 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Jul 22, 2022
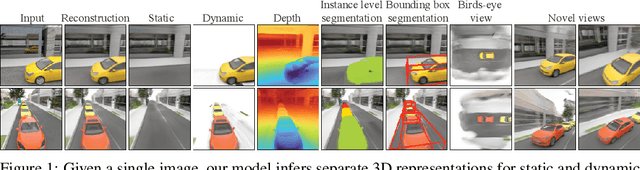
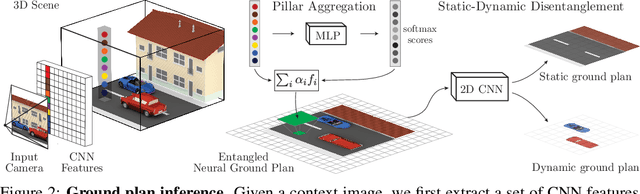
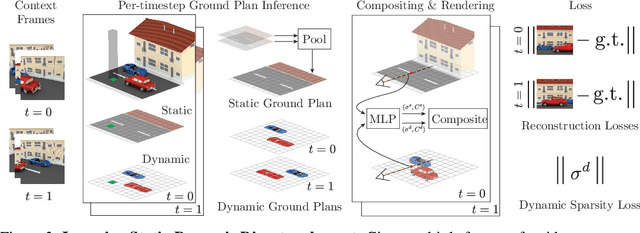

Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
High Performance Simulation for Scalable Multi-Agent Reinforcement Learning
Jul 08, 2022
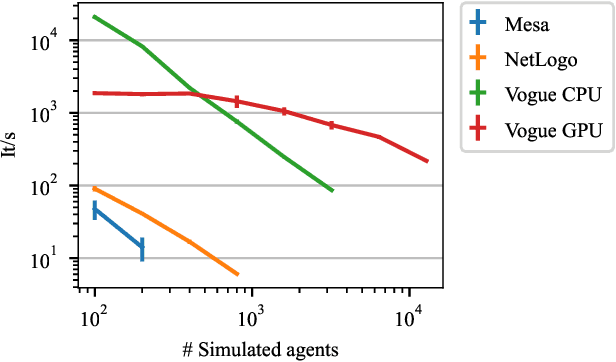
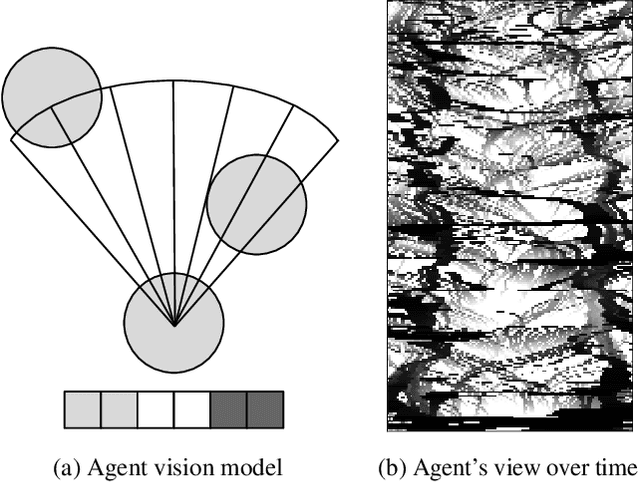
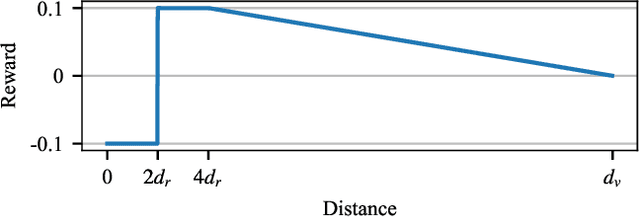
Multi-agent reinforcement learning experiments and open-source training environments are typically limited in scale, supporting tens or sometimes up to hundreds of interacting agents. In this paper we demonstrate the use of Vogue, a high performance agent based model (ABM) framework. Vogue serves as a multi-agent training environment, supporting thousands to tens of thousands of interacting agents while maintaining high training throughput by running both the environment and reinforcement learning (RL) agents on the GPU. High performance multi-agent environments at this scale have the potential to enable the learning of robust and flexible policies for use in ABMs and simulations of complex systems. We demonstrate training performance with two newly developed, large scale multi-agent training environments. Moreover, we show that these environments can train shared RL policies on time-scales of minutes and hours.
Efficiently Learning Single-Arm Fling Motions to Smooth Garments
Jun 17, 2022

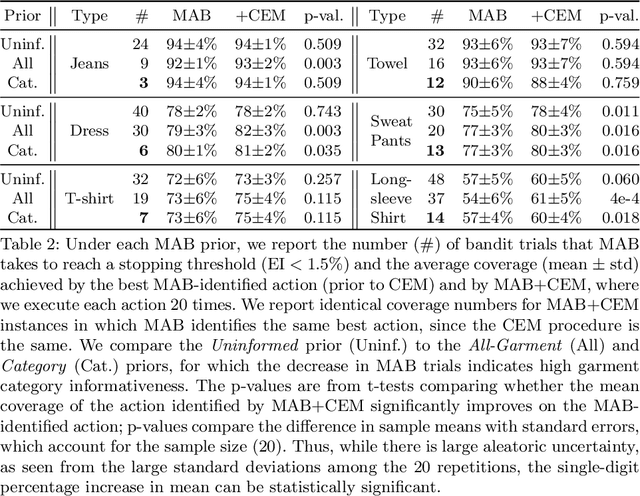
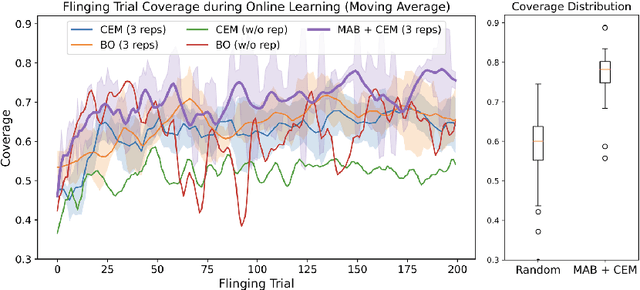
Recent work has shown that 2-arm "fling" motions can be effective for garment smoothing. We consider single-arm fling motions. Unlike 2-arm fling motions, which require little robot trajectory parameter tuning, single-arm fling motions are sensitive to trajectory parameters. We consider a single 6-DOF robot arm that learns fling trajectories to achieve high garment coverage. Given a garment grasp point, the robot explores different parameterized fling trajectories in physical experiments. To improve learning efficiency, we propose a coarse-to-fine learning method that first uses a multi-armed bandit (MAB) framework to efficiently find a candidate fling action, which it then refines via a continuous optimization method. Further, we propose novel training and execution-time stopping criteria based on fling outcome uncertainty. Compared to baselines, we show that the proposed method significantly accelerates learning. Moreover, with prior experience on similar garments collected through self-supervision, the MAB learning time for a new garment is reduced by up to 87%. We evaluate on 6 garment types: towels, T-shirts, long-sleeve shirts, dresses, sweat pants, and jeans. Results suggest that using prior experience, a robot requires under 30 minutes to learn a fling action for a novel garment that achieves 60-94% coverage.
Edge-Aided Sensor Data Sharing in Vehicular Communication Networks
Jun 17, 2022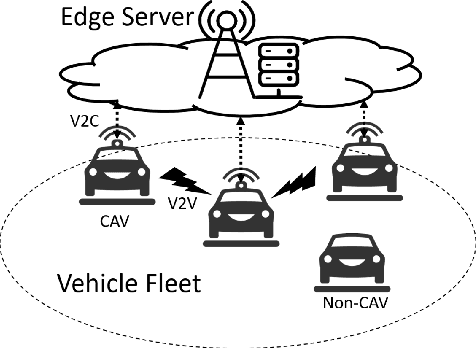
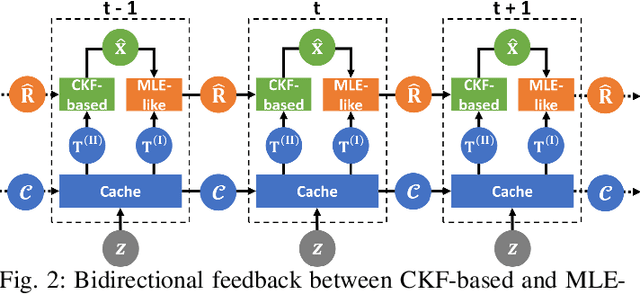
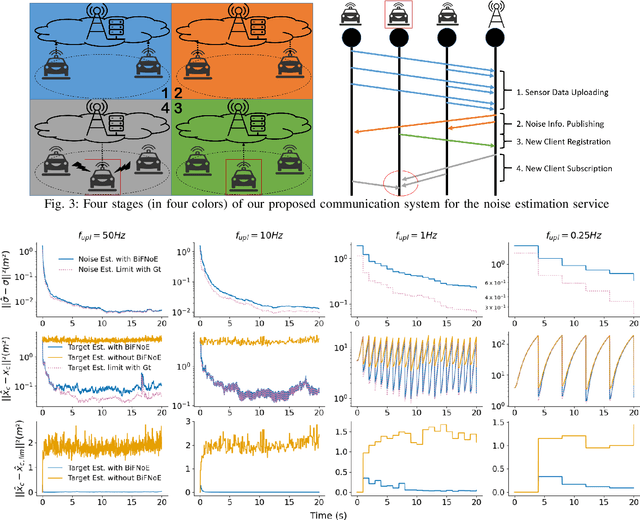
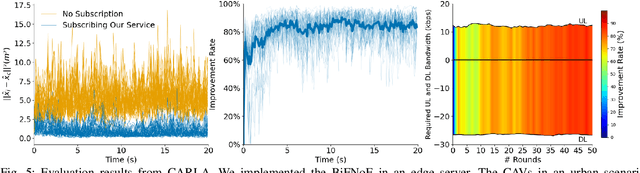
Sensor data sharing in vehicular networks can significantly improve the range and accuracy of environmental perception for connected automated vehicles. Different concepts and schemes for dissemination and fusion of sensor data have been developed. It is common to these schemes that measurement errors of the sensors impair the perception quality and can result in road traffic accidents. Specifically, when the measurement error from the sensors (also referred as measurement noise) is unknown and time varying, the performance of the data fusion process is restricted, which represents a major challenge in the calibration of sensors. In this paper, we consider sensor data sharing and fusion in a vehicular network with both, vehicle-to-infrastructure and vehicle-to-vehicle communication. We propose a method, named Bidirectional Feedback Noise Estimation (BiFNoE), in which an edge server collects and caches sensor measurement data from vehicles. The edge estimates the noise and the targets alternately in double dynamic sliding time windows and enhances the distributed cooperative environment sensing at each vehicle with low communication costs. We evaluate the proposed algorithm and data dissemination strategy in an application scenario by simulation and show that the perception accuracy is on average improved by around 80 % with only 12 kbps uplink and 28 kbps downlink bandwidth.
Efficient Adaptive Regret Minimization
Jul 01, 2022
In online convex optimization the player aims to minimize her regret against a fixed comparator over the entire repeated game. Algorithms that minimize standard regret may converge to a fixed decision, which is undesireable in changing or dynamic environments. This motivates the stronger metric of adaptive regret, or the maximum regret over any continuous sub-interval in time. Existing adaptive regret algorithms suffer from a computational penalty - typically on the order of a multiplicative factor that grows logarithmically in the number of game iterations. In this paper we show how to reduce this computational penalty to be doubly logarithmic in the number of game iterations, and with minimal degradation to the optimal attainable adaptive regret bounds.
Accelerating Magnetic Resonance Parametric Mapping Using Simultaneously Spatial Patch-based and Parametric Group-based Low-rank Tensors (SMART)
Jul 19, 2022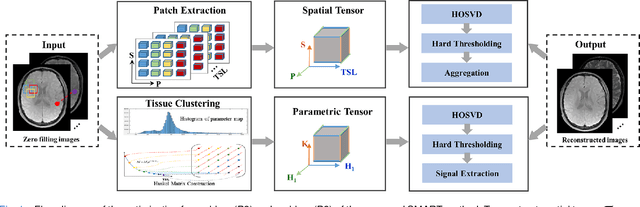
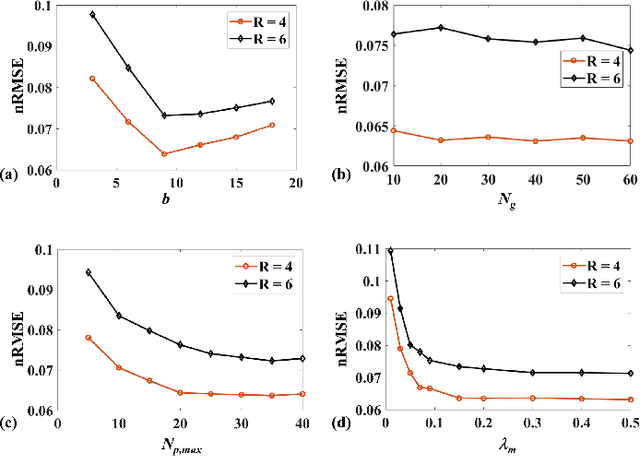
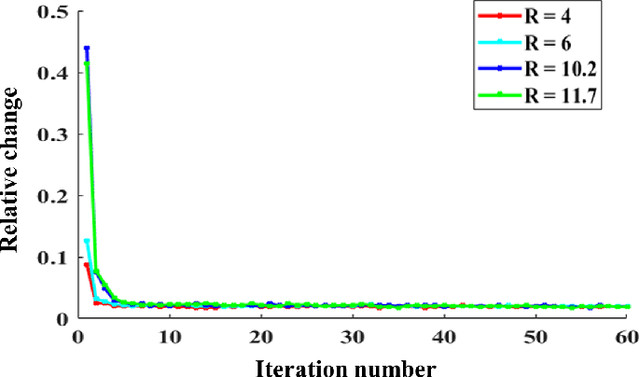
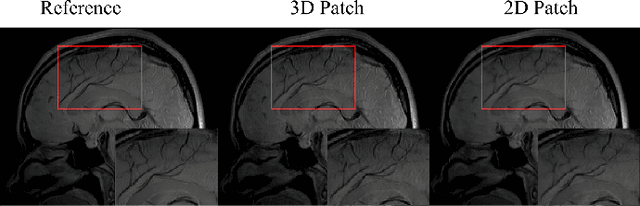
Quantitative magnetic resonance (MR) parametric mapping is a promising approach for characterizing intrinsic tissue-dependent information. However, long scan time significantly hinders its widespread applications. Recently, low-rank tensor has been employed and demonstrated good performance in accelerating MR parametricmapping. In this study, we propose a novel method that uses spatial patch-based and parametric group-based low rank tensors simultaneously (SMART) to reconstruct images from highly undersampled k-space data. The spatial patch-based low-rank tensor exploits the high local and nonlocal redundancies and similarities between the contrast images in parametric mapping. The parametric group based low-rank tensor, which integrates similar exponential behavior of the image signals, is jointly used to enforce the multidimensional low-rankness in the reconstruction process. In vivo brain datasets were used to demonstrate the validity of the proposed method. Experimental results have demonstrated that the proposed method achieves 11.7-fold and 13.21-fold accelerations in two-dimensional and three-dimensional acquisitions, respectively, with more accurate reconstructed images and maps than several state-of-the-art methods. Prospective reconstruction results further demonstrate the capability of the SMART method in accelerating MR quantitative imaging.
Moving Stuff Around: A study on efficiency of moving documents into memory for Neural IR models
May 17, 2022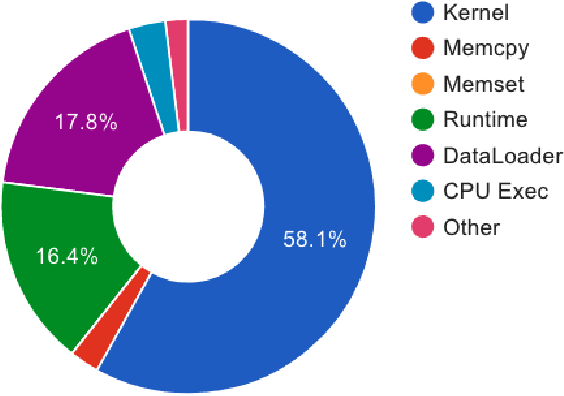



When training neural rankers using Large Language Models, it's expected that a practitioner would make use of multiple GPUs to accelerate the training time. By using more devices, deep learning frameworks, like PyTorch, allow the user to drastically increase the available VRAM pool, making larger batches possible when training, therefore shrinking training time. At the same time, one of the most critical processes, that is generally overlooked when running data-hungry models, is how data is managed between disk, main memory and VRAM. Most open source research implementations overlook this memory hierarchy, and instead resort to loading all documents from disk to main memory and then allowing the framework (e.g., PyTorch) to handle moving data into VRAM. Therefore, with the increasing sizes of datasets dedicated to IR research, a natural question arises: s this the optimal solution for optimizing training time? We here study how three different popular approaches to handling documents for IR datasets behave and how they scale with multiple GPUs. Namely, loading documents directly into memory, reading documents directly from text files with a lookup table and using a library for handling IR datasets (ir_datasets) differ, both in performance (i.e. samples processed per second) and memory footprint. We show that, when using the most popular libraries for neural ranker research (i.e. PyTorch and Hugging Face's Transformers), the practice of loading all documents into main memory is not always the fastest option and is not feasible for setups with more than a couple GPUs. Meanwhile, a good implementation of data streaming from disk can be faster, while being considerably more scalable. We also show how popular techniques for improving loading times, like memory pining, multiple workers, and RAMDISK usage, can reduce the training time further with minor memory overhead.
End-to-end deep learning for directly estimating grape yield from ground-based imagery
Aug 04, 2022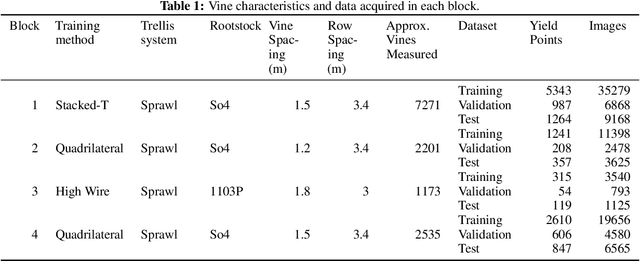
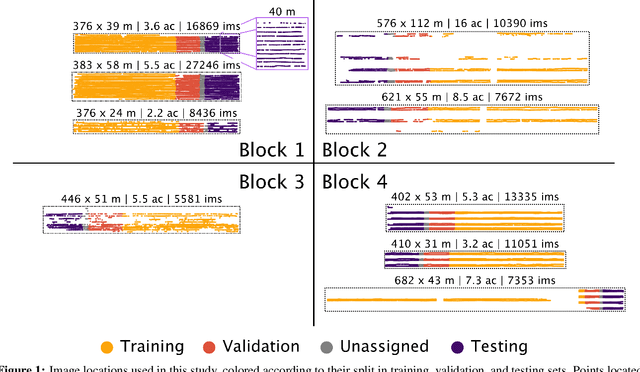
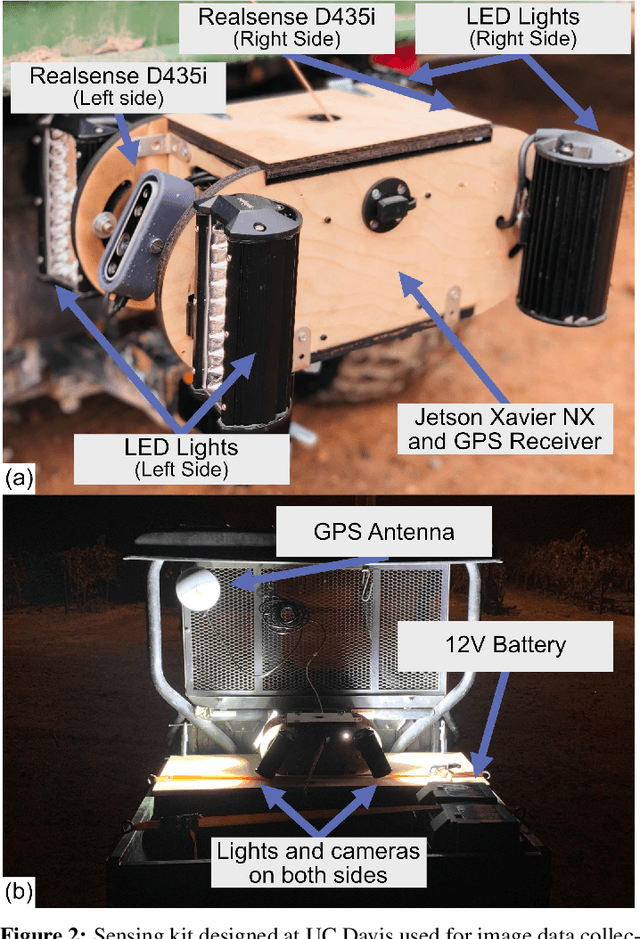
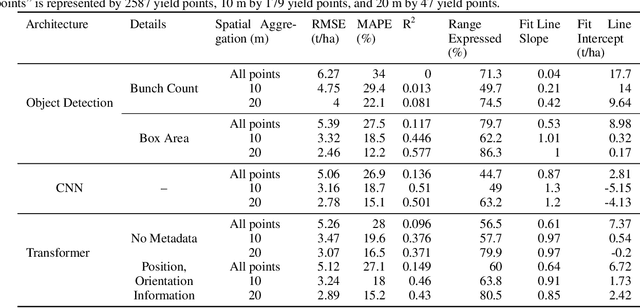
Yield estimation is a powerful tool in vineyard management, as it allows growers to fine-tune practices to optimize yield and quality. However, yield estimation is currently performed using manual sampling, which is time-consuming and imprecise. This study demonstrates the application of proximal imaging combined with deep learning for yield estimation in vineyards. Continuous data collection using a vehicle-mounted sensing kit combined with collection of ground truth yield data at harvest using a commercial yield monitor allowed for the generation of a large dataset of 23,581 yield points and 107,933 images. Moreover, this study was conducted in a mechanically managed commercial vineyard, representing a challenging environment for image analysis but a common set of conditions in the California Central Valley. Three model architectures were tested: object detection, CNN regression, and transformer models. The object detection model was trained on hand-labeled images to localize grape bunches, and either bunch count or pixel area was summed to correlate with grape yield. Conversely, regression models were trained end-to-end to predict grape yield from image data without the need for hand labeling. Results demonstrated that both a transformer as well as the object detection model with pixel area processing performed comparably, with a mean absolute percent error of 18% and 18.5%, respectively on a representative holdout dataset. Saliency mapping was used to demonstrate the attention of the CNN model was localized near the predicted location of grape bunches, as well as on the top of the grapevine canopy. Overall, the study showed the applicability of proximal imaging and deep learning for prediction of grapevine yield on a large scale. Additionally, the end-to-end modeling approach was able to perform comparably to the object detection approach while eliminating the need for hand-labeling.
Distortion-Corrected Image Reconstruction with Deep Learning on an MRI-Linac
May 23, 2022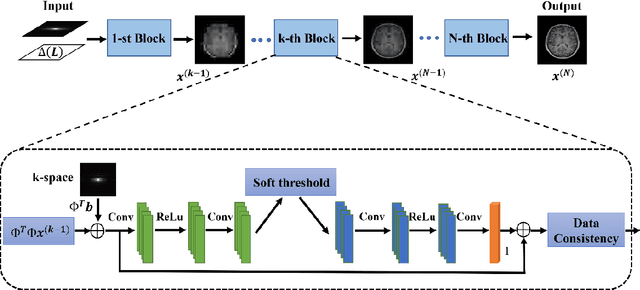

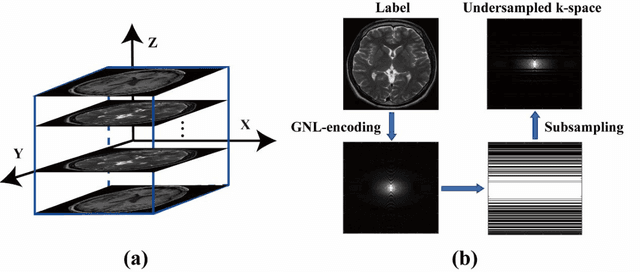
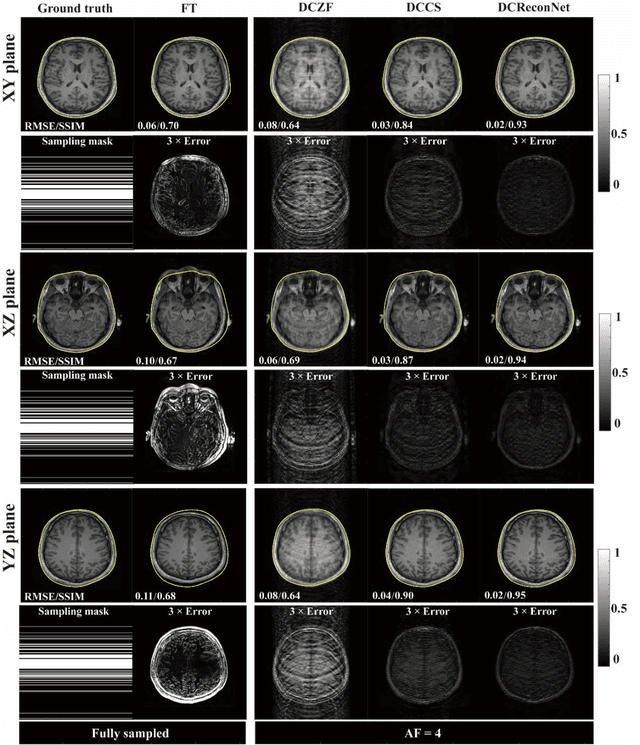
Magnetic resonance imaging (MRI) is increasingly utilized for image-guided radiotherapy due to its outstanding soft-tissue contrast and lack of ionizing radiation. However, geometric distortions caused by gradient nonlinearity (GNL) limit anatomical accuracy, potentially compromising the quality of tumour treatments. In addition, slow MR acquisition and reconstruction limit the potential for real-time image guidance. Here, we demonstrate a deep learning-based method that rapidly reconstructs distortion-corrected images from raw k-space data for real-time MR-guided radiotherapy applications. We leverage recent advances in interpretable unrolling networks to develop a Distortion-Corrected Reconstruction Network (DCReconNet) that applies convolutional neural networks (CNNs) to learn effective regularizations and nonuniform fast Fourier transforms for GNL-encoding. DCReconNet was trained on a public MR brain dataset from eleven healthy volunteers for fully sampled and accelerated techniques including parallel imaging (PI) and compressed sensing (CS). The performance of DCReconNet was tested on phantom and volunteer brain data acquired on a 1.0T MRI-Linac. The DCReconNet, CS- and PI-based reconstructed image quality was measured by structural similarity (SSIM) and root-mean-squared error (RMSE) for numerical comparisons. The computation time for each method was also reported. Phantom and volunteer results demonstrated that DCReconNet better preserves image structure when compared to CS- and PI-based reconstruction methods. DCReconNet resulted in highest SSIM (0.95 median value) and lowest RMSE (<0.04) on simulated brain images with four times acceleration. DCReconNet is over 100-times faster than iterative, regularized reconstruction methods. DCReconNet provides fast and geometrically accurate image reconstruction and has potential for real-time MRI-guided radiotherapy applications.
DeVIS: Making Deformable Transformers Work for Video Instance Segmentation
Jul 22, 2022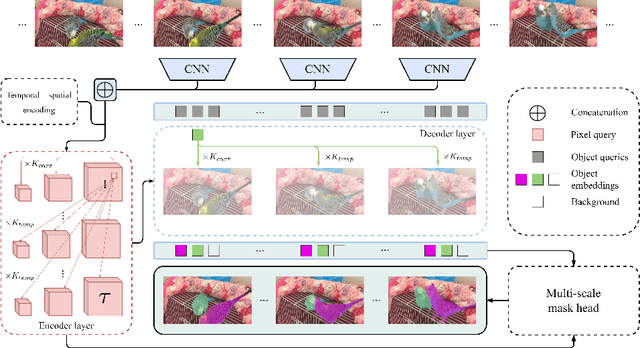
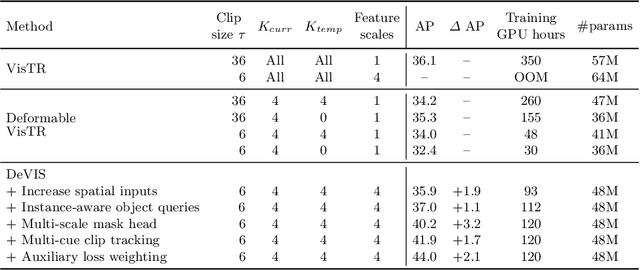
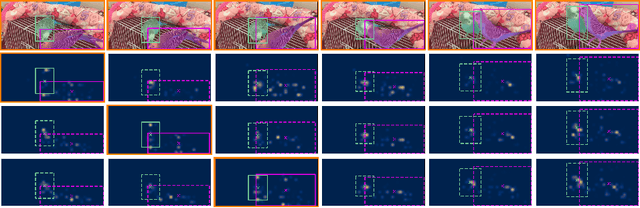
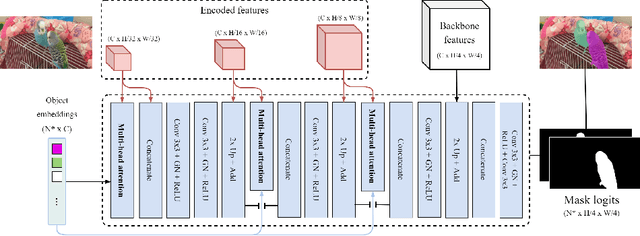
Video Instance Segmentation (VIS) jointly tackles multi-object detection, tracking, and segmentation in video sequences. In the past, VIS methods mirrored the fragmentation of these subtasks in their architectural design, hence missing out on a joint solution. Transformers recently allowed to cast the entire VIS task as a single set-prediction problem. Nevertheless, the quadratic complexity of existing Transformer-based methods requires long training times, high memory requirements, and processing of low-single-scale feature maps. Deformable attention provides a more efficient alternative but its application to the temporal domain or the segmentation task have not yet been explored. In this work, we present Deformable VIS (DeVIS), a VIS method which capitalizes on the efficiency and performance of deformable Transformers. To reason about all VIS subtasks jointly over multiple frames, we present temporal multi-scale deformable attention with instance-aware object queries. We further introduce a new image and video instance mask head with multi-scale features, and perform near-online video processing with multi-cue clip tracking. DeVIS reduces memory as well as training time requirements, and achieves state-of-the-art results on the YouTube-VIS 2021, as well as the challenging OVIS dataset. Code is available at https://github.com/acaelles97/DeVIS.