 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Anomaly Detection for Capsule Endoscopy Using Ensemble Learning Strategies
Apr 08, 2025Capsule endoscopy is a method to capture images of the gastrointestinal tract and screen for diseases which might remain hidden if investigated with standard endoscopes. Due to the limited size of a video capsule, embedding AI models directly into the capsule demands careful consideration of the model size and thus complicates anomaly detection in this field. Furthermore, the scarcity of available data in this domain poses an ongoing challenge to achieving effective anomaly detection. Thus, this work introduces an ensemble strategy to address this challenge in anomaly detection tasks in video capsule endoscopies, requiring only a small number of individual neural networks during both the training and inference phases. Ensemble learning combines the predictions of multiple independently trained neural networks. This has shown to be highly effective in enhancing both the accuracy and robustness of machine learning models. However, this comes at the cost of higher memory usage and increased computational effort, which quickly becomes prohibitive in many real-world applications. Instead of applying the same training algorithm to each individual network, we propose using various loss functions, drawn from the anomaly detection field, to train each network. The methods are validated on the two largest publicly available datasets for video capsule endoscopy images, the Galar and the Kvasir-Capsule dataset. We achieve an AUC score of 76.86% on the Kvasir-Capsule and an AUC score of 76.98% on the Galar dataset. Our approach outperforms current baselines with significantly fewer parameters across all models, which is a crucial step towards incorporating artificial intelligence into capsule endoscopies.
Energy-Efficient Seizure Detection Suitable for low-power Applications
Jun 19, 2024



Epilepsy is the most common, chronic, neurological disease worldwide and is typically accompanied by reoccurring seizures. Neuro implants can be used for effective treatment by suppressing an upcoming seizure upon detection. Due to the restricted size and limited battery lifetime of those medical devices, the employed approach also needs to be limited in size and have low energy requirements. We present an energy-efficient seizure detection approach involving a TC-ResNet and time-series analysis which is suitable for low-power edge devices. The presented approach allows for accurate seizure detection without preceding feature extraction while considering the stringent hardware requirements of neural implants. The approach is validated using the CHB-MIT Scalp EEG Database with a 32-bit floating point model and a hardware suitable 4-bit fixed point model. The presented method achieves an accuracy of 95.28%, a sensitivity of 92.34% and an AUC score of 0.9384 on this dataset with 4-bit fixed point representation. Furthermore, the power consumption of the model is measured with the low-power AI accelerator UltraTrail, which only requires 495 nW on average. Due to this low-power consumption this classification approach is suitable for real-time seizure detection on low-power wearable devices such as neural implants.
Precise localization within the GI tract by combining classification of CNNs and time-series analysis of HMMs
Oct 11, 2023This paper presents a method to efficiently classify the gastroenterologic section of images derived from Video Capsule Endoscopy (VCE) studies by exploring the combination of a Convolutional Neural Network (CNN) for classification with the time-series analysis properties of a Hidden Markov Model (HMM). It is demonstrated that successive time-series analysis identifies and corrects errors in the CNN output. Our approach achieves an accuracy of $98.04\%$ on the Rhode Island (RI) Gastroenterology dataset. This allows for precise localization within the gastrointestinal (GI) tract while requiring only approximately 1M parameters and thus, provides a method suitable for low power devices
Hardware Accelerator and Neural Network Co-Optimization for Ultra-Low-Power Audio Processing Devices
Sep 08, 2022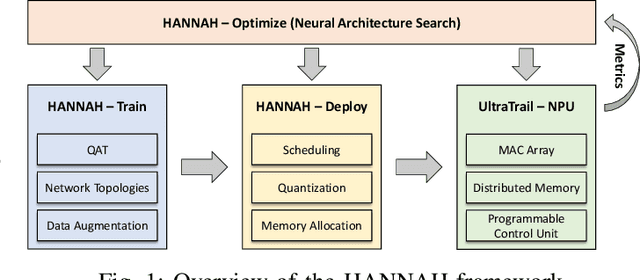
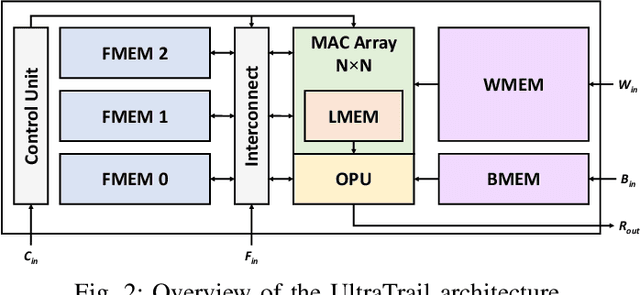
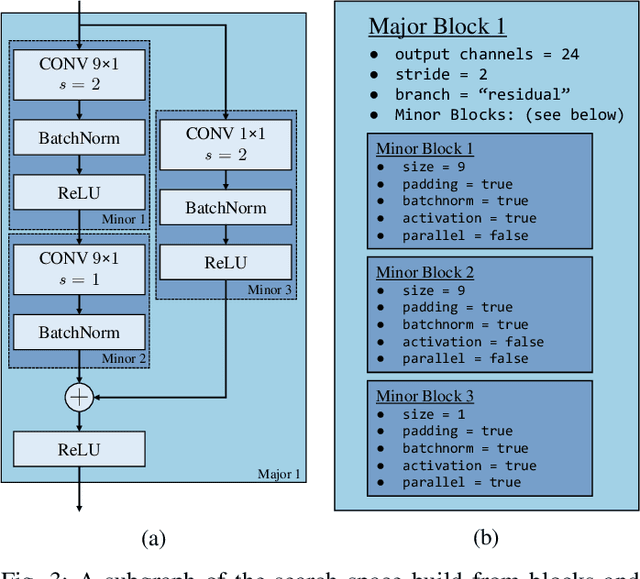
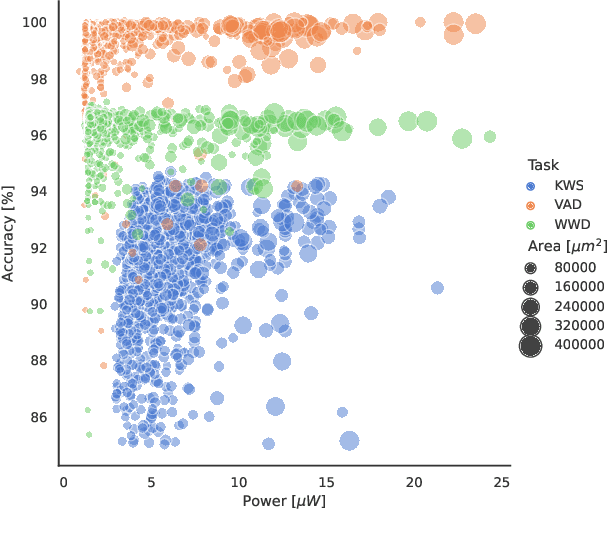
The increasing spread of artificial neural networks does not stop at ultralow-power edge devices. However, these very often have high computational demand and require specialized hardware accelerators to ensure the design meets power and performance constraints. The manual optimization of neural networks along with the corresponding hardware accelerators can be very challenging. This paper presents HANNAH (Hardware Accelerator and Neural Network seArcH), a framework for automated and combined hardware/software co-design of deep neural networks and hardware accelerators for resource and power-constrained edge devices. The optimization approach uses an evolution-based search algorithm, a neural network template technique, and analytical KPI models for the configurable UltraTrail hardware accelerator template to find an optimized neural network and accelerator configuration. We demonstrate that HANNAH can find suitable neural networks with minimized power consumption and high accuracy for different audio classification tasks such as single-class wake word detection, multi-class keyword detection, and voice activity detection, which are superior to the related work.
Behavior of Keyword Spotting Networks Under Noisy Conditions
Sep 15, 2021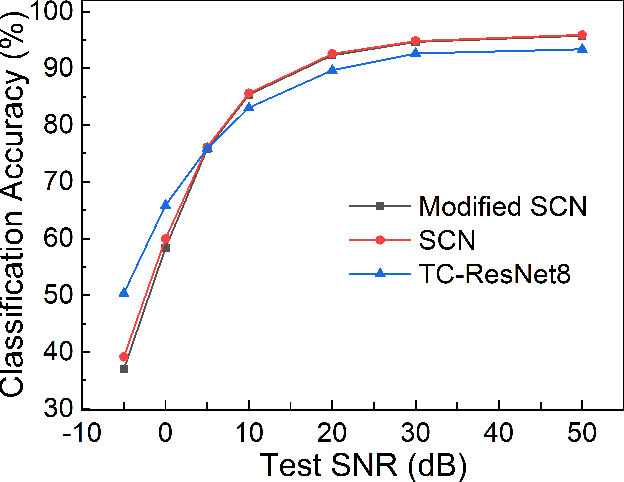
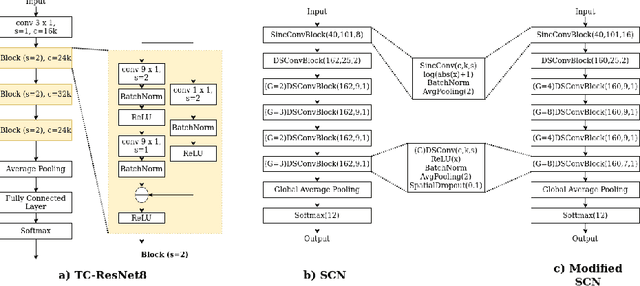
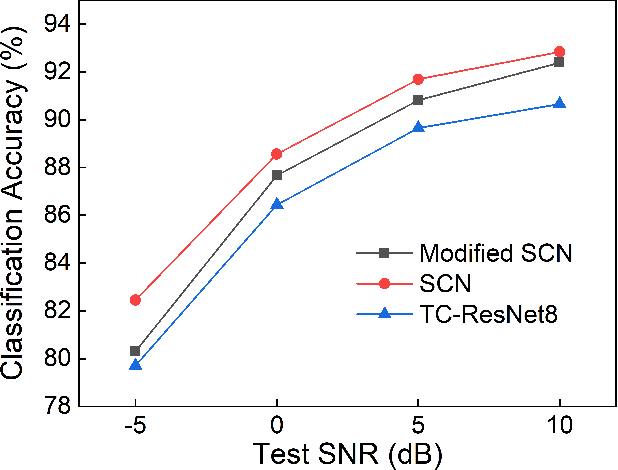
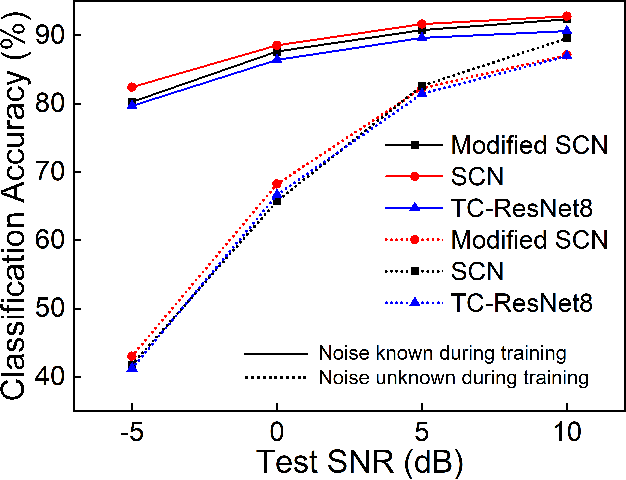
Keyword spotting (KWS) is becoming a ubiquitous need with the advancement in artificial intelligence and smart devices. Recent work in this field have focused on several different architectures to achieve good results on datasets with low to moderate noise. However, the performance of these models deteriorates under high noise conditions as shown by our experiments. In our paper, we present an extensive comparison between state-of-the-art KWS networks under various noisy conditions. We also suggest adaptive batch normalization as a technique to improve the performance of the networks when the noise files are unknown during the training phase. The results of such high noise characterization enable future work in developing models that perform better in the aforementioned conditions.
* 11 pages, 5 figures, Published in Lecture Notes in Computer Science book series (LNCS, volume 12891)