 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Large-scale Mixed Traffic Control Using Dynamic Vehicle Routing and Privacy-Preserving Crowdsourcing
Nov 19, 2023
Controlling and coordinating urban traffic flow through robot vehicles is emerging as a novel transportation paradigm for the future. While this approach garners growing attention from researchers and practitioners, effectively managing and coordinating large-scale mixed traffic remains a challenge. We introduce an effective framework for large-scale mixed traffic control via privacy-preserving crowdsourcing and dynamic vehicle routing. Our framework consists of three modules: a privacy-protecting crowdsensing method, a graph propagation-based traffic forecasting method, and a privacy-preserving route selection mechanism. We evaluate our framework using a real-world road network. The results show that our framework accurately forecasts traffic flow, efficiently mitigates network-wide RV shortage issue, and coordinates large-scale mixed traffic. Compared to other baseline methods, our framework not only reduces the RV shortage issue up to 69.4% but also reduces the average waiting time of all vehicles in the network up to 27%.
Precise localization within the GI tract by combining classification of CNNs and time-series analysis of HMMs
Oct 11, 2023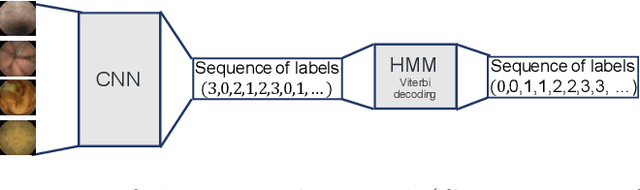
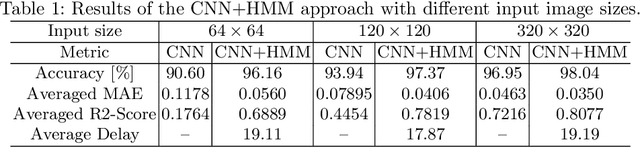
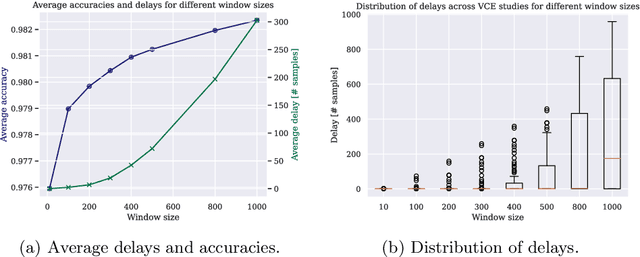
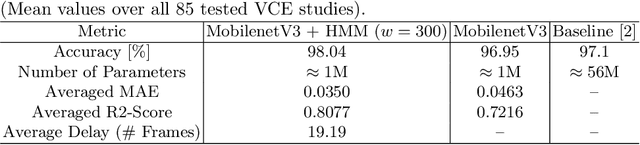
This paper presents a method to efficiently classify the gastroenterologic section of images derived from Video Capsule Endoscopy (VCE) studies by exploring the combination of a Convolutional Neural Network (CNN) for classification with the time-series analysis properties of a Hidden Markov Model (HMM). It is demonstrated that successive time-series analysis identifies and corrects errors in the CNN output. Our approach achieves an accuracy of $98.04\%$ on the Rhode Island (RI) Gastroenterology dataset. This allows for precise localization within the gastrointestinal (GI) tract while requiring only approximately 1M parameters and thus, provides a method suitable for low power devices
Power grid operational risk assessment using graph neural network surrogates
Nov 21, 2023We investigate the utility of graph neural networks (GNNs) as proxies of power grid operational decision-making algorithms (optimal power flow (OPF) and security-constrained unit commitment (SCUC)) to enable rigorous quantification of the operational risk. To conduct principled risk analysis, numerous Monte Carlo (MC) samples are drawn from the (foretasted) probability distributions of spatio-temporally correlated stochastic grid variables. The corresponding OPF and SCUC solutions, which are needed to quantify the risk, are generated using traditional OPF and SCUC solvers to generate data for training GNN model(s). The GNN model performance is evaluated in terms of the accuracy of predicting quantities of interests (QoIs) derived from the decision variables in OPF and SCUC. Specifically, we focus on thermal power generation and load shedding at system and individual zone level. We also perform reliability and risk quantification based on GNN predictions and compare with that obtained from OPF/SCUC solutions. Our results demonstrate that GNNs are capable of providing fast and accurate prediction of QoIs and thus can be good surrogate models for OPF and SCUC. The excellent accuracy of GNN-based reliability and risk assessment further suggests that GNN surrogate has the potential to be applied in real-time and hours-ahead risk quantification.
GMISeg: General Medical Image Segmentation without Re-Training
Nov 21, 2023Although deep learning models have become the main method for medical image segmentation, they often cannot be extended to unknown segmentation tasks involving new anatomical structures, image shapes, or labels. For new segmentation tasks, researchers often have to retrain or fine-tune the model, which is time-consuming and poses a significant obstacle to clinical researchers, who often lack the resources and professional knowledge to train neural networks. Therefore, we proposed a general method that can solve unknown medical image segmentation tasks without requiring additional training. Given an example set of images and prompts for defining new segmentation tasks, GMISeg applies a novel low-rank fine-tuning strategy based on the proposed approach to the SAM (Segment Anything Model) image encoder, and works with the prompt encoder and mask decoder to fine-tune the labeled dataset without the need for additional training. To achieve generalization of new tasks, we used medical image datasets with different imaging modes for different parts. We trained and generalized GMISeg on a different set of anatomical and imaging modes using cardiac images on other site datasets. We have demonstrated that GMISeg outperforms the latest methods on unknown tasks and have conducted a comprehensive analysis and summary of the important performance of the proposed method.
Hierarchical Meta-learning-based Adaptive Controller
Nov 21, 2023We study how to design learning-based adaptive controllers that enable fast and accurate online adaptation in changing environments. In these settings, learning is typically done during an initial (offline) design phase, where the vehicle is exposed to different environmental conditions and disturbances (e.g., a drone exposed to different winds) to collect training data. Our work is motivated by the observation that real-world disturbances fall into two categories: 1) those that can be directly monitored or controlled during training, which we call "manageable", and 2) those that cannot be directly measured or controlled (e.g., nominal model mismatch, air plate effects, and unpredictable wind), which we call "latent". Imprecise modeling of these effects can result in degraded control performance, particularly when latent disturbances continuously vary. This paper presents the Hierarchical Meta-learning-based Adaptive Controller (HMAC) to learn and adapt to such multi-source disturbances. Within HMAC, we develop two techniques: 1) Hierarchical Iterative Learning, which jointly trains representations to caption the various sources of disturbances, and 2) Smoothed Streaming Meta-Learning, which learns to capture the evolving structure of latent disturbances over time (in addition to standard meta-learning on the manageable disturbances). Experimental results demonstrate that HMAC exhibits more precise and rapid adaptation to multi-source disturbances than other adaptive controllers.
CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
Nov 11, 2023Reconstructing personalized animatable head avatars has significant implications in the fields of AR/VR. Existing methods for achieving explicit face control of 3D Morphable Models (3DMM) typically rely on multi-view images or videos of a single subject, making the reconstruction process complex. Additionally, the traditional rendering pipeline is time-consuming, limiting real-time animation possibilities. In this paper, we introduce CVTHead, a novel approach that generates controllable neural head avatars from a single reference image using point-based neural rendering. CVTHead considers the sparse vertices of mesh as the point set and employs the proposed Vertex-feature Transformer to learn local feature descriptors for each vertex. This enables the modeling of long-range dependencies among all the vertices. Experimental results on the VoxCeleb dataset demonstrate that CVTHead achieves comparable performance to state-of-the-art graphics-based methods. Moreover, it enables efficient rendering of novel human heads with various expressions, head poses, and camera views. These attributes can be explicitly controlled using the coefficients of 3DMMs, facilitating versatile and realistic animation in real-time scenarios.
Regions are Who Walk Them: a Large Pre-trained Spatiotemporal Model Based on Human Mobility for Ubiquitous Urban Sensing
Nov 17, 2023User profiling and region analysis are two tasks of significant commercial value. However, in practical applications, modeling different features typically involves four main steps: data preparation, data processing, model establishment, evaluation, and optimization. This process is time-consuming and labor-intensive. Repeating this workflow for each feature results in abundant development time for tasks and a reduced overall volume of task development. Indeed, human mobility data contains a wealth of information. Several successful cases suggest that conducting in-depth analysis of population movement data could potentially yield meaningful profiles about users and areas. Nonetheless, most related works have not thoroughly utilized the semantic information within human mobility data and trained on a fixed number of the regions. To tap into the rich information within population movement, based on the perspective that Regions Are Who walk them, we propose a large spatiotemporal model based on trajectories (RAW). It possesses the following characteristics: 1) Tailored for trajectory data, introducing a GPT-like structure with a parameter count of up to 1B; 2) Introducing a spatiotemporal fine-tuning module, interpreting trajectories as collection of users to derive arbitrary region embedding. This framework allows rapid task development based on the large spatiotemporal model. We conducted extensive experiments to validate the effectiveness of our proposed large spatiotemporal model. It's evident that our proposed method, relying solely on human mobility data without additional features, exhibits a certain level of relevance in user profiling and region analysis. Moreover, our model showcases promising predictive capabilities in trajectory generation tasks based on the current state, offering the potential for further innovative work utilizing this large spatiotemporal model.
Forecasting large collections of time series: feature-based methods
Sep 25, 2023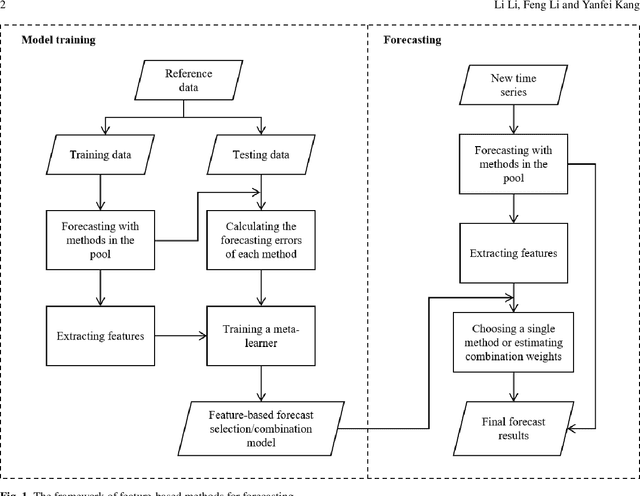
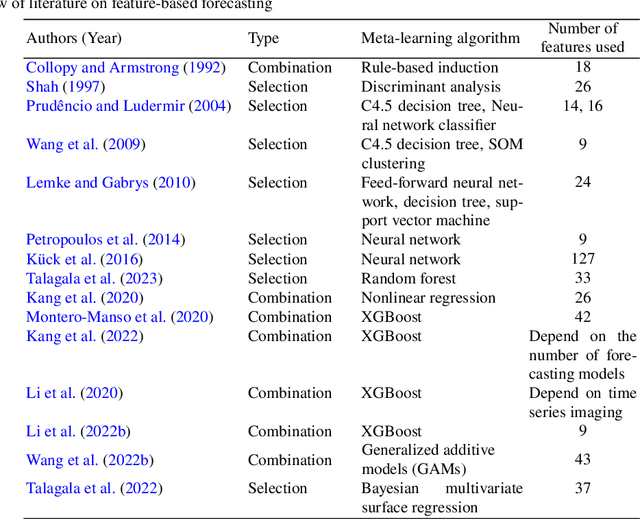
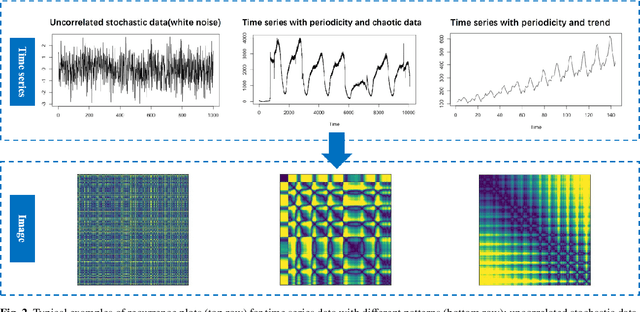
In economics and many other forecasting domains, the real world problems are too complex for a single model that assumes a specific data generation process. The forecasting performance of different methods changes depending on the nature of the time series. When forecasting large collections of time series, two lines of approaches have been developed using time series features, namely feature-based model selection and feature-based model combination. This chapter discusses the state-of-the-art feature-based methods, with reference to open-source software implementations.
Unified Long-Term Time-Series Forecasting Benchmark
Sep 27, 2023
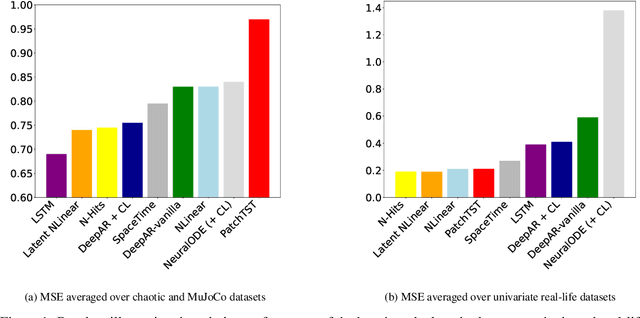
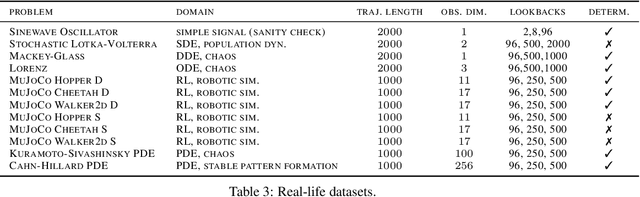
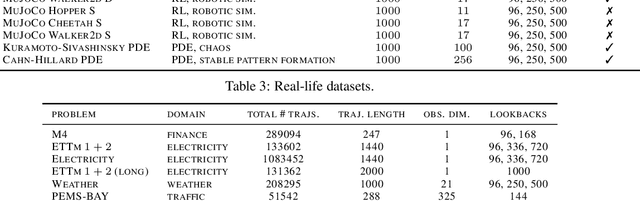
In order to support the advancement of machine learning methods for predicting time-series data, we present a comprehensive dataset designed explicitly for long-term time-series forecasting. We incorporate a collection of datasets obtained from diverse, dynamic systems and real-life records. Each dataset is standardized by dividing it into training and test trajectories with predetermined lookback lengths. We include trajectories of length up to $2000$ to ensure a reliable evaluation of long-term forecasting capabilities. To determine the most effective model in diverse scenarios, we conduct an extensive benchmarking analysis using classical and state-of-the-art models, namely LSTM, DeepAR, NLinear, N-Hits, PatchTST, and LatentODE. Our findings reveal intriguing performance comparisons among these models, highlighting the dataset-dependent nature of model effectiveness. Notably, we introduce a custom latent NLinear model and enhance DeepAR with a curriculum learning phase. Both consistently outperform their vanilla counterparts.
VoxNeRF: Bridging Voxel Representation and Neural Radiance Fields for Enhanced Indoor View Synthesis
Nov 09, 2023Creating high-quality view synthesis is essential for immersive applications but continues to be problematic, particularly in indoor environments and for real-time deployment. Current techniques frequently require extensive computational time for both training and rendering, and often produce less-than-ideal 3D representations due to inadequate geometric structuring. To overcome this, we introduce VoxNeRF, a novel approach that leverages volumetric representations to enhance the quality and efficiency of indoor view synthesis. Firstly, VoxNeRF constructs a structured scene geometry and converts it into a voxel-based representation. We employ multi-resolution hash grids to adaptively capture spatial features, effectively managing occlusions and the intricate geometry of indoor scenes. Secondly, we propose a unique voxel-guided efficient sampling technique. This innovation selectively focuses computational resources on the most relevant portions of ray segments, substantially reducing optimization time. We validate our approach against three public indoor datasets and demonstrate that VoxNeRF outperforms state-of-the-art methods. Remarkably, it achieves these gains while reducing both training and rendering times, surpassing even Instant-NGP in speed and bringing the technology closer to real-time.