 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Paper and Code
Apr 22, 2022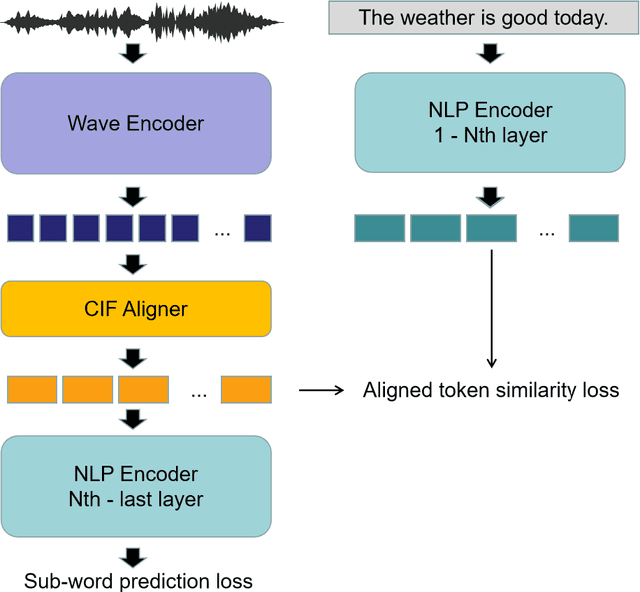


Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.