 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-regularised Minimum Latency Training for Streaming Transformer-based Speech Recognition
Apr 24, 2023



This paper proposes a self-regularised minimum latency training (SR-MLT) method for streaming Transformer-based automatic speech recognition (ASR) systems. In previous works, latency was optimised by truncating the online attention weights based on the hard alignments obtained from conventional ASR models, without taking into account the potential loss of ASR accuracy. On the contrary, here we present a strategy to obtain the alignments as a part of the model training without external supervision. The alignments produced by the proposed method are dynamically regularised on the training data, such that the latency reduction does not result in the loss of ASR accuracy. SR-MLT is applied as a fine-tuning step on the pre-trained Transformer models that are based on either monotonic chunkwise attention (MoChA) or cumulative attention (CA) algorithms for online decoding. ASR experiments on the AIShell-1 and Librispeech datasets show that when applied on a decent pre-trained MoChA or CA baseline model, SR-MLT can effectively reduce the latency with the relative gains ranging from 11.8% to 39.5%. Furthermore, we also demonstrate that under certain accuracy levels, the models trained with SR-MLT can achieve lower latency when compared to those supervised using external hard alignments.
Speaker Reinforcement Using Target Source Extraction for Robust Automatic Speech Recognition
May 09, 2022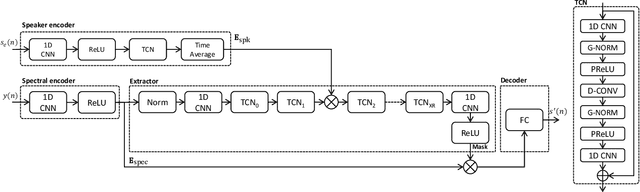

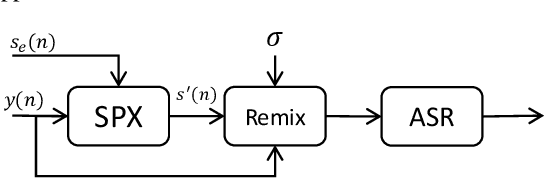
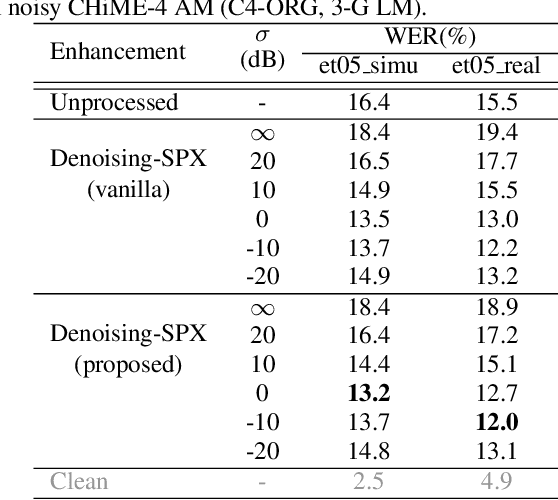
Improving the accuracy of single-channel automatic speech recognition (ASR) in noisy conditions is challenging. Strong speech enhancement front-ends are available, however, they typically require that the ASR model is retrained to cope with the processing artifacts. In this paper we explore a speaker reinforcement strategy for improving recognition performance without retraining the acoustic model (AM). This is achieved by remixing the enhanced signal with the unprocessed input to alleviate the processing artifacts. We evaluate the proposed approach using a DNN speaker extraction based speech denoiser trained with a perceptually motivated loss function. Results show that (without AM retraining) our method yields about 23% and 25% relative accuracy gains compared with the unprocessed for the monoaural simulated and real CHiME-4 evaluation sets, respectively, and outperforms a state-of-the-art reference method.
On monoaural speech enhancement for automatic recognition of real noisy speech using mixture invariant training
May 03, 2022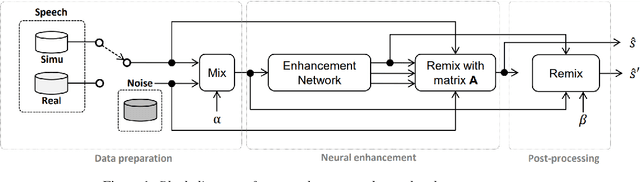
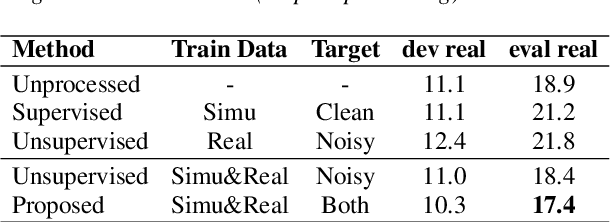
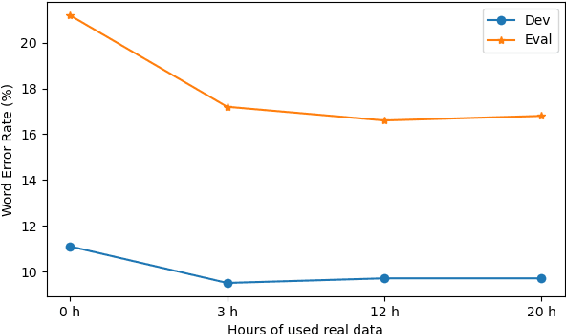
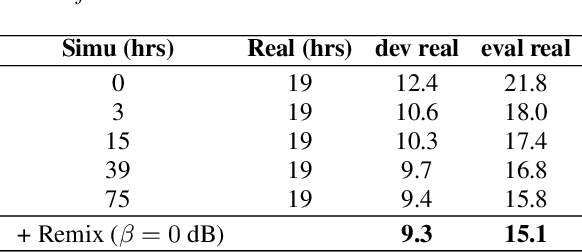
In this paper, we explore an improved framework to train a monoaural neural enhancement model for robust speech recognition. The designed training framework extends the existing mixture invariant training criterion to exploit both unpaired clean speech and real noisy data. It is found that the unpaired clean speech is crucial to improve quality of separated speech from real noisy speech. The proposed method also performs remixing of processed and unprocessed signals to alleviate the processing artifacts. Experiments on the single-channel CHiME-3 real test sets show that the proposed method improves significantly in terms of speech recognition performance over the enhancement system trained either on the mismatched simulated data in a supervised fashion or on the matched real data in an unsupervised fashion. Between 16% and 39% relative WER reduction has been achieved by the proposed system compared to the unprocessed signal using end-to-end and hybrid acoustic models without retraining on distorted data.
Transformer-based Streaming ASR with Cumulative Attention
Mar 11, 2022
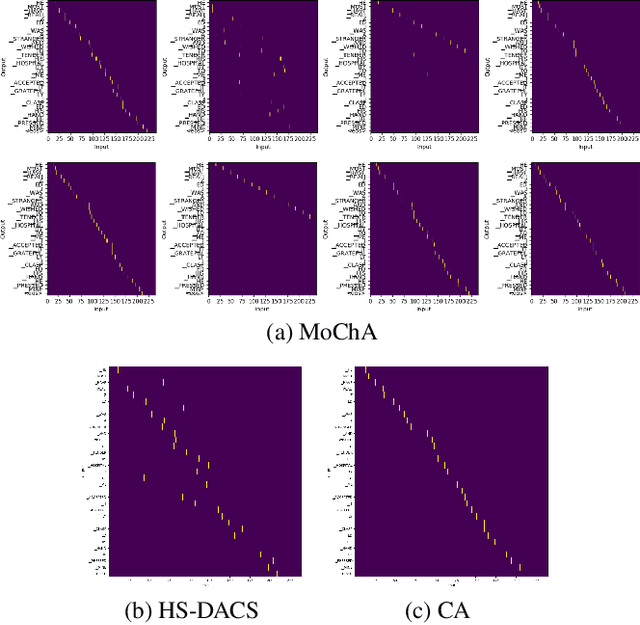
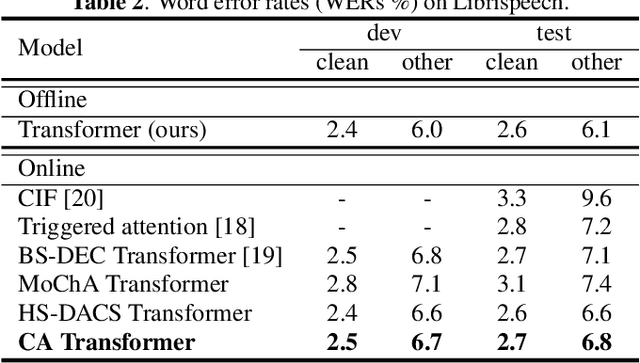
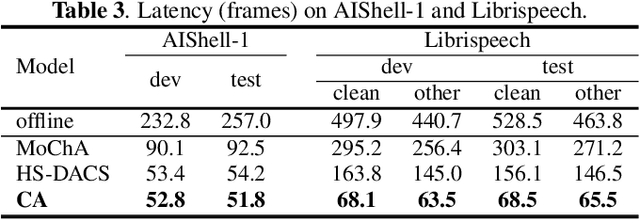
In this paper, we propose an online attention mechanism, known as cumulative attention (CA), for streaming Transformer-based automatic speech recognition (ASR). Inspired by monotonic chunkwise attention (MoChA) and head-synchronous decoder-end adaptive computation steps (HS-DACS) algorithms, CA triggers the ASR outputs based on the acoustic information accumulated at each encoding timestep, where the decisions are made using a trainable device, referred to as halting selector. In CA, all the attention heads of the same decoder layer are synchronised to have a unified halting position. This feature effectively alleviates the problem caused by the distinct behaviour of individual heads, which may otherwise give rise to severe latency issues as encountered by MoChA. The ASR experiments conducted on AIShell-1 and Librispeech datasets demonstrate that the proposed CA-based Transformer system can achieve on par or better performance with significant reduction in latency during inference, when compared to other streaming Transformer systems in literature.
Monaural source separation: From anechoic to reverberant environments
Nov 15, 2021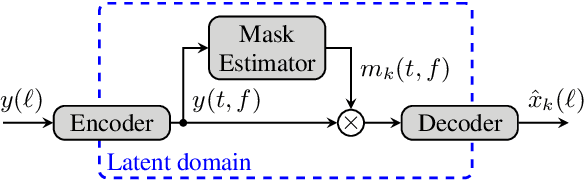
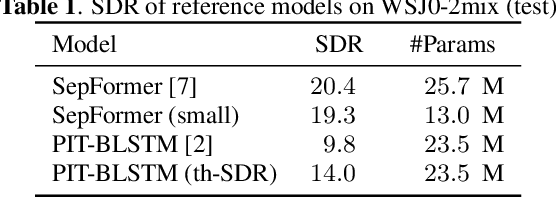
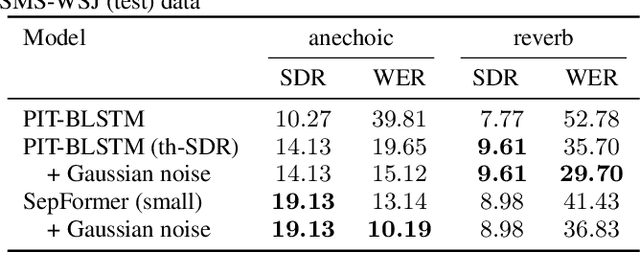
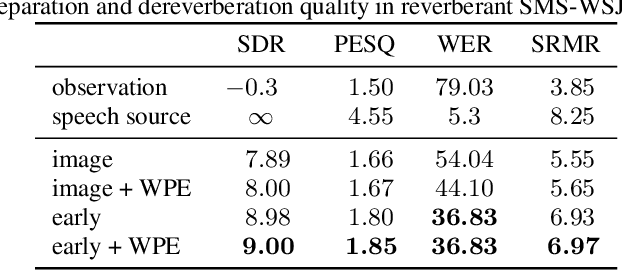
Impressive progress in neural network-based single-channel speech source separation has been made in recent years. But those improvements have been mostly reported on anechoic data, a situation that is hardly met in practice. Taking the SepFormer as a starting point, which achieves state-of-the-art performance on anechoic mixtures, we gradually modify it to optimize its performance on reverberant mixtures. Although this leads to a word error rate improvement by 8 percentage points compared to the standard SepFormer implementation, the system ends up with only marginally better performance than our improved PIT-BLSTM separation system, that is optimized with rather straightforward means. This is surprising and at the same time sobering, challenging the practical usefulness of many improvements reported in recent years for monaural source separation on nonreverberant data.
Teacher-Student MixIT for Unsupervised and Semi-supervised Speech Separation
Jun 16, 2021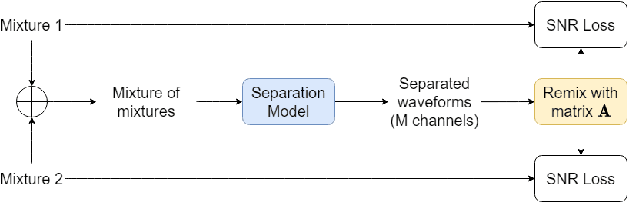
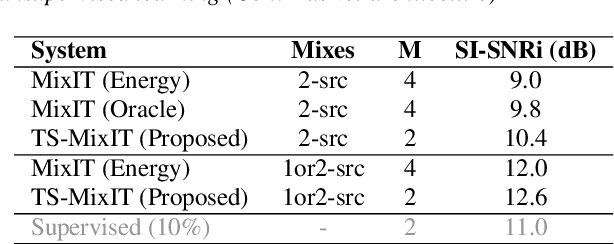
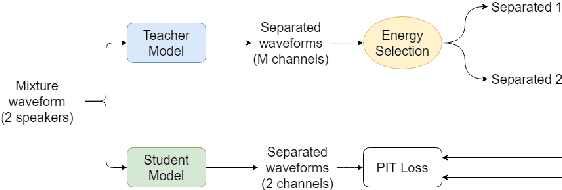
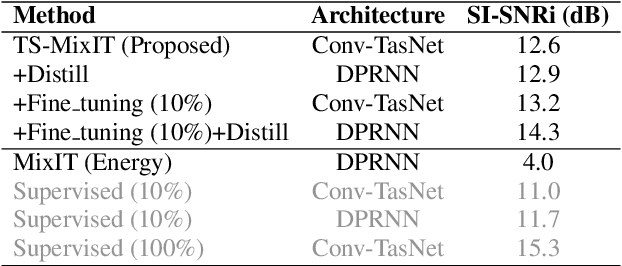
In this paper, we introduce a novel semi-supervised learning framework for end-to-end speech separation. The proposed method first uses mixtures of unseparated sources and the mixture invariant training (MixIT) criterion to train a teacher model. The teacher model then estimates separated sources that are used to train a student model with standard permutation invariant training (PIT). The student model can be fine-tuned with supervised data, i.e., paired artificial mixtures and clean speech sources, and further improved via model distillation. Experiments with single and multi channel mixtures show that the teacher-student training resolves the over-separation problem observed in the original MixIT method. Further, the semisupervised performance is comparable to a fully-supervised separation system trained using ten times the amount of supervised data.
Head-synchronous Decoding for Transformer-based Streaming ASR
Apr 26, 2021
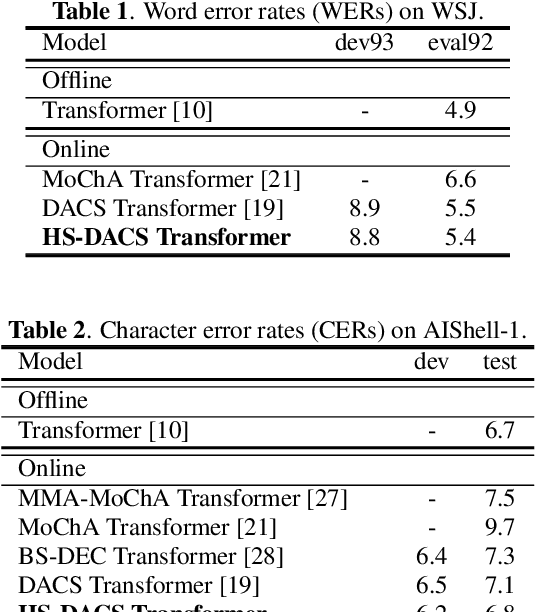
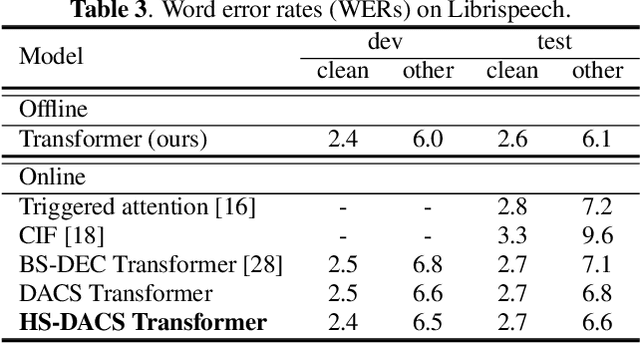
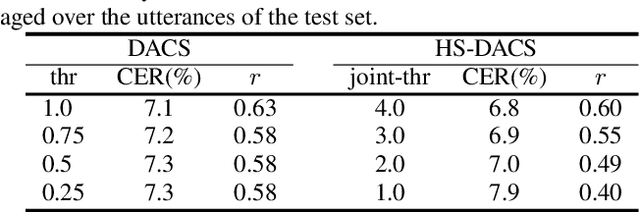
Online Transformer-based automatic speech recognition (ASR) systems have been extensively studied due to the increasing demand for streaming applications. Recently proposed Decoder-end Adaptive Computation Steps (DACS) algorithm for online Transformer ASR was shown to achieve state-of-the-art performance and outperform other existing methods. However, like any other online approach, the DACS-based attention heads in each of the Transformer decoder layers operate independently (or asynchronously) and lead to diverged attending positions. Since DACS employs a truncation threshold to determine the halting position, some of the attention weights are cut off untimely and might impact the stability and precision of decoding. To overcome these issues, here we propose a head-synchronous (HS) version of the DACS algorithm, where the boundary of attention is jointly detected by all the DACS heads in each decoder layer. ASR experiments on Wall Street Journal (WSJ), AIShell-1 and Librispeech show that the proposed method consistently outperforms vanilla DACS and achieves state-of-the-art performance. We will also demonstrate that HS-DACS has reduced decoding cost when compared to vanilla DACS.
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021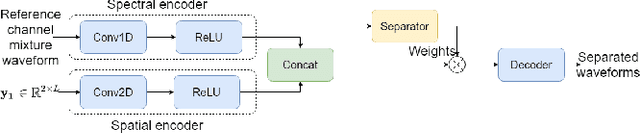
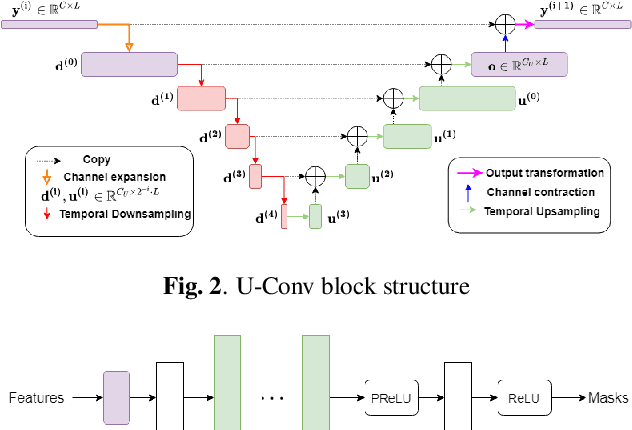
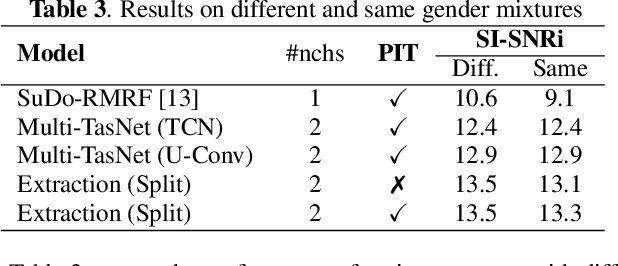

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
On End-to-end Multi-channel Time Domain Speech Separation in Reverberant Environments
Nov 11, 2020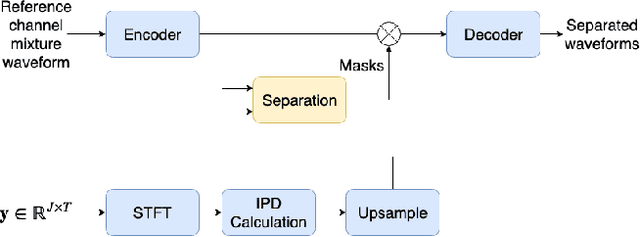

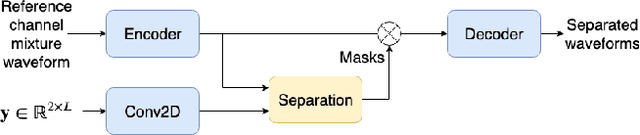
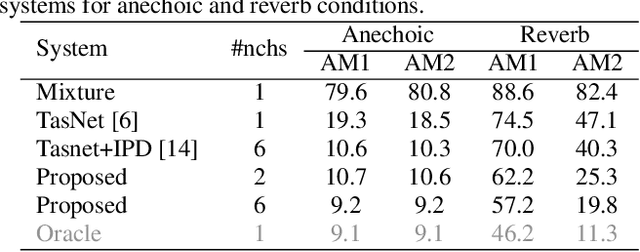
This paper introduces a new method for multi-channel time domain speech separation in reverberant environments. A fully-convolutional neural network structure has been used to directly separate speech from multiple microphone recordings, with no need of conventional spatial feature extraction. To reduce the influence of reverberation on spatial feature extraction, a dereverberation pre-processing method has been applied to further improve the separation performance. A spatialized version of wsj0-2mix dataset has been simulated to evaluate the proposed system. Both source separation and speech recognition performance of the separated signals have been evaluated objectively. Experiments show that the proposed fully-convolutional network improves the source separation metric and the word error rate (WER) by more than 13% and 50% relative, respectively, over a reference system with conventional features. Applying dereverberation as pre-processing to the proposed system can further reduce the WER by 29% relative using an acoustic model trained on clean and reverberated data.
* Presented at IEEE ICASSP 2020
An Investigation into the Effectiveness of Enhancement in ASR Training and Test for CHiME-5 Dinner Party Transcription
Sep 26, 2019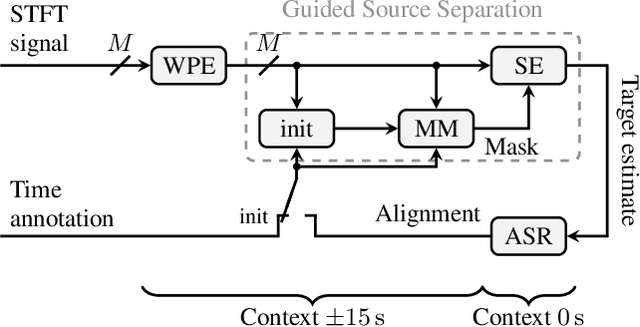
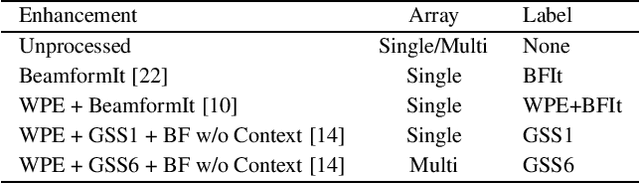

Despite the strong modeling power of neural network acoustic models, speech enhancement has been shown to deliver additional word error rate improvements if multi-channel data is available. However, there has been a longstanding debate whether enhancement should also be carried out on the ASR training data. In an extensive experimental evaluation on the acoustically very challenging CHiME-5 dinner party data we show that: (i) cleaning up the training data can lead to substantial error rate reductions, and (ii) enhancement in training is advisable as long as enhancement in test is at least as strong as in training. This approach stands in contrast and delivers larger gains than the common strategy reported in the literature to augment the training database with additional artificially degraded speech. Together with an acoustic model topology consisting of initial CNN layers followed by factorized TDNN layers we achieve with 41.6% and 43.2% WER on the DEV and EVAL test sets, respectively, a new single-system state-of-the-art result on the CHiME-5 data. This is a 8% relative improvement compared to the best word error rate published so far for a speech recognizer without system combination.