 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscover Fast Power Allocation Solution for Multi-Target Tracking via AlphaEvolve Evolution
May 03, 2026Efficient radar resource allocation is a fundamental yet computationally challenging problem, as optimal solutions typically require iterative optimization with high complexity. Motivated by the need for real-time scheduling, robust generalization, and low data dependency, this paper proposes a novel paradigm that leverages large language model (LLM)-guided evolutionary search (AlphaEvolve) to autonomously discover a closed-form power allocation solution for multi-target tracking. The approach encodes high-dimensional radar states into physically inspired features, then evolves a compact and interpretable scoring function, which is transformed to feasible power allocations via a deterministic constraint-satisfying transformation. Extensive experiments demonstrate that the discovered closed-form solution achieves near-optimal tracking accuracy (average relative performance loss of only $1.51\%$), reliable generalization across diverse scenarios and target counts, and over three orders of magnitude speedup compared to conventional iterative solvers. These results highlight the potential of LLM-guided symbolic search to revolutionize not only radar resource management but also broader classes of engineering optimization problems.
Learning an Opponent-aware Anti-jamming Strategy via Online Convex Optimization
Apr 13, 2026The dynamic competition against intelligent jammer systems presents a significant challenge to modern radar. Traditional active anti-jamming strategy learning methods often suffer from low sample efficiency and fail to fully exploit the structures of the adversary jammer. To reveal the inherent structure, this paper adopts an Online Convex Optimization (OCO) framework to capture the competition between a frequency agile radar and a digital radio frequency memory (DRFM)-based intelligent jammer. Recognizing that conventional OCO algorithms also suffer from suboptimal sample efficiency, two refined algorithms are developed that incorporate unbiased gradient estimators specifically tailored to the unique characteristics of DRFM-based jammers. Our theoretical analysis of the regret bound indicates significant improvements in long-term performance compared to standard OCO. The simulation results consistently show that our algorithms outperform traditional OCO and reinforcement learning baselines, achieving faster convergence and better anti-jamming performance.
Leveraging LLM Agents for Automated Optimization Modeling for SASP Problems: A Graph-RAG based Approach
Jan 30, 2025



Automated optimization modeling (AOM) has evoked considerable interest with the rapid evolution of large language models (LLMs). Existing approaches predominantly rely on prompt engineering, utilizing meticulously designed expert response chains or structured guidance. However, prompt-based techniques have failed to perform well in the sensor array signal processing (SASP) area due the lack of specific domain knowledge. To address this issue, we propose an automated modeling approach based on retrieval-augmented generation (RAG) technique, which consists of two principal components: a multi-agent (MA) structure and a graph-based RAG (Graph-RAG) process. The MA structure is tailored for the architectural AOM process, with each agent being designed based on principles of human modeling procedure. The Graph-RAG process serves to match user query with specific SASP modeling knowledge, thereby enhancing the modeling result. Results on ten classical signal processing problems demonstrate that the proposed approach (termed as MAG-RAG) outperforms several AOM benchmarks.
Hybrid Data-Driven SSM for Interpretable and Label-Free mmWave Channel Prediction
Nov 18, 2024



Accurate prediction of mmWave time-varying channels is essential for mitigating the issue of channel aging in complex scenarios owing to high user mobility. Existing channel prediction methods have limitations: classical model-based methods often struggle to track highly nonlinear channel dynamics due to limited expert knowledge, while emerging data-driven methods typically require substantial labeled data for effective training and often lack interpretability. To address these issues, this paper proposes a novel hybrid method that integrates a data-driven neural network into a conventional model-based workflow based on a state-space model (SSM), implicitly tracking complex channel dynamics from data without requiring precise expert knowledge. Additionally, a novel unsupervised learning strategy is developed to train the embedded neural network solely with unlabeled data. Theoretical analyses and ablation studies are conducted to interpret the enhanced benefits gained from the hybrid integration. Numerical simulations based on the 3GPP mmWave channel model corroborate the superior prediction accuracy of the proposed method, compared to state-of-the-art methods that are either purely model-based or data-driven. Furthermore, extensive experiments validate its robustness against various challenging factors, including among others severe channel variations and high noise levels.
Radar Anti-jamming Strategy Learning via Domain-knowledge Enhanced Online Convex Optimization
Feb 29, 2024The dynamic competition between radar and jammer systems presents a significant challenge for modern Electronic Warfare (EW), as current active learning approaches still lack sample efficiency and fail to exploit jammer's characteristics. In this paper, the competition between a frequency agile radar and a Digital Radio Frequency Memory (DRFM)-based intelligent jammer is considered. We introduce an Online Convex Optimization (OCO) framework designed to illustrate this adversarial interaction. Notably, traditional OCO algorithms exhibit suboptimal sample efficiency due to the limited information obtained per round. To address the limitations, two refined algorithms are proposed, utilizing unbiased gradient estimators that leverage the unique attributes of the jammer system. Sub-linear theoretical results on both static regret and universal regret are provided, marking a significant improvement in OCO performance. Furthermore, simulation results reveal that the proposed algorithms outperform common OCO baselines, suggesting the potential for effective deployment in real-world scenarios.
Optimistic Thompson Sampling for No-Regret Learning in Unknown Games
Feb 25, 2024This work tackles the complexities of multi-player scenarios in \emph{unknown games}, where the primary challenge lies in navigating the uncertainty of the environment through bandit feedback alongside strategic decision-making. We introduce Thompson Sampling (TS)-based algorithms that exploit the information of opponents' actions and reward structures, leading to a substantial reduction in experimental budgets -- achieving over tenfold improvements compared to conventional approaches. Notably, our algorithms demonstrate that, given specific reward structures, the regret bound depends logarithmically on the total action space, significantly alleviating the curse of multi-player. Furthermore, we unveil the \emph{Optimism-then-NoRegret} (OTN) framework, a pioneering methodology that seamlessly incorporates our advancements with established algorithms, showcasing its utility in practical scenarios such as traffic routing and radar sensing in the real world.
An Alternating Riemannian Gradient Algorithm for Fair Principal Component Analysis
Oct 28, 2022Fair principal component analysis (FPCA), a ubiquitous dimensionality reduction technique in signal processing and machine learning, aims to find a low-dimensional representation for a high-dimensional dataset in view of fairness. The FPCA problem is a non-convex and non-smooth optimization over the Stiefel manifold. The state-of-the-art methods for solving the problem are subgradient methods and semidefinite relaxation based methods. However, these two types of methods have their obvious limitations and thus are only suitable for efficiently solving the FPCA problem in very special scenarios. The goal of this paper is to develop efficient algorithms for solving the FPCA problem in general settings, especially the very high-dimensional setting. In this paper, we first transform the problem into a smooth non-convex concave minimax optimization over the Stiefel manifold. Then we propose an alternating Riemannian gradient (ARG) algorithm, which performs a Riemannian gradient descent step and an ordinary gradient projection step at each iteration, for solving the general non-convex concave minimax problems over Riemannian manifolds. We prove that ARG can find an $\varepsilon$-stationary point of the above problem within $O(\varepsilon^{-4})$ iterations. Simulation results show that, compared with the state-of-the-art methods, our proposed ARG algorithm can achieve better performance in terms of the solution quality and speed for solving the FPCA problems arising from signal processing and machine learning.
Counterfactual Regret Minimization for Anti-jamming Game of Frequency Agile Radar
Feb 21, 2022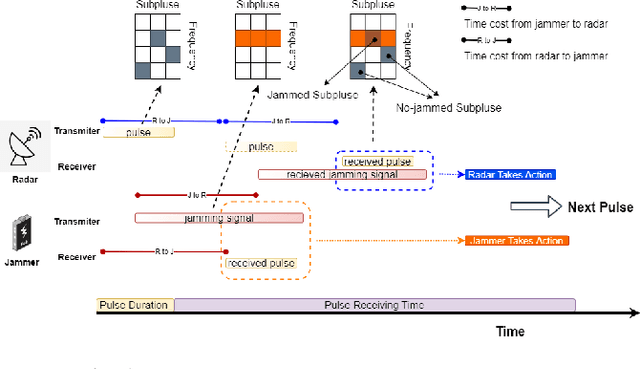
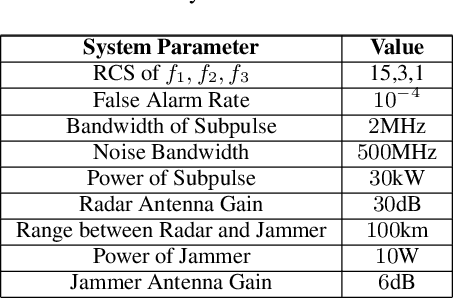
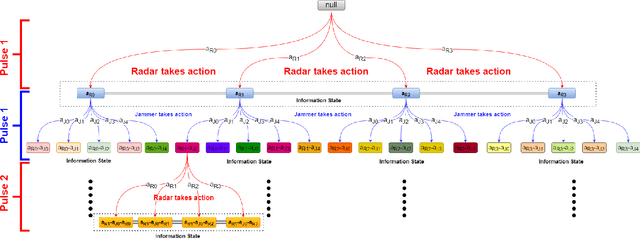
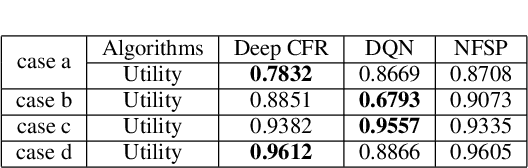
The competition between radar and jammer is one emerging issue in modern electronic warfare, which in principle can be viewed as a non-cooperative game with two players. In this work, the competition between a frequency agile (FA) radar and a noise-modulated jammer is considered. As modern FA radar adopts coherent processing with several pulses, the competition is hence in a multiple-round way where each pulse can be modeled as one round interaction between the radar and jammer. To capture such multiple-round property as well as imperfect information inside the game, i.e., radar and jammer are unable to know the upcoming signal, we propose an extensive-form game formulation for such competition. Since the number of game information states grows exponentially with respect to number of pulses, finding Nash Equilibrium (NE) strategies may be a computationally intractable task. To effectively solve the game, a learning-based algorithm called deep Counterfactual Regret Minimization (CFR) is utilized. Numerical simulations demonstrates the effectiveness of deep CFR algorithm for approximately finding NE and obtaining the best response strategy.
To Supervise or Not: How to Effectively Learn Wireless Interference Management Models?
Dec 28, 2021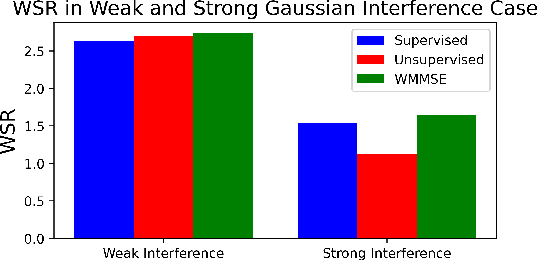
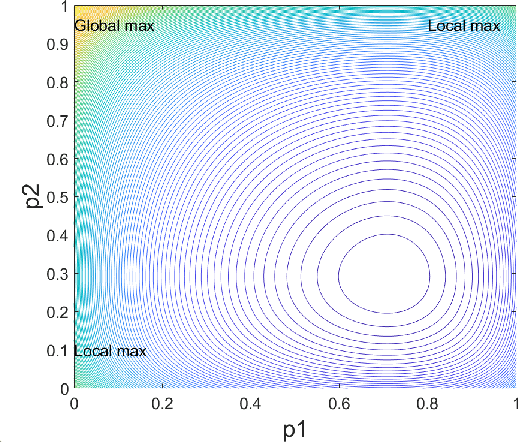
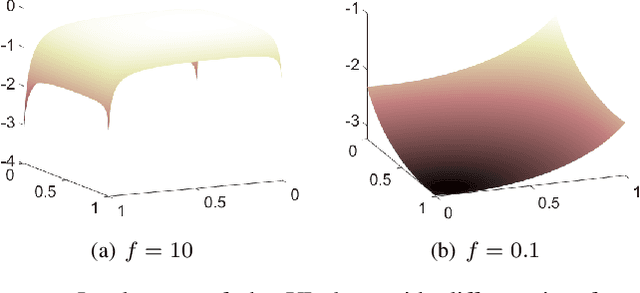
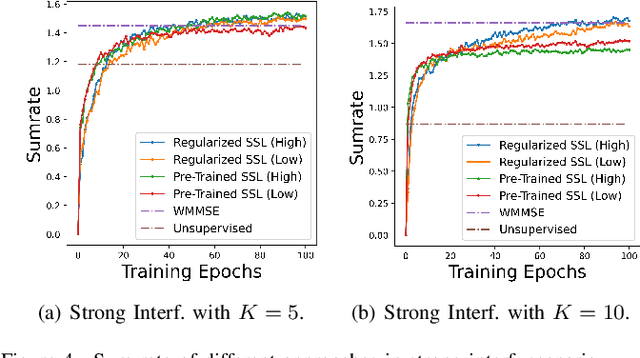
Machine learning has become successful in solving wireless interference management problems. Different kinds of deep neural networks (DNNs) have been trained to accomplish key tasks such as power control, beamforming and admission control. There are two popular training paradigms for such DNNs-based interference management models: supervised learning (i.e., fitting labels generated by an optimization algorithm) and unsupervised learning (i.e., directly optimizing some system performance measure). Although both of these paradigms have been extensively applied in practice, due to the lack of any theoretical understanding about these methods, it is not clear how to systematically understand and compare their performance. In this work, we conduct theoretical studies to provide some in-depth understanding about these two training paradigms. First, we show a somewhat surprising result, that for some special power control problem, the unsupervised learning can perform much worse than its supervised counterpart, because it is more likely to stuck at some low-quality local solutions. We then provide a series of theoretical results to further understand the properties of the two approaches. Generally speaking, we show that when high-quality labels are available, then the supervised learning is less likely to be stuck at a solution than its unsupervised counterpart. Additionally, we develop a semi-supervised learning approach which properly integrates these two training paradigms, and can effectively utilize limited number of labels to find high-quality solutions. To our knowledge, these are the first set of theoretical results trying to understand different training approaches in learning-based wireless communication system design.
Efficient Estimation of Sensor Biases for the 3-Dimensional Asynchronous Multi-Sensor System
Sep 04, 2021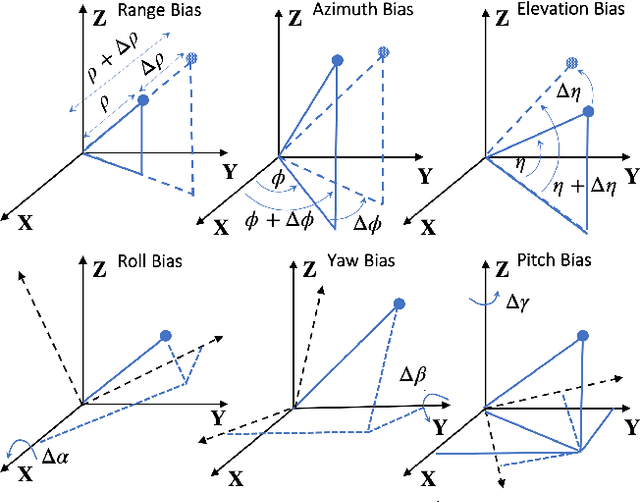
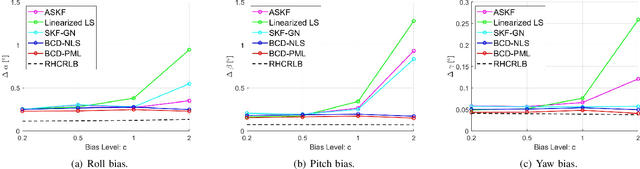
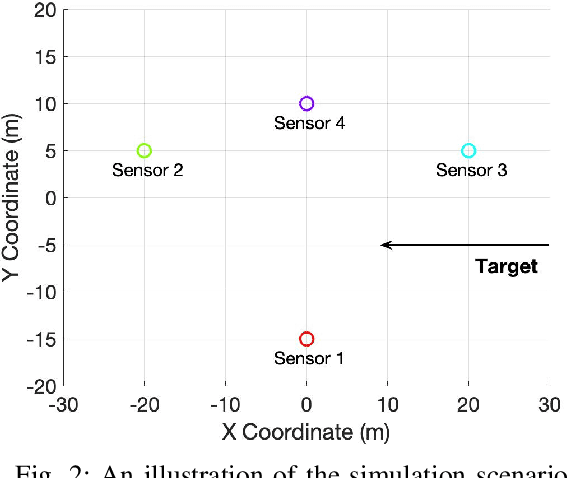
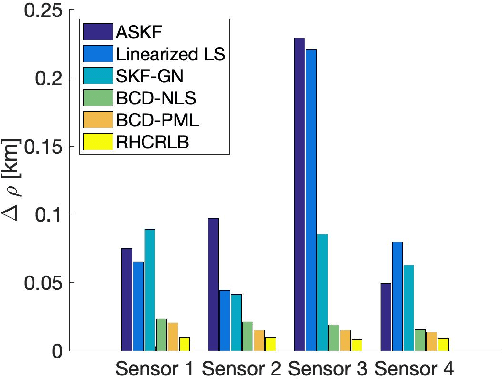
An important preliminary procedure in multi-sensor data fusion is sensor registration, and the key step in this procedure is to estimate sensor biases from their noisy measurements. There are generally two difficulties in this bias estimation problem: one is the unknown target states which serve as the nuisance variables in the estimation problem, and the other is the highly nonlinear coordinate transformation between the local and global coordinate systems of the sensors. In this paper, we focus on the 3-dimensional asynchronous multi-sensor scenario and propose a weighted nonlinear least squares (NLS) formulation by assuming that there is a target moving with a nearly constant velocity. We propose two possible choices of the weighting matrix in the NLS formulation, which correspond to classical NLS estimation and maximum likelihood (ML) estimation, respectively. To address the intrinsic nonlinearity, we propose a block coordinate descent (BCD) algorithm for solving the formulated problem, which alternately updates different kinds of bias estimates. Specifically, the proposed BCD algorithm involves solving linear LS problems and nonconvex quadratically constrained quadratic program (QCQP) problems with special structures. Instead of adopting the semidefinite relaxation technique, we develop a much more computationally efficient algorithm (with global performance guarantee under certain conditions) to solve the nonconvex QCQP subproblems. The effectiveness and efficiency of the proposed BCD algorithm are demonstrated via numerical simulations.