 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTrans: Accelerating Transformer Compression with Variational Information Bottleneck based Pruning
Jun 11, 2024



In recent years, there has been a growing emphasis on compressing large pre-trained transformer models for resource-constrained devices. However, traditional pruning methods often leave the embedding layer untouched, leading to model over-parameterization. Additionally, they require extensive compression time with large datasets to maintain performance in pruned models. To address these challenges, we propose VTrans, an iterative pruning framework guided by the Variational Information Bottleneck (VIB) principle. Our method compresses all structural components, including embeddings, attention heads, and layers using VIB-trained masks. This approach retains only essential weights in each layer, ensuring compliance with specified model size or computational constraints. Notably, our method achieves upto 70% more compression than prior state-of-the-art approaches, both task-agnostic and task-specific. We further propose faster variants of our method: Fast-VTrans utilizing only 3% of the data and Faster-VTrans, a time efficient alternative that involves exclusive finetuning of VIB masks, accelerating compression by upto 25 times with minimal performance loss compared to previous methods. Extensive experiments on BERT, ROBERTa, and GPT-2 models substantiate the efficacy of our method. Moreover, our method demonstrates scalability in compressing large models such as LLaMA-2-7B, achieving superior performance compared to previous pruning methods. Additionally, we use attention-based probing to qualitatively assess model redundancy and interpret the efficiency of our approach. Notably, our method considers heads with high attention to special and current tokens in un-pruned model as foremost candidates for pruning while retained heads are observed to attend more to task-critical keywords.
Search-time Efficient Device Constraints-Aware Neural Architecture Search
Jul 10, 2023



Edge computing aims to enable edge devices, such as IoT devices, to process data locally instead of relying on the cloud. However, deep learning techniques like computer vision and natural language processing can be computationally expensive and memory-intensive. Creating manual architectures specialized for each device is infeasible due to their varying memory and computational constraints. To address these concerns, we automate the construction of task-specific deep learning architectures optimized for device constraints through Neural Architecture Search (NAS). We present DCA-NAS, a principled method of fast neural network architecture search that incorporates edge-device constraints such as model size and floating-point operations. It incorporates weight sharing and channel bottleneck techniques to speed up the search time. Based on our experiments, we see that DCA-NAS outperforms manual architectures for similar sized models and is comparable to popular mobile architectures on various image classification datasets like CIFAR-10, CIFAR-100, and Imagenet-1k. Experiments with search spaces -- DARTS and NAS-Bench-201 show the generalization capabilities of DCA-NAS. On further evaluating our approach on Hardware-NAS-Bench, device-specific architectures with low inference latency and state-of-the-art performance were discovered.
A Variational Information Bottleneck Based Method to Compress Sequential Networks for Human Action Recognition
Oct 03, 2020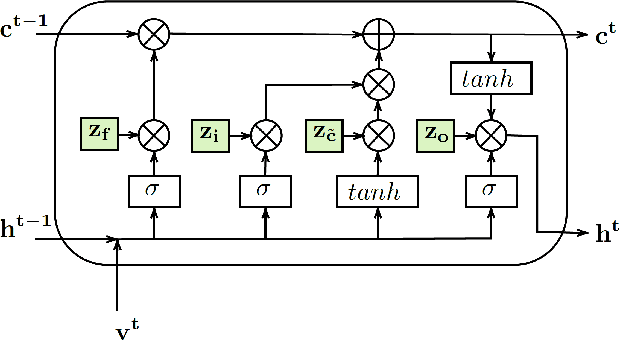
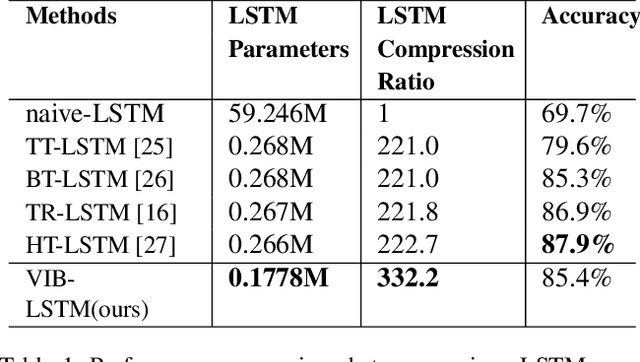
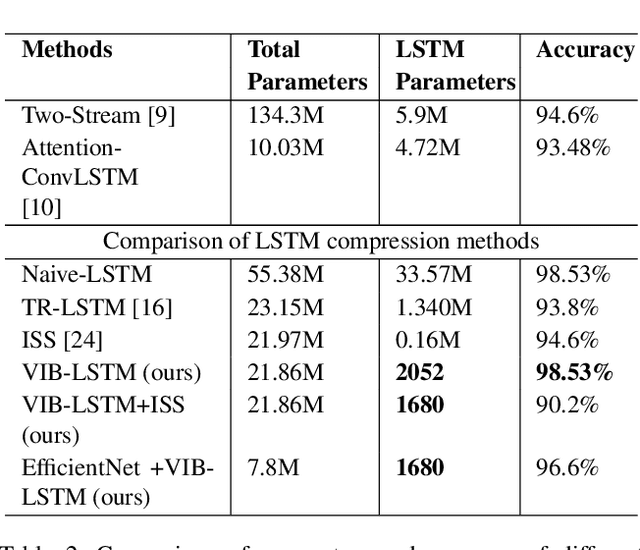
In the last few years, compression of deep neural networks has become an important strand of machine learning and computer vision research. Deep models require sizeable computational complexity and storage, when used for instance for Human Action Recognition (HAR) from videos, making them unsuitable to be deployed on edge devices. In this paper, we address this issue and propose a method to effectively compress Recurrent Neural Networks (RNNs) such as Gated Recurrent Units (GRUs) and Long-Short-Term-Memory Units (LSTMs) that are used for HAR. We use a Variational Information Bottleneck (VIB) theory-based pruning approach to limit the information flow through the sequential cells of RNNs to a small subset. Further, we combine our pruning method with a specific group-lasso regularization technique that significantly improves compression. The proposed techniques reduce model parameters and memory footprint from latent representations, with little or no reduction in the validation accuracy while increasing the inference speed several-fold. We perform experiments on the three widely used Action Recognition datasets, viz. UCF11, HMDB51, and UCF101, to validate our approach. It is shown that our method achieves over 70 times greater compression than the nearest competitor with comparable accuracy for the task of action recognition on UCF11.