 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semantically Video Coding: Instill Static-Dynamic Clues into Structured Bitstream for AI Tasks
Jan 25, 2022
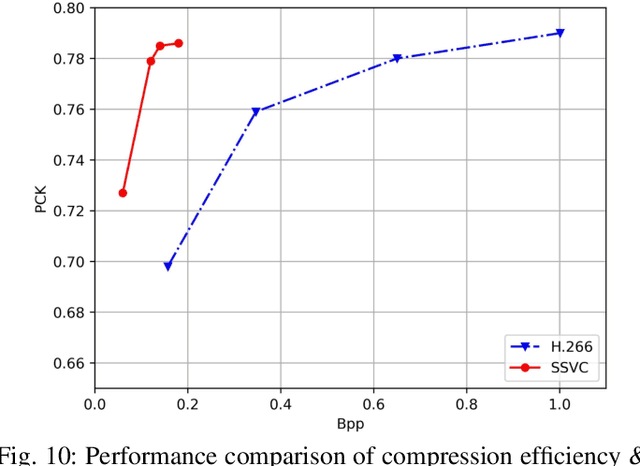
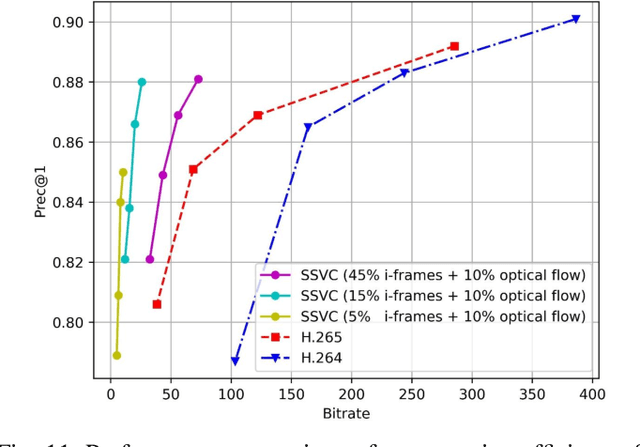
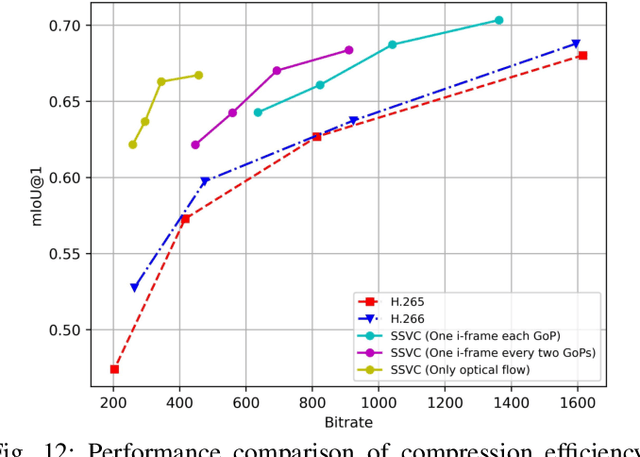
Traditional media coding schemes typically encode image/video into a semantic-unknown binary stream, which fails to directly support downstream intelligent tasks at the bitstream level. Semantically Structured Image Coding (SSIC) framework makes the first attempt to enable decoding-free or partial-decoding image intelligent task analysis via a Semantically Structured Bitstream (SSB). However, the SSIC only considers image coding and its generated SSB only contains the static object information. In this paper, we extend the idea of semantically structured coding from video coding perspective and propose an advanced Semantically Structured Video Coding (SSVC) framework to support heterogeneous intelligent applications. Video signals contain more rich dynamic motion information and exist more redundancy due to the similarity between adjacent frames. Thus, we present a reformulation of semantically structured bitstream (SSB) in SSVC which contains both static object characteristics and dynamic motion clues. Specifically, we introduce optical flow to encode continuous motion information and reduce cross-frame redundancy via a predictive coding architecture, then the optical flow and residual information are reorganized into SSB, which enables the proposed SSVC could better adaptively support video-based downstream intelligent applications. Extensive experiments demonstrate that the proposed SSVC framework could directly support multiple intelligent tasks just depending on a partially decoded bitstream. This avoids the full bitstream decompression and thus significantly saves bitrate/bandwidth consumption for intelligent analytics. We verify this point on the tasks of image object detection, pose estimation, video action recognition, video object segmentation, etc.
WaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Apr 22, 2022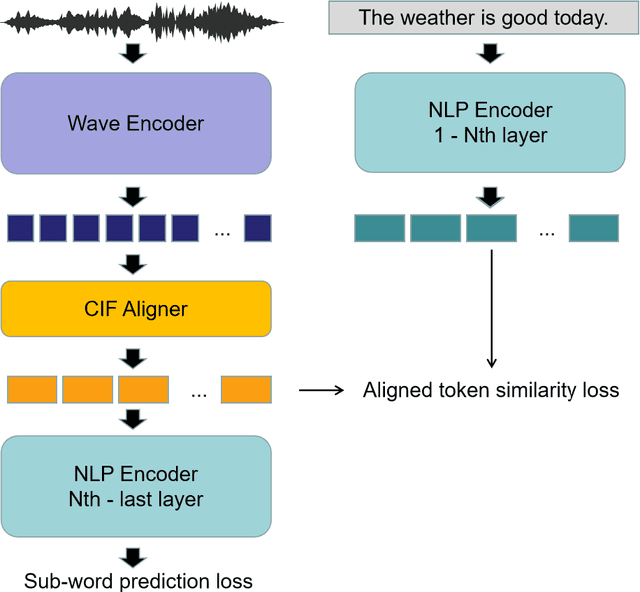


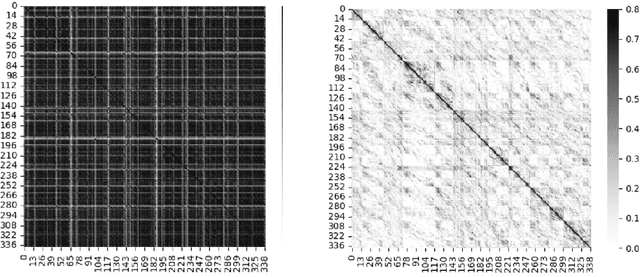
Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021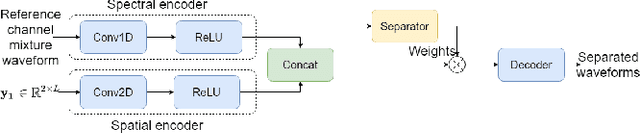
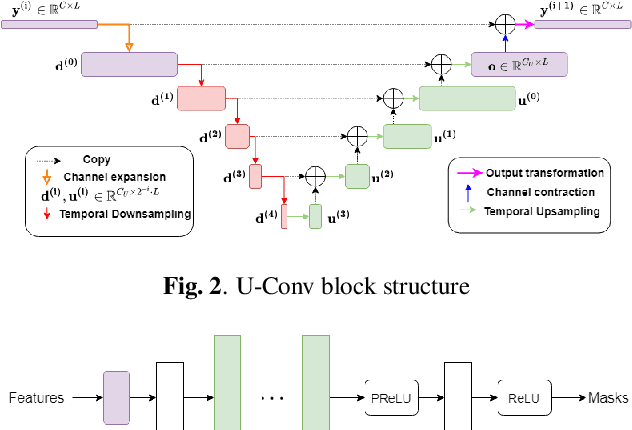
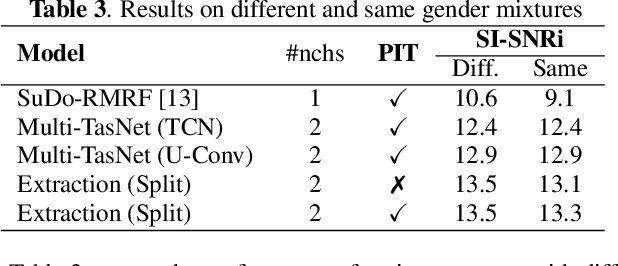

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
CALM: Contrastive Aligned Audio-Language Multirate and Multimodal Representations
Feb 08, 2022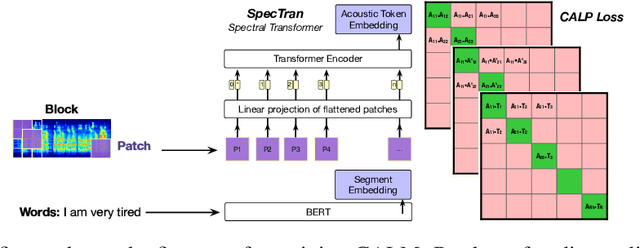
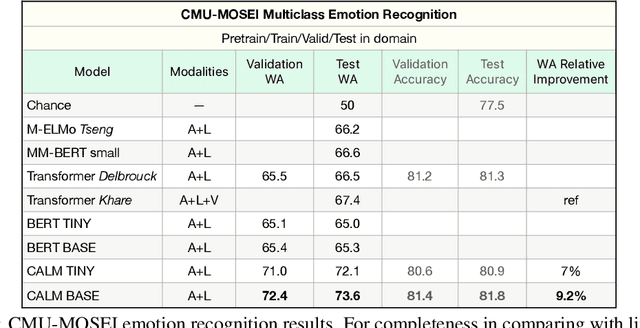
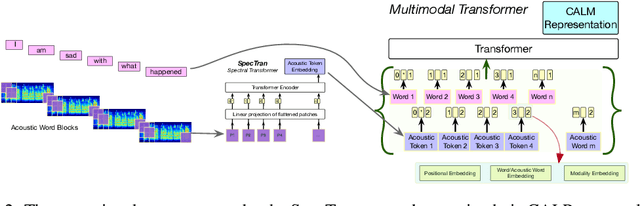
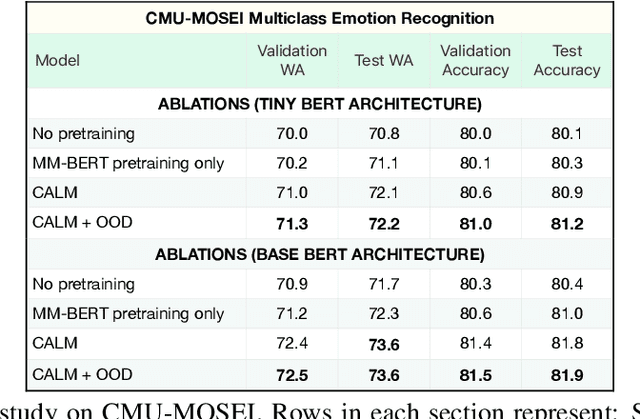
Deriving multimodal representations of audio and lexical inputs is a central problem in Natural Language Understanding (NLU). In this paper, we present Contrastive Aligned Audio-Language Multirate and Multimodal Representations (CALM), an approach for learning multimodal representations using contrastive and multirate information inherent in audio and lexical inputs. The proposed model aligns acoustic and lexical information in the input embedding space of a pretrained language-only contextual embedding model. By aligning audio representations to pretrained language representations and utilizing contrastive information between acoustic inputs, CALM is able to bootstrap audio embedding competitive with existing audio representation models in only a few hours of training time. Operationally, audio spectrograms are processed using linearized patches through a Spectral Transformer (SpecTran) which is trained using a Contrastive Audio-Language Pretraining objective to align audio and language from similar queries. Subsequently, the derived acoustic and lexical tokens representations are input into a multimodal transformer to incorporate utterance level context and derive the proposed CALM representations. We show that these pretrained embeddings can subsequently be used in multimodal supervised tasks and demonstrate the benefits of the proposed pretraining steps in terms of the alignment of the two embedding spaces and the multirate nature of the pretraining. Our system shows 10-25\% improvement over existing emotion recognition systems including state-of-the-art three-modality systems under various evaluation objectives.
Two heads are better than one: Enhancing medical representations by pre-training over structured and unstructured electronic health records
Jan 25, 2022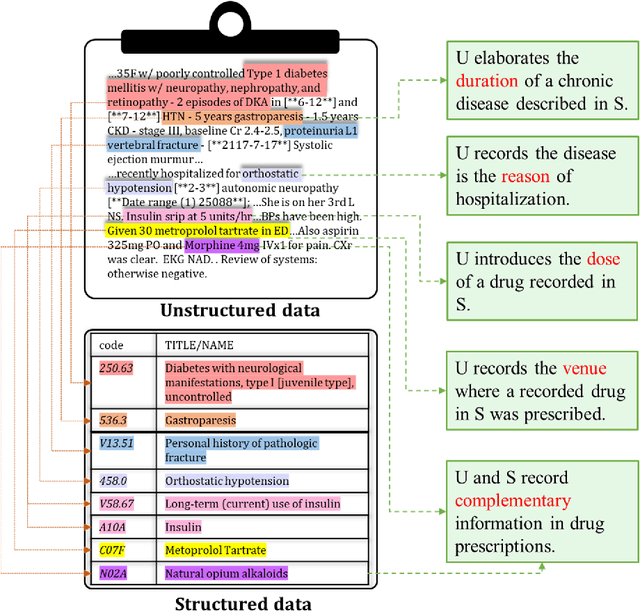
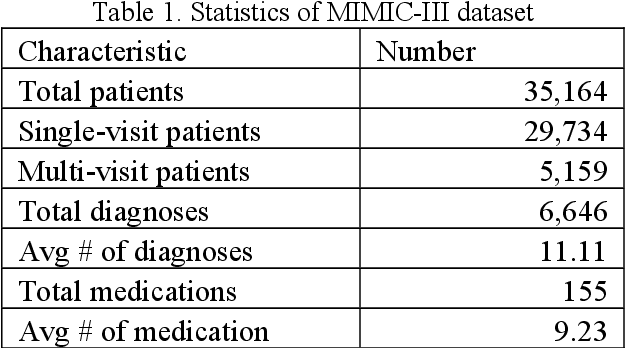
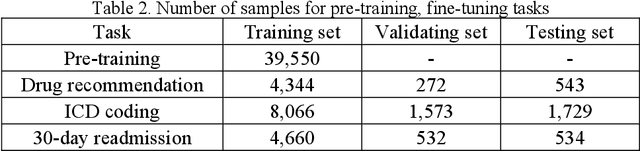
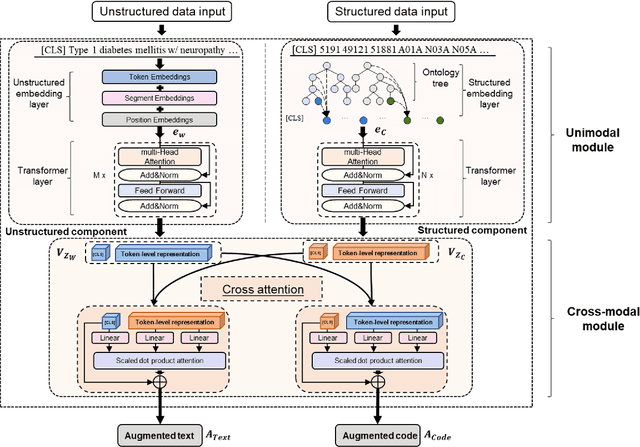
The massive context of electronic health records (EHRs) has created enormous potentials for improving healthcare, among which structured (coded) data and unstructured (text) data are two important textual modalities. They do not exist in isolation and can complement each other in most real-life clinical scenarios. Most existing researches in medical informatics, however, either only focus on a particular modality or straightforwardly concatenate the information from different modalities, which ignore the interaction and information sharing between them. To address these issues, we proposed a unified deep learning-based medical pre-trained language model, named UMM-PLM, to automatically learn representative features from multimodal EHRs that consist of both structured data and unstructured data. Specifically, we first developed parallel unimodal information representation modules to capture the unimodal-specific characteristic, where unimodal representations were learned from each data source separately. A cross-modal module was further introduced to model the interactions between different modalities. We pre-trained the model on a large EHRs dataset containing both structured data and unstructured data and verified the effectiveness of the model on three downstream clinical tasks, i.e., medication recommendation, 30-day readmission and ICD coding through extensive experiments. The results demonstrate the power of UMM-PLM compared with benchmark methods and state-of-the-art baselines. Analyses show that UMM-PLM can effectively concern with multimodal textual information and has the potential to provide more comprehensive interpretations for clinical decision making.
Large-scale Bilingual Language-Image Contrastive Learning
Apr 15, 2022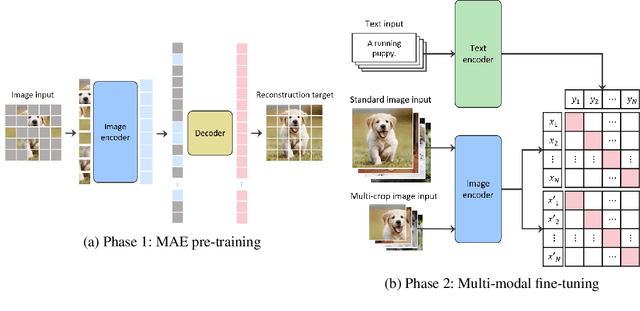
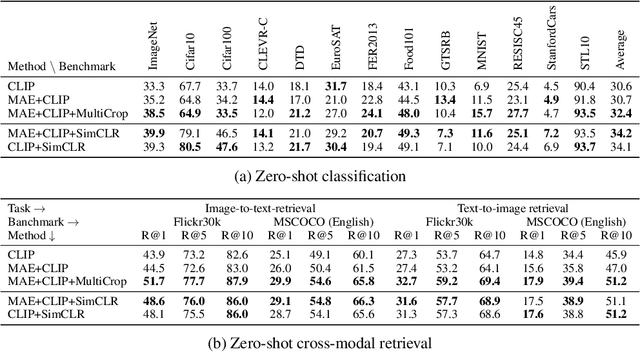
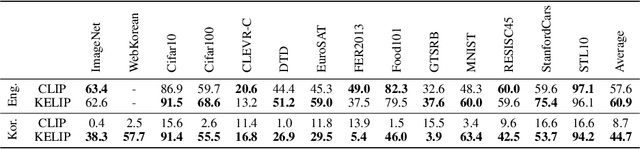
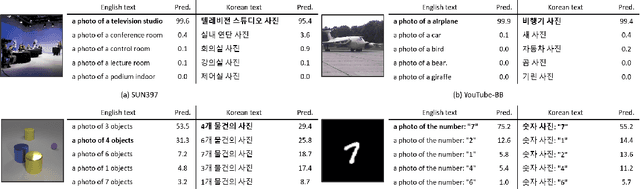
This paper is a technical report to share our experience and findings building a Korean and English bilingual multimodal model. While many of the multimodal datasets focus on English and multilingual multimodal research uses machine-translated texts, employing such machine-translated texts is limited to describing unique expressions, cultural information, and proper noun in languages other than English. In this work, we collect 1.1 billion image-text pairs (708 million Korean and 476 million English) and train a bilingual multimodal model named KELIP. We introduce simple yet effective training schemes, including MAE pre-training and multi-crop augmentation. Extensive experiments demonstrate that a model trained with such training schemes shows competitive performance in both languages. Moreover, we discuss multimodal-related research questions: 1) strong augmentation-based methods can distract the model from learning proper multimodal relations; 2) training multimodal model without cross-lingual relation can learn the relation via visual semantics; 3) our bilingual KELIP can capture cultural differences of visual semantics for the same meaning of words; 4) a large-scale multimodal model can be used for multimodal feature analogy. We hope that this work will provide helpful experience and findings for future research. We provide an open-source pre-trained KELIP.
Adaptive graph convolutional networks for weakly supervised anomaly detection in videos
Feb 14, 2022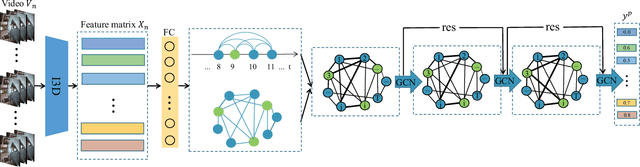

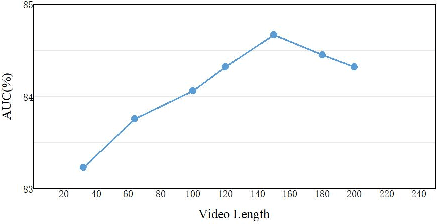
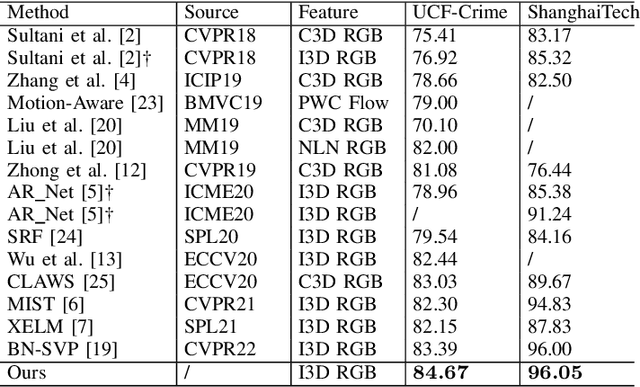
For the weakly supervised anomaly detection task, most existing work is limited to the problem of inadequate video representation due to the inability to model long-time contextual information. We propose a weakly supervised adaptive graph convolutional network (WAGCN) to model the contextual relationships among video segments. And we fully consider the influence of other video segments on the current segment when generating the anomaly probability score for each segment. Firstly, we combine the temporal consistency as well as feature similarity of video segments for composition, which makes full use of the association information among spatial-temporal features of anomalous events in videos. Secondly, we propose a graph learning layer in order to break the limitation of setting topology manually, which adaptively extracts sparse graph adjacency matrix based on data. Extensive experiments on two public datasets (i.e., UCF-Crime dataset and ShanghaiTech dataset) demonstrate the effectiveness of our approach.
Multiple-environment Self-adaptive Network for Aerial-view Geo-localization
Apr 18, 2022
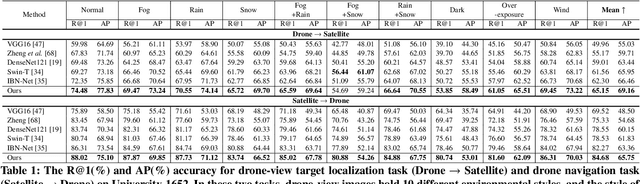
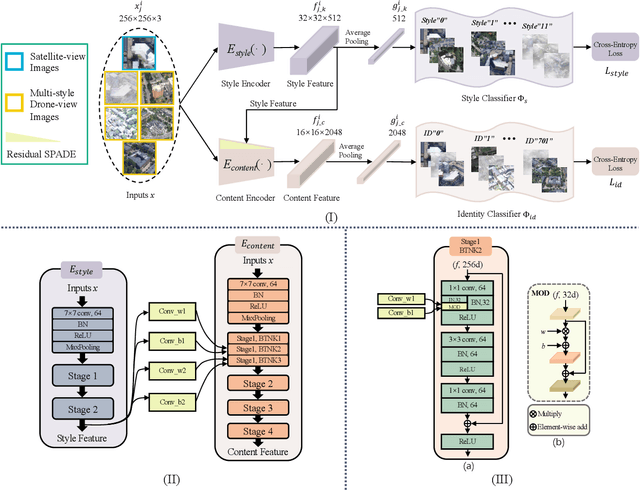

Aerial-view geo-localization tends to determine an unknown position through matching the drone-view image with the geo-tagged satellite-view image. This task is mostly regarded as an image retrieval problem. The key underpinning this task is to design a series of deep neural networks to learn discriminative image descriptors. However, existing methods meet large performance drops under realistic weather, such as rain and fog, since they do not take the domain shift between the training data and multiple test environments into consideration. To minor this domain gap, we propose a Multiple-environment Self-adaptive Network (MuSe-Net) to dynamically adjust the domain shift caused by environmental changing. In particular, MuSe-Net employs a two-branch neural network containing one multiple-environment style extraction network and one self-adaptive feature extraction network. As the name implies, the multiple-environment style extraction network is to extract the environment-related style information, while the self-adaptive feature extraction network utilizes an adaptive modulation module to dynamically minimize the environment-related style gap. Extensive experiments on two widely-used benchmarks, i.e., University-1652 and CVUSA, demonstrate that the proposed MuSe-Net achieves a competitive result for geo-localization in multiple environments. Furthermore, we observe that the proposed method also shows great potential to the unseen extreme weather, such as mixing the fog, rain and snow.
Counterfactual Regret Minimization for Anti-jamming Game of Frequency Agile Radar
Feb 21, 2022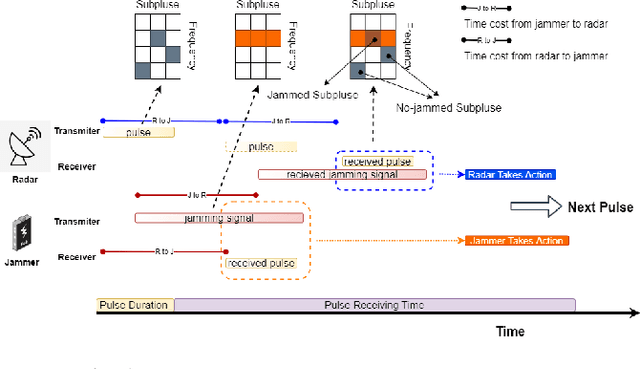
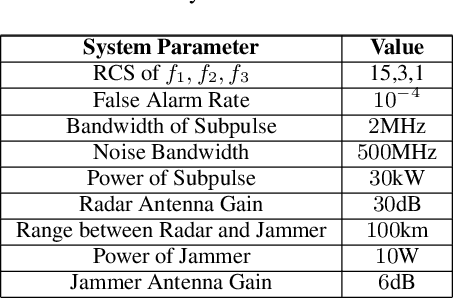
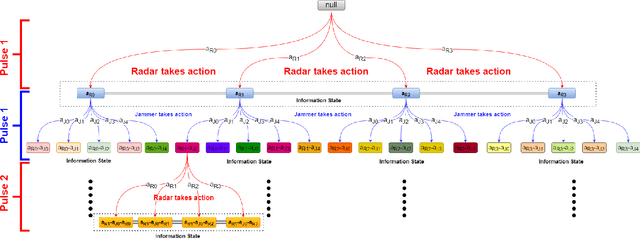
The competition between radar and jammer is one emerging issue in modern electronic warfare, which in principle can be viewed as a non-cooperative game with two players. In this work, the competition between a frequency agile (FA) radar and a noise-modulated jammer is considered. As modern FA radar adopts coherent processing with several pulses, the competition is hence in a multiple-round way where each pulse can be modeled as one round interaction between the radar and jammer. To capture such multiple-round property as well as imperfect information inside the game, i.e., radar and jammer are unable to know the upcoming signal, we propose an extensive-form game formulation for such competition. Since the number of game information states grows exponentially with respect to number of pulses, finding Nash Equilibrium (NE) strategies may be a computationally intractable task. To effectively solve the game, a learning-based algorithm called deep Counterfactual Regret Minimization (CFR) is utilized. Numerical simulations demonstrates the effectiveness of deep CFR algorithm for approximately finding NE and obtaining the best response strategy.
Building a 3-Player Mahjong AI using Deep Reinforcement Learning
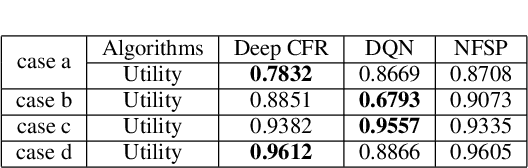
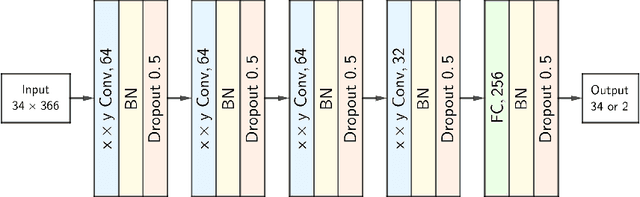
Feb 25, 2022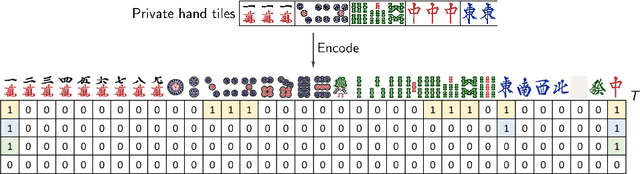
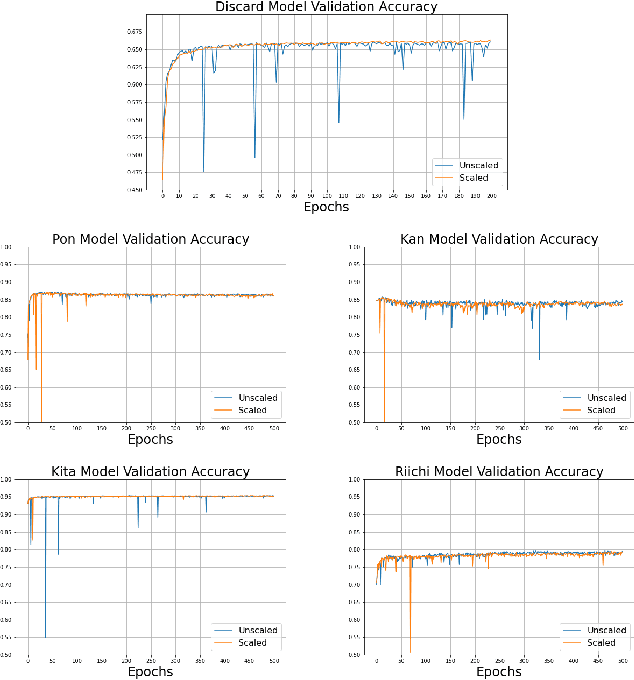
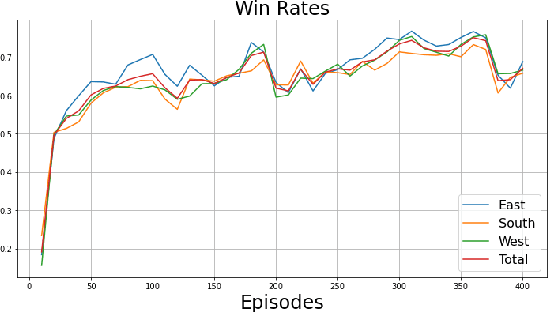
Mahjong is a popular multi-player imperfect-information game developed in China in the late 19th-century, with some very challenging features for AI research. Sanma, being a 3-player variant of the Japanese Riichi Mahjong, possesses unique characteristics including fewer tiles and, consequently, a more aggressive playing style. It is thus challenging and of great research interest in its own right, but has not yet been explored. In this paper, we present Meowjong, an AI for Sanma using deep reinforcement learning. We define an informative and compact 2-dimensional data structure for encoding the observable information in a Sanma game. We pre-train 5 convolutional neural networks (CNNs) for Sanma's 5 actions -- discard, Pon, Kan, Kita and Riichi, and enhance the major action's model, namely the discard model, via self-play reinforcement learning using the Monte Carlo policy gradient method. Meowjong's models achieve test accuracies comparable with AIs for 4-player Mahjong through supervised learning, and gain a significant further enhancement from reinforcement learning. Being the first ever AI in Sanma, we claim that Meowjong stands as a state-of-the-art in this game.