 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Level Residual Diffusion Transformer: Scalable 3D CT Volume Generation
Jun 18, 2026Generating high-resolution 3D CT volumes with fine details remains challenging due to substantial computational demands and optimization difficulties inherent to existing generative models. In this paper, we propose the Pixel-Level Residual Diffusion Transformer (PRDiT), a scalable generative framework that synthesizes high-quality 3D medical volumes directly at voxel-level. PRDiT introduces a two-stage training architecture comprising 1) a local denoiser in the form of an MLP-based blind estimator operating on overlapping 3D patches to separate low-frequency structures efficiently, and 2) a global residual diffusion transformer employing memory-efficient attention to model and refine high-frequency residuals across entire volumes. This coarse-to-fine modeling strategy simplifies optimization, enhances training stability, and effectively preserves subtle structures without the limitations of an autoencoder bottleneck. Extensive experiments conducted on the LIDC-IDRI and RAD-ChestCT datasets demonstrate that PRDiT consistently outperforms state-of-the-art models, such as HA-GAN, 3D LDM and WDM-3D, achieving significantly lower 3D FID, MMD and Wasserstein distance scores.
Deep Learning-Based Computer Vision for Beam Selection and Proactive Blockage Prediction
May 06, 2026Millimeter-wave communication faces two critical challenges: propagation losses requiring costly narrow-beam alignment, and penetration losses causing link failures from blocked line-of-sight paths. We address propagation loss through a novel vision-aided beam selection framework that integrates RGB imagery with received power profiles for efficient transmitter identification and beam prediction. This framework achieves 98.96% top-5 beam prediction accuracy, surpassing current state-of-the-art methods by at least 6% across all metrics. We address penetration loss through a proactive blockage prediction framework using a modified object tracker with weighted centroid-based depth estimation. This represents the first analysis of simultaneous non-uniform mobility of both transmitters and obstacles. Evaluated on completely unseen data, this framework achieves over 98% accuracy in predicting blockages up to three frames ahead, establishing strong performance benchmarks.
Few-Shot Multilingual Open-Domain QA from 5 Examples
Feb 27, 2025Recent approaches to multilingual open-domain question answering (MLODQA) have achieved promising results given abundant language-specific training data. However, the considerable annotation cost limits the application of these methods for underrepresented languages. We introduce a \emph{few-shot learning} approach to synthesise large-scale multilingual data from large language models (LLMs). Our method begins with large-scale self-supervised pre-training using WikiData, followed by training on high-quality synthetic multilingual data generated by prompting LLMs with few-shot supervision. The final model, \textsc{FsModQA}, significantly outperforms existing few-shot and supervised baselines in MLODQA and cross-lingual and monolingual retrieval. We further show our method can be extended for effective zero-shot adaptation to new languages through a \emph{cross-lingual prompting} strategy with only English-supervised data, making it a general and applicable solution for MLODQA tasks without costly large-scale annotation.
Sound Judgment: Properties of Consequential Sounds Affecting Human-Perception of Robots
Feb 04, 2025
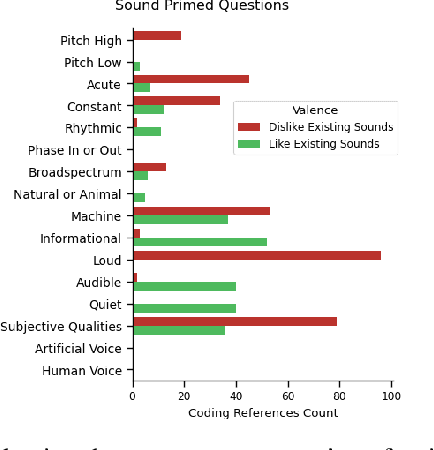
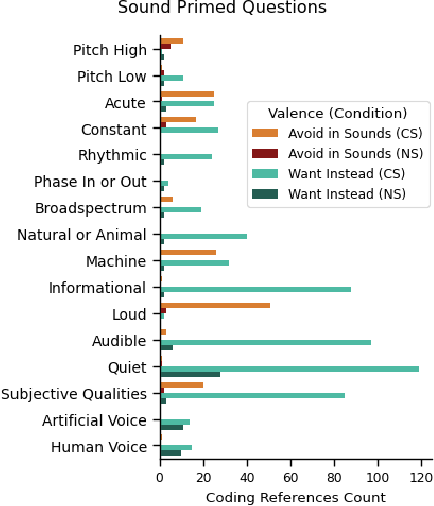
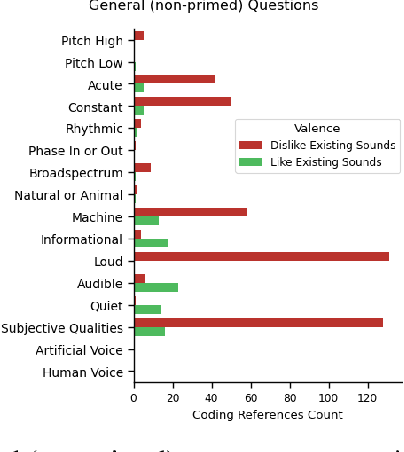
Positive human-perception of robots is critical to achieving sustained use of robots in shared environments. One key factor affecting human-perception of robots are their sounds, especially the consequential sounds which robots (as machines) must produce as they operate. This paper explores qualitative responses from 182 participants to gain insight into human-perception of robot consequential sounds. Participants viewed videos of different robots performing their typical movements, and responded to an online survey regarding their perceptions of robots and the sounds they produce. Topic analysis was used to identify common properties of robot consequential sounds that participants expressed liking, disliking, wanting or wanting to avoid being produced by robots. Alongside expected reports of disliking high pitched and loud sounds, many participants preferred informative and audible sounds (over no sound) to provide predictability of purpose and trajectory of the robot. Rhythmic sounds were preferred over acute or continuous sounds, and many participants wanted more natural sounds (such as wind or cat purrs) in-place of machine-like noise. The results presented in this paper support future research on methods to improve consequential sounds produced by robots by highlighting features of sounds that cause negative perceptions, and providing insights into sound profile changes for improvement of human-perception of robots, thus enhancing human robot interaction.
Admitting Ignorance Helps the Video Question Answering Models to Answer
Jan 15, 2025



Significant progress has been made in the field of video question answering (VideoQA) thanks to deep learning and large-scale pretraining. Despite the presence of sophisticated model structures and powerful video-text foundation models, most existing methods focus solely on maximizing the correlation between answers and video-question pairs during training. We argue that these models often establish shortcuts, resulting in spurious correlations between questions and answers, especially when the alignment between video and text data is suboptimal. To address these spurious correlations, we propose a novel training framework in which the model is compelled to acknowledge its ignorance when presented with an intervened question, rather than making guesses solely based on superficial question-answer correlations. We introduce methodologies for intervening in questions, utilizing techniques such as displacement and perturbation, and design frameworks for the model to admit its lack of knowledge in both multi-choice VideoQA and open-ended settings. In practice, we integrate a state-of-the-art model into our framework to validate its effectiveness. The results clearly demonstrate that our framework can significantly enhance the performance of VideoQA models with minimal structural modifications.
Efficiently Scanning and Resampling Spatio-Temporal Tasks with Irregular Observations
Oct 11, 2024Various works have aimed at combining the inference efficiency of recurrent models and training parallelism of multi-head attention for sequence modeling. However, most of these works focus on tasks with fixed-dimension observation spaces, such as individual tokens in language modeling or pixels in image completion. To handle an observation space of varying size, we propose a novel algorithm that alternates between cross-attention between a 2D latent state and observation, and a discounted cumulative sum over the sequence dimension to efficiently accumulate historical information. We find this resampling cycle is critical for performance. To evaluate efficient sequence modeling in this domain, we introduce two multi-agent intention tasks: simulated agents chasing bouncing particles and micromanagement analysis in professional StarCraft II games. Our algorithm achieves comparable accuracy with a lower parameter count, faster training and inference compared to existing methods.
Carefully Structured Compression: Efficiently Managing StarCraft II Data
Oct 11, 2024Creation and storage of datasets are often overlooked input costs in machine learning, as many datasets are simple image label pairs or plain text. However, datasets with more complex structures, such as those from the real time strategy game StarCraft II, require more deliberate thought and strategy to reduce cost of ownership. We introduce a serialization framework for StarCraft II that reduces the cost of dataset creation and storage, as well as improving usage ergonomics. We benchmark against the most comparable existing dataset from \textit{AlphaStar-Unplugged} and highlight the benefit of our framework in terms of both the cost of creation and storage. We use our dataset to train deep learning models that exceed the performance of comparable models trained on other datasets. The dataset conversion and usage framework introduced is open source and can be used as a framework for datasets with similar characteristics such as digital twin simulations. Pre-converted StarCraft II tournament data is also available online.
Robots Have Been Seen and Not Heard: Effects of Consequential Sounds on Human-Perception of Robots
Jun 05, 2024



Many people expect robots to move fairly quietly, or make pleasant "beep boop" sounds or jingles similar to what they have observed in videos of robots. Unfortunately, this expectation of quietness does not match reality, as robots make machine sounds, known as 'consequential sounds', as they move and operate. As robots become more prevalent within society, understanding the sounds produced by robots and how these sounds are perceived by people is becoming increasingly important for positive human robot interactions (HRI). This paper investigates how people respond to the consequential sounds of robots, specifically how robots make a participant feel, how much they like the robot, would be distracted by the robot, and a person's desire to colocate with robots. Participants were shown 5 videos of different robots and asked their opinions on the robots and the sounds they made. This was compared with a control condition of completely silent videos. The results in this paper demonstrate with data from 182 participants (858 trials) that consequential sounds produced by robots have a significant negative effect on human perceptions of robots. Firstly there were increased negative 'associated affects' of the participants, such as making them feel more uncomfortable or agitated around the robot. Secondly, the presence of consequential sounds correlated with participants feeling more distracted and less able to focus. Thirdly participants reported being less likely to want to colocate in a shared environment with robots.
Pre-training Cross-lingual Open Domain Question Answering with Large-scale Synthetic Supervision
Feb 26, 2024



Cross-lingual question answering (CLQA) is a complex problem, comprising cross-lingual retrieval from a multilingual knowledge base, followed by answer generation either in English or the query language. Both steps are usually tackled by separate models, requiring substantial annotated datasets, and typically auxiliary resources, like machine translation systems to bridge between languages. In this paper, we show that CLQA can be addressed using a single encoder-decoder model. To effectively train this model, we propose a self-supervised method based on exploiting the cross-lingual link structure within Wikipedia. We demonstrate how linked Wikipedia pages can be used to synthesise supervisory signals for cross-lingual retrieval, through a form of cloze query, and generate more natural queries to supervise answer generation. Together, we show our approach, \texttt{CLASS}, outperforms comparable methods on both supervised and zero-shot language adaptation settings, including those using machine translation.
Perceiving Longer Sequences With Bi-Directional Cross-Attention Transformers
Feb 19, 2024



We present a novel bi-directional Transformer architecture (BiXT) which scales linearly with input size in terms of computational cost and memory consumption, but does not suffer the drop in performance or limitation to only one input modality seen with other efficient Transformer-based approaches. BiXT is inspired by the Perceiver architectures but replaces iterative attention with an efficient bi-directional cross-attention module in which input tokens and latent variables attend to each other simultaneously, leveraging a naturally emerging attention-symmetry between the two. This approach unlocks a key bottleneck experienced by Perceiver-like architectures and enables the processing and interpretation of both semantics (`what') and location (`where') to develop alongside each other over multiple layers -- allowing its direct application to dense and instance-based tasks alike. By combining efficiency with the generality and performance of a full Transformer architecture, BiXT can process longer sequences like point clouds or images at higher feature resolutions and achieves competitive performance across a range of tasks like point cloud part segmentation, semantic image segmentation and image classification.