 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink over Trajectories: Leveraging Video Generation to Reconstruct GPS Trajectories from Cellular Signaling
Mar 27, 2026Mobile devices continuously interact with cellular base stations, generating massive volumes of signaling records that provide broad coverage for understanding human mobility. However, such records offer only coarse location cues (e.g., serving-cell identifiers) and therefore limit their direct use in applications that require high-precision GPS trajectories. This paper studies the Sig2GPS problem: reconstructing GPS trajectories from cellular signaling. Inspired by domain experts often lay the signaling trace on the map and sketch the corresponding GPS route, unlike conventional solutions that rely on complex multi-stage engineering pipelines or regress coordinates, Sig2GPS is reframed as an image-to-video generation task that directly operates in the map-visual domain: signaling traces are rendered on a map, and a video generation model is trained to draw a continuous GPS path. To support this paradigm, a paired signaling-to-trajectory video dataset is constructed to fine-tune an open-source video model, and a trajectory-aware reinforcement learning-based optimization method is introduced to improve generation fidelity via rewards. Experiments on large-scale real-world datasets show substantial improvements over strong engineered and learning-based baselines, while additional results on next GPS prediction indicate scalability and cross-city transferability. Overall, these results suggest that map-visual video generation provides a practical interface for trajectory data mining by enabling direct generation and refinement of continuous paths under map constraints.
The Sonar Moment: Benchmarking Audio-Language Models in Audio Geo-Localization
Jan 06, 2026Geo-localization aims to infer the geographic origin of a given signal. In computer vision, geo-localization has served as a demanding benchmark for compositional reasoning and is relevant to public safety. In contrast, progress on audio geo-localization has been constrained by the lack of high-quality audio-location pairs. To address this gap, we introduce AGL1K, the first audio geo-localization benchmark for audio language models (ALMs), spanning 72 countries and territories. To extract reliably localizable samples from a crowd-sourced platform, we propose the Audio Localizability metric that quantifies the informativeness of each recording, yielding 1,444 curated audio clips. Evaluations on 16 ALMs show that ALMs have emerged with audio geo-localization capability. We find that closed-source models substantially outperform open-source models, and that linguistic clues often dominate as a scaffold for prediction. We further analyze ALMs' reasoning traces, regional bias, error causes, and the interpretability of the localizability metric. Overall, AGL1K establishes a benchmark for audio geo-localization and may advance ALMs with better geospatial reasoning capability.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025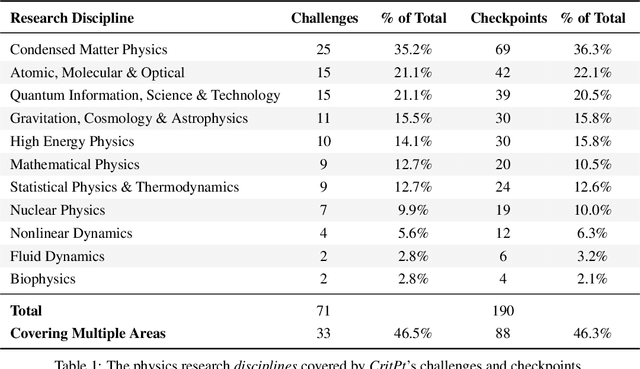



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Regions are Who Walk Them: a Large Pre-trained Spatiotemporal Model Based on Human Mobility for Ubiquitous Urban Sensing
Nov 17, 2023User profiling and region analysis are two tasks of significant commercial value. However, in practical applications, modeling different features typically involves four main steps: data preparation, data processing, model establishment, evaluation, and optimization. This process is time-consuming and labor-intensive. Repeating this workflow for each feature results in abundant development time for tasks and a reduced overall volume of task development. Indeed, human mobility data contains a wealth of information. Several successful cases suggest that conducting in-depth analysis of population movement data could potentially yield meaningful profiles about users and areas. Nonetheless, most related works have not thoroughly utilized the semantic information within human mobility data and trained on a fixed number of the regions. To tap into the rich information within population movement, based on the perspective that Regions Are Who walk them, we propose a large spatiotemporal model based on trajectories (RAW). It possesses the following characteristics: 1) Tailored for trajectory data, introducing a GPT-like structure with a parameter count of up to 1B; 2) Introducing a spatiotemporal fine-tuning module, interpreting trajectories as collection of users to derive arbitrary region embedding. This framework allows rapid task development based on the large spatiotemporal model. We conducted extensive experiments to validate the effectiveness of our proposed large spatiotemporal model. It's evident that our proposed method, relying solely on human mobility data without additional features, exhibits a certain level of relevance in user profiling and region analysis. Moreover, our model showcases promising predictive capabilities in trajectory generation tasks based on the current state, offering the potential for further innovative work utilizing this large spatiotemporal model.
Dynamic Graph Learning Based on Hierarchical Memory for Origin-Destination Demand Prediction
May 29, 2022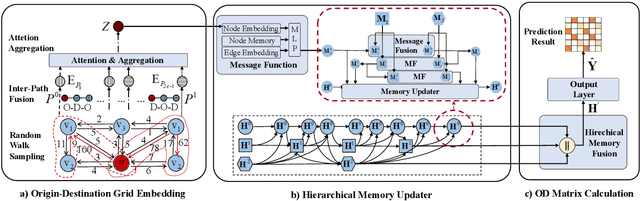
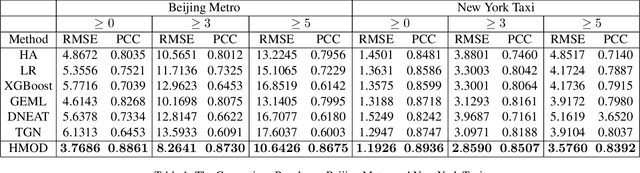
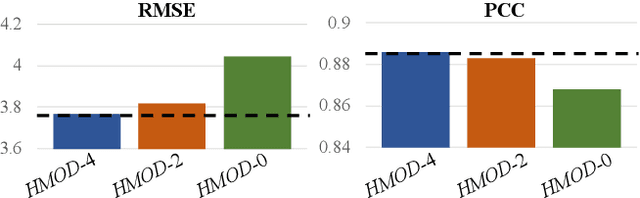
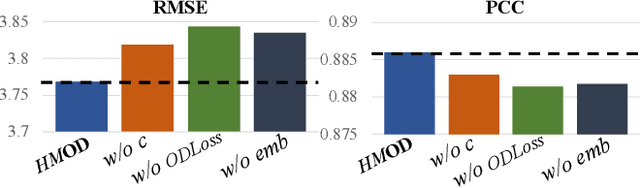
Recent years have witnessed a rapid growth of applying deep spatiotemporal methods in traffic forecasting. However, the prediction of origin-destination (OD) demands is still a challenging problem since the number of OD pairs is usually quadratic to the number of stations. In this case, most of the existing spatiotemporal methods fail to handle spatial relations on such a large scale. To address this problem, this paper provides a dynamic graph representation learning framework for OD demands prediction. In particular, a hierarchical memory updater is first proposed to maintain a time-aware representation for each node, and the representations are updated according to the most recently observed OD trips in continuous-time and multiple discrete-time ways. Second, a spatiotemporal propagation mechanism is provided to aggregate representations of neighbor nodes along a random spatiotemporal route which treats origin and destination as two different semantic entities. Last, an objective function is designed to derive the future OD demands according to the most recent node representations, and also to tackle the data sparsity problem in OD prediction. Extensive experiments have been conducted on two real-world datasets, and the experimental results demonstrate the superiority of the proposed method. The code and data are available at https://github.com/Rising0321/HMOD.