 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise localization within the GI tract by combining classification of CNNs and time-series analysis of HMMs
Oct 11, 2023This paper presents a method to efficiently classify the gastroenterologic section of images derived from Video Capsule Endoscopy (VCE) studies by exploring the combination of a Convolutional Neural Network (CNN) for classification with the time-series analysis properties of a Hidden Markov Model (HMM). It is demonstrated that successive time-series analysis identifies and corrects errors in the CNN output. Our approach achieves an accuracy of $98.04\%$ on the Rhode Island (RI) Gastroenterology dataset. This allows for precise localization within the gastrointestinal (GI) tract while requiring only approximately 1M parameters and thus, provides a method suitable for low power devices
HW-Aware Initialization of DNN Auto-Tuning to Improve Exploration Time and Robustness
May 31, 2022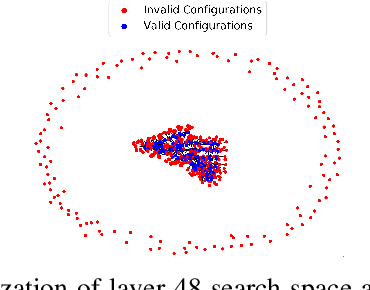
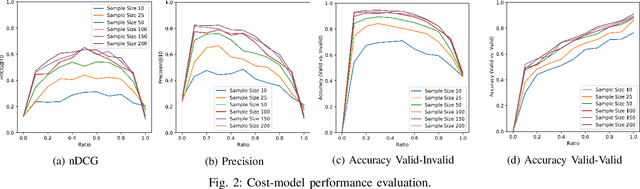
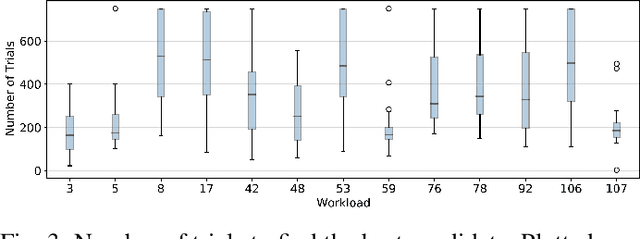
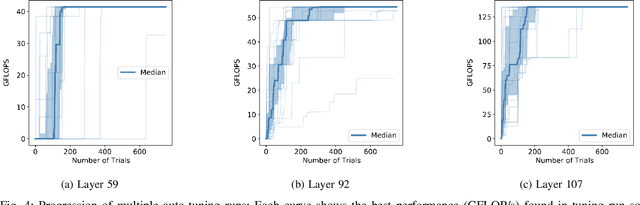
The process of optimizing the latency of DNN operators with ML models and hardware-in-the-loop, called auto-tuning, has established itself as a pervasive method for the deployment of neural networks. From a search space of loop-optimizations, the candidate providing the best performance has to be selected. Performance of individual configurations is evaluated through hardware measurements. The combinatorial explosion of possible configurations, together with the cost of hardware evaluation makes exhaustive explorations of the search space infeasible in practice. Machine Learning methods, like random forests or reinforcement learning are used to aid in the selection of candidates for hardware evaluation. For general purpose hardware like x86 and GPGPU architectures impressive performance gains can be achieved, compared to hand-optimized libraries like cuDNN. The method is also useful in the space of hardware accelerators with less wide-spread adoption, where a high-performance library is not always available. However, hardware accelerators are often less flexible with respect to their programming which leads to operator configurations not executable on the hardware target. This work evaluates how these invalid configurations affect the auto-tuning process and its underlying performance prediction model for the VTA hardware. From these results, a validity-driven initialization method for AutoTVM is developed, only requiring 41.6% of the necessary hardware measurements to find the best solution, while improving search robustness.