 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Temporal Anomaly Segmentation with Dynamic Time Warping
Aug 15, 2021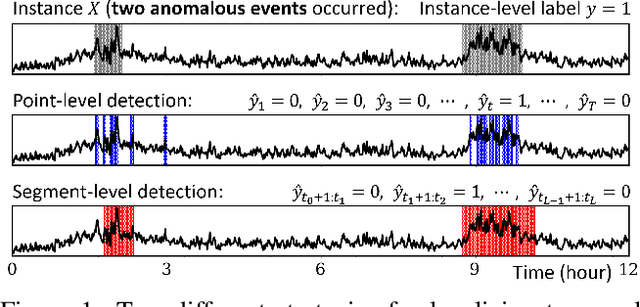

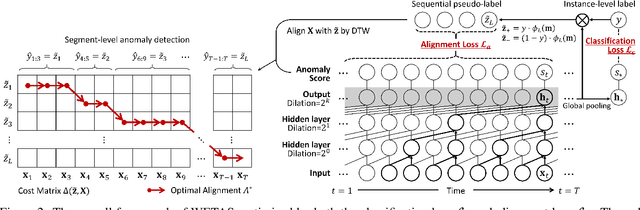
Most recent studies on detecting and localizing temporal anomalies have mainly employed deep neural networks to learn the normal patterns of temporal data in an unsupervised manner. Unlike them, the goal of our work is to fully utilize instance-level (or weak) anomaly labels, which only indicate whether any anomalous events occurred or not in each instance of temporal data. In this paper, we present WETAS, a novel framework that effectively identifies anomalous temporal segments (i.e., consecutive time points) in an input instance. WETAS learns discriminative features from the instance-level labels so that it infers the sequential order of normal and anomalous segments within each instance, which can be used as a rough segmentation mask. Based on the dynamic time warping (DTW) alignment between the input instance and its segmentation mask, WETAS obtains the result of temporal segmentation, and simultaneously, it further enhances itself by using the mask as additional supervision. Our experiments show that WETAS considerably outperforms other baselines in terms of the localization of temporal anomalies, and also it provides more informative results than point-level detection methods.
Bootstrapping User and Item Representations for One-Class Collaborative Filtering
May 13, 2021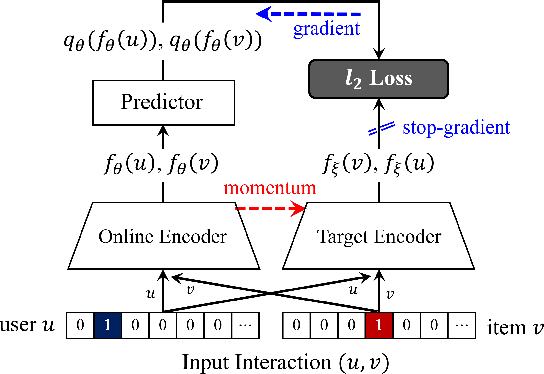
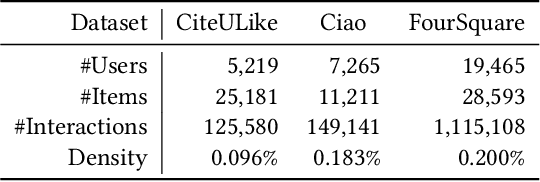
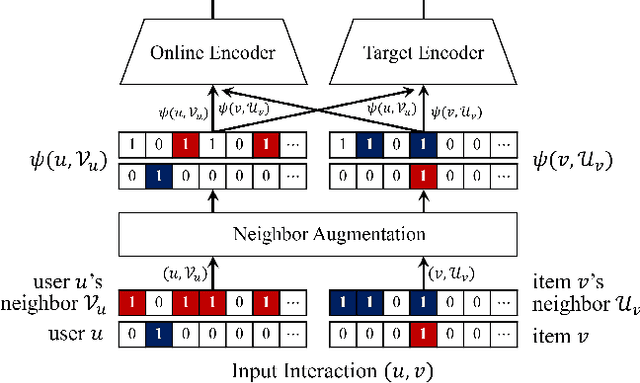
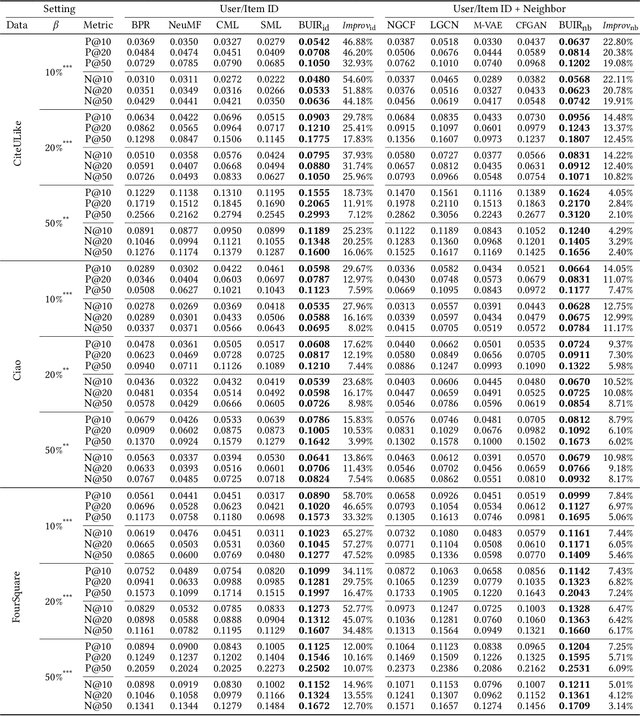
The goal of one-class collaborative filtering (OCCF) is to identify the user-item pairs that are positively-related but have not been interacted yet, where only a small portion of positive user-item interactions (e.g., users' implicit feedback) are observed. For discriminative modeling between positive and negative interactions, most previous work relied on negative sampling to some extent, which refers to considering unobserved user-item pairs as negative, as actual negative ones are unknown. However, the negative sampling scheme has critical limitations because it may choose "positive but unobserved" pairs as negative. This paper proposes a novel OCCF framework, named as BUIR, which does not require negative sampling. To make the representations of positively-related users and items similar to each other while avoiding a collapsed solution, BUIR adopts two distinct encoder networks that learn from each other; the first encoder is trained to predict the output of the second encoder as its target, while the second encoder provides the consistent targets by slowly approximating the first encoder. In addition, BUIR effectively alleviates the data sparsity issue of OCCF, by applying stochastic data augmentation to encoder inputs. Based on the neighborhood information of users and items, BUIR randomly generates the augmented views of each positive interaction each time it encodes, then further trains the model by this self-supervision. Our extensive experiments demonstrate that BUIR consistently and significantly outperforms all baseline methods by a large margin especially for much sparse datasets in which any assumptions about negative interactions are less valid.