 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Autoregressive Hidden Markov Models with partial knowledge on latent space applied to aero-engines prognostics
May 01, 2021
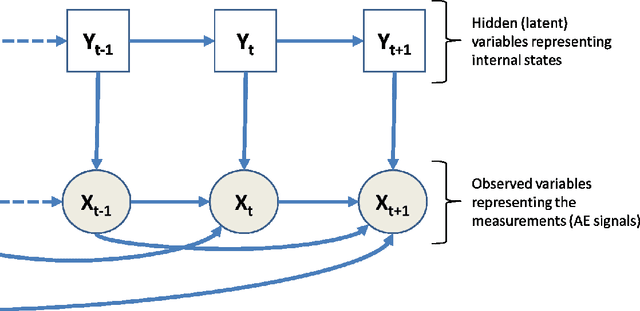
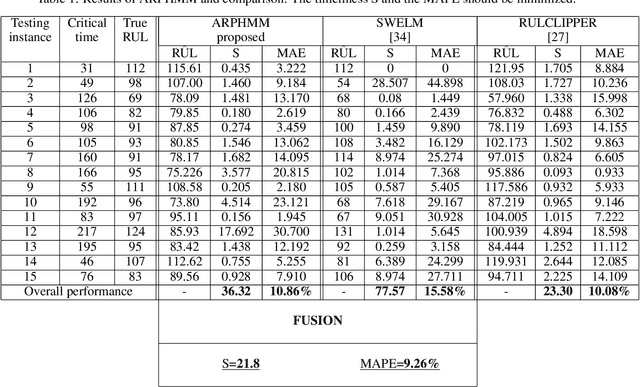
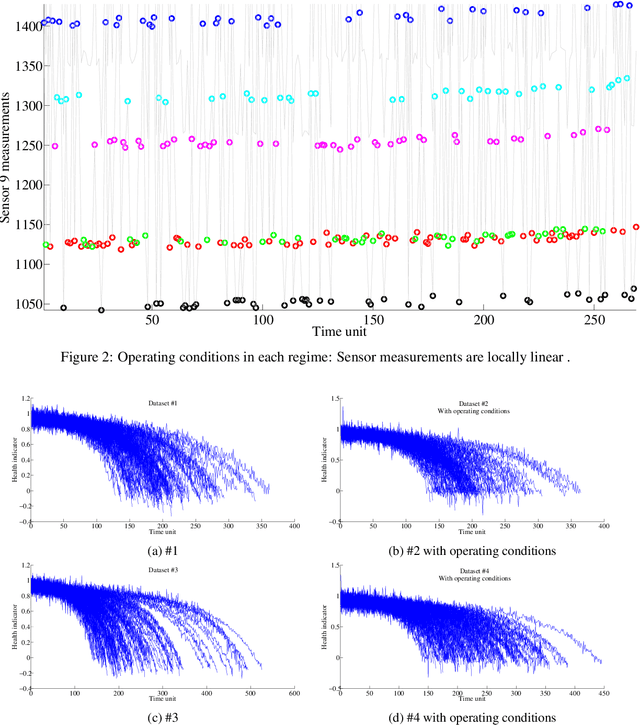
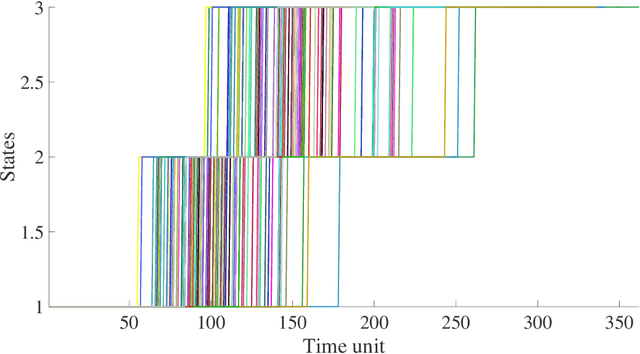
[This paper was initially published in PHME conference in 2016, selected for further publication in International Journal of Prognostics and Health Management.] This paper describes an Autoregressive Partially-hidden Markov model (ARPHMM) for fault detection and prognostics of equipments based on sensors' data. It is a particular dynamic Bayesian network that allows to represent the dynamics of a system by means of a Hidden Markov Model (HMM) and an autoregressive (AR) process. The Markov chain assumes that the system is switching back and forth between internal states while the AR process ensures a temporal coherence on sensor measurements. A sound learning procedure of standard ARHMM based on maximum likelihood allows to iteratively estimate all parameters simultaneously. This paper suggests a modification of the learning procedure considering that one may have prior knowledge about the structure which becomes partially hidden. The integration of the prior is based on the Theory of Weighted Distributions which is compatible with the Expectation-Maximization algorithm in the sense that the convergence properties are still satisfied. We show how to apply this model to estimate the remaining useful life based on health indicators. The autoregressive parameters can indeed be used for prediction while the latent structure can be used to get information about the degradation level. The interest of the proposed method for prognostics and health assessment is demonstrated on CMAPSS datasets.
Research of Damped Newton Stochastic Gradient Descent Method for Neural Network Training
Mar 31, 2021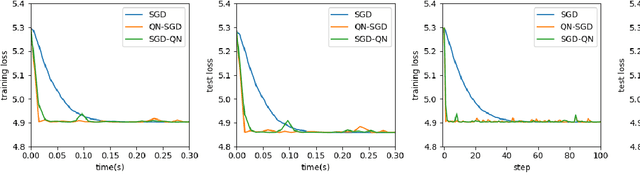
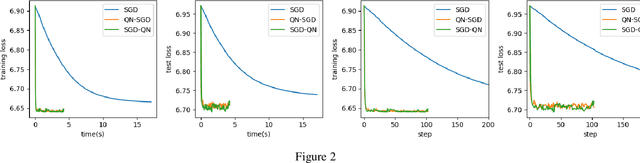
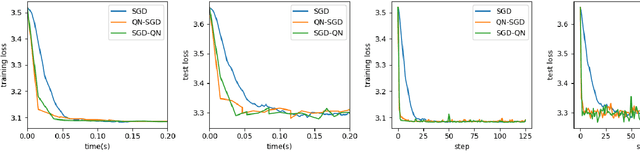
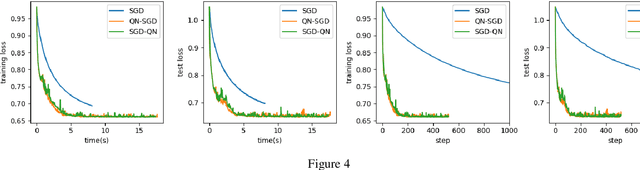
First-order methods like stochastic gradient descent(SGD) are recently the popular optimization method to train deep neural networks (DNNs), but second-order methods are scarcely used because of the overpriced computing cost in getting the high-order information. In this paper, we propose the Damped Newton Stochastic Gradient Descent(DN-SGD) method and Stochastic Gradient Descent Damped Newton(SGD-DN) method to train DNNs for regression problems with Mean Square Error(MSE) and classification problems with Cross-Entropy Loss(CEL), which is inspired by a proved fact that the hessian matrix of last layer of DNNs is always semi-definite. Different from other second-order methods to estimate the hessian matrix of all parameters, our methods just accurately compute a small part of the parameters, which greatly reduces the computational cost and makes convergence of the learning process much faster and more accurate than SGD. Several numerical experiments on real datesets are performed to verify the effectiveness of our methods for regression and classification problems.
Bootstrapping User and Item Representations for One-Class Collaborative Filtering
May 13, 2021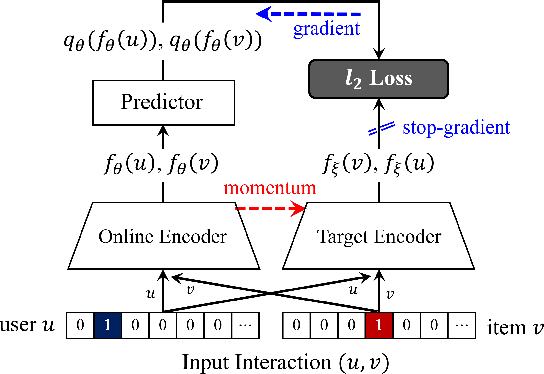
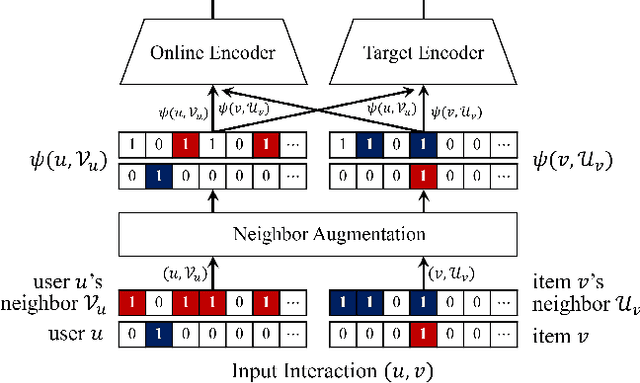
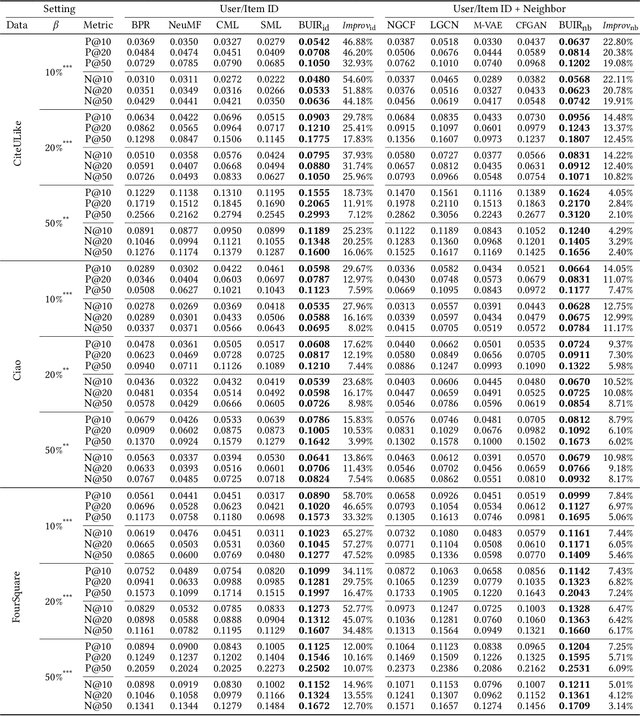
The goal of one-class collaborative filtering (OCCF) is to identify the user-item pairs that are positively-related but have not been interacted yet, where only a small portion of positive user-item interactions (e.g., users' implicit feedback) are observed. For discriminative modeling between positive and negative interactions, most previous work relied on negative sampling to some extent, which refers to considering unobserved user-item pairs as negative, as actual negative ones are unknown. However, the negative sampling scheme has critical limitations because it may choose "positive but unobserved" pairs as negative. This paper proposes a novel OCCF framework, named as BUIR, which does not require negative sampling. To make the representations of positively-related users and items similar to each other while avoiding a collapsed solution, BUIR adopts two distinct encoder networks that learn from each other; the first encoder is trained to predict the output of the second encoder as its target, while the second encoder provides the consistent targets by slowly approximating the first encoder. In addition, BUIR effectively alleviates the data sparsity issue of OCCF, by applying stochastic data augmentation to encoder inputs. Based on the neighborhood information of users and items, BUIR randomly generates the augmented views of each positive interaction each time it encodes, then further trains the model by this self-supervision. Our extensive experiments demonstrate that BUIR consistently and significantly outperforms all baseline methods by a large margin especially for much sparse datasets in which any assumptions about negative interactions are less valid.
Sample Reuse via Importance Sampling in Information Geometric Optimization
May 31, 2018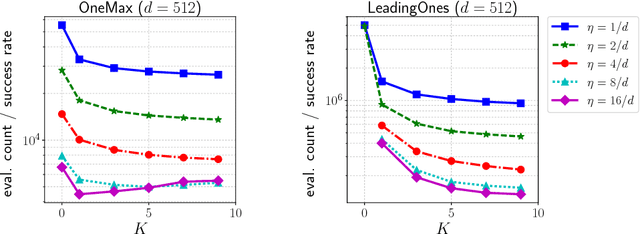

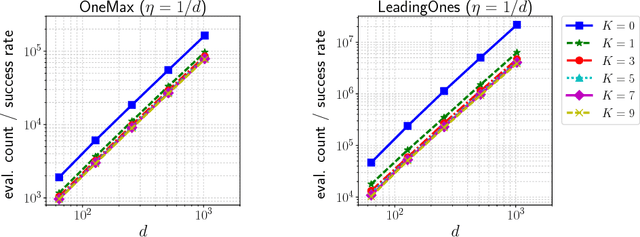
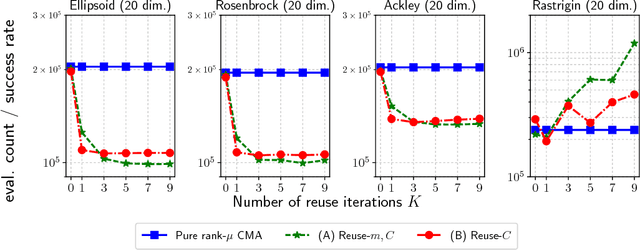
In this paper we propose a technique to reduce the number of function evaluations, which is often the bottleneck of the black-box optimization, in the information geometric optimization (IGO) that is a generic framework of the probability model-based black-box optimization algorithms and generalizes several well-known evolutionary algorithms, such as the population-based incremental learning (PBIL) and the pure rank-$\mu$ update covariance matrix adaptation evolution strategy (CMA-ES). In each iteration, the IGO algorithms update the parameters of the probability distribution to the natural gradient direction estimated by Monte-Carlo with the samples drawn from the current distribution. Our strategy is to reuse previously generated and evaluated samples based on the importance sampling. It is a technique to reduce the estimation variance without introducing a bias in Monte-Carlo estimation. We apply the sample reuse technique to the PBIL and the pure rank-$\mu$ update CMA-ES and empirically investigate its effect. The experimental results show that the sample reuse helps to reduce the number of function evaluations on many benchmark functions for both the PBIL and the pure rank-$\mu$ update CMA-ES. Moreover, we demonstrate how to combine the importance sampling technique with a variant of the CMA-ES involving an algorithmic component that is not derived in the IGO framework.
Discriminative and Semantic Feature Selection for Place Recognition towards Dynamic Environments
Mar 21, 2021
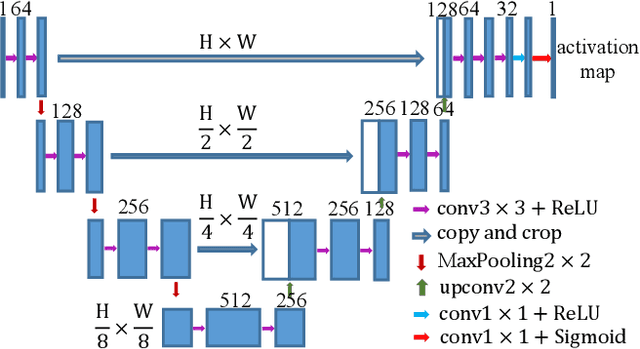
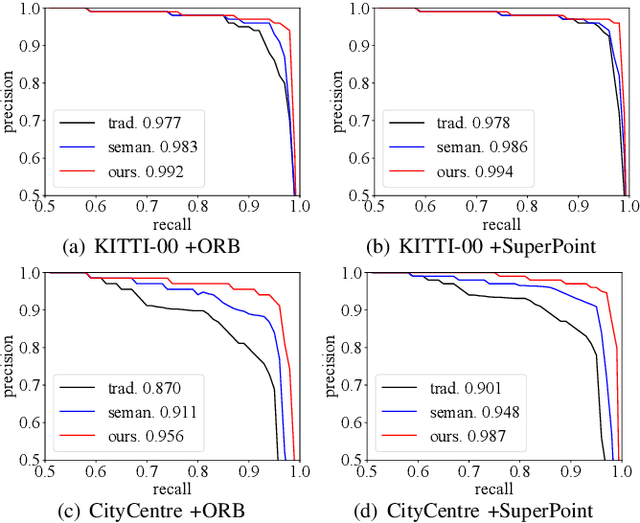
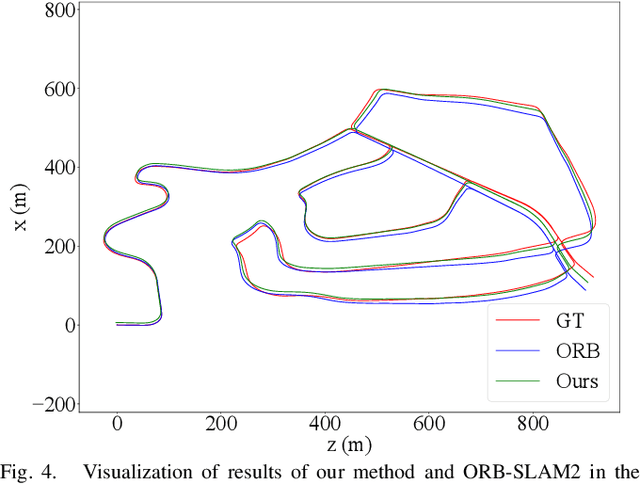
Features play an important role in various visual tasks, especially in visual place recognition applied in perceptual changing environments. In this paper, we address the challenges of place recognition due to dynamics and confusable patterns by proposing a discriminative and semantic feature selection network, dubbed as DSFeat. Supervised by both semantic information and attention mechanism, we can estimate pixel-wise stability of features, indicating the probability of a static and stable region from which features are extracted, and then select features that are insensitive to dynamic interference and distinguishable to be correctly matched. The designed feature selection model is evaluated in place recognition and SLAM system in several public datasets with varying appearances and viewpoints. Experimental results conclude that the effectiveness of the proposed method. It should be noticed that our proposal can be readily pluggable into any feature-based SLAM system.
Sparse Auxiliary Networks for Unified Monocular Depth Prediction and Completion
Mar 30, 2021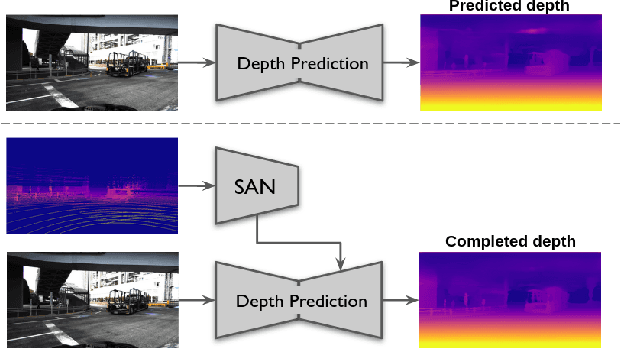
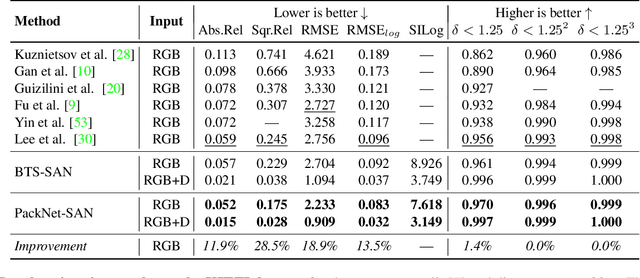
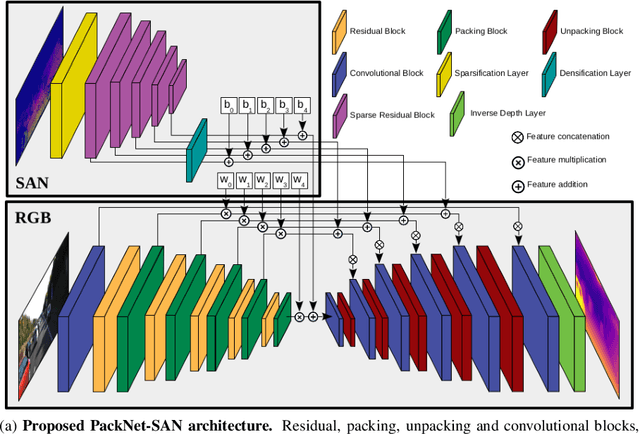
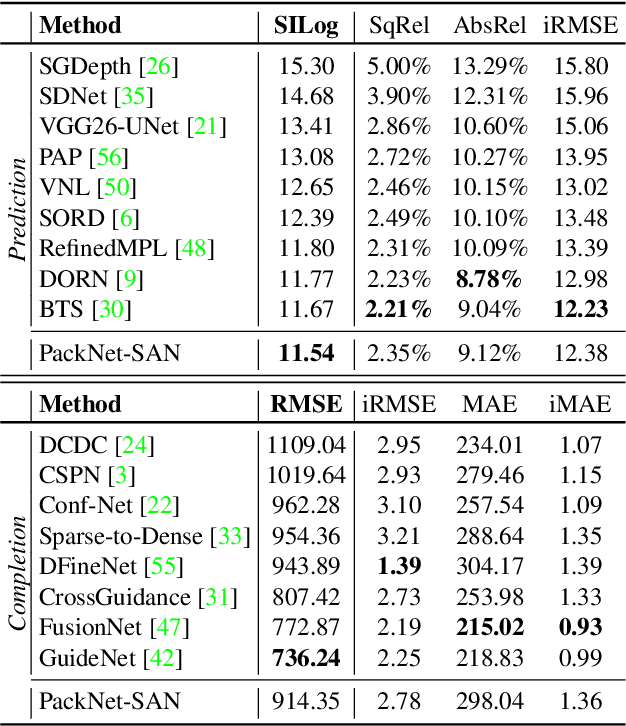
Estimating scene geometry from data obtained with cost-effective sensors is key for robots and self-driving cars. In this paper, we study the problem of predicting dense depth from a single RGB image (monodepth) with optional sparse measurements from low-cost active depth sensors. We introduce Sparse Auxiliary Networks (SANs), a new module enabling monodepth networks to perform both the tasks of depth prediction and completion, depending on whether only RGB images or also sparse point clouds are available at inference time. First, we decouple the image and depth map encoding stages using sparse convolutions to process only the valid depth map pixels. Second, we inject this information, when available, into the skip connections of the depth prediction network, augmenting its features. Through extensive experimental analysis on one indoor (NYUv2) and two outdoor (KITTI and DDAD) benchmarks, we demonstrate that our proposed SAN architecture is able to simultaneously learn both tasks, while achieving a new state of the art in depth prediction by a significant margin.
Spatial-Spectral Clustering with Anchor Graph for Hyperspectral Image
Apr 24, 2021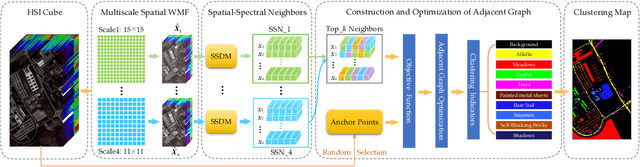
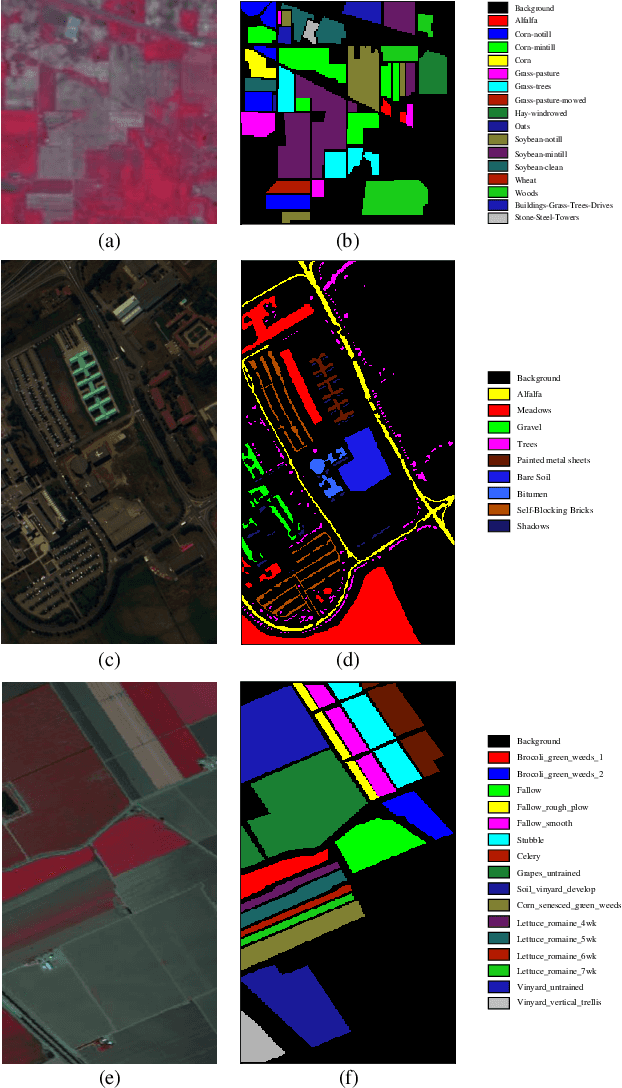
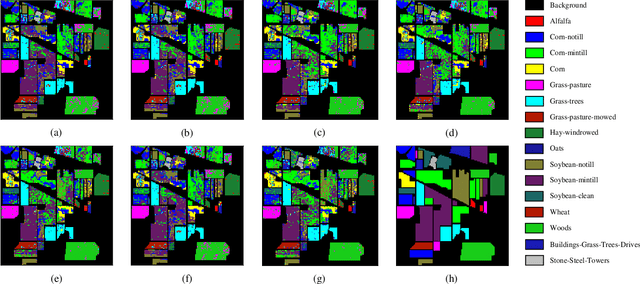
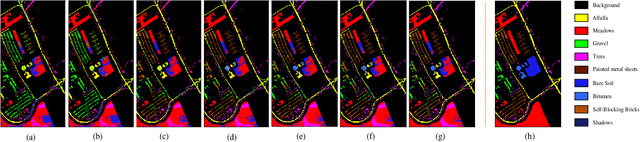
Hyperspectral image (HSI) clustering, which aims at dividing hyperspectral pixels into clusters, has drawn significant attention in practical applications. Recently, many graph-based clustering methods, which construct an adjacent graph to model the data relationship, have shown dominant performance. However, the high dimensionality of HSI data makes it hard to construct the pairwise adjacent graph. Besides, abundant spatial structures are often overlooked during the clustering procedure. In order to better handle the high dimensionality problem and preserve the spatial structures, this paper proposes a novel unsupervised approach called spatial-spectral clustering with anchor graph (SSCAG) for HSI data clustering. The SSCAG has the following contributions: 1) the anchor graph-based strategy is used to construct a tractable large graph for HSI data, which effectively exploits all data points and reduces the computational complexity; 2) a new similarity metric is presented to embed the spatial-spectral information into the combined adjacent graph, which can mine the intrinsic property structure of HSI data; 3) an effective neighbors assignment strategy is adopted in the optimization, which performs the singular value decomposition (SVD) on the adjacent graph to get solutions efficiently. Extensive experiments on three public HSI datasets show that the proposed SSCAG is competitive against the state-of-the-art approaches.
Fast discovery of multidimensional subsequences for robust trajectory classification
Feb 09, 2021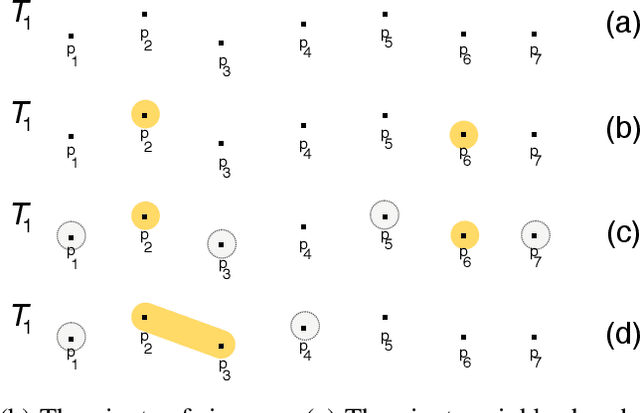
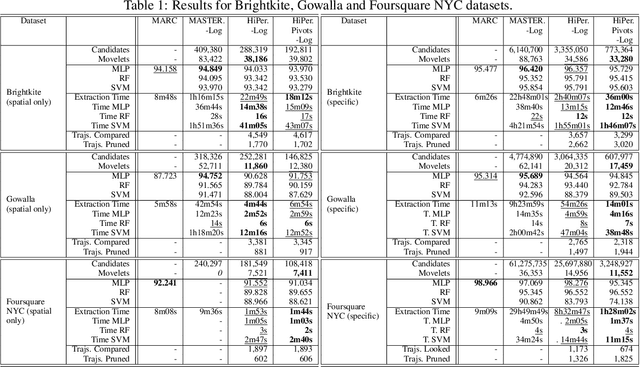
Trajectory classification tasks became more complex as large volumes of mobility data are being generated every day and enriched with new sources of information, such as social networks and IoT sensors. Fast classification algorithms are essential for discovering knowledge in trajectory data for real applications. In this work we propose a method for fast discovery of subtrajectories with the reduction of the search space and the optimization of the MASTERMovelets method, which has proven to be effective for discovering interpretable patterns in classification problems.
Learning Intuitive Physics with Multimodal Generative Models
Jan 19, 2021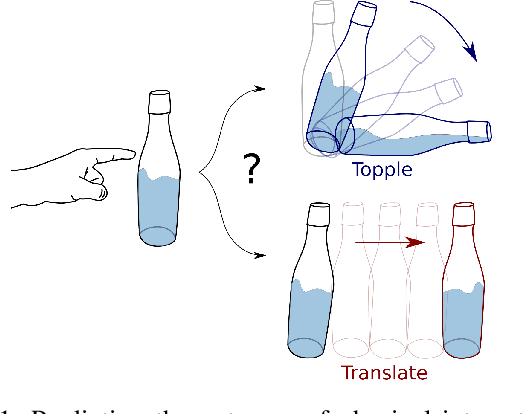
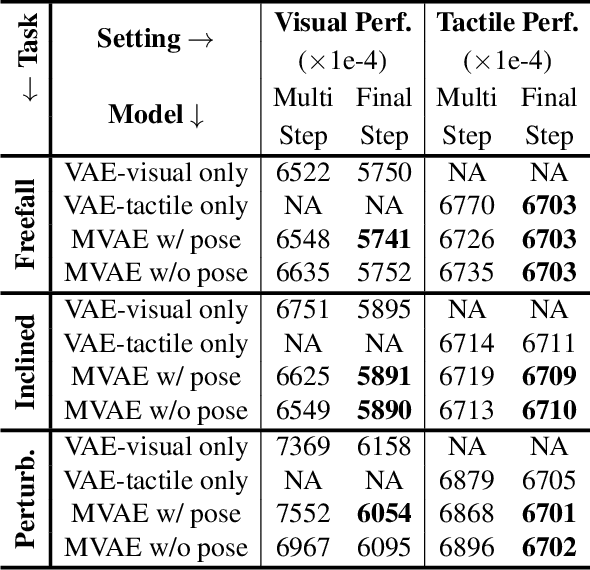
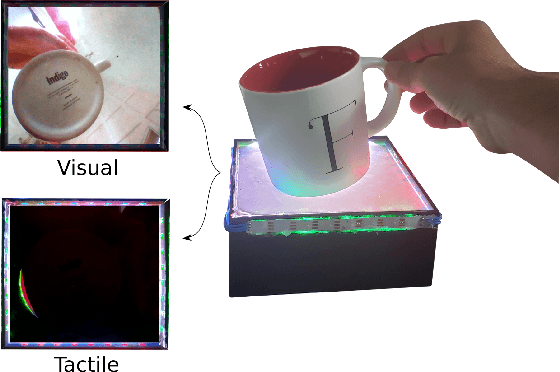

Predicting the future interaction of objects when they come into contact with their environment is key for autonomous agents to take intelligent and anticipatory actions. This paper presents a perception framework that fuses visual and tactile feedback to make predictions about the expected motion of objects in dynamic scenes. Visual information captures object properties such as 3D shape and location, while tactile information provides critical cues about interaction forces and resulting object motion when it makes contact with the environment. Utilizing a novel See-Through-your-Skin (STS) sensor that provides high resolution multimodal sensing of contact surfaces, our system captures both the visual appearance and the tactile properties of objects. We interpret the dual stream signals from the sensor using a Multimodal Variational Autoencoder (MVAE), allowing us to capture both modalities of contacting objects and to develop a mapping from visual to tactile interaction and vice-versa. Additionally, the perceptual system can be used to infer the outcome of future physical interactions, which we validate through simulated and real-world experiments in which the resting state of an object is predicted from given initial conditions.
Self-Attentive 3D Human Pose and Shape Estimation from Videos
Mar 26, 2021
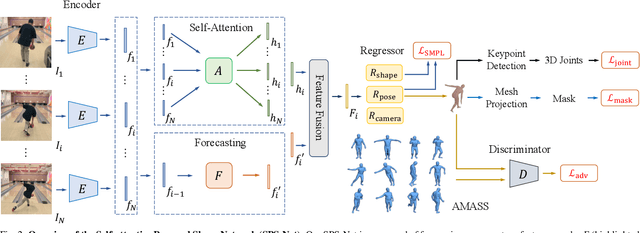
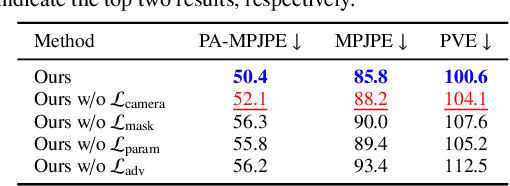
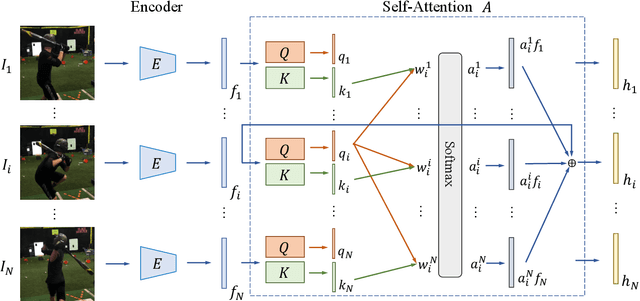
We consider the task of estimating 3D human pose and shape from videos. While existing frame-based approaches have made significant progress, these methods are independently applied to each image, thereby often leading to inconsistent predictions. In this work, we present a video-based learning algorithm for 3D human pose and shape estimation. The key insights of our method are two-fold. First, to address the inconsistent temporal prediction issue, we exploit temporal information in videos and propose a self-attention module that jointly considers short-range and long-range dependencies across frames, resulting in temporally coherent estimations. Second, we model human motion with a forecasting module that allows the transition between adjacent frames to be smooth. We evaluate our method on the 3DPW, MPI-INF-3DHP, and Human3.6M datasets. Extensive experimental results show that our algorithm performs favorably against the state-of-the-art methods.