 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Pick: A Visuomotor Policy for Clustered Strawberry Picking
Sep 18, 2025Strawberries naturally grow in clusters, interwoven with leaves, stems, and other fruits, which frequently leads to occlusion. This inherent growth habit presents a significant challenge for robotic picking, as traditional percept-plan-control systems struggle to reach fruits amid the clutter. Effectively picking an occluded strawberry demands dexterous manipulation to carefully bypass or gently move the surrounding soft objects and precisely access the ideal picking point located at the stem just above the calyx. To address this challenge, we introduce a strawberry-picking robotic system that learns from human demonstrations. Our system features a 4-DoF SCARA arm paired with a human teleoperation interface for efficient data collection and leverages an End Pose Assisted Action Chunking Transformer (ACT) to develop a fine-grained visuomotor picking policy. Experiments under various occlusion scenarios demonstrate that our modified approach significantly outperforms the direct implementation of ACT, underscoring its potential for practical application in occluded strawberry picking.
Strawberry Robotic Operation Interface: An Open-Source Device for Collecting Dexterous Manipulation Data in Robotic Strawberry Farming
Jan 28, 2025



The strawberry farming is labor-intensive, particularly in tasks requiring dexterous manipulation such as picking occluded strawberries. To address this challenge, we present the Strawberry Robotic Operation Interface (SROI), an open-source device designed for collecting dexterous manipulation data in robotic strawberry farming. The SROI features a handheld unit with a modular end effector, a stereo robotic camera, enabling the easy collection of demonstration data in field environments. A data post-processing pipeline is introduced to extract spatial trajectories and gripper states from the collected data. Additionally, we release an open-source dataset of strawberry picking demonstrations to facilitate research in dexterous robotic manipulation. The SROI represents a step toward automating complex strawberry farming tasks, reducing reliance on manual labor.
Efficient and Safe Trajectory Planning for Autonomous Agricultural Vehicle Headland Turning in Cluttered Orchard Environments
Jan 18, 2025



Autonomous agricultural vehicles (AAVs), including field robots and autonomous tractors, are becoming essential in modern farming by improving efficiency and reducing labor costs. A critical task in AAV operations is headland turning between crop rows. This task is challenging in orchards with limited headland space, irregular boundaries, operational constraints, and static obstacles. While traditional trajectory planning methods work well in arable farming, they often fail in cluttered orchard environments. This letter presents a novel trajectory planner that enhances the safety and efficiency of AAV headland maneuvers, leveraging advancements in autonomous driving. Our approach includes an efficient front-end algorithm and a high-performance back-end optimization. Applied to vehicles with various implements, it outperforms state-of-the-art methods in both standard and challenging orchard fields. This work bridges agricultural and autonomous driving technologies, facilitating a broader adoption of AAVs in complex orchards.
Learn from Foundation Model: Fruit Detection Model without Manual Annotation
Nov 25, 2024



Recent breakthroughs in large foundation models have enabled the possibility of transferring knowledge pre-trained on vast datasets to domains with limited data availability. Agriculture is one of the domains that lacks sufficient data. This study proposes a framework to train effective, domain-specific, small models from foundation models without manual annotation. Our approach begins with SDM (Segmentation-Description-Matching), a stage that leverages two foundation models: SAM2 (Segment Anything in Images and Videos) for segmentation and OpenCLIP (Open Contrastive Language-Image Pretraining) for zero-shot open-vocabulary classification. In the second stage, a novel knowledge distillation mechanism is utilized to distill compact, edge-deployable models from SDM, enhancing both inference speed and perception accuracy. The complete method, termed SDM-D (Segmentation-Description-Matching-Distilling), demonstrates strong performance across various fruit detection tasks object detection, semantic segmentation, and instance segmentation) without manual annotation. It nearly matches the performance of models trained with abundant labels. Notably, SDM-D outperforms open-set detection methods such as Grounding SAM and YOLO-World on all tested fruit detection datasets. Additionally, we introduce MegaFruits, a comprehensive fruit segmentation dataset encompassing over 25,000 images, and all code and datasets are made publicly available at https://github.com/AgRoboticsResearch/SDM-D.git.
Optimization-Based Motion Planning for Autonomous Agricultural Vehicles Turning in Constrained Headlands
Aug 02, 2023



Headland maneuvering is a crucial aspect of unmanned field operations for autonomous agricultural vehicles (AAVs). While motion planning for headland turning in open fields has been extensively studied and integrated into commercial auto-guidance systems, the existing methods primarily address scenarios with ample headland space and thus may not work in more constrained headland geometries. Commercial orchards often contain narrow and irregularly shaped headlands, which may include static obstacles,rendering the task of planning a smooth and collision-free turning trajectory difficult. To address this challenge, we propose an optimization-based motion planning algorithm for headland turning under geometrical constraints imposed by field geometry and obstacles.
End-to-end deep learning for directly estimating grape yield from ground-based imagery
Aug 04, 2022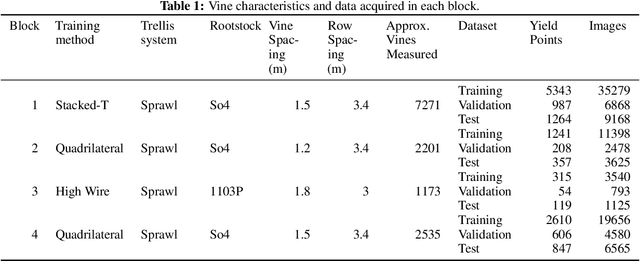
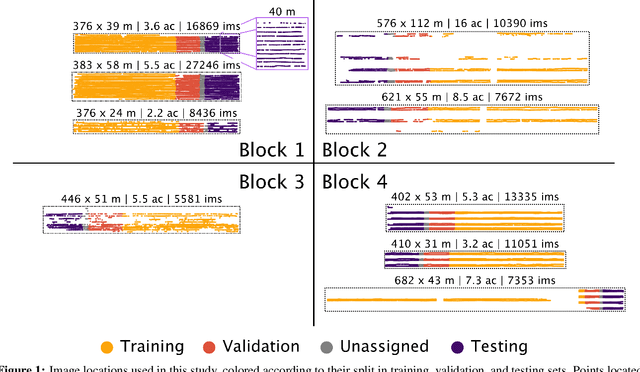
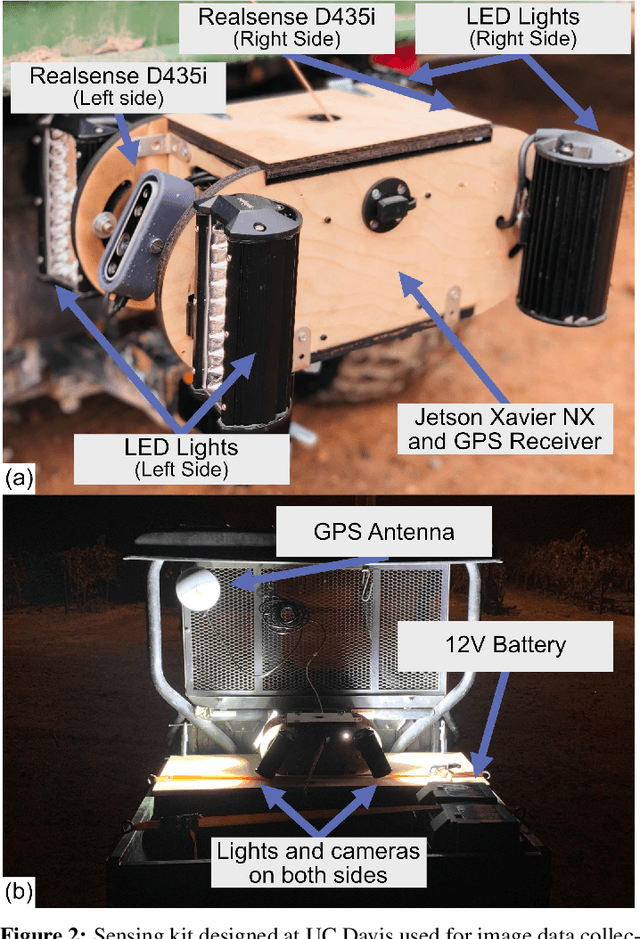
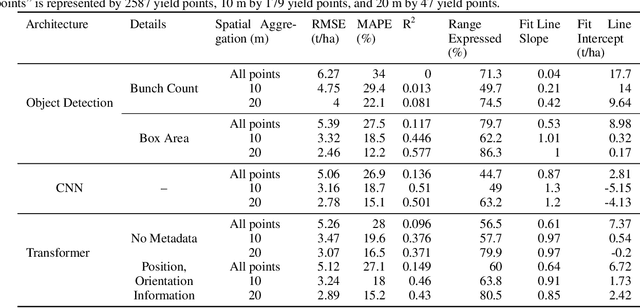
Yield estimation is a powerful tool in vineyard management, as it allows growers to fine-tune practices to optimize yield and quality. However, yield estimation is currently performed using manual sampling, which is time-consuming and imprecise. This study demonstrates the application of proximal imaging combined with deep learning for yield estimation in vineyards. Continuous data collection using a vehicle-mounted sensing kit combined with collection of ground truth yield data at harvest using a commercial yield monitor allowed for the generation of a large dataset of 23,581 yield points and 107,933 images. Moreover, this study was conducted in a mechanically managed commercial vineyard, representing a challenging environment for image analysis but a common set of conditions in the California Central Valley. Three model architectures were tested: object detection, CNN regression, and transformer models. The object detection model was trained on hand-labeled images to localize grape bunches, and either bunch count or pixel area was summed to correlate with grape yield. Conversely, regression models were trained end-to-end to predict grape yield from image data without the need for hand labeling. Results demonstrated that both a transformer as well as the object detection model with pixel area processing performed comparably, with a mean absolute percent error of 18% and 18.5%, respectively on a representative holdout dataset. Saliency mapping was used to demonstrate the attention of the CNN model was localized near the predicted location of grape bunches, as well as on the top of the grapevine canopy. Overall, the study showed the applicability of proximal imaging and deep learning for prediction of grapevine yield on a large scale. Additionally, the end-to-end modeling approach was able to perform comparably to the object detection approach while eliminating the need for hand-labeling.
Enlisting 3D Crop Models and GANs for More Data Efficient and Generalizable Fruit Detection
Aug 30, 2021


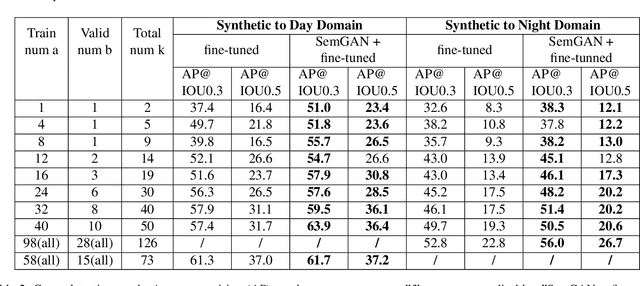
Training real-world neural network models to achieve high performance and generalizability typically requires a substantial amount of labeled data, spanning a broad range of variation. This data-labeling process can be both labor and cost intensive. To achieve desirable predictive performance, a trained model is typically applied into a domain where the data distribution is similar to the training dataset. However, for many agricultural machine learning problems, training datasets are collected at a specific location, during a specific period in time of the growing season. Since agricultural systems exhibit substantial variability in terms of crop type, cultivar, management, seasonal growth dynamics, lighting condition, sensor type, etc, a model trained from one dataset often does not generalize well across domains. To enable more data efficient and generalizable neural network models in agriculture, we propose a method that generates photorealistic agricultural images from a synthetic 3D crop model domain into real world crop domains. The method uses a semantically constrained GAN (generative adversarial network) to preserve the fruit position and geometry. We observe that a baseline CycleGAN method generates visually realistic target domain images but does not preserve fruit position information while our method maintains fruit positions well. Image generation results in vineyard grape day and night images show the visual outputs of our network are much better compared to a baseline network. Incremental training experiments in vineyard grape detection tasks show that the images generated from our method can significantly speed the domain adaption process, increase performance for a given number of labeled images (i.e. data efficiency), and decrease labeling requirements.
A strawberry harvest-aiding system with crop-transport co-robots: Design, development, and field evaluation
Jul 27, 2021

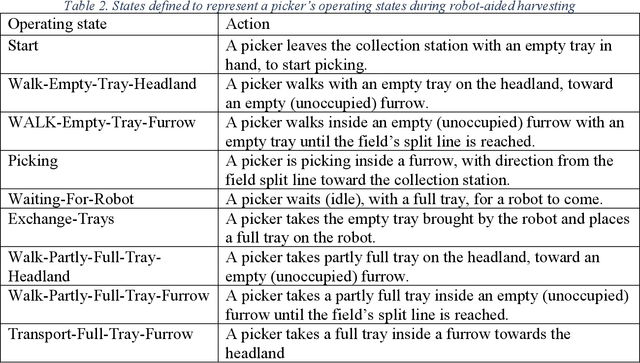
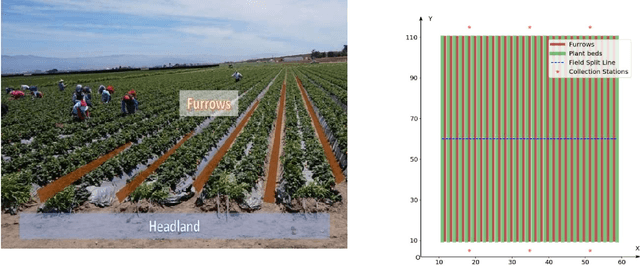
Mechanizing the manual harvesting of fresh market fruits constitutes one of the biggest challenges to the sustainability of the fruit industry. During manual harvesting of some fresh-market crops like strawberries and table grapes, pickers spend significant amounts of time walking to carry full trays to a collection station at the edge of the field. A step toward increasing harvest automation for such crops is to deploy harvest-aid collaborative robots (co-bots) that transport the empty and full trays, thus increasing harvest efficiency by reducing pickers' non-productive walking times. This work presents the development of a co-robotic harvest-aid system and its evaluation during commercial strawberry harvesting. At the heart of the system lies a predictive stochastic scheduling algorithm that minimizes the expected non-picking time, thus maximizing the harvest efficiency. During the evaluation experiments, the co-robots improved the mean harvesting efficiency by around 10% and reduced the mean non-productive time by 60%, when the robot-to-picker ratio was 1:3. The concepts developed in this work can be applied to robotic harvest-aids for other manually harvested crops that involve walking for crop transportation.
Row-sensing Templates: A Generic 3D Sensor-based Approach to Robot Localization with Respect to Orchard Row Centerlines
Jul 03, 2021
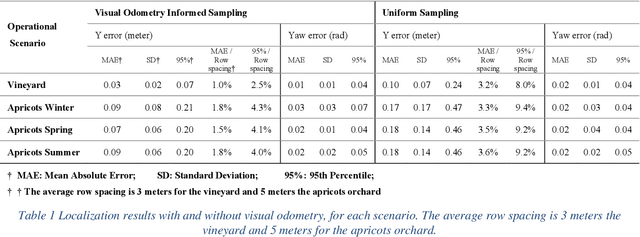

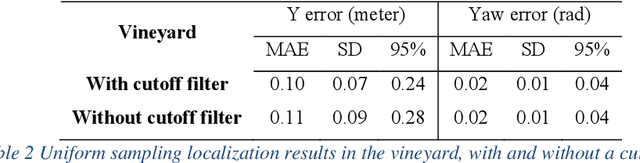
Accurate robot localization relative to orchard row centerlines is essential for autonomous guidance where satellite signals are often obstructed by foliage. Existing sensor-based approaches rely on various features extracted from images and point clouds. However, any selected features are not available consistently, because the visual and geometrical characteristics of orchard rows change drastically when tree types, growth stages, canopy management practices, seasons, and weather conditions change. In this work, we introduce a novel localization method that doesn't rely on features; instead, it relies on the concept of a row-sensing template, which is the expected observation of a 3D sensor traveling in an orchard row, when the sensor is anywhere on the centerline and perfectly aligned with it. First, the template is built using a few measurements, provided that the sensor's true pose with respect to the centerline is available. Then, during navigation, the best pose estimate (and its confidence) is estimated by maximizing the match between the template and the sensed point cloud using particle-filtering. The method can adapt to various orchards and conditions by re-building the template. Experiments were performed in a vineyard, and in an orchard in different seasons. Results showed that the lateral mean absolute error (MAE) was less than 3.6% of the row width, and the heading MAE was less than 1.72 degrees. Localization was robust, as errors didn't increase when less than 75% of measurement points were missing. The results indicate that template-based localization can provide a generic approach for accurate and robust localization in real-world orchards.