 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleDL: Towards Scalable and Efficient Runtime Prediction for Distributed Deep Learning Workloads
Nov 13, 2025Deep neural networks (DNNs) form the cornerstone of modern AI services, supporting a wide range of applications, including autonomous driving, chatbots, and recommendation systems. As models increase in size and complexity, DNN workloads such as training and inference tasks impose unprecedented demands on distributed computing resources, making accurate runtime prediction essential for optimizing development and resource allocation. Traditional methods rely on additive computational unit models, limiting their accuracy and generalizability. In contrast, graph-enhanced modeling improves performance but significantly increases data collection costs. Therefore, there is a critical need for a method that strikes a balance between accuracy, generalizability, and data collection costs. To address these challenges, we propose ScaleDL, a novel runtime prediction framework that combines nonlinear layer-wise modeling with graph neural network (GNN)-based cross-layer interaction mechanism, enabling accurate DNN runtime prediction and hierarchical generalizability across different network architectures. Additionally, we employ the D-optimal method to reduce data collection costs. Experiments on the workloads of five popular DNN models demonstrate that ScaleDL enhances runtime prediction accuracy and generalizability, achieving 6 times lower MRE and 5 times lower RMSE compared to baseline models.
Context-Guided Dynamic Retrieval for Improving Generation Quality in RAG Models
Apr 28, 2025



This paper focuses on the dynamic optimization of the Retrieval-Augmented Generation (RAG) architecture. It proposes a state-aware dynamic knowledge retrieval mechanism to enhance semantic understanding and knowledge scheduling efficiency in large language models for open-domain question answering and complex generation tasks. The method introduces a multi-level perceptive retrieval vector construction strategy and a differentiable document matching path. These components enable end-to-end joint training and collaborative optimization of the retrieval and generation modules. This effectively addresses the limitations of static RAG structures in context adaptation and knowledge access. Experiments are conducted on the Natural Questions dataset. The proposed structure is thoroughly evaluated across different large models, including GPT-4, GPT-4o, and DeepSeek. Comparative and ablation experiments from multiple perspectives confirm the significant improvements in BLEU and ROUGE-L scores. The approach also demonstrates stronger robustness and generation consistency in tasks involving semantic ambiguity and multi-document fusion. These results highlight its broad application potential and practical value in building high-quality language generation systems.
Pre-trained Language Models and Few-shot Learning for Medical Entity Extraction
Apr 06, 2025This study proposes a medical entity extraction method based on Transformer to enhance the information extraction capability of medical literature. Considering the professionalism and complexity of medical texts, we compare the performance of different pre-trained language models (BERT, BioBERT, PubMedBERT, ClinicalBERT) in medical entity extraction tasks. Experimental results show that PubMedBERT achieves the best performance (F1-score = 88.8%), indicating that a language model pre-trained on biomedical literature is more effective in the medical domain. In addition, we analyze the impact of different entity extraction methods (CRF, Span-based, Seq2Seq) and find that the Span-based approach performs best in medical entity extraction tasks (F1-score = 88.6%). It demonstrates superior accuracy in identifying entity boundaries. In low-resource scenarios, we further explore the application of Few-shot Learning in medical entity extraction. Experimental results show that even with only 10-shot training samples, the model achieves an F1-score of 79.1%, verifying the effectiveness of Few-shot Learning under limited data conditions. This study confirms that the combination of pre-trained language models and Few-shot Learning can enhance the accuracy of medical entity extraction. Future research can integrate knowledge graphs and active learning strategies to improve the model's generalization and stability, providing a more effective solution for medical NLP research. Keywords- Natural Language Processing, medical named entity recognition, pre-trained language model, Few-shot Learning, information extraction, deep learning
A LongFormer-Based Framework for Accurate and Efficient Medical Text Summarization
Mar 10, 2025This paper proposes a medical text summarization method based on LongFormer, aimed at addressing the challenges faced by existing models when processing long medical texts. Traditional summarization methods are often limited by short-term memory, leading to information loss or reduced summary quality in long texts. LongFormer, by introducing long-range self-attention, effectively captures long-range dependencies in the text, retaining more key information and improving the accuracy and information retention of summaries. Experimental results show that the LongFormer-based model outperforms traditional models, such as RNN, T5, and BERT in automatic evaluation metrics like ROUGE. It also receives high scores in expert evaluations, particularly excelling in information retention and grammatical accuracy. However, there is still room for improvement in terms of conciseness and readability. Some experts noted that the generated summaries contain redundant information, which affects conciseness. Future research will focus on further optimizing the model structure to enhance conciseness and fluency, achieving more efficient medical text summarization. As medical data continues to grow, automated summarization technology will play an increasingly important role in fields such as medical research, clinical decision support, and knowledge management.
A Dual-Stream Neural Network Explains the Functional Segregation of Dorsal and Ventral Visual Pathways in Human Brains
Oct 20, 2023



The human visual system uses two parallel pathways for spatial processing and object recognition. In contrast, computer vision systems tend to use a single feedforward pathway, rendering them less robust, adaptive, or efficient than human vision. To bridge this gap, we developed a dual-stream vision model inspired by the human eyes and brain. At the input level, the model samples two complementary visual patterns to mimic how the human eyes use magnocellular and parvocellular retinal ganglion cells to separate retinal inputs to the brain. At the backend, the model processes the separate input patterns through two branches of convolutional neural networks (CNN) to mimic how the human brain uses the dorsal and ventral cortical pathways for parallel visual processing. The first branch (WhereCNN) samples a global view to learn spatial attention and control eye movements. The second branch (WhatCNN) samples a local view to represent the object around the fixation. Over time, the two branches interact recurrently to build a scene representation from moving fixations. We compared this model with the human brains processing the same movie and evaluated their functional alignment by linear transformation. The WhereCNN and WhatCNN branches were found to differentially match the dorsal and ventral pathways of the visual cortex, respectively, primarily due to their different learning objectives. These model-based results lead us to speculate that the distinct responses and representations of the ventral and dorsal streams are more influenced by their distinct goals in visual attention and object recognition than by their specific bias or selectivity in retinal inputs. This dual-stream model takes a further step in brain-inspired computer vision, enabling parallel neural networks to actively explore and understand the visual surroundings.
Human Eyes Inspired Recurrent Neural Networks are More Robust Against Adversarial Noises
Jun 15, 2022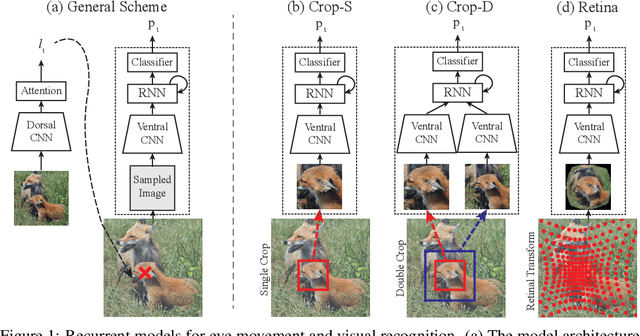

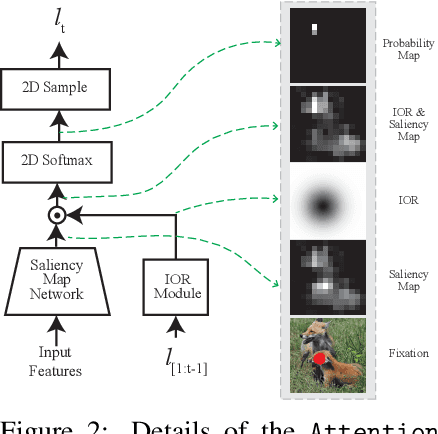

Compared to human vision, computer vision based on convolutional neural networks (CNN) are more vulnerable to adversarial noises. This difference is likely attributable to how the eyes sample visual input and how the brain processes retinal samples through its dorsal and ventral visual pathways, which are under-explored for computer vision. Inspired by the brain, we design recurrent neural networks, including an input sampler that mimics the human retina, a dorsal network that guides where to look next, and a ventral network that represents the retinal samples. Taking these modules together, the models learn to take multiple glances at an image, attend to a salient part at each glance, and accumulate the representation over time to recognize the image. We test such models for their robustness against a varying level of adversarial noises with a special focus on the effect of different input sampling strategies. Our findings suggest that retinal foveation and sampling renders a model more robust against adversarial noises, and the model may correct itself from an attack when it is given a longer time to take more glances at an image. In conclusion, robust visual recognition can benefit from the combined use of three brain-inspired mechanisms: retinal transformation, attention guided eye movement, and recurrent processing, as opposed to feedforward-only CNNs.