 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Ultrafast Photorealistic Style Transfer via Neural Architecture Search
Dec 05, 2019

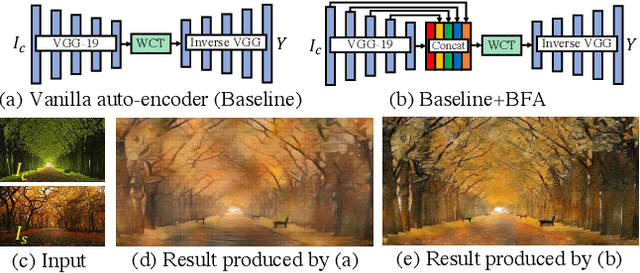

The key challenge in photorealistic style transfer is that an algorithm should faithfully transfer the style of a reference photo to a content photo while the generated image should look like one captured by a camera. Although several photorealistic style transfer algorithms have been proposed, they need to rely on post- and/or pre-processing to make the generated images look photorealistic. If we disable the additional processing, these algorithms would fail to produce plausible photorealistic stylization in terms of detail preservation and photorealism. In this work, we propose an effective solution to these issues. Our method consists of a construction step (C-step) to build a photorealistic stylization network and a pruning step (P-step) for acceleration. In the C-step, we propose a dense auto-encoder named PhotoNet based on a carefully designed pre-analysis. PhotoNet integrates a feature aggregation module (BFA) and instance normalized skip links (INSL). To generate faithful stylization, we introduce multiple style transfer modules in the decoder and INSLs. PhotoNet significantly outperforms existing algorithms in terms of both efficiency and effectiveness. In the P-step, we adopt a neural architecture search method to accelerate PhotoNet. We propose an automatic network pruning framework in the manner of teacher-student learning for photorealistic stylization. The network architecture named PhotoNAS resulted from the search achieves significant acceleration over PhotoNet while keeping the stylization effects almost intact. We conduct extensive experiments on both image and video transfer. The results show that our method can produce favorable results while achieving 20-30 times acceleration in comparison with the existing state-of-the-art approaches. It is worth noting that the proposed algorithm accomplishes better performance without any pre- or post-processing.
A leak in PRNU based source identification? Questioning fingerprint uniqueness
Sep 10, 2020
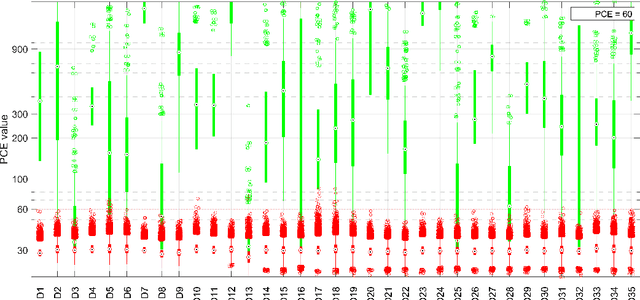
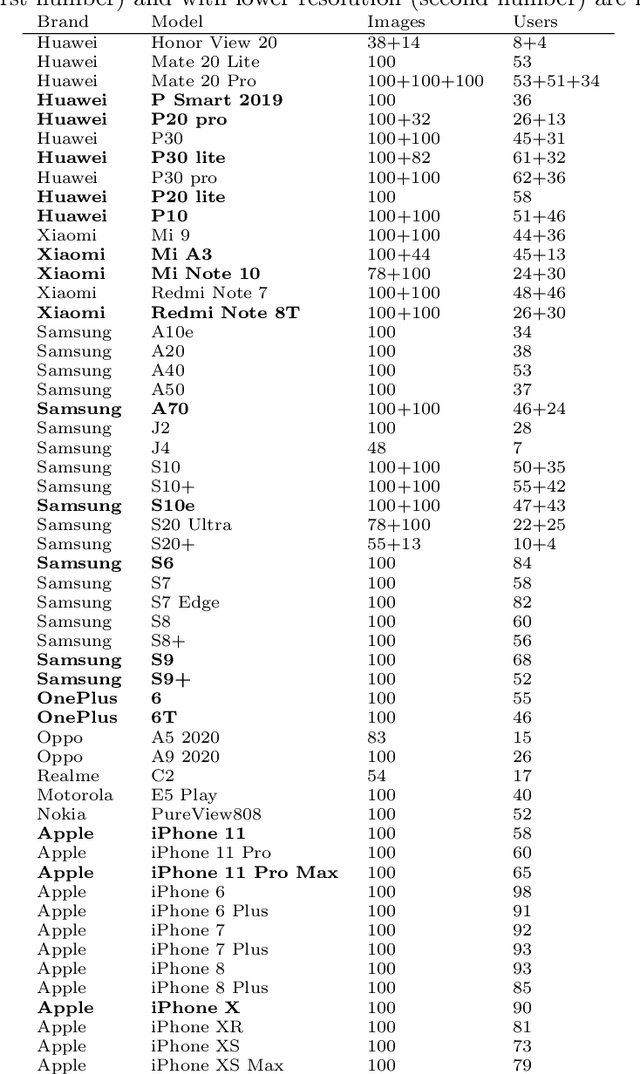
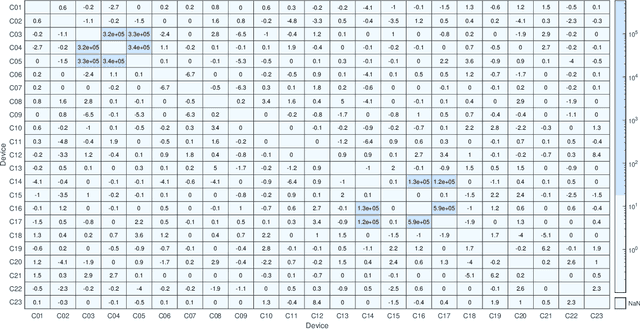
Photo Response Non Uniformity (PRNU) is considered the most effective trace for the image source attribution task. Its uniqueness ensures that the sensor pattern noises extracted from different cameras are strongly uncorrelated, even when they belong to the same camera model. However, with the advent of computational photography, most recent devices of the same model start exposing correlated patterns thus introducing the real chance of erroneous image source attribution. In this paper, after highlighting the issue under a controlled environment, we perform a large testing campaign on Flickr images to determine how widespread the issue is and which is the plausible cause. To this aim, we tested over $240000$ image pairs from $54$ recent smartphone models comprising the most relevant brands. Experiments show that many Samsung, Xiaomi and Huawei devices are strongly affected by this issue. Although the primary cause of high false alarm rates cannot be directly related to specific camera models, firmware nor image contents, it is evident that the effectiveness of PRNU-based source identification on the most recent devices must be reconsidered in light of these results. Therefore, this paper is to be intended as a call to action for the scientific community rather than a complete treatment of the subject.
Adversarial Privacy-preserving Filter
Aug 04, 2020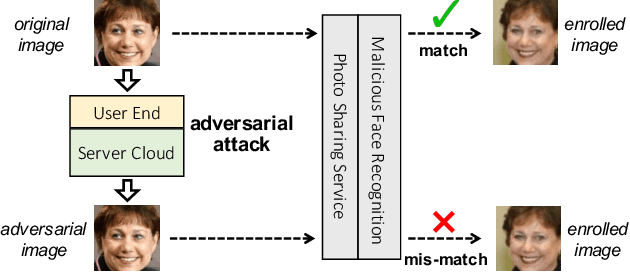
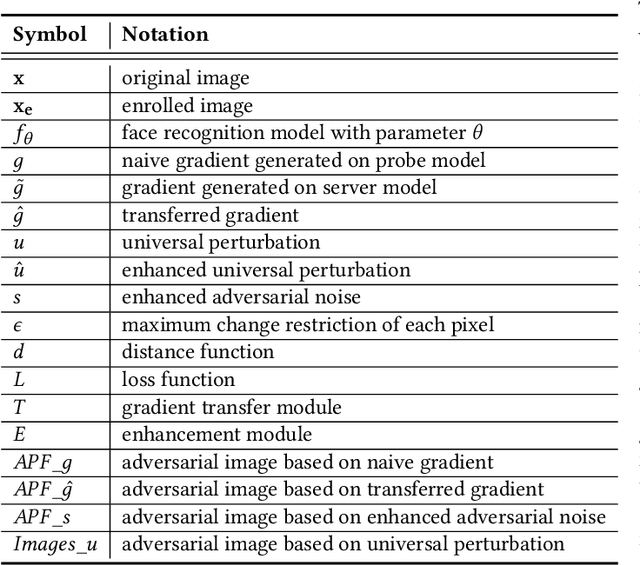
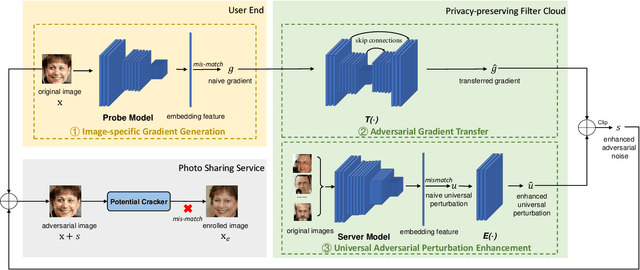
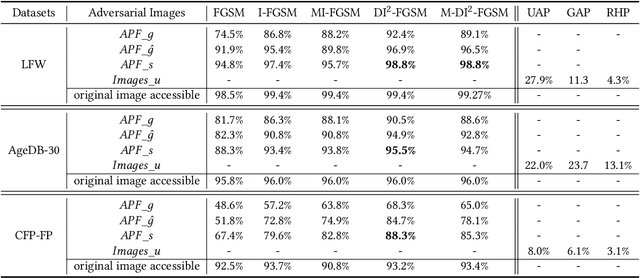
While widely adopted in practical applications, face recognition has been critically discussed regarding the malicious use of face images and the potential privacy problems, e.g., deceiving payment system and causing personal sabotage. Online photo sharing services unintentionally act as the main repository for malicious crawler and face recognition applications. This work aims to develop a privacy-preserving solution, called Adversarial Privacy-preserving Filter (APF), to protect the online shared face images from being maliciously used.We propose an end-cloud collaborated adversarial attack solution to satisfy requirements of privacy, utility and nonaccessibility. Specifically, the solutions consist of three modules: (1) image-specific gradient generation, to extract image-specific gradient in the user end with a compressed probe model; (2) adversarial gradient transfer, to fine-tune the image-specific gradient in the server cloud; and (3) universal adversarial perturbation enhancement, to append image-independent perturbation to derive the final adversarial noise. Extensive experiments on three datasets validate the effectiveness and efficiency of the proposed solution. A prototype application is also released for further evaluation.We hope the end-cloud collaborated attack framework could shed light on addressing the issue of online multimedia sharing privacy-preserving issues from user side.
Kimera: from SLAM to Spatial Perception with 3D Dynamic Scene Graphs
Jan 18, 2021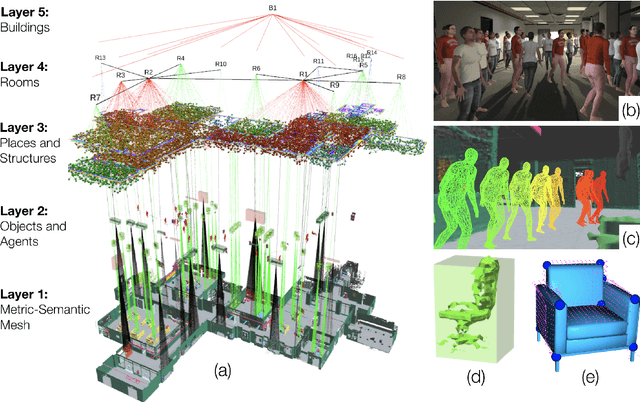
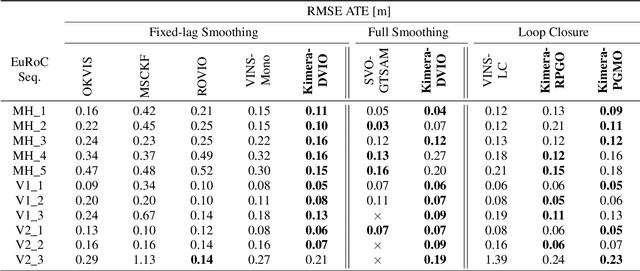
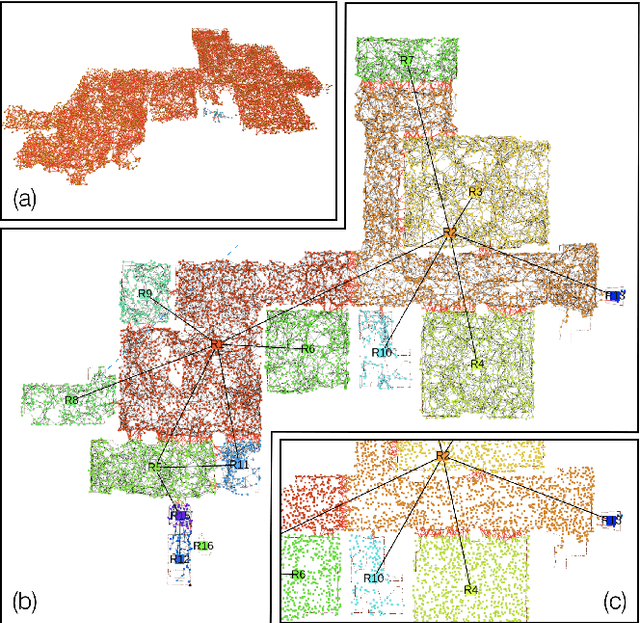
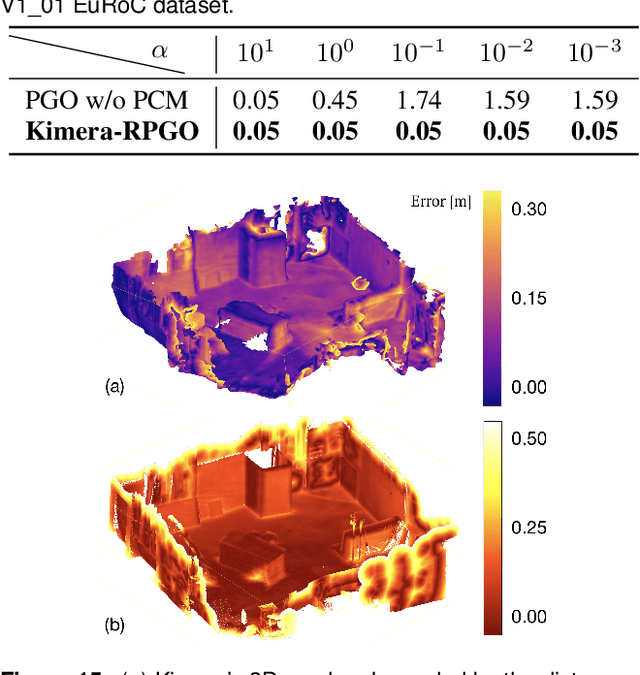
Humans are able to form a complex mental model of the environment they move in. This mental model captures geometric and semantic aspects of the scene, describes the environment at multiple levels of abstractions (e.g., objects, rooms, buildings), includes static and dynamic entities and their relations (e.g., a person is in a room at a given time). In contrast, current robots' internal representations still provide a partial and fragmented understanding of the environment, either in the form of a sparse or dense set of geometric primitives (e.g., points, lines, planes, voxels) or as a collection of objects. This paper attempts to reduce the gap between robot and human perception by introducing a novel representation, a 3D Dynamic Scene Graph(DSG), that seamlessly captures metric and semantic aspects of a dynamic environment. A DSG is a layered graph where nodes represent spatial concepts at different levels of abstraction, and edges represent spatio-temporal relations among nodes. Our second contribution is Kimera, the first fully automatic method to build a DSG from visual-inertial data. Kimera includes state-of-the-art techniques for visual-inertial SLAM, metric-semantic 3D reconstruction, object localization, human pose and shape estimation, and scene parsing. Our third contribution is a comprehensive evaluation of Kimera in real-life datasets and photo-realistic simulations, including a newly released dataset, uHumans2, which simulates a collection of crowded indoor and outdoor scenes. Our evaluation shows that Kimera achieves state-of-the-art performance in visual-inertial SLAM, estimates an accurate 3D metric-semantic mesh model in real-time, and builds a DSG of a complex indoor environment with tens of objects and humans in minutes. Our final contribution shows how to use a DSG for real-time hierarchical semantic path-planning. The core modules in Kimera are open-source.
Attribute-Guided Sketch Generation
Jan 28, 2019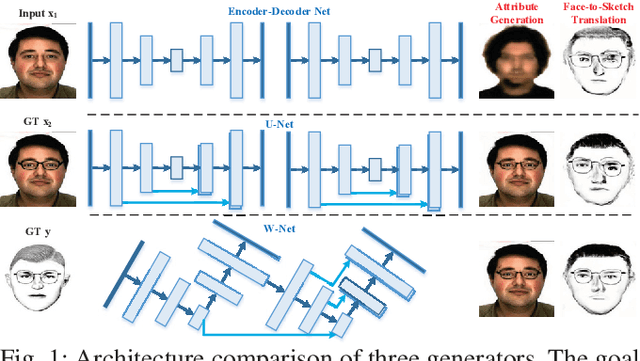
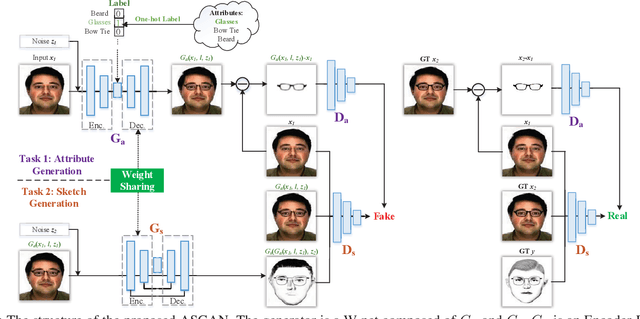


Facial attributes are important since they provide a detailed description and determine the visual appearance of human faces. In this paper, we aim at converting a face image to a sketch while simultaneously generating facial attributes. To this end, we propose a novel Attribute-Guided Sketch Generative Adversarial Network (ASGAN) which is an end-to-end framework and contains two pairs of generators and discriminators, one of which is used to generate faces with attributes while the other one is employed for image-to-sketch translation. The two generators form a W-shaped network (W-net) and they are trained jointly with a weight-sharing constraint. Additionally, we also propose two novel discriminators, the residual one focusing on attribute generation and the triplex one helping to generate realistic looking sketches. To validate our model, we have created a new large dataset with 8,804 images, named the Attribute Face Photo & Sketch (AFPS) dataset which is the first dataset containing attributes associated to face sketch images. The experimental results demonstrate that the proposed network (i) generates more photo-realistic faces with sharper facial attributes than baselines and (ii) has good generalization capability on different generative tasks.
VisualEchoes: Spatial Image Representation Learning through Echolocation
May 04, 2020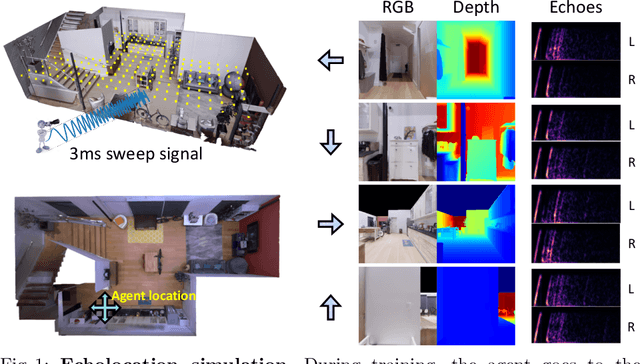

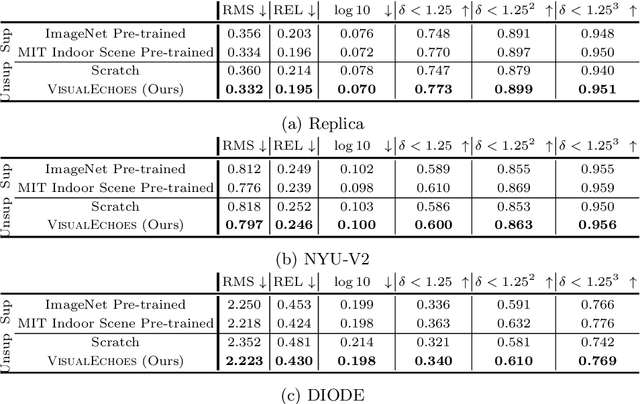
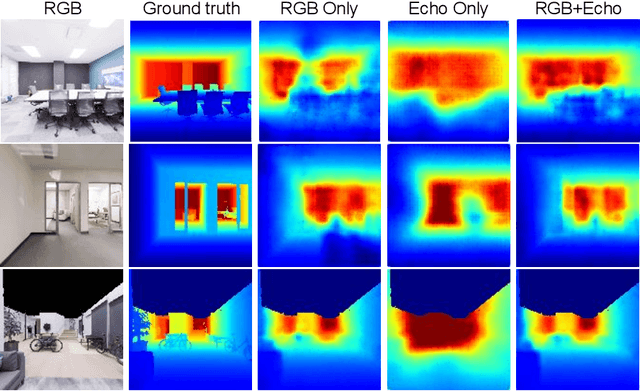
Several animal species (e.g., bats, dolphins, and whales) and even visually impaired humans have the remarkable ability to perform echolocation: a biological sonar used to perceive spatial layout and locate objects in the world. We explore the spatial cues contained in echoes and how they can benefit vision tasks that require spatial reasoning. First we capture echo responses in photo-realistic 3D indoor scene environments. Then we propose a novel interaction-based representation learning framework that learns useful visual features via echolocation. We show that the learned image features are useful for multiple downstream vision tasks requiring spatial reasoning---monocular depth estimation, surface normal estimation, and visual navigation. Our work opens a new path for representation learning for embodied agents, where supervision comes from interacting with the physical world. Our experiments demonstrate that our image features learned from echoes are comparable or even outperform heavily supervised pre-training methods for multiple fundamental spatial tasks.
Face2Face: Real-time Face Capture and Reenactment of RGB Videos
Jul 29, 2020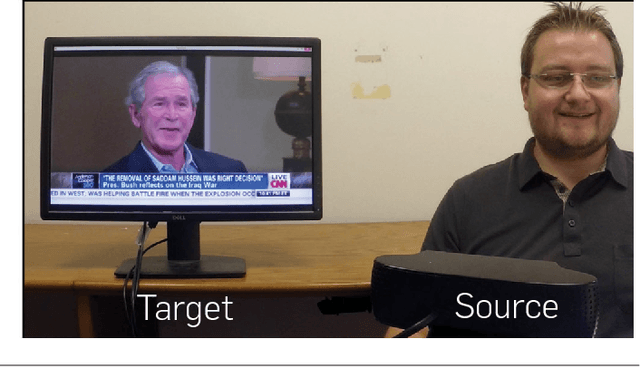
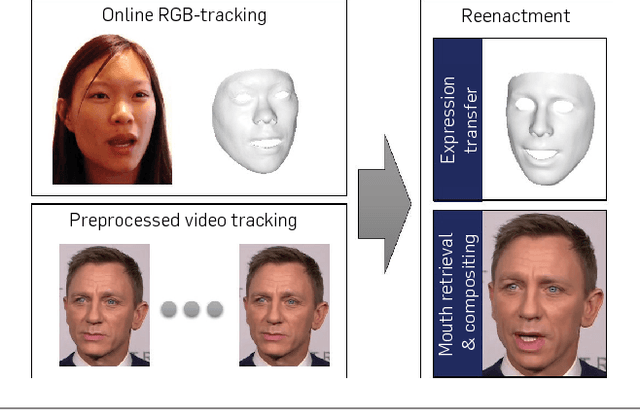

We present Face2Face, a novel approach for real-time facial reenactment of a monocular target video sequence (e.g., Youtube video). The source sequence is also a monocular video stream, captured live with a commodity webcam. Our goal is to animate the facial expressions of the target video by a source actor and re-render the manipulated output video in a photo-realistic fashion. To this end, we first address the under-constrained problem of facial identity recovery from monocular video by non-rigid model-based bundling. At run time, we track facial expressions of both source and target video using a dense photometric consistency measure. Reenactment is then achieved by fast and efficient deformation transfer between source and target. The mouth interior that best matches the re-targeted expression is retrieved from the target sequence and warped to produce an accurate fit. Finally, we convincingly re-render the synthesized target face on top of the corresponding video stream such that it seamlessly blends with the real-world illumination. We demonstrate our method in a live setup, where Youtube videos are reenacted in real time.
Head2Head++: Deep Facial Attributes Re-Targeting
Jun 17, 2020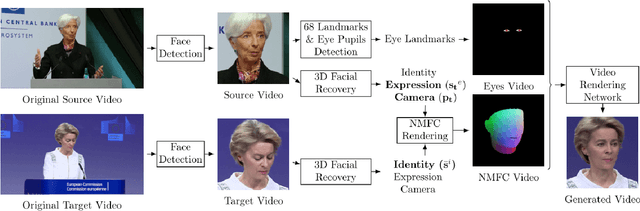
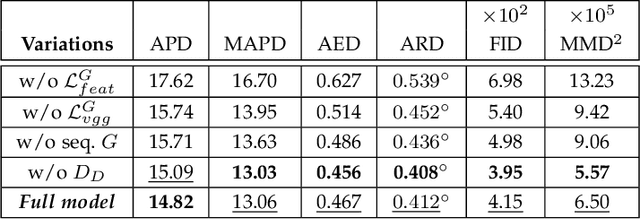

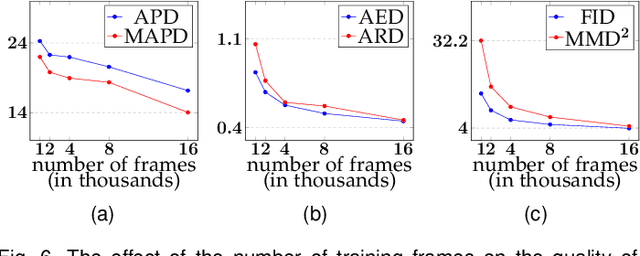
Facial video re-targeting is a challenging problem aiming to modify the facial attributes of a target subject in a seamless manner by a driving monocular sequence. We leverage the 3D geometry of faces and Generative Adversarial Networks (GANs) to design a novel deep learning architecture for the task of facial and head reenactment. Our method is different to purely 3D model-based approaches, or recent image-based methods that use Deep Convolutional Neural Networks (DCNNs) to generate individual frames. We manage to capture the complex non-rigid facial motion from the driving monocular performances and synthesise temporally consistent videos, with the aid of a sequential Generator and an ad-hoc Dynamics Discriminator network. We conduct a comprehensive set of quantitative and qualitative tests and demonstrate experimentally that our proposed method can successfully transfer facial expressions, head pose and eye gaze from a source video to a target subject, in a photo-realistic and faithful fashion, better than other state-of-the-art methods. Most importantly, our system performs end-to-end reenactment in nearly real-time speed (18 fps).
Photon-Driven Neural Path Guiding
Oct 05, 2020
Although Monte Carlo path tracing is a simple and effective algorithm to synthesize photo-realistic images, it is often very slow to converge to noise-free results when involving complex global illumination. One of the most successful variance-reduction techniques is path guiding, which can learn better distributions for importance sampling to reduce pixel noise. However, previous methods require a large number of path samples to achieve reliable path guiding. We present a novel neural path guiding approach that can reconstruct high-quality sampling distributions for path guiding from a sparse set of samples, using an offline trained neural network. We leverage photons traced from light sources as the input for sampling density reconstruction, which is highly effective for challenging scenes with strong global illumination. To fully make use of our deep neural network, we partition the scene space into an adaptive hierarchical grid, in which we apply our network to reconstruct high-quality sampling distributions for any local region in the scene. This allows for highly efficient path guiding for any path bounce at any location in path tracing. We demonstrate that our photon-driven neural path guiding method can generalize well on diverse challenging testing scenes that are not seen in training. Our approach achieves significantly better rendering results of testing scenes than previous state-of-the-art path guiding methods.
REXUP: I REason, I EXtract, I UPdate with Structured Compositional Reasoning for Visual Question Answering
Jul 27, 2020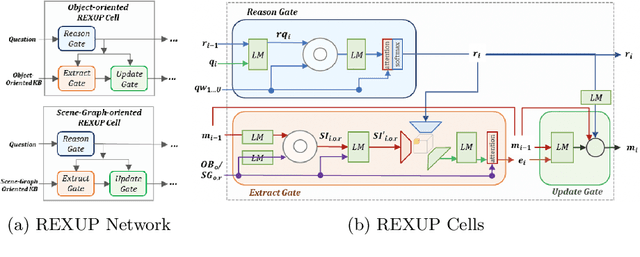
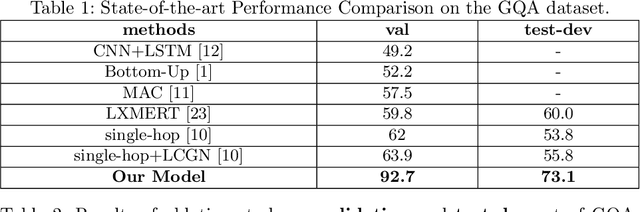


Visual question answering (VQA) is a challenging multi-modal task that requires not only the semantic understanding of both images and questions, but also the sound perception of a step-by-step reasoning process that would lead to the correct answer. So far, most successful attempts in VQA have been focused on only one aspect, either the interaction of visual pixel features of images and word features of questions, or the reasoning process of answering the question in an image with simple objects. In this paper, we propose a deep reasoning VQA model with explicit visual structure-aware textual information, and it works well in capturing step-by-step reasoning process and detecting a complex object-relationship in photo-realistic images. REXUP network consists of two branches, image object-oriented and scene graph oriented, which jointly works with super-diagonal fusion compositional attention network. We quantitatively and qualitatively evaluate REXUP on the GQA dataset and conduct extensive ablation studies to explore the reasons behind REXUP's effectiveness. Our best model significantly outperforms the precious state-of-the-art, which delivers 92.7% on the validation set and 73.1% on the test-dev set.