 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Deep Learning Approach for Network-wide Dynamic Traffic Prediction during Hurricane Evacuation
Feb 25, 2022
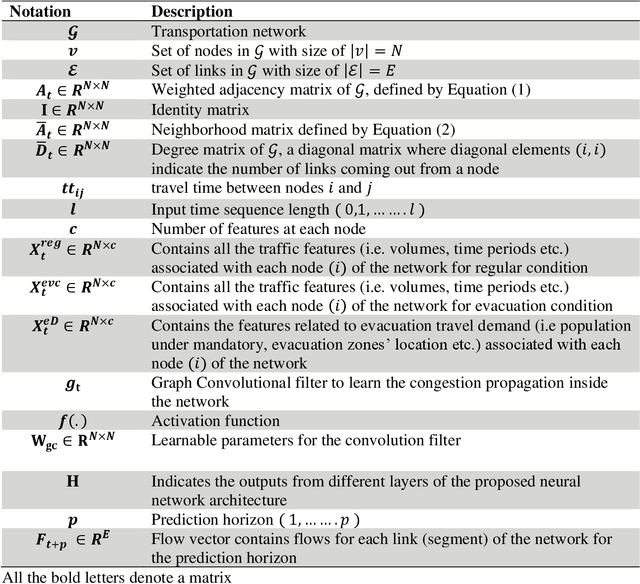
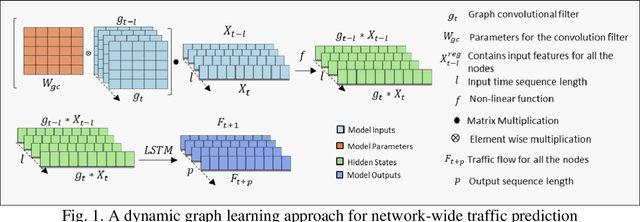
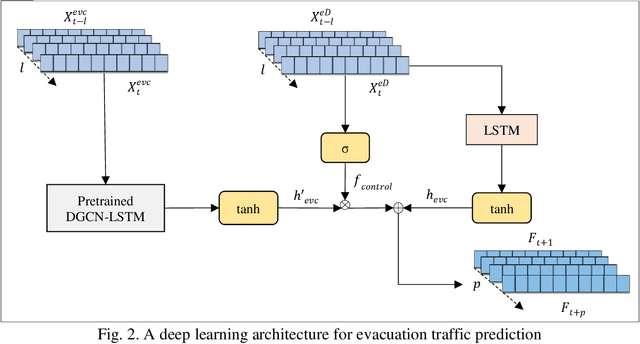

Proactive evacuation traffic management largely depends on real-time monitoring and prediction of traffic flow at a high spatiotemporal resolution. However, evacuation traffic prediction is challenging due to the uncertainties caused by sudden changes in projected hurricane paths and consequently household evacuation behavior. Moreover, modeling spatiotemporal traffic flow patterns requires extensive data over a longer time period, whereas evacuations typically last for 2 to 5 days. In this paper, we present a novel data-driven approach for predicting evacuation traffic at a network scale. We develop a dynamic graph convolution LSTM (DGCN-LSTM) model to learn the network dynamics of hurricane evacuation. We first train the model for non-evacuation period traffic data showing that the model outperforms existing deep learning models for predicting non-evacuation period traffic with an RMSE value of 226.84. However, when we apply the model for evacuation period, the RMSE value increased to 1440.99. We overcome this issue by adopting a transfer learning approach with additional features related to evacuation traffic demand such as distance from the evacuation zone, time to landfall, and other zonal level features to control the transfer of information (network dynamics) from non-evacuation periods to evacuation periods. The final transfer learned DGCN-LSTM model performs well to predict evacuation traffic flow (RMSE=399.69). The implemented model can be applied to predict evacuation traffic over a longer forecasting horizon (6 hour). It will assist transportation agencies to activate appropriate traffic management strategies to reduce delays for evacuating traffic.
A cross-domain recommender system using deep coupled autoencoders
Dec 08, 2021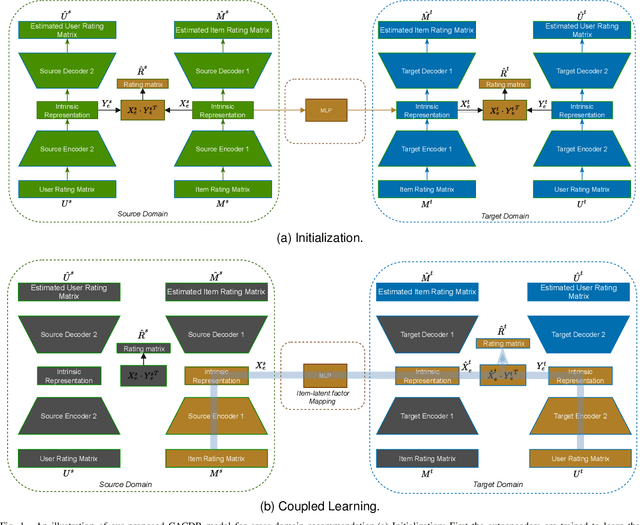
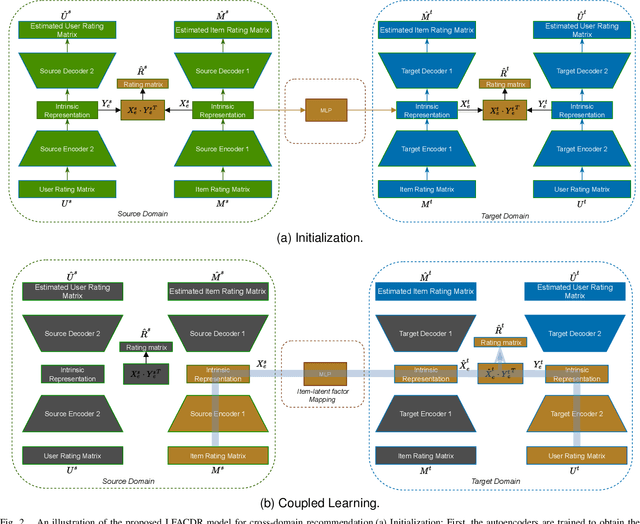
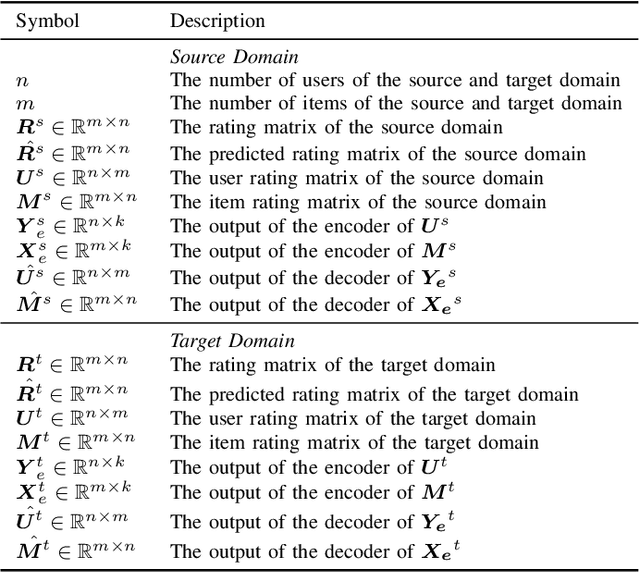
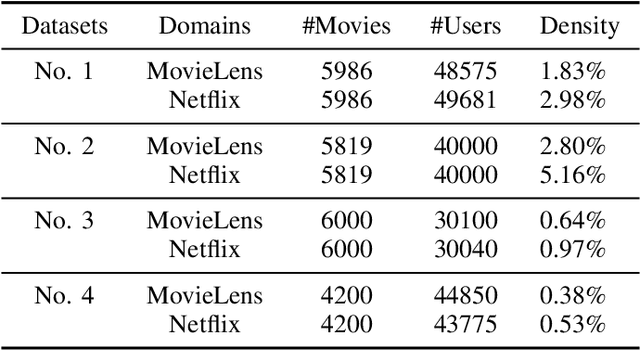
Long-standing data sparsity and cold-start constitute thorny and perplexing problems for the recommendation systems. Cross-domain recommendation as a domain adaptation framework has been utilized to efficiently address these challenging issues, by exploiting information from multiple domains. In this study, an item-level relevance cross-domain recommendation task is explored, where two related domains, that is, the source and the target domain contain common items without sharing sensitive information regarding the users' behavior, and thus avoiding the leak of user privacy. In light of this scenario, two novel coupled autoencoder-based deep learning methods are proposed for cross-domain recommendation. The first method aims to simultaneously learn a pair of autoencoders in order to reveal the intrinsic representations of the items in the source and target domains, along with a coupled mapping function to model the non-linear relationships between these representations, thus transferring beneficial information from the source to the target domain. The second method is derived based on a new joint regularized optimization problem, which employs two autoencoders to generate in a deep and non-linear manner the user and item-latent factors, while at the same time a data-driven function is learnt to map the item-latent factors across domains. Extensive numerical experiments on two publicly available benchmark datasets are conducted illustrating the superior performance of our proposed methods compared to several state-of-the-art cross-domain recommendation frameworks.
3D-Aware Indoor Scene Synthesis with Depth Priors
Feb 17, 2022
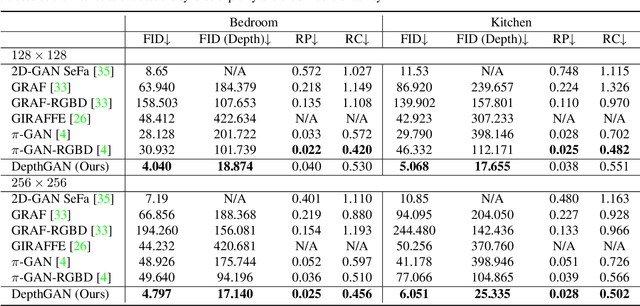
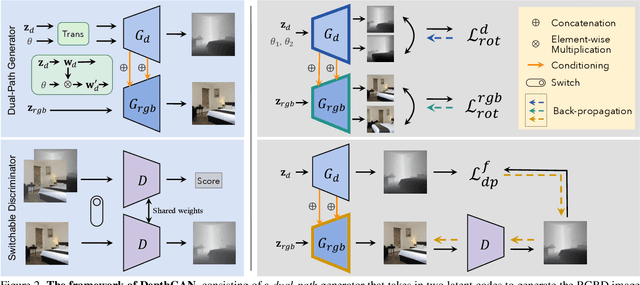
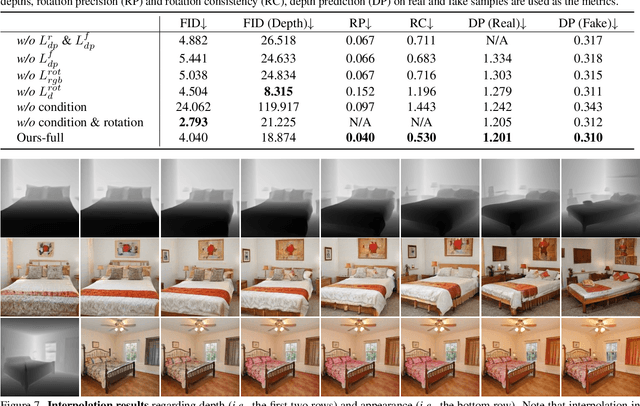
Despite the recent advancement of Generative Adversarial Networks (GANs) in learning 3D-aware image synthesis from 2D data, existing methods fail to model indoor scenes due to the large diversity of room layouts and the objects inside. We argue that indoor scenes do not have a shared intrinsic structure, and hence only using 2D images cannot adequately guide the model with the 3D geometry. In this work, we fill in this gap by introducing depth as a 3D prior. Compared with other 3D data formats, depth better fits the convolution-based generation mechanism and is more easily accessible in practice. Specifically, we propose a dual-path generator, where one path is responsible for depth generation, whose intermediate features are injected into the other path as the condition for appearance rendering. Such a design eases the 3D-aware synthesis with explicit geometry information. Meanwhile, we introduce a switchable discriminator both to differentiate real v.s. fake domains and to predict the depth from a given input. In this way, the discriminator can take the spatial arrangement into account and advise the generator to learn an appropriate depth condition. Extensive experimental results suggest that our approach is capable of synthesizing indoor scenes with impressively good quality and 3D consistency, significantly outperforming state-of-the-art alternatives.
Recommendation Unlearning
Jan 18, 2022
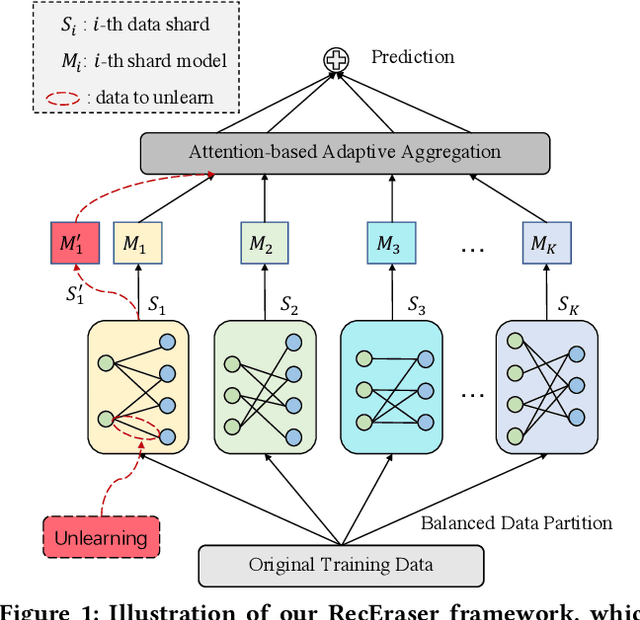
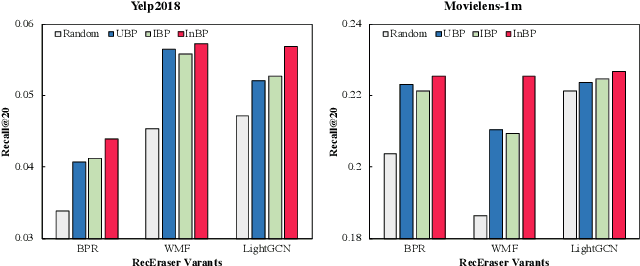
Recommender systems provide essential web services by learning users' personal preferences from collected data. However, in many cases, systems also need to forget some training data. From the perspective of privacy, several privacy regulations have recently been proposed, requiring systems to eliminate any impact of the data whose owner requests to forget. From the perspective of utility, if a system's utility is damaged by some bad data, the system needs to forget these data to regain utility. From the perspective of usability, users can delete noise and incorrect entries so that a system can provide more useful recommendations. While unlearning is very important, it has not been well-considered in existing recommender systems. Although there are some researches have studied the problem of machine unlearning in the domains of image and text data, existing methods can not been directly applied to recommendation as they are unable to consider the collaborative information. In this paper, we propose RecEraser, a general and efficient machine unlearning framework tailored to recommendation task. The main idea of RecEraser is to partition the training set into multiple shards and train a constituent model for each shard. Specifically, to keep the collaborative information of the data, we first design three novel data partition algorithms to divide training data into balanced groups based on their similarity. Then, considering that different shard models do not uniformly contribute to the final prediction, we further propose an adaptive aggregation method to improve the global model utility. Experimental results on three public benchmarks show that RecEraser can not only achieve efficient unlearning, but also outperform the state-of-the-art unlearning methods in terms of model utility. The source code can be found at https://github.com/chenchongthu/Recommendation-Unlearning
A Variational Information Bottleneck Based Method to Compress Sequential Networks for Human Action Recognition
Oct 03, 2020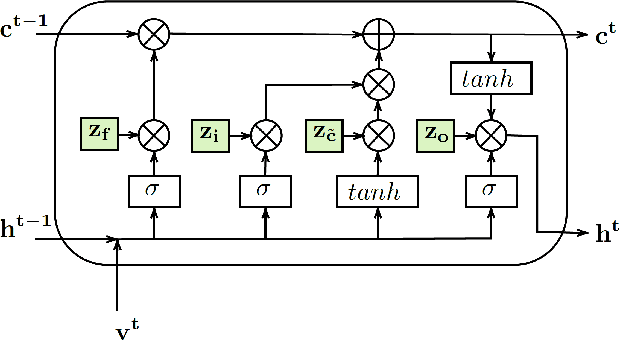
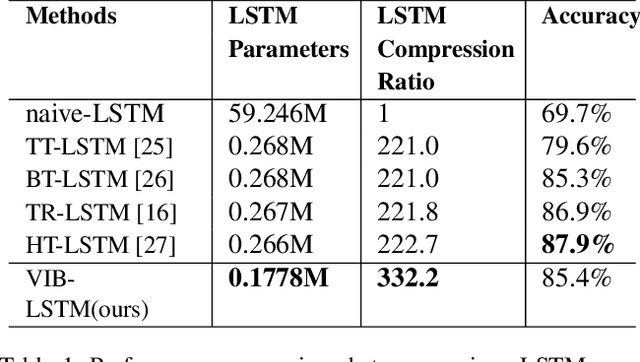
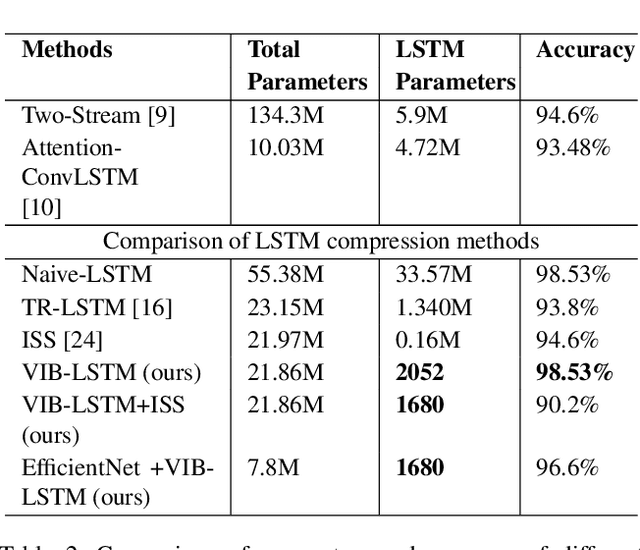
In the last few years, compression of deep neural networks has become an important strand of machine learning and computer vision research. Deep models require sizeable computational complexity and storage, when used for instance for Human Action Recognition (HAR) from videos, making them unsuitable to be deployed on edge devices. In this paper, we address this issue and propose a method to effectively compress Recurrent Neural Networks (RNNs) such as Gated Recurrent Units (GRUs) and Long-Short-Term-Memory Units (LSTMs) that are used for HAR. We use a Variational Information Bottleneck (VIB) theory-based pruning approach to limit the information flow through the sequential cells of RNNs to a small subset. Further, we combine our pruning method with a specific group-lasso regularization technique that significantly improves compression. The proposed techniques reduce model parameters and memory footprint from latent representations, with little or no reduction in the validation accuracy while increasing the inference speed several-fold. We perform experiments on the three widely used Action Recognition datasets, viz. UCF11, HMDB51, and UCF101, to validate our approach. It is shown that our method achieves over 70 times greater compression than the nearest competitor with comparable accuracy for the task of action recognition on UCF11.
Privacy Amplification via Shuffling for Linear Contextual Bandits
Dec 11, 2021
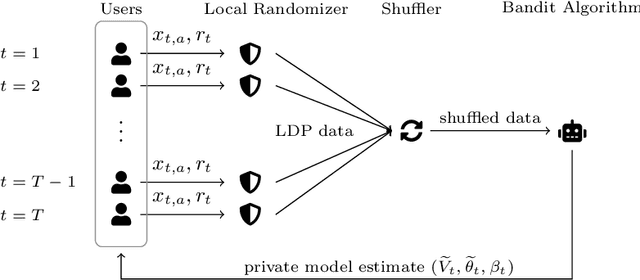
Contextual bandit algorithms are widely used in domains where it is desirable to provide a personalized service by leveraging contextual information, that may contain sensitive information that needs to be protected. Inspired by this scenario, we study the contextual linear bandit problem with differential privacy (DP) constraints. While the literature has focused on either centralized (joint DP) or local (local DP) privacy, we consider the shuffle model of privacy and we show that is possible to achieve a privacy/utility trade-off between JDP and LDP. By leveraging shuffling from privacy and batching from bandits, we present an algorithm with regret bound $\widetilde{\mathcal{O}}(T^{2/3}/\varepsilon^{1/3})$, while guaranteeing both central (joint) and local privacy. Our result shows that it is possible to obtain a trade-off between JDP and LDP by leveraging the shuffle model while preserving local privacy.
Graph-Relational Domain Adaptation
Feb 08, 2022
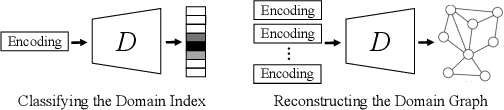
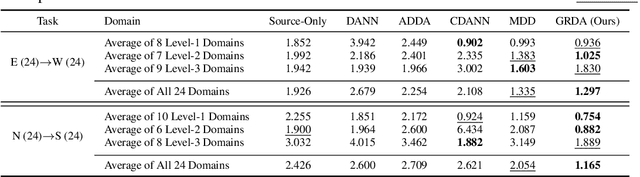
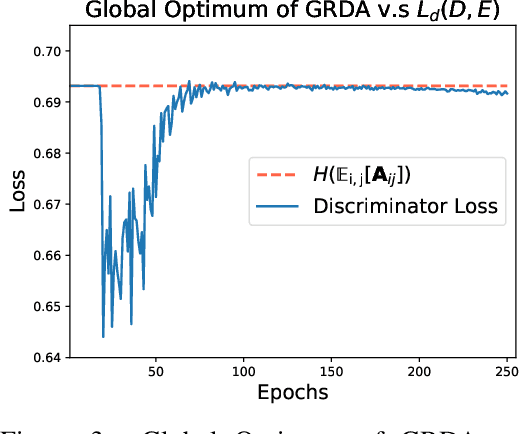
Existing domain adaptation methods tend to treat every domain equally and align them all perfectly. Such uniform alignment ignores topological structures among different domains; therefore it may be beneficial for nearby domains, but not necessarily for distant domains. In this work, we relax such uniform alignment by using a domain graph to encode domain adjacency, e.g., a graph of states in the US with each state as a domain and each edge indicating adjacency, thereby allowing domains to align flexibly based on the graph structure. We generalize the existing adversarial learning framework with a novel graph discriminator using encoding-conditioned graph embeddings. Theoretical analysis shows that at equilibrium, our method recovers classic domain adaptation when the graph is a clique, and achieves non-trivial alignment for other types of graphs. Empirical results show that our approach successfully generalizes uniform alignment, naturally incorporates domain information represented by graphs, and improves upon existing domain adaptation methods on both synthetic and real-world datasets. Code will soon be available at https://github.com/Wang-ML-Lab/GRDA.
PanoDepth: A Two-Stage Approach for Monocular Omnidirectional Depth Estimation
Feb 02, 2022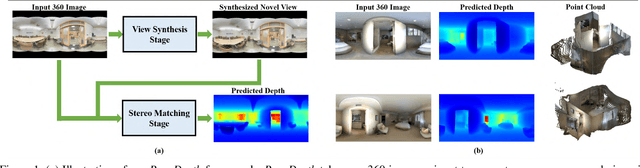
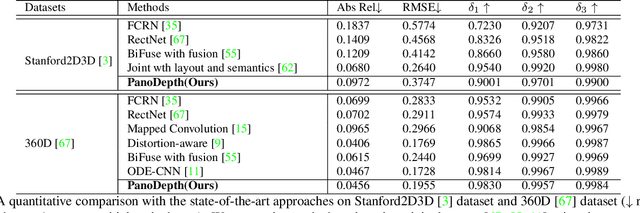
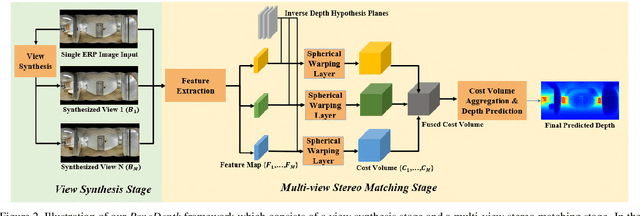

Omnidirectional 3D information is essential for a wide range of applications such as Virtual Reality, Autonomous Driving, Robotics, etc. In this paper, we propose a novel, model-agnostic, two-stage pipeline for omnidirectional monocular depth estimation. Our proposed framework PanoDepth takes one 360 image as input, produces one or more synthesized views in the first stage, and feeds the original image and the synthesized images into the subsequent stereo matching stage. In the second stage, we propose a differentiable Spherical Warping Layer to handle omnidirectional stereo geometry efficiently and effectively. By utilizing the explicit stereo-based geometric constraints in the stereo matching stage, PanoDepth can generate dense high-quality depth. We conducted extensive experiments and ablation studies to evaluate PanoDepth with both the full pipeline as well as the individual modules in each stage. Our results show that PanoDepth outperforms the state-of-the-art approaches by a large margin for 360 monocular depth estimation.
TransCG: A Large-Scale Real-World Dataset for Transparent Object Depth Completion and Grasping
Feb 17, 2022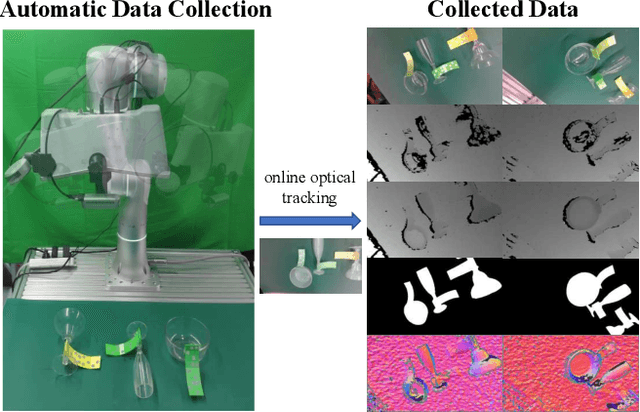

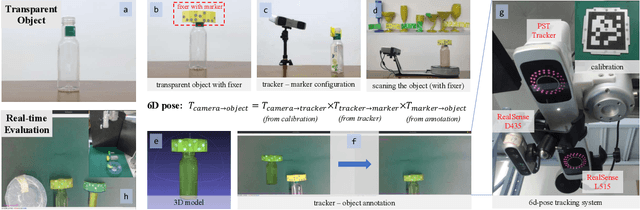
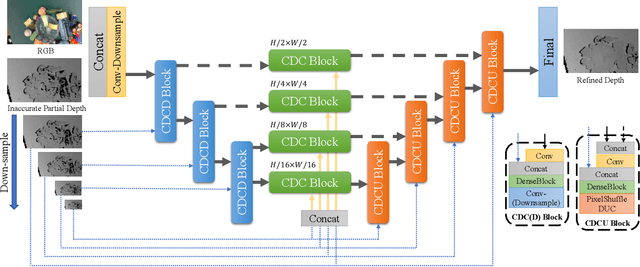
Transparent objects are common in our daily life and frequently handled in the automated production line. Robust vision-based robotic grasping and manipulation for these objects would be beneficial for automation. However, the majority of current grasping algorithms would fail in this case since they heavily rely on the depth image, while ordinary depth sensors usually fail to produce accurate depth information for transparent objects owing to the reflection and refraction of light. In this work, we address this issue by contributing a large-scale real-world dataset for transparent object depth completion, which contains 57,715 RGB-D images from 130 different scenes. Our dataset is the first large-scale real-world dataset and provides the most comprehensive annotation. Cross-domain experiments show that our dataset has a great generalization ability. Moreover, we propose an end-to-end depth completion network, which takes the RGB image and the inaccurate depth map as inputs and outputs a refined depth map. Experiments demonstrate superior efficacy, efficiency and robustness of our method over previous works, and it is able to process images of high resolutions under limited hardware resources. Real robot experiment shows that our method can also be applied to novel object grasping robustly. The full dataset and our method are publicly available at www.graspnet.net/transcg.
DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR
Feb 08, 2022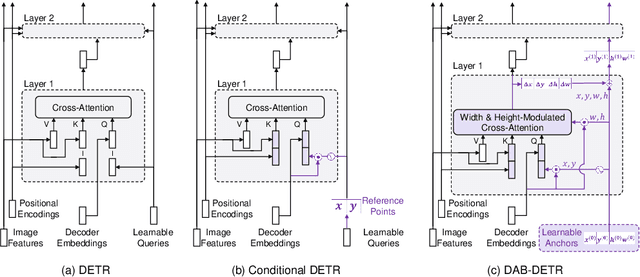


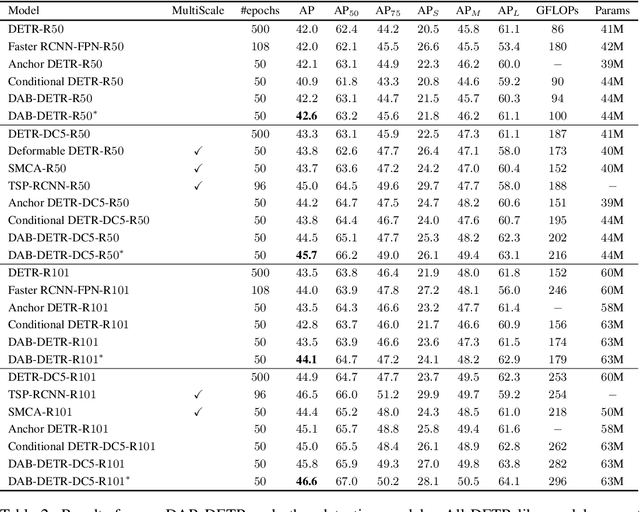
We present in this paper a novel query formulation using dynamic anchor boxes for DETR (DEtection TRansformer) and offer a deeper understanding of the role of queries in DETR. This new formulation directly uses box coordinates as queries in Transformer decoders and dynamically updates them layer-by-layer. Using box coordinates not only helps using explicit positional priors to improve the query-to-feature similarity and eliminate the slow training convergence issue in DETR, but also allows us to modulate the positional attention map using the box width and height information. Such a design makes it clear that queries in DETR can be implemented as performing soft ROI pooling layer-by-layer in a cascade manner. As a result, it leads to the best performance on MS-COCO benchmark among the DETR-like detection models under the same setting, e.g., AP 45.7\% using ResNet50-DC5 as backbone trained in 50 epochs. We also conducted extensive experiments to confirm our analysis and verify the effectiveness of our methods. Code is available at \url{https://github.com/SlongLiu/DAB-DETR}.