 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactile Modality Fusion for Vision-Language-Action Models
Mar 15, 2026We propose TacFiLM, a lightweight modality-fusion approach that integrates visual-tactile signals into vision-language-action (VLA) models. While recent advances in VLA models have introduced robot policies that are both generalizable and semantically grounded, these models mainly rely on vision-based perception. Vision alone, however, cannot capture the complex interaction dynamics that occur during contact-rich manipulation, including contact forces, surface friction, compliance, and shear. While recent attempts to integrate tactile signals into VLA models often increase complexity through token concatenation or large-scale pretraining, the heavy computational demands of behavioural models necessitate more lightweight fusion strategies. To address these challenges, TacFiLM outlines a post-training finetuning approach that conditions intermediate visual features on pretrained tactile representations using feature-wise linear modulation (FiLM). Experimental results on insertion tasks demonstrate consistent improvements in success rate, direct insertion performance, completion time, and force stability across both in-distribution and out-of-distribution tasks. Together, these results support our method as an effective approach to integrating tactile signals into VLA models, improving contact-rich manipulation behaviours.
MANSION: Multi-floor lANguage-to-3D Scene generatIOn for loNg-horizon tasks
Mar 12, 2026Real-world robotic tasks are long-horizon and often span multiple floors, demanding rich spatial reasoning. However, existing embodied benchmarks are largely confined to single-floor in-house environments, failing to reflect the complexity of real-world tasks. We introduce MANSION, the first language-driven framework for generating building-scale, multi-floor 3D environments. Being aware of vertical structural constraints, MANSION generates realistic, navigable whole-building structures with diverse, human-friendly scenes, enabling the development and evaluation of cross-floor long-horizon tasks. Building on this framework, we release MansionWorld, a dataset of over 1,000 diverse buildings ranging from hospitals to offices, alongside a Task-Semantic Scene Editing Agent that customizes these environments using open-vocabulary commands to meet specific user needs. Benchmarking reveals that state-of-the-art agents degrade sharply in our settings, establishing MANSION as a critical testbed for the next generation of spatial reasoning and planning.
AMP2026: A Multi-Platform Marine Robotics Dataset for Tracking and Mapping
Mar 04, 2026Marine environments present significant challenges for perception and autonomy due to dynamic surfaces, limited visibility, and complex interactions between aerial, surface, and submerged sensing modalities. This paper introduces the Aerial Marine Perception Dataset (AMP2026), a multi-platform marine robotics dataset collected across multiple field deployments designed to support research in two primary areas: multi-view tracking and marine environment mapping. The dataset includes synchronized data from aerial drones, boat-mounted cameras, and submerged robotic platforms, along with associated localization and telemetry information. The goal of this work is to provide a publicly available dataset enabling research in marine perception and multi-robot observation scenarios. This paper describes the data collection methodology, sensor configurations, dataset organization, and intended research tasks supported by the dataset.
The Surprising Difficulty of Search in Model-Based Reinforcement Learning
Jan 29, 2026This paper investigates search in model-based reinforcement learning (RL). Conventional wisdom holds that long-term predictions and compounding errors are the primary obstacles for model-based RL. We challenge this view, showing that search is not a plug-and-play replacement for a learned policy. Surprisingly, we find that search can harm performance even when the model is highly accurate. Instead, we show that mitigating distribution shift matters more than improving model or value function accuracy. Building on this insight, we identify key techniques for enabling effective search, achieving state-of-the-art performance across multiple popular benchmark domains.
Contractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations
Jan 02, 2026Diffusion policies have emerged as powerful generative models for offline policy learning, whose sampling process can be rigorously characterized by a score function guiding a Stochastic Differential Equation (SDE). However, the same score-based SDE modeling that grants diffusion policies the flexibility to learn diverse behavior also incurs solver and score-matching errors, large data requirements, and inconsistencies in action generation. While less critical in image generation, these inaccuracies compound and lead to failure in continuous control settings. We introduce Contractive Diffusion Policies (CDPs) to induce contractive behavior in the diffusion sampling dynamics. Contraction pulls nearby flows closer to enhance robustness against solver and score-matching errors while reducing unwanted action variance. We develop an in-depth theoretical analysis along with a practical implementation recipe to incorporate CDPs into existing diffusion policy architectures with minimal modification and computational cost. We evaluate CDPs for offline learning by conducting extensive experiments in simulation and real-world settings. Across benchmarks, CDPs often outperform baseline policies, with pronounced benefits under data scarcity.
On Mobile Ad Hoc Networks for Coverage of Partially Observable Worlds
Dec 10, 2025This paper addresses the movement and placement of mobile agents to establish a communication network in initially unknown environments. We cast the problem in a computational-geometric framework by relating the coverage problem and line-of-sight constraints to the Cooperative Guard Art Gallery Problem, and introduce its partially observable variant, the Partially Observable Cooperative Guard Art Gallery Problem (POCGAGP). We then present two algorithms that solve POCGAGP: CADENCE, a centralized planner that incrementally selects 270 degree corners at which to deploy agents, and DADENCE, a decentralized scheme that coordinates agents using local information and lightweight messaging. Both approaches operate under partial observability and target simultaneous coverage and connectivity. We evaluate the methods in simulation across 1,500 test cases of varied size and structure, demonstrating consistent success in forming connected networks while covering and exploring unknown space. These results highlight the value of geometric abstractions for communication-driven exploration and show that decentralized policies are competitive with centralized performance while retaining scalability.
Swarm Oracle: Trustless Blockchain Agreements through Robot Swarms
Sep 19, 2025
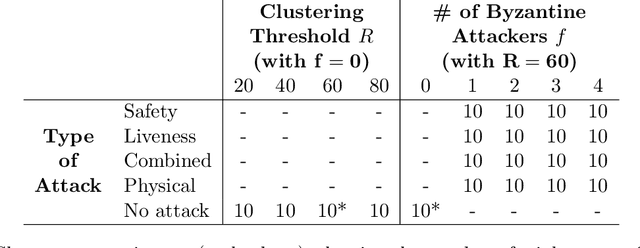


Blockchain consensus, rooted in the principle ``don't trust, verify'', limits access to real-world data, which may be ambiguous or inaccessible to some participants. Oracles address this limitation by supplying data to blockchains, but existing solutions may reduce autonomy, transparency, or reintroduce the need for trust. We propose Swarm Oracle: a decentralized network of autonomous robots -- that is, a robot swarm -- that use onboard sensors and peer-to-peer communication to collectively verify real-world data and provide it to smart contracts on public blockchains. Swarm Oracle leverages the built-in decentralization, fault tolerance and mobility of robot swarms, which can flexibly adapt to meet information requests on-demand, even in remote locations. Unlike typical cooperative robot swarms, Swarm Oracle integrates robots from multiple stakeholders, protecting the system from single-party biases but also introducing potential adversarial behavior. To ensure the secure, trustless and global consensus required by blockchains, we employ a Byzantine fault-tolerant protocol that enables robots from different stakeholders to operate together, reaching social agreements of higher quality than the estimates of individual robots. Through extensive experiments using both real and simulated robots, we showcase how consensus on uncertain environmental information can be achieved, despite several types of attacks orchestrated by large proportions of the robots, and how a reputation system based on blockchain tokens lets Swarm Oracle autonomously recover from faults and attacks, a requirement for long-term operation.
Scalable Aerial GNSS Localization for Marine Robots
May 07, 2025



Accurate localization is crucial for water robotics, yet traditional onboard Global Navigation Satellite System (GNSS) approaches are difficult or ineffective due to signal reflection on the water's surface and its high cost of aquatic GNSS receivers. Existing approaches, such as inertial navigation, Doppler Velocity Loggers (DVL), SLAM, and acoustic-based methods, face challenges like error accumulation and high computational complexity. Therefore, a more efficient and scalable solution remains necessary. This paper proposes an alternative approach that leverages an aerial drone equipped with GNSS localization to track and localize a marine robot once it is near the surface of the water. Our results show that this novel adaptation enables accurate single and multi-robot marine robot localization.
Learning Heuristics for Transit Network Design and Improvement with Deep Reinforcement Learning
Apr 15, 2024



Transit agencies world-wide face tightening budgets. To maintain quality of service while cutting costs, efficient transit network design is essential. But planning a network of public transit routes is a challenging optimization problem. The most successful approaches to date use metaheuristic algorithms to search through the space of possible transit networks by applying low-level heuristics that randomly alter routes in a network. The design of these low-level heuristics has a major impact on the quality of the result. In this paper we use deep reinforcement learning with graph neural nets to learn low-level heuristics for an evolutionary algorithm, instead of designing them manually. These learned heuristics improve the algorithm's results on benchmark synthetic cities with 70 nodes or more, and obtain state-of-the-art results when optimizing operating costs. They also improve upon a simulation of the real transit network in the city of Laval, Canada, by as much as 54% and 18% on two key metrics, and offer cost savings of up to 12% over the city's existing transit network.
Constrained Robotic Navigation on Preferred Terrains Using LLMs and Speech Instruction: Exploiting the Power of Adverbs
Apr 02, 2024This paper explores leveraging large language models for map-free off-road navigation using generative AI, reducing the need for traditional data collection and annotation. We propose a method where a robot receives verbal instructions, converted to text through Whisper, and a large language model (LLM) model extracts landmarks, preferred terrains, and crucial adverbs translated into speed settings for constrained navigation. A language-driven semantic segmentation model generates text-based masks for identifying landmarks and terrain types in images. By translating 2D image points to the vehicle's motion plane using camera parameters, an MPC controller can guides the vehicle towards the desired terrain. This approach enhances adaptation to diverse environments and facilitates the use of high-level instructions for navigating complex and challenging terrains.