 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See What You Need: Gaze Attention for Multimodal Large Language Models
May 13, 2026When humans describe a visual scene, they do not process the entire image uniformly; instead, they selectively fixate on regions relevant to their intended description. In contrast, current multimodal large language models (MLLMs) attend to all visual tokens at each generation step, leading to diluted focus and unnecessary computational overhead. In this work, we introduce Gaze Attention, a novel mechanism that enables MLLMs to selectively attend to task-relevant visual regions during generation. Specifically, we spatially group visual embeddings-stored as key-value caches-into compact gaze regions, each represented by a lightweight descriptor. At each decoding step, the model dynamically selects the most relevant regions and restricts attention to them, reducing redundant computation while enhancing focus. To mitigate the loss of global context caused by localized attention, we further propose learnable context tokens appended to each image or frame, allowing the model to maintain holistic visual awareness. Extensive experiments on image and video understanding benchmarks demonstrate that Gaze Attention matches or surpasses dense-attention baselines, while using up to 90% fewer visual KV entries in the attention computation.
Grounding World Simulation Models in a Real-World Metropolis
Mar 16, 2026What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul. SWM anchors autoregressive video generation through retrieval-augmented conditioning on nearby street-view images. However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals. We address these challenges through cross-temporal pairing, a large-scale synthetic dataset enabling diverse camera trajectories, and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view images. We further introduce a Virtual Lookahead Sink to stabilize long-horizon generation by continuously re-grounding each chunk to a retrieved image at a future location. We evaluate SWM against recent video world models across three cities: Seoul, Busan, and Ann Arbor. SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
MuCo: Multi-turn Contrastive Learning for Multimodal Embedding Model
Feb 06, 2026Universal Multimodal embedding models built on Multimodal Large Language Models (MLLMs) have traditionally employed contrastive learning, which aligns representations of query-target pairs across different modalities. Yet, despite its empirical success, they are primarily built on a "single-turn" formulation where each query-target pair is treated as an independent data point. This paradigm leads to computational inefficiency when scaling, as it requires a separate forward pass for each pair and overlooks potential contextual relationships between multiple queries that can relate to the same context. In this work, we introduce Multi-Turn Contrastive Learning (MuCo), a dialogue-inspired framework that revisits this process. MuCo leverages the conversational nature of MLLMs to process multiple, related query-target pairs associated with a single image within a single forward pass. This allows us to extract a set of multiple query and target embeddings simultaneously, conditioned on a shared context representation, amplifying the effective batch size and overall training efficiency. Experiments exhibit MuCo with a newly curated 5M multimodal multi-turn dataset (M3T), which yields state-of-the-art retrieval performance on MMEB and M-BEIR benchmarks, while markedly enhancing both training efficiency and representation coherence across modalities. Code and M3T are available at https://github.com/naver-ai/muco
Language-only Efficient Training of Zero-shot Composed Image Retrieval
Dec 04, 2023Composed image retrieval (CIR) task takes a composed query of image and text, aiming to search relative images for both conditions. Conventional CIR approaches need a training dataset composed of triplets of query image, query text, and target image, which is very expensive to collect. Several recent works have worked on the zero-shot (ZS) CIR paradigm to tackle the issue without using pre-collected triplets. However, the existing ZS-CIR methods show limited backbone scalability and generalizability due to the lack of diversity of the input texts during training. We propose a novel CIR framework, only using language for its training. Our LinCIR (Language-only training for CIR) can be trained only with text datasets by a novel self-supervision named self-masking projection (SMP). We project the text latent embedding to the token embedding space and construct a new text by replacing the keyword tokens of the original text. Then, we let the new and original texts have the same latent embedding vector. With this simple strategy, LinCIR is surprisingly efficient and highly effective; LinCIR with CLIP ViT-G backbone is trained in 48 minutes and shows the best ZS-CIR performances on four different CIR benchmarks, CIRCO, GeneCIS, FashionIQ, and CIRR, even outperforming supervised method on FashionIQ. Code is available at https://github.com/navervision/lincir
CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
Mar 21, 2023This paper proposes a novel diffusion-based model, CompoDiff, for solving Composed Image Retrieval (CIR) with latent diffusion and presents a newly created dataset of 18 million reference images, conditions, and corresponding target image triplets to train the model. CompoDiff not only achieves a new zero-shot state-of-the-art on a CIR benchmark such as FashionIQ but also enables a more versatile CIR by accepting various conditions, such as negative text and image mask conditions, which are unavailable with existing CIR methods. In addition, the CompoDiff features are on the intact CLIP embedding space so that they can be directly used for all existing models exploiting the CLIP space. The code and dataset used for the training, and the pre-trained weights are available at https://github.com/navervision/CompoDiff
Group Generalized Mean Pooling for Vision Transformer
Dec 08, 2022



Vision Transformer (ViT) extracts the final representation from either class token or an average of all patch tokens, following the architecture of Transformer in Natural Language Processing (NLP) or Convolutional Neural Networks (CNNs) in computer vision. However, studies for the best way of aggregating the patch tokens are still limited to average pooling, while widely-used pooling strategies, such as max and GeM pooling, can be considered. Despite their effectiveness, the existing pooling strategies do not consider the architecture of ViT and the channel-wise difference in the activation maps, aggregating the crucial and trivial channels with the same importance. In this paper, we present Group Generalized Mean (GGeM) pooling as a simple yet powerful pooling strategy for ViT. GGeM divides the channels into groups and computes GeM pooling with a shared pooling parameter per group. As ViT groups the channels via a multi-head attention mechanism, grouping the channels by GGeM leads to lower head-wise dependence while amplifying important channels on the activation maps. Exploiting GGeM shows 0.1%p to 0.7%p performance boosts compared to the baselines and achieves state-of-the-art performance for ViT-Base and ViT-Large models in ImageNet-1K classification task. Moreover, GGeM outperforms the existing pooling strategies on image retrieval and multi-modal representation learning tasks, demonstrating the superiority of GGeM for a variety of tasks. GGeM is a simple algorithm in that only a few lines of code are necessary for implementation.
Granularity-aware Adaptation for Image Retrieval over Multiple Tasks
Oct 05, 2022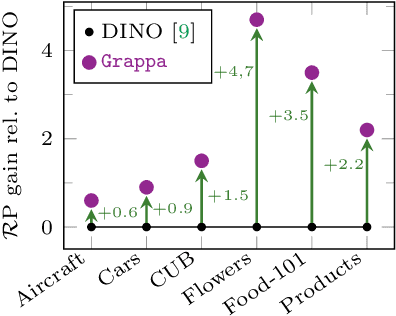
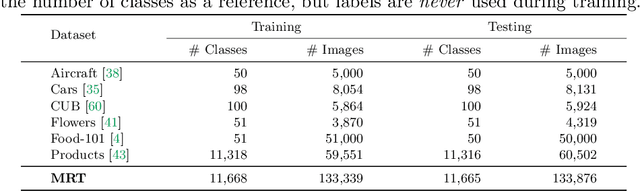
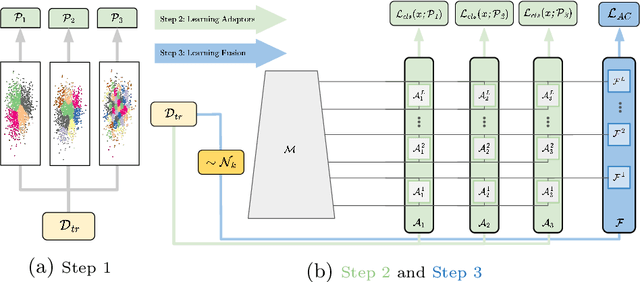
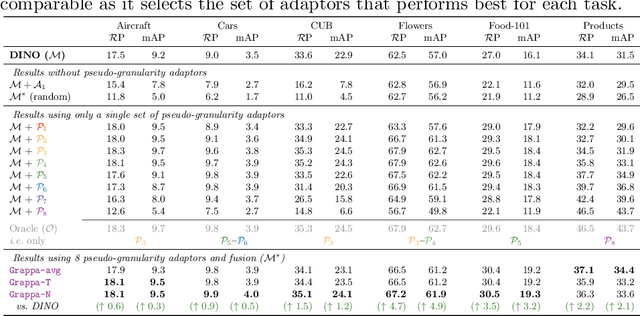
Strong image search models can be learned for a specific domain, ie. set of labels, provided that some labeled images of that domain are available. A practical visual search model, however, should be versatile enough to solve multiple retrieval tasks simultaneously, even if those cover very different specialized domains. Additionally, it should be able to benefit from even unlabeled images from these various retrieval tasks. This is the more practical scenario that we consider in this paper. We address it with the proposed Grappa, an approach that starts from a strong pretrained model, and adapts it to tackle multiple retrieval tasks concurrently, using only unlabeled images from the different task domains. We extend the pretrained model with multiple independently trained sets of adaptors that use pseudo-label sets of different sizes, effectively mimicking different pseudo-granularities. We reconcile all adaptor sets into a single unified model suited for all retrieval tasks by learning fusion layers that we guide by propagating pseudo-granularity attentions across neighbors in the feature space. Results on a benchmark composed of six heterogeneous retrieval tasks show that the unsupervised Grappa model improves the zero-shot performance of a state-of-the-art self-supervised learning model, and in some places reaches or improves over a task label-aware oracle that selects the most fitting pseudo-granularity per task.
Large-scale Bilingual Language-Image Contrastive Learning
Apr 15, 2022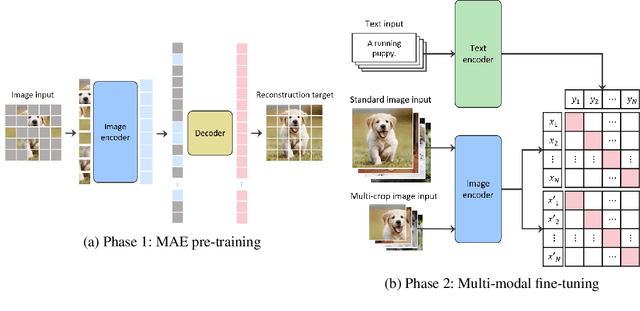
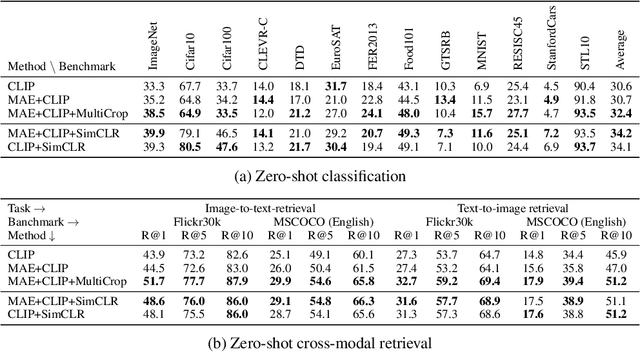
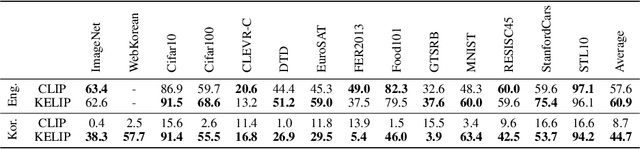
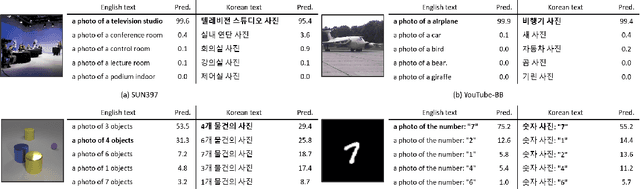
This paper is a technical report to share our experience and findings building a Korean and English bilingual multimodal model. While many of the multimodal datasets focus on English and multilingual multimodal research uses machine-translated texts, employing such machine-translated texts is limited to describing unique expressions, cultural information, and proper noun in languages other than English. In this work, we collect 1.1 billion image-text pairs (708 million Korean and 476 million English) and train a bilingual multimodal model named KELIP. We introduce simple yet effective training schemes, including MAE pre-training and multi-crop augmentation. Extensive experiments demonstrate that a model trained with such training schemes shows competitive performance in both languages. Moreover, we discuss multimodal-related research questions: 1) strong augmentation-based methods can distract the model from learning proper multimodal relations; 2) training multimodal model without cross-lingual relation can learn the relation via visual semantics; 3) our bilingual KELIP can capture cultural differences of visual semantics for the same meaning of words; 4) a large-scale multimodal model can be used for multimodal feature analogy. We hope that this work will provide helpful experience and findings for future research. We provide an open-source pre-trained KELIP.
Self-Distilled Hashing for Deep Image Retrieval
Dec 16, 2021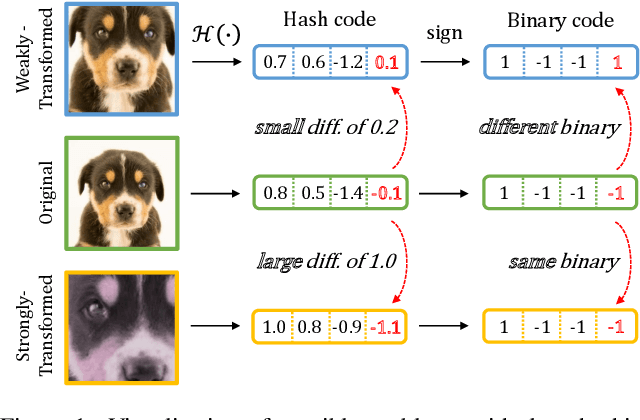
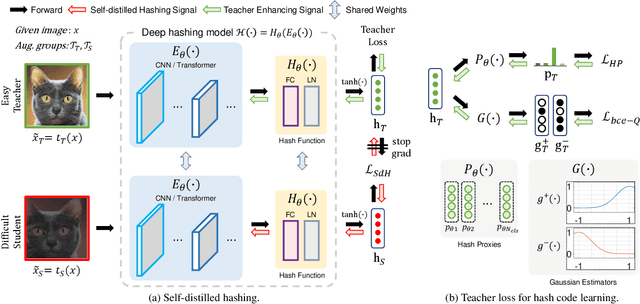
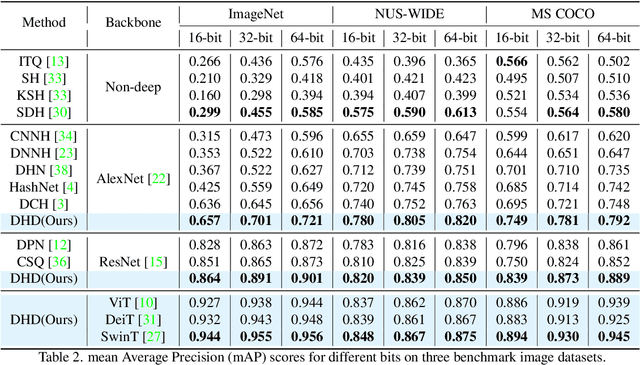
In hash-based image retrieval systems, the transformed input from the original usually generates different codes, deteriorating the retrieval accuracy. To mitigate this issue, data augmentation can be applied during training. However, even if the augmented samples of one content are similar in real space, the quantization can scatter them far away in Hamming space. This results in representation discrepancies that can impede training and degrade performance. In this work, we propose a novel self-distilled hashing scheme to minimize the discrepancy while exploiting the potential of augmented data. By transferring the hash knowledge of the weakly-transformed samples to the strong ones, we make the hash code insensitive to various transformations. We also introduce hash proxy-based similarity learning and binary cross entropy-based quantization loss to provide fine quality hash codes. Ultimately, we construct a deep hashing framework that generates discriminative hash codes. Extensive experiments on benchmarks verify that our self-distillation improves the existing deep hashing approaches, and our framework achieves state-of-the-art retrieval results. The code will be released soon.
Towards Real-time and Light-weight Line Segment Detection
Jun 01, 2021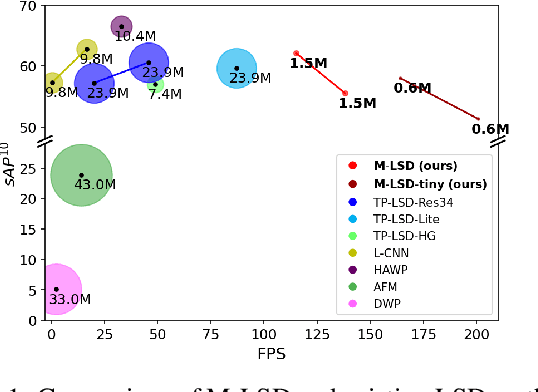
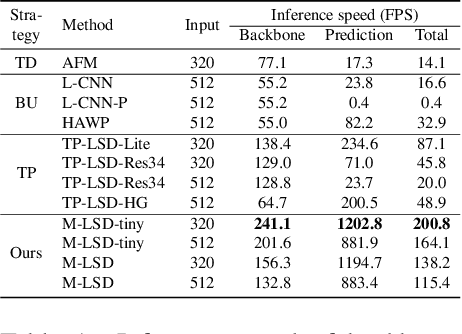
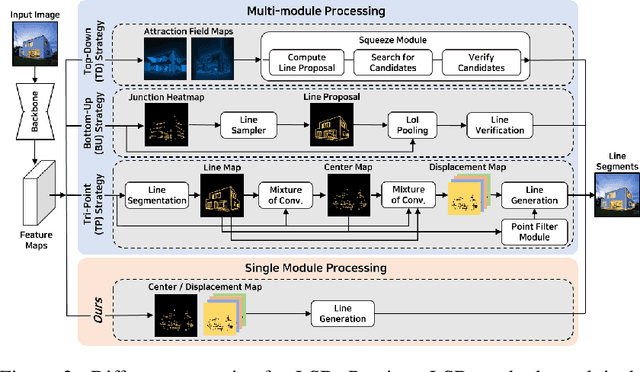
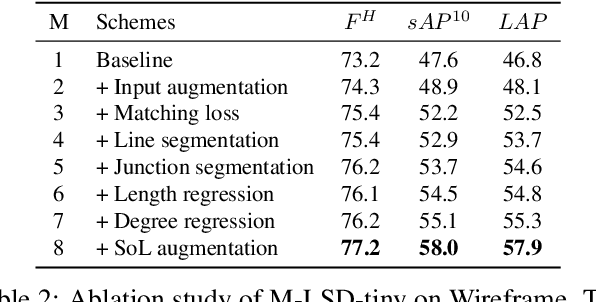
Previous deep learning-based line segment detection (LSD) suffer from the immense model size and high computational cost for line prediction. This constrains them from real-time inference on computationally restricted environments. In this paper, we propose a real-time and light-weight line segment detector for resource-constrained environments named Mobile LSD (M-LSD). We design an extremely efficient LSD architecture by minimizing the backbone network and removing the typical multi-module process for line prediction in previous methods. To maintain competitive performance with such a light-weight network, we present novel training schemes: Segments of Line segment (SoL) augmentation and geometric learning scheme. SoL augmentation splits a line segment into multiple subparts, which are used to provide auxiliary line data during the training process. Moreover, the geometric learning scheme allows a model to capture additional geometry cues from matching loss, junction and line segmentation, length and degree regression. Compared with TP-LSD-Lite, previously the best real-time LSD method, our model (M-LSD-tiny) achieves competitive performance with 2.5% of model size and an increase of 130.5% in inference speed on GPU when evaluated with Wireframe and YorkUrban datasets. Furthermore, our model runs at 56.8 FPS and 48.6 FPS on Android and iPhone mobile devices, respectively. To the best of our knowledge, this is the first real-time deep LSD method available on mobile devices.