 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerating Magnetic Resonance Parametric Mapping Using Simultaneously Spatial Patch-based and Parametric Group-based Low-rank Tensors (SMART)
Jul 17, 2022
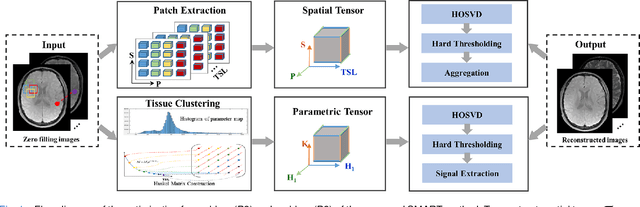
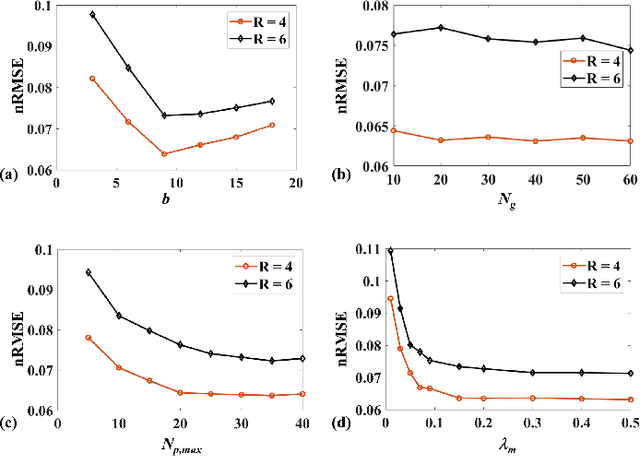
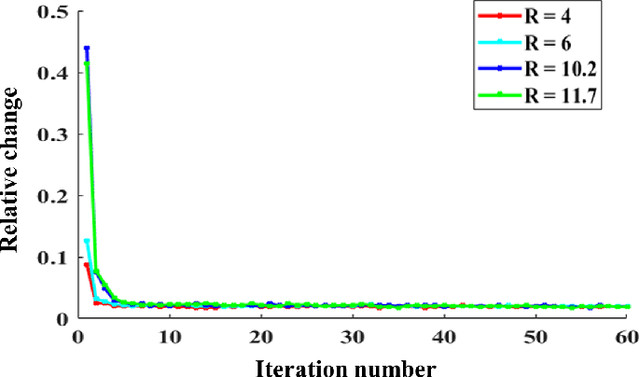
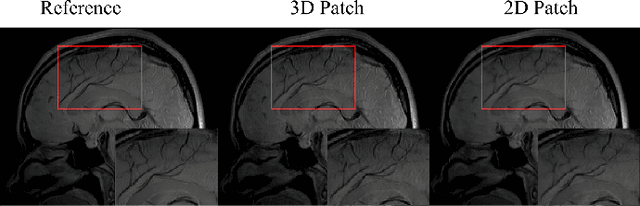
Quantitative magnetic resonance (MR) parametric mapping is a promising approach for characterizing intrinsic tissue-dependent information. However, long scan time significantly hinders its widespread applications. Recently, low-rank tensor has been employed and demonstrated good performance in accelerating MR parametricmapping. In this study, we propose a novel method that uses spatial patch-based and parametric group-based low rank tensors simultaneously (SMART) to reconstruct images from highly undersampled k-space data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and similarities between the contrast images in parametric mapping. The parametric group based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce the multidimensional low-rankness in the reconstruction process. In vivo brain datasets were used to demonstrate the validity of the proposed method. Experimental results have demonstrated that the proposed method achieves 11.7-fold and 13.21-fold accelerations in two-dimensional and three-dimensional acquisitions, respectively, with more accurate reconstructed images and maps than several state-of-the-art methods. Prospective reconstruction results further demonstrate the capability of the SMART method in accelerating MR quantitative imaging.
TimeGym: Debugging for Time Series Modeling in Python
May 04, 2021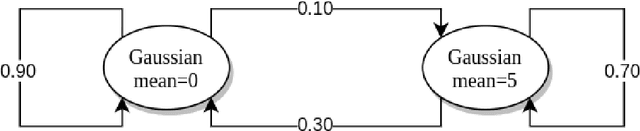
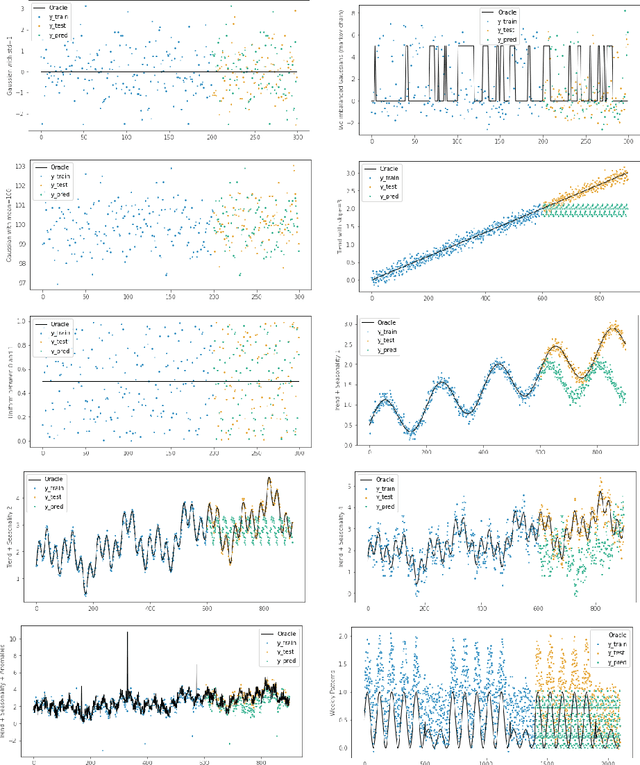
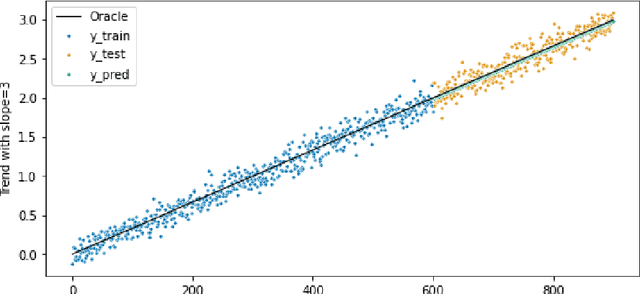
We introduce the TimeGym Forecasting Debugging Toolkit, a Python library for testing and debugging time series forecasting pipelines. TimeGym simplifies the testing forecasting pipeline by providing generic tests for forecasting pipelines fresh out of the box. These tests are based on common modeling challenges of time series. Our library enables forecasters to apply a Test-Driven Development approach to forecast modeling, using specified oracles to generate artificial data with noise.
Super Vision Transformer
May 26, 2022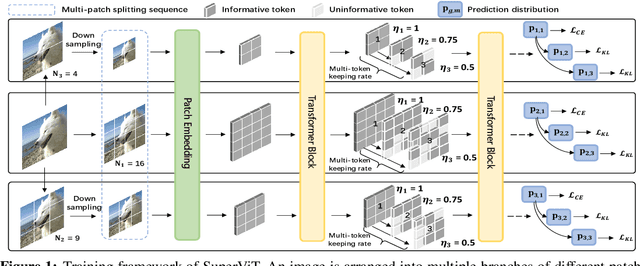
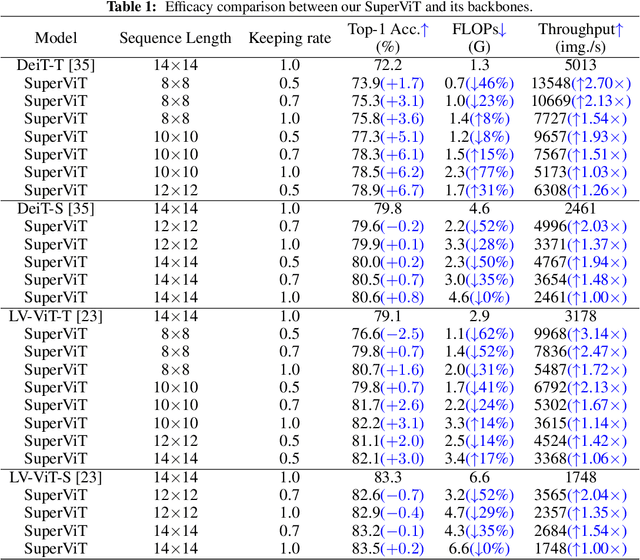
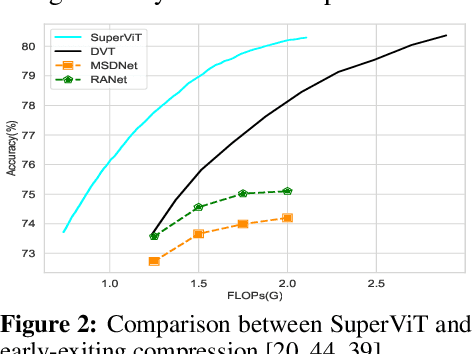
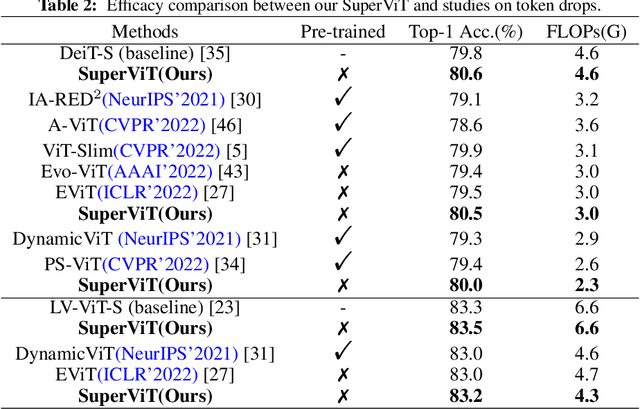
We attempt to reduce the computational costs in vision transformers (ViTs), which increase quadratically in the token number. We present a novel training paradigm that trains only one ViT model at a time, but is capable of providing improved image recognition performance with various computational costs. Here, the trained ViT model, termed super vision transformer (SuperViT), is empowered with the versatile ability to solve incoming patches of multiple sizes as well as preserve informative tokens with multiple keeping rates (the ratio of keeping tokens) to achieve good hardware efficiency for inference, given that the available hardware resources often change from time to time. Experimental results on ImageNet demonstrate that our SuperViT can considerably reduce the computational costs of ViT models with even performance increase. For example, we reduce 2x FLOPs of DeiT-S while increasing the Top-1 accuracy by 0.2% and 0.7% for 1.5x reduction. Also, our SuperViT significantly outperforms existing studies on efficient vision transformers. For example, when consuming the same amount of FLOPs, our SuperViT surpasses the recent state-of-the-art (SoTA) EViT by 1.1% when using DeiT-S as their backbones. The project of this work is made publicly available at https://github.com/lmbxmu/SuperViT.
Symplectic Transformations on Wigner Distributions and Time Frequency Signal Design
Apr 26, 2021This work considers uncertainty relations on time frequency distributions from a signal processing viewpoint. An uncertainty relation on the marginalizable time frequency distributions is given. A result from quantum mechanics is used on Wigner distributions and marginalizable time frequency distributions to investigate the change in variance of time and frequency variables from a signal processing perspective. Moreover, operations on signals which leave uncertainty relations unchanged are studied.
Quantifying the value of transient voltage sources
Jun 18, 2022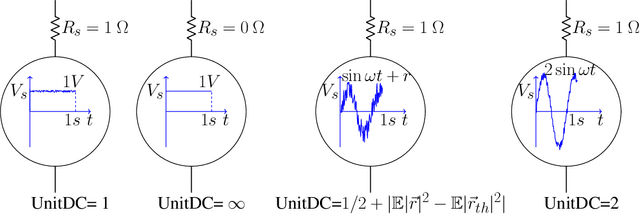

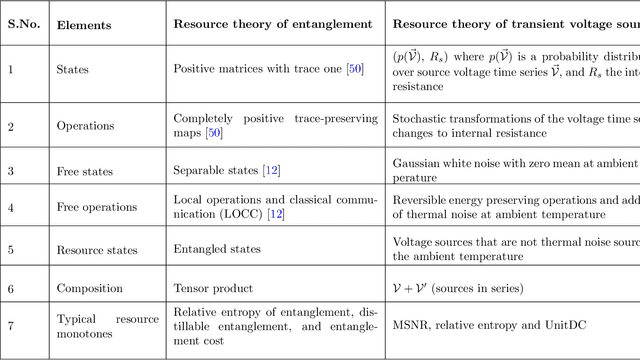
Some voltage sources are transient, lasting only for a moment of time, such as the voltage generated by converting a human motion into electricity. Such sources moreover tend to have a degree of randomness as well as internal resistance. We investigate how to put a number to how valuable a given transient source is. We derive several candidate measures via a systematic approach. We establish an inter-convertibility hierarchy between such sources, where inter-conversion means adding passive interface circuits to the sources. Resistors at the ambient temperature are at the bottom of this hierarchy and sources with low internal resistance and high internal voltages are at the top. We provide three possible measures for a given source that assign a number to the source respecting this hierarchy. One measure captures how much "UnitDC" the source contains, meaning 1V DC with 1$\Omega$ internal resistance for 1s. Another measure relates to the signal-to-noise ratio of the voltage time-series whereas a third is based on the relative entropy between the voltage probability distribution and a thermal noise resistor. We argue that the UnitDc measure is particularly useful by virtue of its operational interpretation in terms of the number of UnitDc sources that one needs to combine to create the source or that can be distilled from the source.
Human Eyes Inspired Recurrent Neural Networks are More Robust Against Adversarial Noises
Jun 15, 2022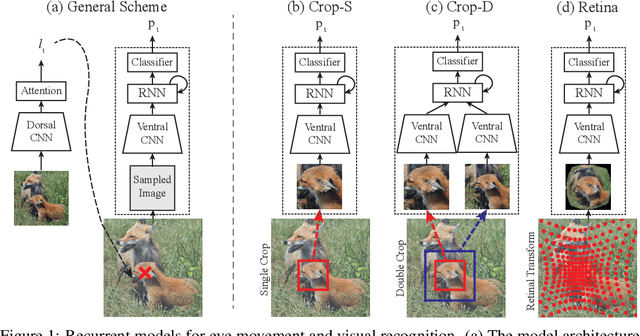

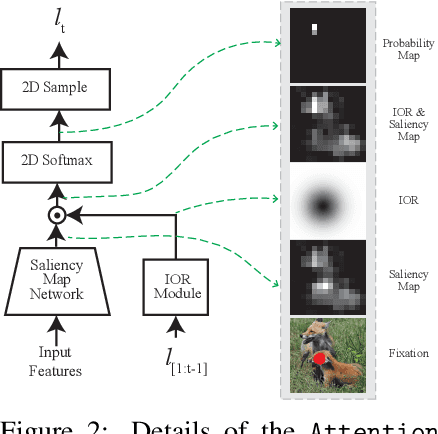

Compared to human vision, computer vision based on convolutional neural networks (CNN) are more vulnerable to adversarial noises. This difference is likely attributable to how the eyes sample visual input and how the brain processes retinal samples through its dorsal and ventral visual pathways, which are under-explored for computer vision. Inspired by the brain, we design recurrent neural networks, including an input sampler that mimics the human retina, a dorsal network that guides where to look next, and a ventral network that represents the retinal samples. Taking these modules together, the models learn to take multiple glances at an image, attend to a salient part at each glance, and accumulate the representation over time to recognize the image. We test such models for their robustness against a varying level of adversarial noises with a special focus on the effect of different input sampling strategies. Our findings suggest that retinal foveation and sampling renders a model more robust against adversarial noises, and the model may correct itself from an attack when it is given a longer time to take more glances at an image. In conclusion, robust visual recognition can benefit from the combined use of three brain-inspired mechanisms: retinal transformation, attention guided eye movement, and recurrent processing, as opposed to feedforward-only CNNs.
Discovering Dynamic Functional Brain Networks via Spatial and Channel-wise Attention
May 31, 2022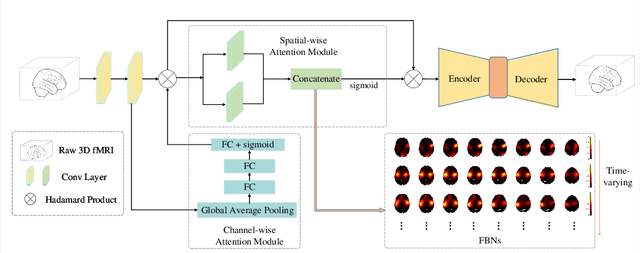
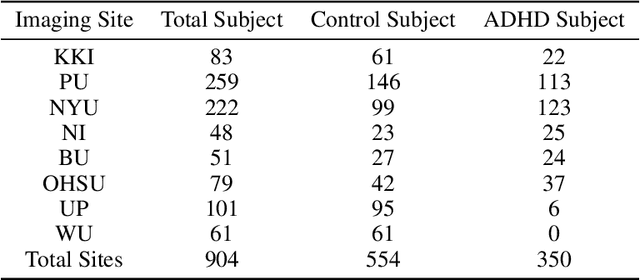


Using deep learning models to recognize functional brain networks (FBNs) in functional magnetic resonance imaging (fMRI) has been attracting increasing interest recently. However, most existing work focuses on detecting static FBNs from entire fMRI signals, such as correlation-based functional connectivity. Sliding-window is a widely used strategy to capture the dynamics of FBNs, but it is still limited in representing intrinsic functional interactive dynamics at each time step. And the number of FBNs usually need to be set manually. More over, due to the complexity of dynamic interactions in brain, traditional linear and shallow models are insufficient in identifying complex and spatially overlapped FBNs across each time step. In this paper, we propose a novel Spatial and Channel-wise Attention Autoencoder (SCAAE) for discovering FBNs dynamically. The core idea of SCAAE is to apply attention mechanism to FBNs construction. Specifically, we designed two attention modules: 1) spatial-wise attention (SA) module to discover FBNs in the spatial domain and 2) a channel-wise attention (CA) module to weigh the channels for selecting the FBNs automatically. We evaluated our approach on ADHD200 dataset and our results indicate that the proposed SCAAE method can effectively recover the dynamic changes of the FBNs at each fMRI time step, without using sliding windows. More importantly, our proposed hybrid attention modules (SA and CA) do not enforce assumptions of linearity and independence as previous methods, and thus provide a novel approach to better understanding dynamic functional brain networks.
RT-RCG: Neural Network and Accelerator Search Towards Effective and Real-time ECG Reconstruction from Intracardiac Electrograms
Nov 04, 2021

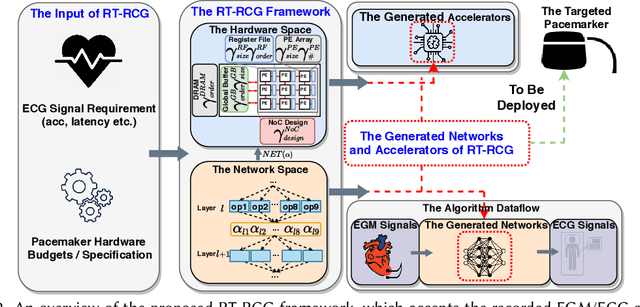
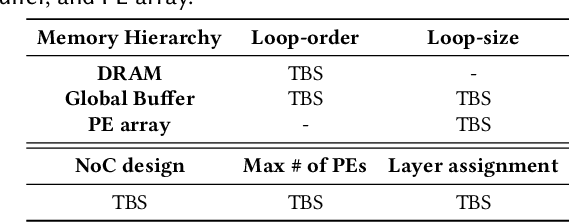
There exists a gap in terms of the signals provided by pacemakers (i.e., intracardiac electrogram (EGM)) and the signals doctors use (i.e., 12-lead electrocardiogram (ECG)) to diagnose abnormal rhythms. Therefore, the former, even if remotely transmitted, are not sufficient for doctors to provide a precise diagnosis, let alone make a timely intervention. To close this gap and make a heuristic step towards real-time critical intervention in instant response to irregular and infrequent ventricular rhythms, we propose a new framework dubbed RT-RCG to automatically search for (1) efficient Deep Neural Network (DNN) structures and then (2)corresponding accelerators, to enable Real-Time and high-quality Reconstruction of ECG signals from EGM signals. Specifically, RT-RCG proposes a new DNN search space tailored for ECG reconstruction from EGM signals, and incorporates a differentiable acceleration search (DAS) engine to efficiently navigate over the large and discrete accelerator design space to generate optimized accelerators. Extensive experiments and ablation studies under various settings consistently validate the effectiveness of our RT-RCG. To the best of our knowledge, RT-RCG is the first to leverage neural architecture search (NAS) to simultaneously tackle both reconstruction efficacy and efficiency.
On the Versatile Uses of Partial Distance Correlation in Deep Learning
Jul 20, 2022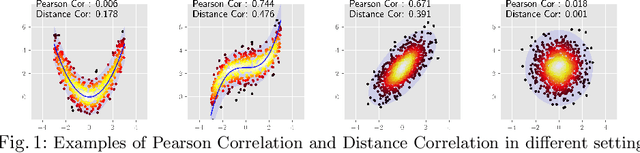
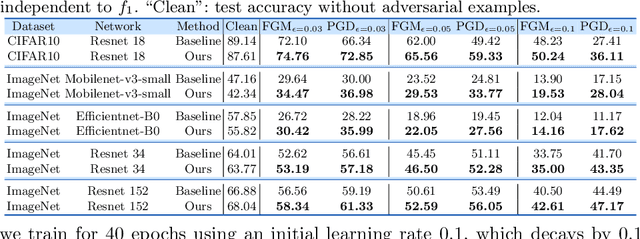
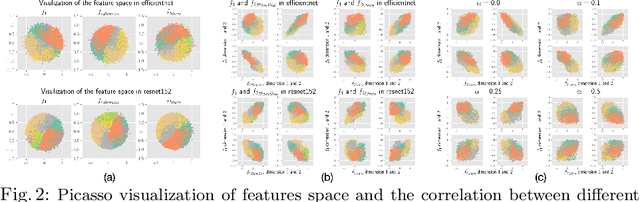
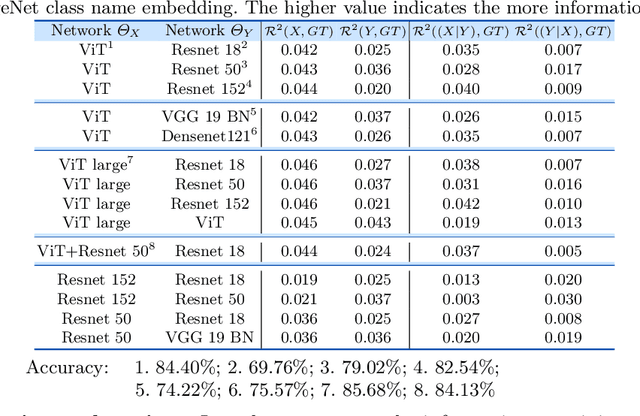
Comparing the functional behavior of neural network models, whether it is a single network over time or two (or more networks) during or post-training, is an essential step in understanding what they are learning (and what they are not), and for identifying strategies for regularization or efficiency improvements. Despite recent progress, e.g., comparing vision transformers to CNNs, systematic comparison of function, especially across different networks, remains difficult and is often carried out layer by layer. Approaches such as canonical correlation analysis (CCA) are applicable in principle, but have been sparingly used so far. In this paper, we revisit a (less widely known) from statistics, called distance correlation (and its partial variant), designed to evaluate correlation between feature spaces of different dimensions. We describe the steps necessary to carry out its deployment for large scale models -- this opens the door to a surprising array of applications ranging from conditioning one deep model w.r.t. another, learning disentangled representations as well as optimizing diverse models that would directly be more robust to adversarial attacks. Our experiments suggest a versatile regularizer (or constraint) with many advantages, which avoids some of the common difficulties one faces in such analyses. Code is at https://github.com/zhenxingjian/Partial_Distance_Correlation.
Rethinking Generalization in Few-Shot Classification
Jun 15, 2022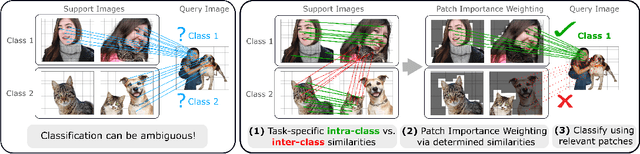
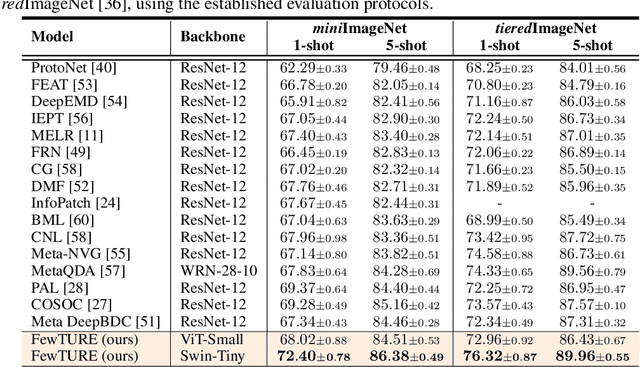
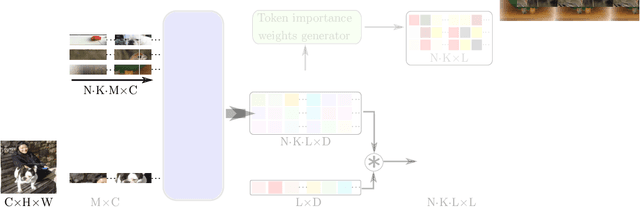
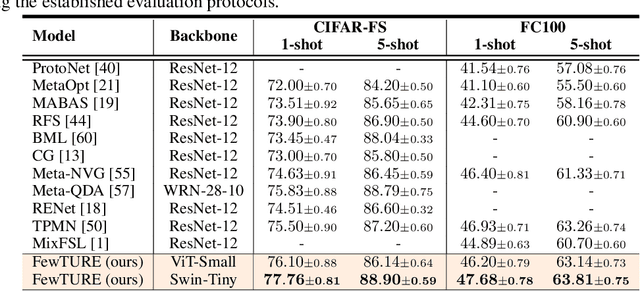
Single image-level annotations only correctly describe an often small subset of an image's content, particularly when complex real-world scenes are depicted. While this might be acceptable in many classification scenarios, it poses a significant challenge for applications where the set of classes differs significantly between training and test time. In this paper, we take a closer look at the implications in the context of $\textit{few-shot learning}$. Splitting the input samples into patches and encoding these via the help of Vision Transformers allows us to establish semantic correspondences between local regions across images and independent of their respective class. The most informative patch embeddings for the task at hand are then determined as a function of the support set via online optimization at inference time, additionally providing visual interpretability of `$\textit{what matters most}$' in the image. We build on recent advances in unsupervised training of networks via masked image modelling to overcome the lack of fine-grained labels and learn the more general statistical structure of the data while avoiding negative image-level annotation influence, $\textit{aka}$ supervision collapse. Experimental results show the competitiveness of our approach, achieving new state-of-the-art results on four popular few-shot classification benchmarks for $5$-shot and $1$-shot scenarios.