 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Video Coding: Instill Static-Dynamic Clues into Structured Bitstream for AI Tasks
Paper and Code
Jan 25, 2022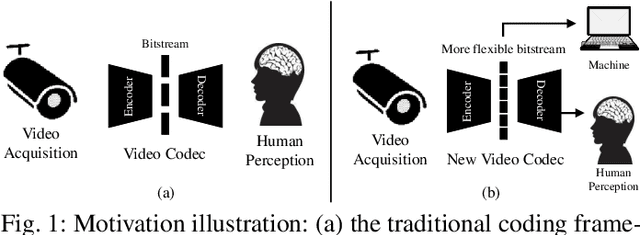
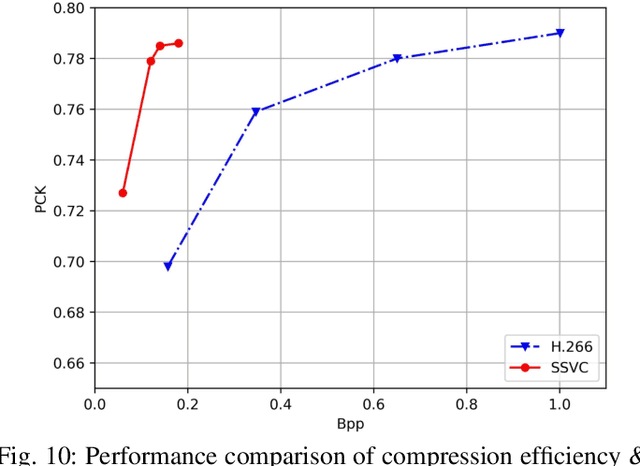
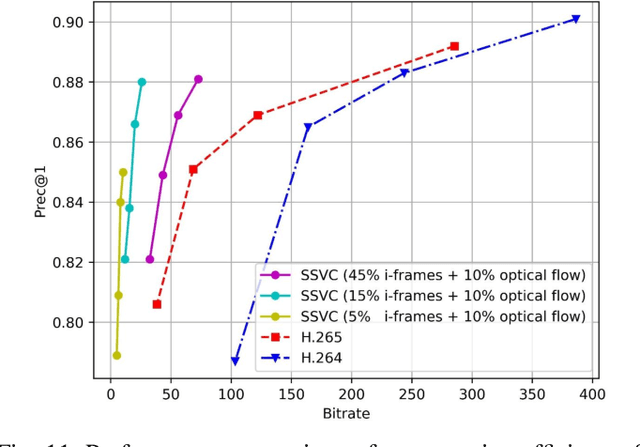
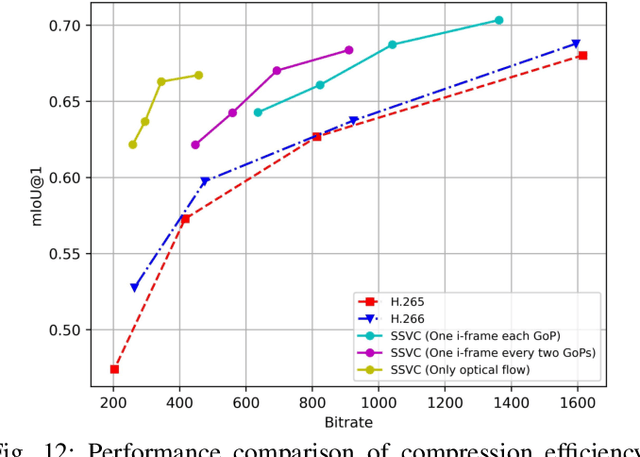
Traditional media coding schemes typically encode image/video into a semantic-unknown binary stream, which fails to directly support downstream intelligent tasks at the bitstream level. Semantically Structured Image Coding (SSIC) framework makes the first attempt to enable decoding-free or partial-decoding image intelligent task analysis via a Semantically Structured Bitstream (SSB). However, the SSIC only considers image coding and its generated SSB only contains the static object information. In this paper, we extend the idea of semantically structured coding from video coding perspective and propose an advanced Semantically Structured Video Coding (SSVC) framework to support heterogeneous intelligent applications. Video signals contain more rich dynamic motion information and exist more redundancy due to the similarity between adjacent frames. Thus, we present a reformulation of semantically structured bitstream (SSB) in SSVC which contains both static object characteristics and dynamic motion clues. Specifically, we introduce optical flow to encode continuous motion information and reduce cross-frame redundancy via a predictive coding architecture, then the optical flow and residual information are reorganized into SSB, which enables the proposed SSVC could better adaptively support video-based downstream intelligent applications. Extensive experiments demonstrate that the proposed SSVC framework could directly support multiple intelligent tasks just depending on a partially decoded bitstream. This avoids the full bitstream decompression and thus significantly saves bitrate/bandwidth consumption for intelligent analytics. We verify this point on the tasks of image object detection, pose estimation, video action recognition, video object segmentation, etc.