 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLV-CTC: Non-autoregressive ASR with CTC and latent variable models
Mar 28, 2024Non-autoregressive (NAR) models for automatic speech recognition (ASR) aim to achieve high accuracy and fast inference by simplifying the autoregressive (AR) generation process of conventional models. Connectionist temporal classification (CTC) is one of the key techniques used in NAR ASR models. In this paper, we propose a new model combining CTC and a latent variable model, which is one of the state-of-the-art models in the neural machine translation research field. A new neural network architecture and formulation specialized for ASR application are introduced. In the proposed model, CTC alignment is assumed to be dependent on the latent variables that are expected to capture dependencies between tokens. Experimental results on a 100 hours subset of Librispeech corpus showed the best recognition accuracy among CTC-based NAR models. On the TED-LIUM2 corpus, the best recognition accuracy is achieved including AR E2E models with faster inference speed.
HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model
Oct 06, 2023Recently, the usefulness of self-supervised representation learning (SSRL) methods has been confirmed in various downstream tasks. Many of these models, as exemplified by HuBERT and WavLM, use pseudo-labels generated from spectral features or the model's own representation features. From previous studies, it is known that the pseudo-labels contain semantic information. However, the masked prediction task, the learning criterion of HuBERT, focuses on local contextual information and may not make effective use of global semantic information such as speaker, theme of speech, and so on. In this paper, we propose a new approach to enrich the semantic representation of HuBERT. We apply topic model to pseudo-labels to generate a topic label for each utterance. An auxiliary topic classification task is added to HuBERT by using topic labels as teachers. This allows additional global semantic information to be incorporated in an unsupervised manner. Experimental results demonstrate that our method achieves comparable or better performance than the baseline in most tasks, including automatic speech recognition and five out of the eight SUPERB tasks. Moreover, we find that topic labels include various information about utterance, such as gender, speaker, and its theme. This highlights the effectiveness of our approach in capturing multifaceted semantic nuances.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023



Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
Cross-Modal Multi-Tasking for Speech-to-Text Translation via Hard Parameter Sharing
Sep 27, 2023



Recent works in end-to-end speech-to-text translation (ST) have proposed multi-tasking methods with soft parameter sharing which leverage machine translation (MT) data via secondary encoders that map text inputs to an eventual cross-modal representation. In this work, we instead propose a ST/MT multi-tasking framework with hard parameter sharing in which all model parameters are shared cross-modally. Our method reduces the speech-text modality gap via a pre-processing stage which converts speech and text inputs into two discrete token sequences of similar length -- this allows models to indiscriminately process both modalities simply using a joint vocabulary. With experiments on MuST-C, we demonstrate that our multi-tasking framework improves attentional encoder-decoder, Connectionist Temporal Classification (CTC), transducer, and joint CTC/attention models by an average of +0.5 BLEU without any external MT data. Further, we show that this framework incorporates external MT data, yielding +0.8 BLEU, and also improves transfer learning from pre-trained textual models, yielding +1.8 BLEU.
Exploration of Efficient End-to-End ASR using Discretized Input from Self-Supervised Learning
May 29, 2023



Self-supervised learning (SSL) of speech has shown impressive results in speech-related tasks, particularly in automatic speech recognition (ASR). While most methods employ the output of intermediate layers of the SSL model as real-valued features for downstream tasks, there is potential in exploring alternative approaches that use discretized token sequences. This approach offers benefits such as lower storage requirements and the ability to apply techniques from natural language processing. In this paper, we propose a new protocol that utilizes discretized token sequences in ASR tasks, which includes de-duplication and sub-word modeling to enhance the input sequence. It reduces computational cost by decreasing the length of the sequence. Our experiments on the LibriSpeech dataset demonstrate that our proposed protocol performs competitively with conventional ASR systems using continuous input features, while reducing computational and storage costs.
Align, Write, Re-order: Explainable End-to-End Speech Translation via Operation Sequence Generation
Nov 11, 2022



The black-box nature of end-to-end speech translation (E2E ST) systems makes it difficult to understand how source language inputs are being mapped to the target language. To solve this problem, we would like to simultaneously generate automatic speech recognition (ASR) and ST predictions such that each source language word is explicitly mapped to a target language word. A major challenge arises from the fact that translation is a non-monotonic sequence transduction task due to word ordering differences between languages -- this clashes with the monotonic nature of ASR. Therefore, we propose to generate ST tokens out-of-order while remembering how to re-order them later. We achieve this by predicting a sequence of tuples consisting of a source word, the corresponding target words, and post-editing operations dictating the correct insertion points for the target word. We examine two variants of such operation sequences which enable generation of monotonic transcriptions and non-monotonic translations from the same speech input simultaneously. We apply our approach to offline and real-time streaming models, demonstrating that we can provide explainable translations without sacrificing quality or latency. In fact, the delayed re-ordering ability of our approach improves performance during streaming. As an added benefit, our method performs ASR and ST simultaneously, making it faster than using two separate systems to perform these tasks.
End-to-End Integration of Speech Recognition, Speech Enhancement, and Self-Supervised Learning Representation
Apr 01, 2022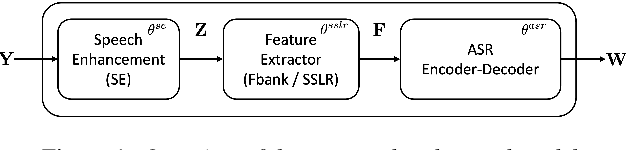
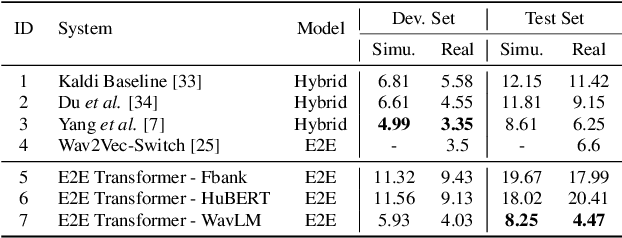
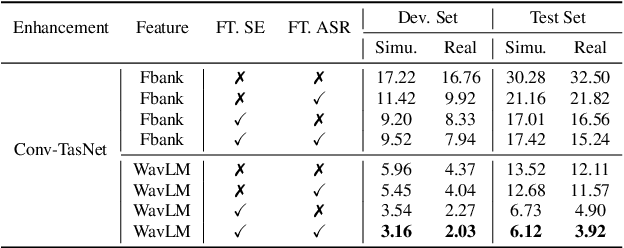
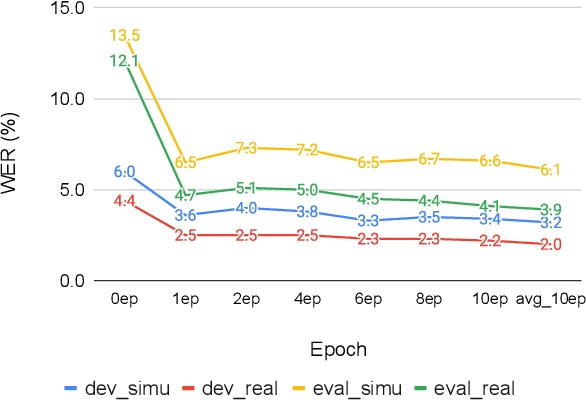
This work presents our end-to-end (E2E) automatic speech recognition (ASR) model targetting at robust speech recognition, called Integraded speech Recognition with enhanced speech Input for Self-supervised learning representation (IRIS). Compared with conventional E2E ASR models, the proposed E2E model integrates two important modules including a speech enhancement (SE) module and a self-supervised learning representation (SSLR) module. The SE module enhances the noisy speech. Then the SSLR module extracts features from enhanced speech to be used for speech recognition (ASR). To train the proposed model, we establish an efficient learning scheme. Evaluation results on the monaural CHiME-4 task show that the IRIS model achieves the best performance reported in the literature for the single-channel CHiME-4 benchmark (2.0% for the real development and 3.9% for the real test) thanks to the powerful pre-trained SSLR module and the fine-tuned SE module.
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021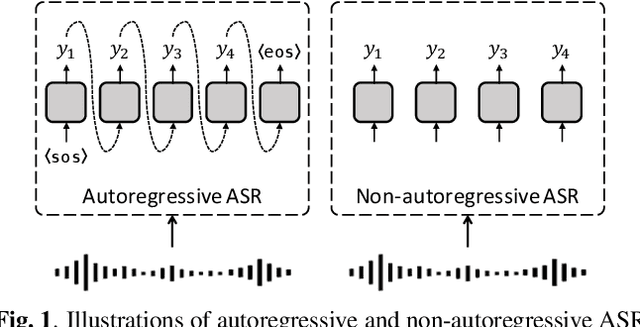

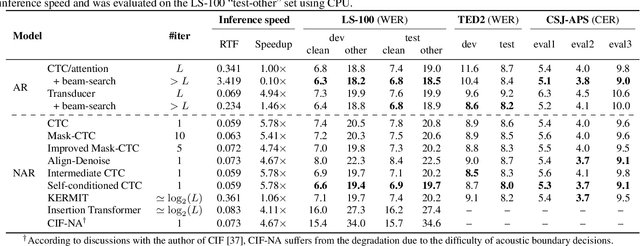
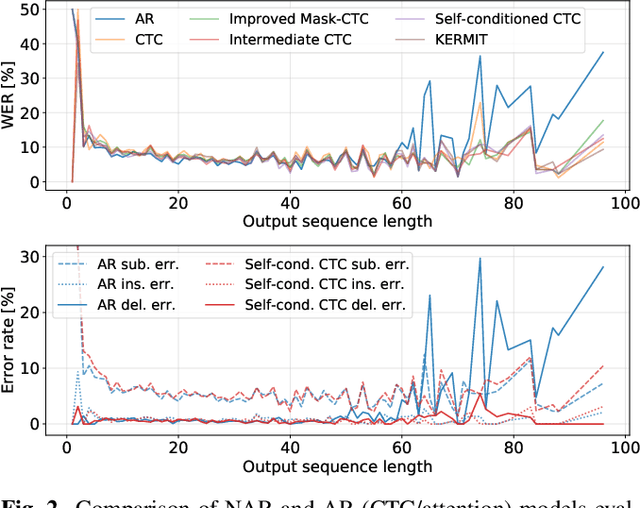
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
Streaming End-to-End ASR based on Blockwise Non-Autoregressive Models
Jul 20, 2021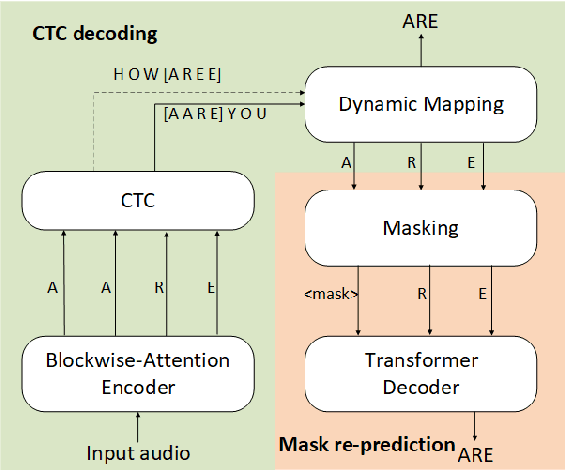
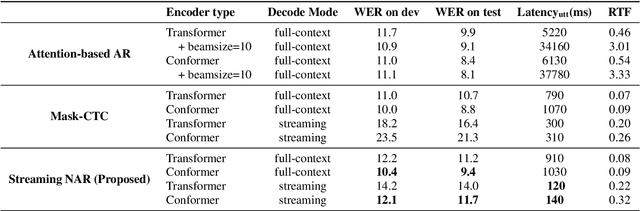
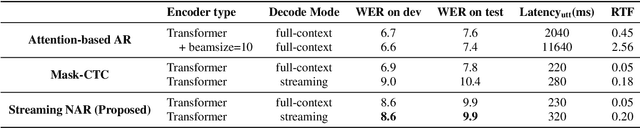
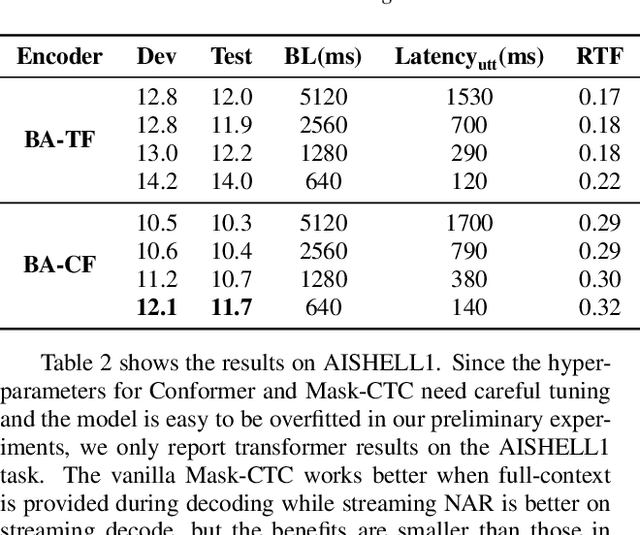
Non-autoregressive (NAR) modeling has gained more and more attention in speech processing. With recent state-of-the-art attention-based automatic speech recognition (ASR) structure, NAR can realize promising real-time factor (RTF) improvement with only small degradation of accuracy compared to the autoregressive (AR) models. However, the recognition inference needs to wait for the completion of a full speech utterance, which limits their applications on low latency scenarios. To address this issue, we propose a novel end-to-end streaming NAR speech recognition system by combining blockwise-attention and connectionist temporal classification with mask-predict (Mask-CTC) NAR. During inference, the input audio is separated into small blocks and then processed in a blockwise streaming way. To address the insertion and deletion error at the edge of the output of each block, we apply an overlapping decoding strategy with a dynamic mapping trick that can produce more coherent sentences. Experimental results show that the proposed method improves online ASR recognition in low latency conditions compared to vanilla Mask-CTC. Moreover, it can achieve a much faster inference speed compared to the AR attention-based models. All of our codes will be publicly available at https://github.com/espnet/espnet.
Speech Representation Learning Combining Conformer CPC with Deep Cluster for the ZeroSpeech Challenge 2021
Jul 13, 2021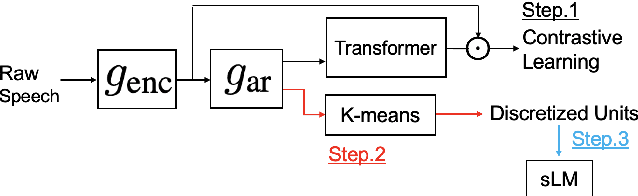

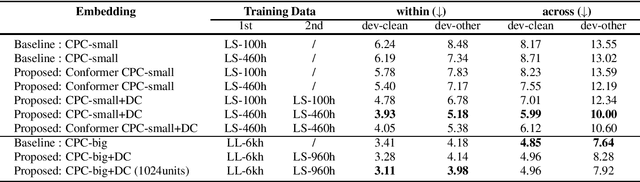

We present a system for the Zero Resource Speech Challenge 2021, which combines a Contrastive Predictive Coding (CPC) with deep cluster. In deep cluster, we first prepare pseudo-labels obtained by clustering the outputs of a CPC network with k-means. Then, we train an additional autoregressive model to classify the previously obtained pseudo-labels in a supervised manner. Phoneme discriminative representation is achieved by executing the second-round clustering with the outputs of the final layer of the autoregressive model. We show that replacing a Transformer layer with a Conformer layer leads to a further gain in a lexical metric. Experimental results show that a relative improvement of 35% in a phonetic metric, 1.5% in the lexical metric, and 2.3% in a syntactic metric are achieved compared to a baseline method of CPC-small which is trained on LibriSpeech 460h data. We achieve top results in this challenge with the syntactic metric.