielding substantial TPR improvements over training from scratch on all benchmarks. The full augmentation chain provides additional gains on acoustically mismatched out-of-domain data, achieving the best mean TPR on the AuDroK subsets and the largest improvements on the most challenging scenarios. We further validate real-world applicability by measuring false positives on public non-drone corpora (IDMT-TRAFFIC and ESC-50), demonstrating equally low FPR on unfamiliar backgrounds. A distance-dependent analysis on IDMT Berne 2022 shows effective detection at distances up to 150 m.
Low-Complexity Own Voice Reconstruction for Hearables with an In-Ear Microphone
Sep 09, 2024



Hearable devices, equipped with one or more microphones, are commonly used for speech communication. Here, we consider the scenario where a hearable is used to capture the user's own voice in a noisy environment. In this scenario, own voice reconstruction (OVR) is essential for enhancing the quality and intelligibility of the recorded noisy own voice signals. In previous work, we developed a deep learning-based OVR system, aiming to reduce the amount of device-specific recordings for training by using data augmentation with phoneme-dependent models of own voice transfer characteristics. Given the limited computational resources available on hearables, in this paper we propose low-complexity variants of an OVR system based on the FT-JNF architecture and investigate the required amount of device-specific recordings for effective data augmentation and fine-tuning. Simulation results show that the proposed OVR system considerably improves speech quality, even under constraints of low complexity and a limited amount of device-specific recordings.
Speech-dependent Data Augmentation for Own Voice Reconstruction with Hearable Microphones in Noisy Environments
May 19, 2024Own voice pickup for hearables in noisy environments benefits from using both an outer and an in-ear microphone outside and inside the occluded ear. Due to environmental noise recorded at both microphones, and amplification of the own voice at low frequencies and band-limitation at the in-ear microphone, an own voice reconstruction system is needed to enable communication. A large amount of own voice signals is required to train a supervised deep learning-based own voice reconstruction system. Training data can either be obtained by recording a large amount of own voice signals of different talkers with a specific device, which is costly, or through augmentation of available speech data. Own voice signals can be simulated by assuming a linear time-invariant relative transfer function between hearable microphones for each phoneme, referred to as own voice transfer characteristics. In this paper, we propose data augmentation techniques for training an own voice reconstruction system based on speech-dependent models of own voice transfer characteristics between hearable microphones. The proposed techniques use few recorded own voice signals to estimate transfer characteristics and can then be used to simulate a large amount of own voice signals based on single-channel speech signals. Experimental results show that the proposed speech-dependent individual data augmentation technique leads to better performance compared to other data augmentation techniques or compared to training only on the available recorded own voice signals, and additional fine-tuning on the available recorded signals can improve performance further.
Multi-Microphone Noise Data Augmentation for DNN-based Own Voice Reconstruction for Hearables in Noisy Environments
Dec 14, 2023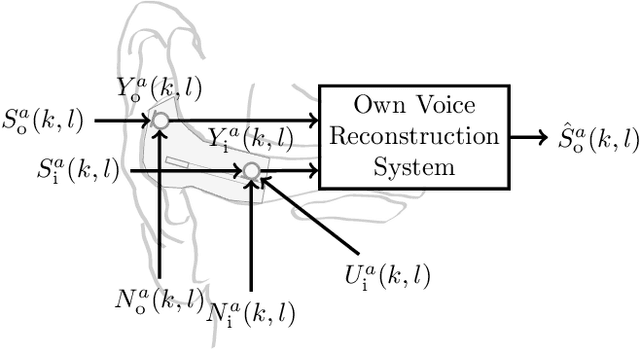
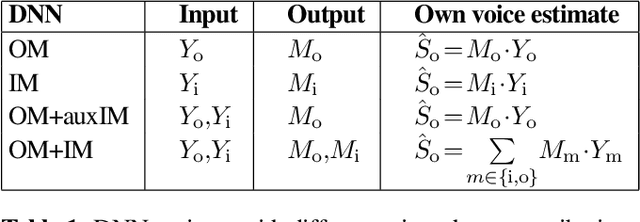
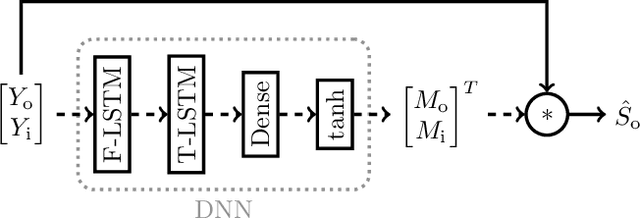
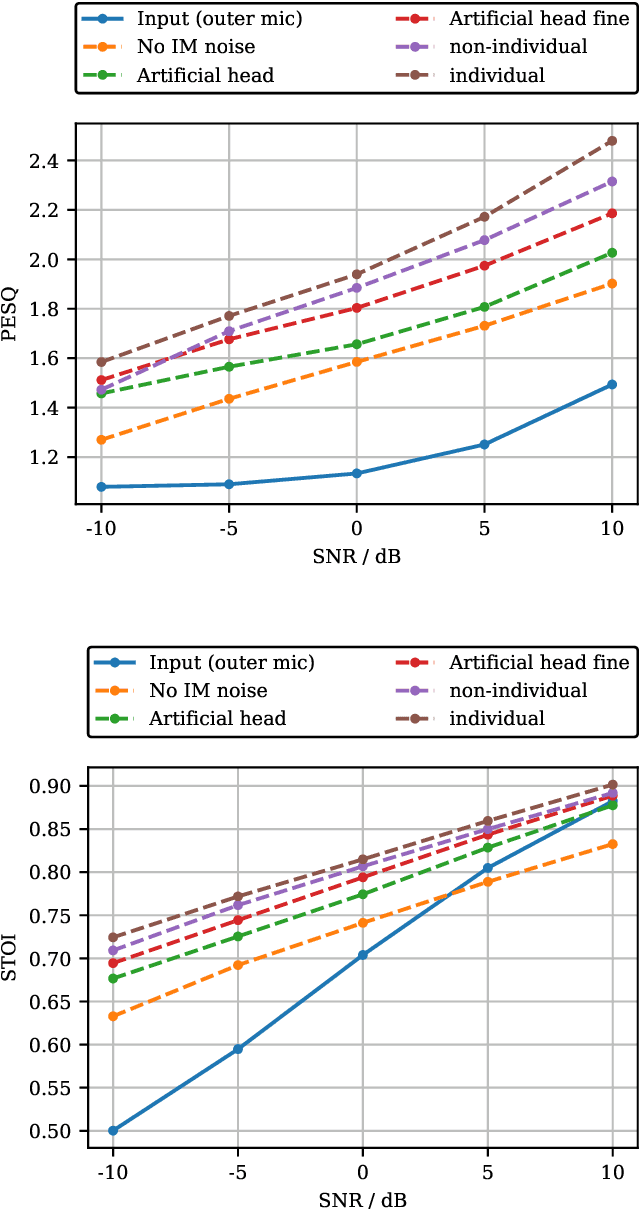
Hearables with integrated microphones may offer communication benefits in noisy working environments, e.g. by transmitting the recorded own voice of the user. Systems aiming at reconstructing the clean and full-bandwidth own voice from noisy microphone recordings are often based on supervised learning. Recording a sufficient amount of noise required for training such a system is costly since noise transmission between outer and inner microphones varies individually. Previously proposed methods either do not consider noise, only consider noise at outer microphones or assume inner and outer microphone noise to be independent during training, and it is not yet clear whether individualized noise can benefit the training of and own voice reconstruction system. In this paper, we investigate several noise data augmentation techniques based on measured transfer functions to simulate multi-microphone noise. Using augmented noise, we train a multi-channel own voice reconstruction system. Experiments using real noise are carried out to investigate the generalization capability. Results show that incorporating augmented noise yields large benefits, in particular considering individualized noise augmentation leads to higher performance.
Modeling of Speech-dependent Own Voice Transfer Characteristics for Hearables with In-ear Microphones
Oct 10, 2023



Hearables often contain an in-ear microphone, which may be used to capture the own voice of its user. However, due to ear canal occlusion the in-ear microphone mostly records body-conducted speech, which suffers from band-limitation effects and is subject to amplification of low frequency content. These transfer characteristics are assumed to vary both based on speech content and between individual talkers. It is desirable to have an accurate model of the own voice transfer characteristics between hearable microphones. Such a model can be used, e.g., to simulate a large amount of in-ear recordings to train supervised learning-based algorithms aiming at compensating own voice transfer characteristics. In this paper we propose a speech-dependent system identification model based on phoneme recognition. Using recordings from a prototype hearable, the modeling accuracy is evaluated in terms of technical measures. We investigate robustness of transfer characteristic models to utterance or talker mismatch. Simulation results show that using the proposed speech-dependent model is preferable for simulating in-ear recordings compared to a speech-independent model. The proposed model is able to generalize better to new utterances than an adaptive filtering-based model. Additionally, we find that talker-averaged models generalize better to different talkers than individual models.
Speech-dependent Modeling of Own Voice Transfer Characteristics for In-ear Microphones in Hearables
Sep 15, 2023



Many hearables contain an in-ear microphone, which may be used to capture the own voice of its user in noisy environments. Since the in-ear microphone mostly records body-conducted speech due to ear canal occlusion, it suffers from band-limitation effects while only capturing a limited amount of external noise. To enhance the quality of the in-ear microphone signal using algorithms aiming at joint bandwidth extension, equalization, and noise reduction, it is desirable to have an accurate model of the own voice transfer characteristics between the entrance of the ear canal and the in-ear microphone. Such a model can be used, e.g., to simulate a large amount of in-ear recordings to train supervised learning-based algorithms. Since previous research on ear canal occlusion suggests that own voice transfer characteristics depend on speech content, in this contribution we propose a speech-dependent system identification model based on phoneme recognition. We assess the accuracy of simulating own voice speech by speech-dependent and speech-independent modeling and investigate how well modeling approaches are able to generalize to different talkers. Simulation results show that using the proposed speech-dependent model is preferable for simulating in-ear recordings compared to using a speech-independent model.
Multilingual Query-by-Example Keyword Spotting with Metric Learning and Phoneme-to-Embedding Mapping
Apr 19, 2023



In this paper, we propose a multilingual query-by-example keyword spotting (KWS) system based on a residual neural network. The model is trained as a classifier on a multilingual keyword dataset extracted from Common Voice sentences and fine-tuned using circle loss. We demonstrate the generalization ability of the model to new languages and report a mean reduction in EER of 59.2 % for previously seen and 47.9 % for unseen languages compared to a competitive baseline. We show that the word embeddings learned by the KWS model can be accurately predicted from the phoneme sequences using a simple LSTM model. Our system achieves a promising accuracy for streaming keyword spotting and keyword search on Common Voice audio using just 5 examples per keyword. Experiments on the Hey-Snips dataset show a good performance with a false negative rate of 5.4 % at only 0.1 false alarms per hour.
Speaker-conditioning Single-channel Target Speaker Extraction using Conformer-based Architectures
May 27, 2022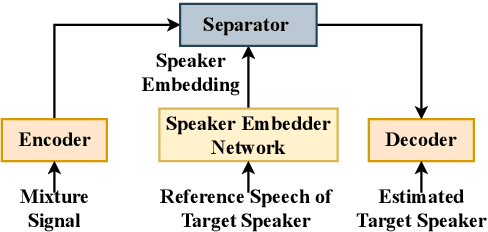
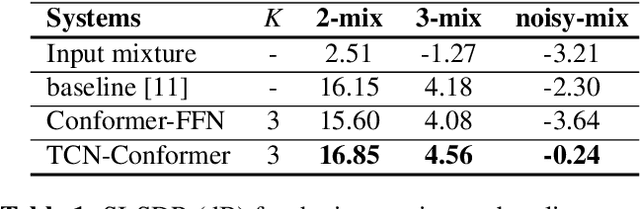
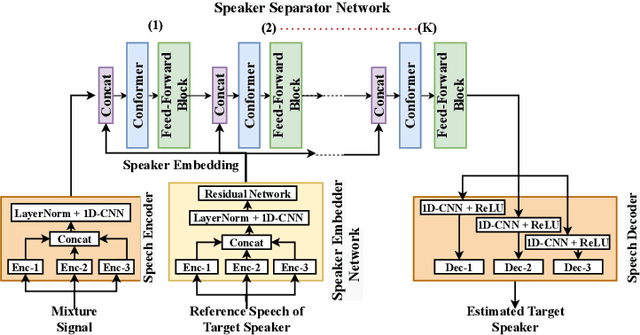
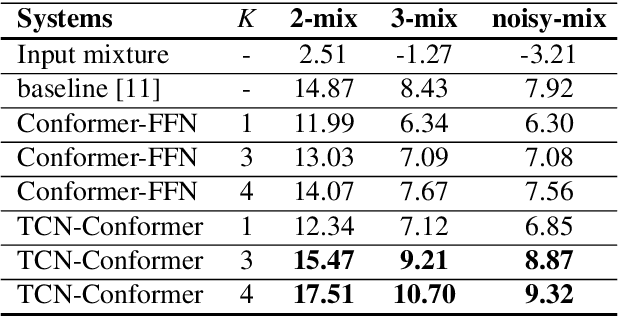
Target speaker extraction aims at extracting the target speaker from a mixture of multiple speakers exploiting auxiliary information about the target speaker. In this paper, we consider a complete time-domain target speaker extraction system consisting of a speaker embedder network and a speaker separator network which are jointly trained in an end-to-end learning process. We propose two different architectures for the speaker separator network which are based on the convolutional augmented transformer (conformer). The first architecture uses stacks of conformer and external feed-forward blocks (Conformer-FFN), while the second architecture uses stacks of temporal convolutional network (TCN) and conformer blocks (TCN-Conformer). Experimental results for 2-speaker mixtures, 3-speaker mixtures, and noisy mixtures of 2-speakers show that among the proposed separator networks, the TCN-Conformer significantly improves the target speaker extraction performance compared to the Conformer-FFN and a TCN-based baseline system.
Training Strategies for Own Voice Reconstruction in Hearing Protection Devices using an In-ear Microphone
May 12, 2022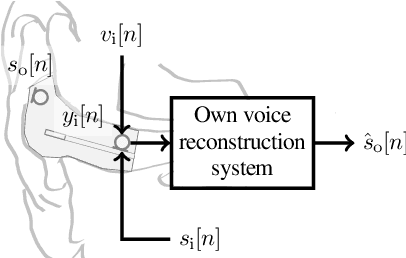
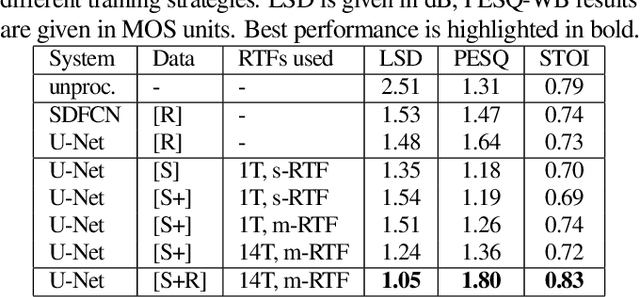
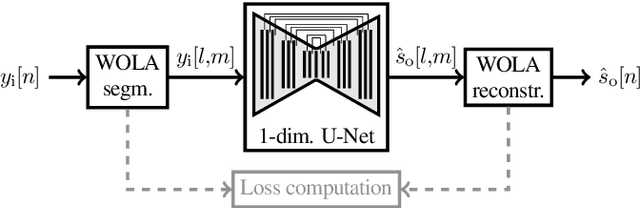
In-ear microphones in hearing protection devices can be utilized to capture the own voice speech of the person wearing the devices in noisy environments. Since in-ear recordings of the own voice are typically band-limited, an own voice reconstruction system is required to recover clean broadband speech from the in-ear signals. However, the availability of speech data for this scenario is typically limited due to device-specific transfer characteristics and the need to collect data from in-situ measurements. In this paper, we apply a deep learning-based bandwidth-extension system to the own voice reconstruction task and investigate different training strategies in order to overcome the limited availability of training data. Experimental results indicate that the use of simulated training data based on recordings of several talkers in combination with a fine-tuning approach using real data is advantageous compared to directly training on a small real dataset.
Speaker-conditioned Target Speaker Extraction based on Customized LSTM Cells
Apr 09, 2021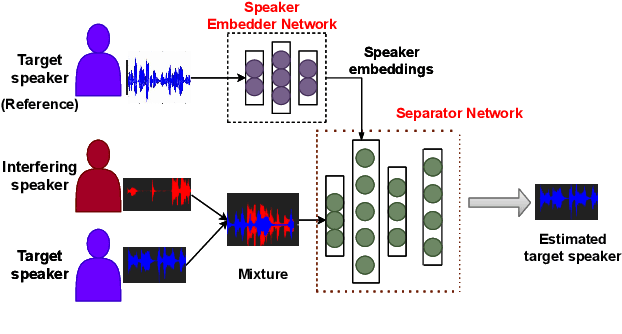
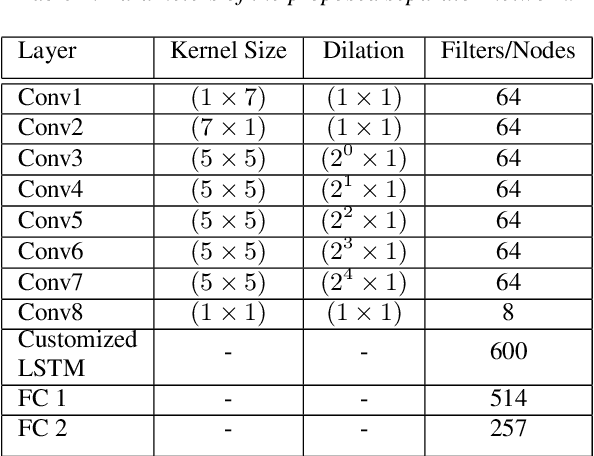
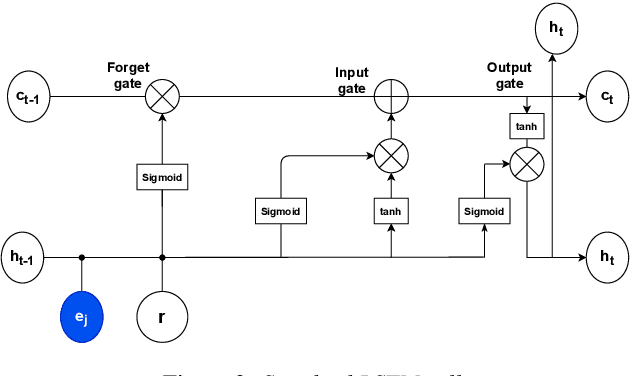
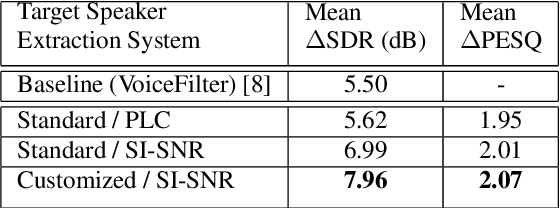
Speaker-conditioned target speaker extraction systems rely on auxiliary information about the target speaker to extract the target speaker signal from a mixture of multiple speakers. Typically, a deep neural network is applied to isolate the relevant target speaker characteristics. In this paper, we focus on a single-channel target speaker extraction system based on a CNN-LSTM separator network and a speaker embedder network requiring reference speech of the target speaker. In the LSTM layer of the separator network, we propose to customize the LSTM cells in order to only remember the specific voice patterns corresponding to the target speaker by modifying the information processing in the forget gate. Experimental results for two-speaker mixtures using the Librispeech dataset show that this customization significantly improves the target speaker extraction performance compared to using standard LSTM cells.