 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Episodic Memory with User Feedback
Apr 27, 2026In episodic memory with natural language queries (EM-NLQ), a user may ask a question (e.g., "Where did I place the mug?") that requires searching a long egocentric video, captured from the user's perspective, to find the moment that answers it. However, queries can be ambiguous or incomplete, leading to incorrect responses. Current methods ignore this key aspect and address EM-NLQ in a one-shot setup, limiting their applicability in real-world scenarios. In this work, we address this gap and introduce the Episodic Memory with Questions and Feedback task (EM-QnF). Here, the user can provide feedback on the model's initial prediction or add more information (e.g., "Before this. I'm looking for the big blue mug not the white one"), helping the model refine its predictions interactively. To this end, we collect datasets for feedback-based interaction and propose a lightweight training scheme that avoids expensive sequential optimization. We also introduce a plug-and-play Feedback ALignment Module (FALM) that enables existing EM-NLQ models to incorporate user feedback effectively. Our approach significantly improves over the state of the art on three challenging benchmarks and is better than or competitive with commercial large vision-language models while remaining efficient. Evaluation with human-generated feedback shows that it generalizes well to real-world scenarios.
Materialistic RIR: Material Conditioned Realistic RIR Generation
Apr 22, 2026Rings like gold, thuds like wood! The sound we hear in a scene is shaped not only by the spatial layout of the environment but also by the materials of the objects and surfaces within it. For instance, a room with wooden walls will produce a different acoustic experience from a room with the same spatial layout but concrete walls. Accurately modeling these effects is essential for applications such as virtual reality, robotics, architectural design, and audio engineering. Yet, existing methods for acoustic modeling often entangle spatial and material influences in correlated representations, which limits user control and reduces the realism of the generated acoustics. In this work, we present a novel approach for material-controlled Room Impulse Response (RIR) generation that explicitly disentangles the effects of spatial and material cues in a scene. Our approach models the RIR using two modules: a spatial module that captures the influence of the spatial layout of the scene, and a material module that modulates this spatial RIR according to a user-specified material configuration. This explicitly disentangled design allows users to easily modify the material configuration of a scene and observe its impact on acoustics without altering the spatial structure or scene content. Our model provides significant improvements over prior approaches on both acoustic-based metrics (up to +16% on RTE) and material-based metrics (up to +70%). Furthermore, through a human perceptual study, we demonstrate the improved realism and material sensitivity of our model compared to the strongest baselines.
MistExit: Learning to Exit for Early Mistake Detection in Procedural Videos
Mar 15, 2026We introduce the task of early mistake detection in video, where the goal is to determine whether a keystep in a procedural activity is performed correctly while observing as little of the streaming video as possible. To tackle this problem, we propose a method comprising a mistake detector and a reinforcement learning policy. At each timestep, the detector processes recently observed frames to estimate the keystep's correctness while anticipating future visual features, enabling reliable early mistake estimates. Meanwhile, the policy aggregates the detector outputs and visual observations over time and adaptively decides when to exit (i.e., stop processing incoming frames) while producing the final prediction. Using diverse real-world procedural video datasets, we demonstrate that our MistExit model achieves superior mistake detection accuracy while reducing the fraction of video observed compared to state-of-the-art models. Project: https://vision.cs.utexas.edu/projects/mist_exit.
Switch-a-View: Few-Shot View Selection Learned from Edited Videos
Dec 24, 2024We introduce Switch-a-View, a model that learns to automatically select the viewpoint to display at each timepoint when creating a how-to video. The key insight of our approach is how to train such a model from unlabeled--but human-edited--video samples. We pose a pretext task that pseudo-labels segments in the training videos for their primary viewpoint (egocentric or exocentric), and then discovers the patterns between those view-switch moments on the one hand and the visual and spoken content in the how-to video on the other hand. Armed with this predictor, our model then takes an unseen multi-view video as input and orchestrates which viewpoint should be displayed when. We further introduce a few-shot training setting that permits steering the model towards a new data domain. We demonstrate our idea on a variety of real-world video from HowTo100M and Ego-Exo4D and rigorously validate its advantages.
Which Viewpoint Shows it Best? Language for Weakly Supervising View Selection in Multi-view Videos
Nov 13, 2024



Given a multi-view video, which viewpoint is most informative for a human observer? Existing methods rely on heuristics or expensive ``best-view" supervision to answer this question, limiting their applicability. We propose a weakly supervised approach that leverages language accompanying an instructional multi-view video as a means to recover its most informative viewpoint(s). Our key hypothesis is that the more accurately an individual view can predict a view-agnostic text summary, the more informative it is. To put this into action, we propose a framework that uses the relative accuracy of view-dependent caption predictions as a proxy for best view pseudo-labels. Then, those pseudo-labels are used to train a view selector, together with an auxiliary camera pose predictor that enhances view-sensitivity. During inference, our model takes as input only a multi-view video -- no language or camera poses -- and returns the best viewpoint to watch at each timestep. On two challenging datasets comprised of diverse multi-camera setups and how-to activities, our model consistently outperforms state-of-the-art baselines, both with quantitative metrics and human evaluation.
Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos
Jul 10, 2023



We propose a self-supervised method for learning representations based on spatial audio-visual correspondences in egocentric videos. In particular, our method leverages a masked auto-encoding framework to synthesize masked binaural audio through the synergy of audio and vision, thereby learning useful spatial relationships between the two modalities. We use our pretrained features to tackle two downstream video tasks requiring spatial understanding in social scenarios: active speaker detection and spatial audio denoising. We show through extensive experiments that our features are generic enough to improve over multiple state-of-the-art baselines on two public challenging egocentric video datasets, EgoCom and EasyCom. Project: http://vision.cs.utexas.edu/projects/ego_av_corr.
SpotEM: Efficient Video Search for Episodic Memory
Jun 28, 2023



The goal in episodic memory (EM) is to search a long egocentric video to answer a natural language query (e.g., "where did I leave my purse?"). Existing EM methods exhaustively extract expensive fixed-length clip features to look everywhere in the video for the answer, which is infeasible for long wearable-camera videos that span hours or even days. We propose SpotEM, an approach to achieve efficiency for a given EM method while maintaining good accuracy. SpotEM consists of three key ideas: 1) a novel clip selector that learns to identify promising video regions to search conditioned on the language query; 2) a set of low-cost semantic indexing features that capture the context of rooms, objects, and interactions that suggest where to look; and 3) distillation losses that address the optimization issues arising from end-to-end joint training of the clip selector and EM model. Our experiments on 200+ hours of video from the Ego4D EM Natural Language Queries benchmark and three different EM models demonstrate the effectiveness of our approach: computing only 10% - 25% of the clip features, we preserve 84% - 97% of the original EM model's accuracy. Project page: https://vision.cs.utexas.edu/projects/spotem
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023



Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
NaQ: Leveraging Narrations as Queries to Supervise Episodic Memory
Jan 02, 2023



Searching long egocentric videos with natural language queries (NLQ) has compelling applications in augmented reality and robotics, where a fluid index into everything that a person (agent) has seen before could augment human memory and surface relevant information on demand. However, the structured nature of the learning problem (free-form text query inputs, localized video temporal window outputs) and its needle-in-a-haystack nature makes it both technically challenging and expensive to supervise. We introduce Narrations-as-Queries (NaQ), a data augmentation strategy that transforms standard video-text narrations into training data for a video query localization model. Validating our idea on the Ego4D benchmark, we find it has tremendous impact in practice. NaQ improves multiple top models by substantial margins (even doubling their accuracy), and yields the very best results to date on the Ego4D NLQ challenge, soundly outperforming all challenge winners in the CVPR and ECCV 2022 competitions and topping the current public leaderboard. Beyond achieving the state-of-the-art for NLQ, we also demonstrate unique properties of our approach such as gains on long-tail object queries, and the ability to perform zero-shot and few-shot NLQ.
Few-Shot Audio-Visual Learning of Environment Acoustics
Jun 08, 2022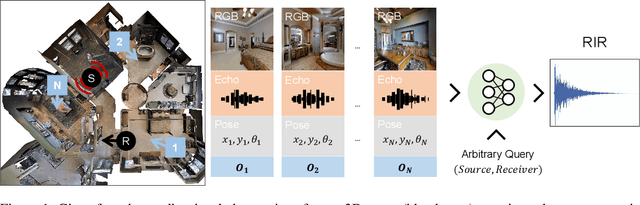
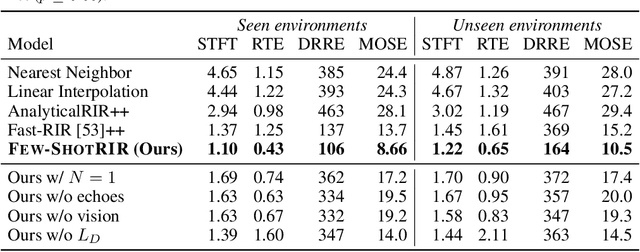
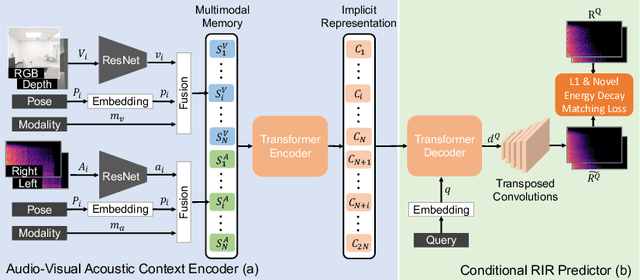

Room impulse response (RIR) functions capture how the surrounding physical environment transforms the sounds heard by a listener, with implications for various applications in AR, VR, and robotics. Whereas traditional methods to estimate RIRs assume dense geometry and/or sound measurements throughout the environment, we explore how to infer RIRs based on a sparse set of images and echoes observed in the space. Towards that goal, we introduce a transformer-based method that uses self-attention to build a rich acoustic context, then predicts RIRs of arbitrary query source-receiver locations through cross-attention. Additionally, we design a novel training objective that improves the match in the acoustic signature between the RIR predictions and the targets. In experiments using a state-of-the-art audio-visual simulator for 3D environments, we demonstrate that our method successfully generates arbitrary RIRs, outperforming state-of-the-art methods and--in a major departure from traditional methods--generalizing to novel environments in a few-shot manner. Project: http://vision.cs.utexas.edu/projects/fs_rir.