 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Learnable Variational Model for Joint Multimodal MRI Reconstruction and Synthesis
Apr 08, 2022
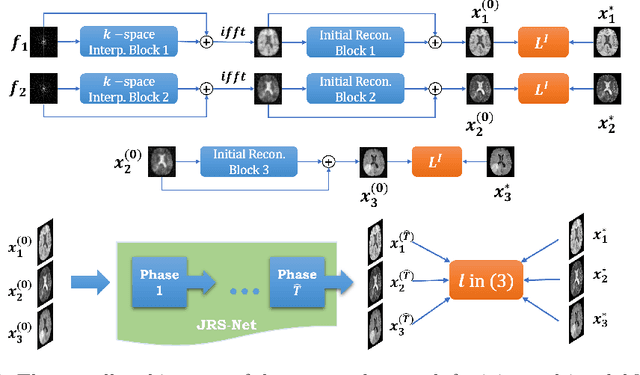
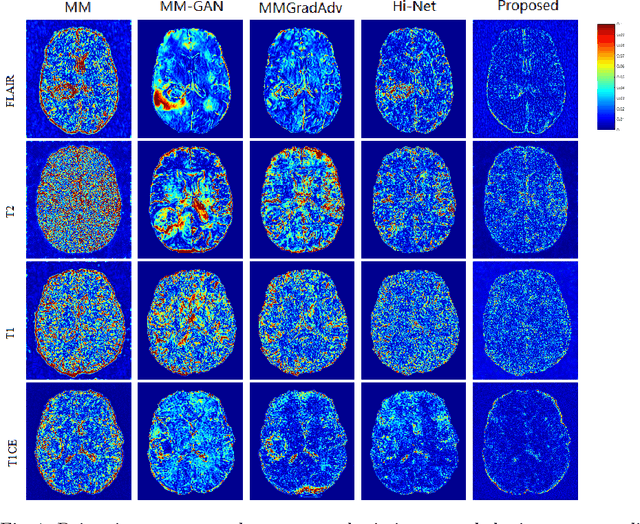

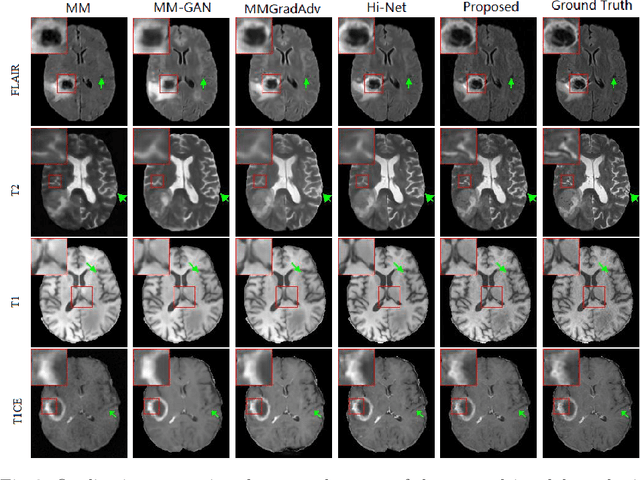
Generating multi-contrasts/modal MRI of the same anatomy enriches diagnostic information but is limited in practice due to excessive data acquisition time. In this paper, we propose a novel deep-learning model for joint reconstruction and synthesis of multi-modal MRI using incomplete k-space data of several source modalities as inputs. The output of our model includes reconstructed images of the source modalities and high-quality image synthesized in the target modality. Our proposed model is formulated as a variational problem that leverages several learnable modality-specific feature extractors and a multimodal synthesis module. We propose a learnable optimization algorithm to solve this model, which induces a multi-phase network whose parameters can be trained using multi-modal MRI data. Moreover, a bilevel-optimization framework is employed for robust parameter training. We demonstrate the effectiveness of our approach using extensive numerical experiments.
Graph-adaptive Rectified Linear Unit for Graph Neural Networks
Feb 13, 2022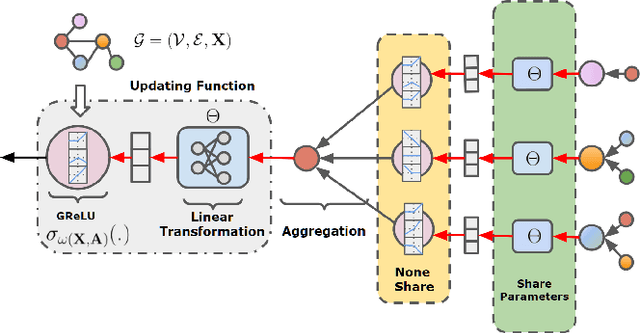

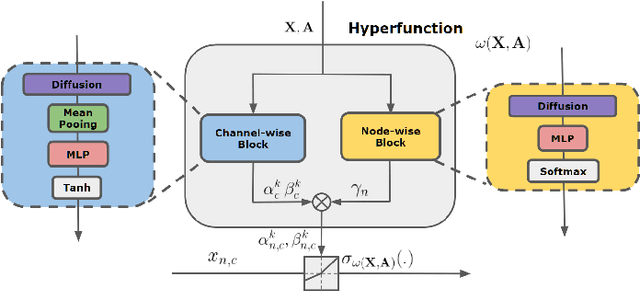
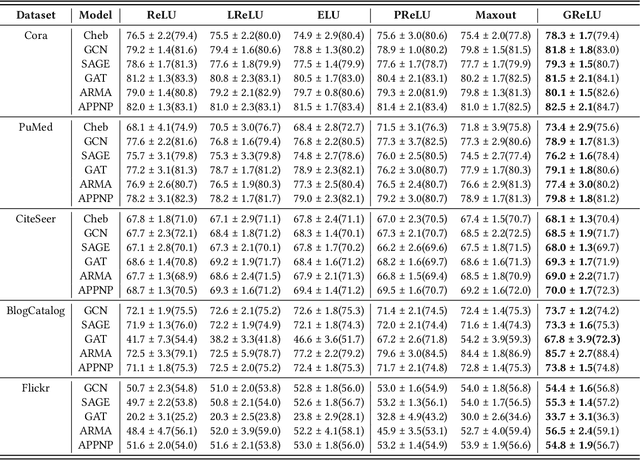
Graph Neural Networks (GNNs) have achieved remarkable success by extending traditional convolution to learning on non-Euclidean data. The key to the GNNs is adopting the neural message-passing paradigm with two stages: aggregation and update. The current design of GNNs considers the topology information in the aggregation stage. However, in the updating stage, all nodes share the same updating function. The identical updating function treats each node embedding as i.i.d. random variables and thus ignores the implicit relationships between neighborhoods, which limits the capacity of the GNNs. The updating function is usually implemented with a linear transformation followed by a non-linear activation function. To make the updating function topology-aware, we inject the topological information into the non-linear activation function and propose Graph-adaptive Rectified Linear Unit (GReLU), which is a new parametric activation function incorporating the neighborhood information in a novel and efficient way. The parameters of GReLU are obtained from a hyperfunction based on both node features and the corresponding adjacent matrix. To reduce the risk of overfitting and the computational cost, we decompose the hyperfunction as two independent components for nodes and features respectively. We conduct comprehensive experiments to show that our plug-and-play GReLU method is efficient and effective given different GNN backbones and various downstream tasks.
Meta Reinforcement Learning for Adaptive Control: An Offline Approach
Mar 17, 2022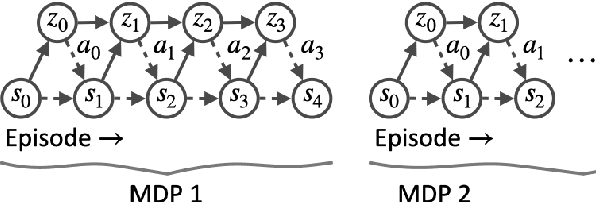
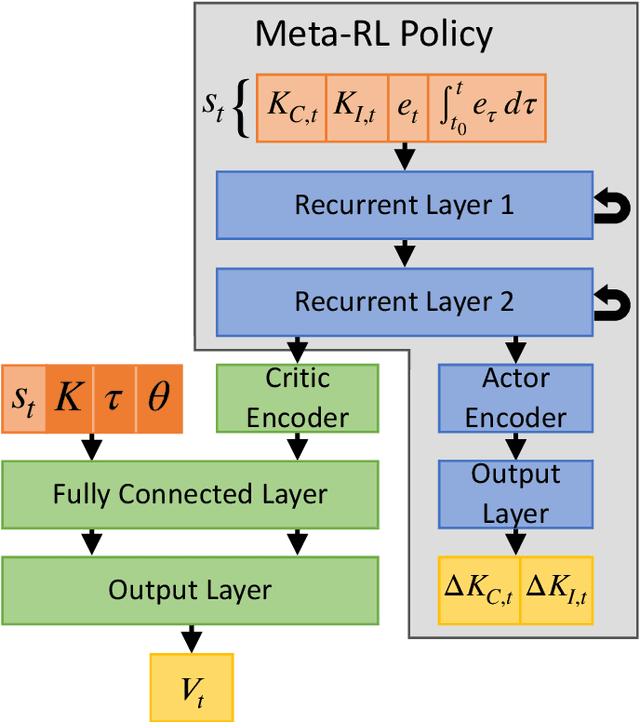
Meta-learning is a branch of machine learning which trains neural network models to synthesize a wide variety of data in order to rapidly solve new problems. In process control, many systems have similar and well-understood dynamics, which suggests it is feasible to create a generalizable controller through meta-learning. In this work, we formulate a meta reinforcement learning (meta-RL) control strategy that takes advantage of known, offline information for training, such as the system gain or time constant, yet efficiently controls novel systems in a completely model-free fashion. Our meta-RL agent has a recurrent structure that accumulates "context" for its current dynamics through a hidden state variable. This end-to-end architecture enables the agent to automatically adapt to changes in the process dynamics. Moreover, the same agent can be deployed on systems with previously unseen nonlinearities and timescales. In tests reported here, the meta-RL agent was trained entirely offline, yet produced excellent results in novel settings. A key design element is the ability to leverage model-based information offline during training, while maintaining a model-free policy structure for interacting with novel environments. To illustrate the approach, we take the actions proposed by the meta-RL agent to be changes to gains of a proportional-integral controller, resulting in a generalized, adaptive, closed-loop tuning strategy. Meta-learning is a promising approach for constructing sample-efficient intelligent controllers.
UniDU: Towards A Unified Generative Dialogue Understanding Framework
Apr 10, 2022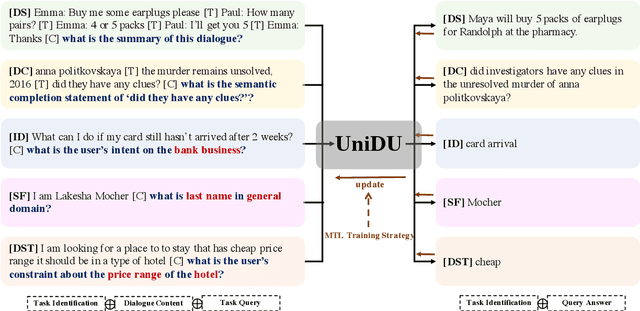
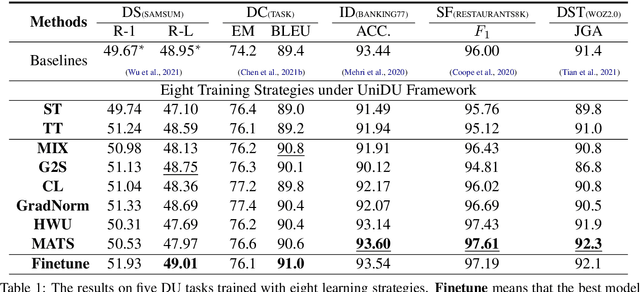

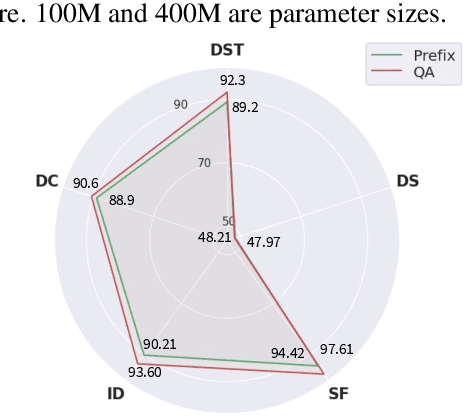
With the development of pre-trained language models, remarkable success has been witnessed in dialogue understanding (DU) direction. However, the current DU approaches just employ an individual model for each DU task, independently, without considering the shared knowledge across different DU tasks. In this paper, we investigate a unified generative dialogue understanding framework, namely UniDU, to achieve information exchange among DU tasks. Specifically, we reformulate the DU tasks into unified generative paradigm. In addition, to consider different training data for each task, we further introduce model-agnostic training strategy to optimize unified model in a balanced manner. We conduct the experiments on ten dialogue understanding datasets, which span five fundamental tasks: dialogue summary, dialogue completion, slot filling, intent detection and dialogue state tracking. The proposed UniDU framework outperforms task-specific well-designed methods on all 5 tasks. We further conduct comprehensive analysis experiments to study the effect factors. The experimental results also show that the proposed method obtains promising performance on unseen dialogue domain.
Graph Neural Diffusion Networks for Semi-supervised Learning
Jan 24, 2022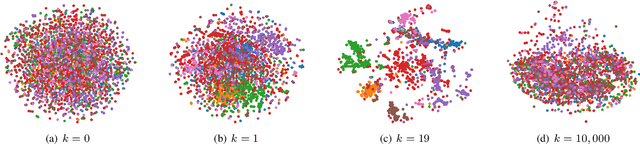
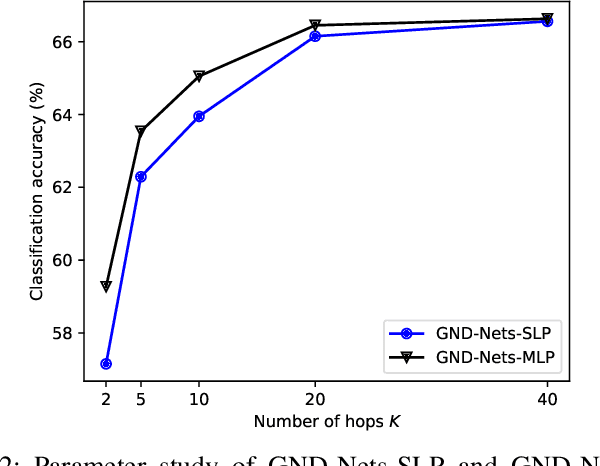
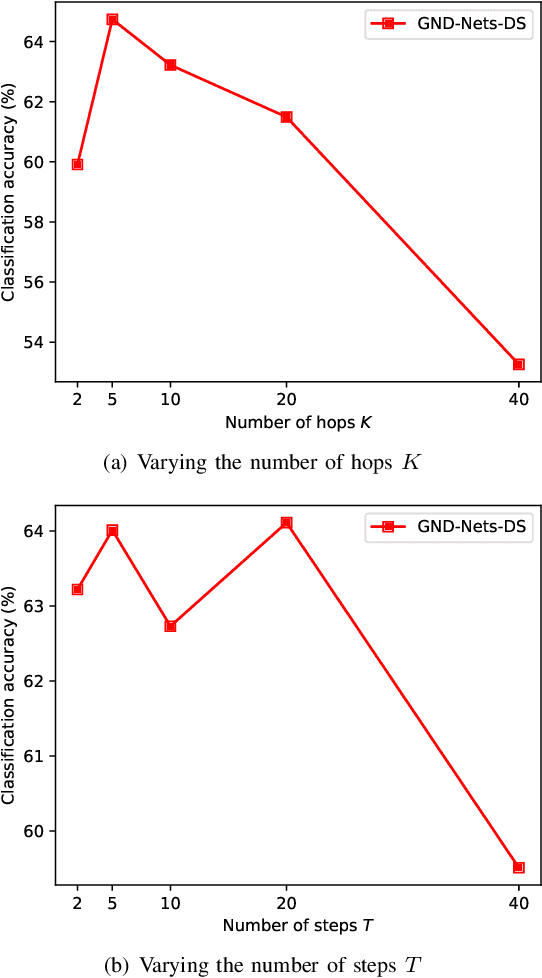
Graph Convolutional Networks (GCN) is a pioneering model for graph-based semi-supervised learning. However, GCN does not perform well on sparsely-labeled graphs. Its two-layer version cannot effectively propagate the label information to the whole graph structure (i.e., the under-smoothing problem) while its deep version over-smoothens and is hard to train (i.e., the over-smoothing problem). To solve these two issues, we propose a new graph neural network called GND-Nets (for Graph Neural Diffusion Networks) that exploits the local and global neighborhood information of a vertex in a single layer. Exploiting the shallow network mitigates the over-smoothing problem while exploiting the local and global neighborhood information mitigates the under-smoothing problem. The utilization of the local and global neighborhood information of a vertex is achieved by a new graph diffusion method called neural diffusions, which integrate neural networks into the conventional linear and nonlinear graph diffusions. The adoption of neural networks makes neural diffusions adaptable to different datasets. Extensive experiments on various sparsely-labeled graphs verify the effectiveness and efficiency of GND-Nets compared to state-of-the-art approaches.
Real-time Online Multi-Object Tracking in Compressed Domain
Apr 05, 2022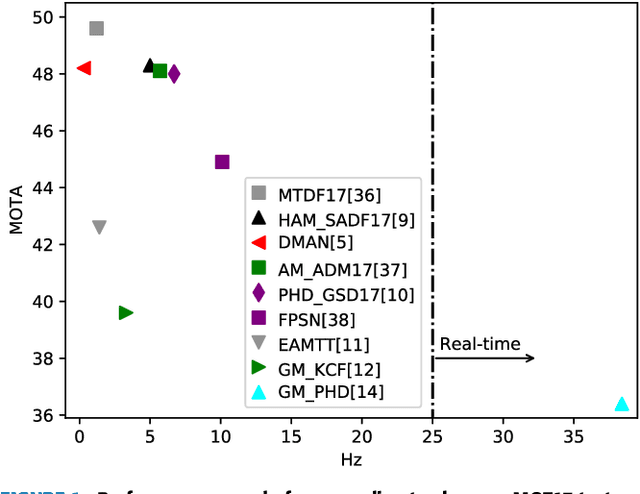

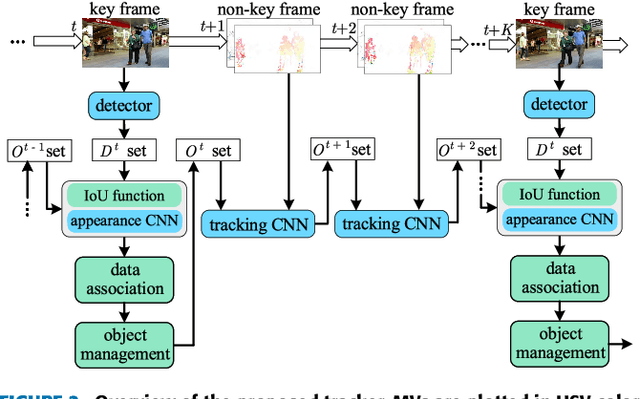
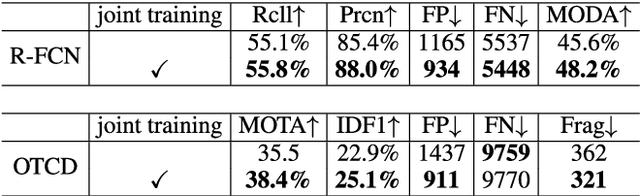
Recent online Multi-Object Tracking (MOT) methods have achieved desirable tracking performance. However, the tracking speed of most existing methods is rather slow. Inspired from the fact that the adjacent frames are highly relevant and redundant, we divide the frames into key and non-key frames respectively and track objects in the compressed domain. For the key frames, the RGB images are restored for detection and data association. To make data association more reliable, an appearance Convolutional Neural Network (CNN) which can be jointly trained with the detector is proposed. For the non-key frames, the objects are directly propagated by a tracking CNN based on the motion information provided in the compressed domain. Compared with the state-of-the-art online MOT methods,our tracker is about 6x faster while maintaining a comparable tracking performance.
ClothFormer:Taming Video Virtual Try-on in All Module
Apr 26, 2022
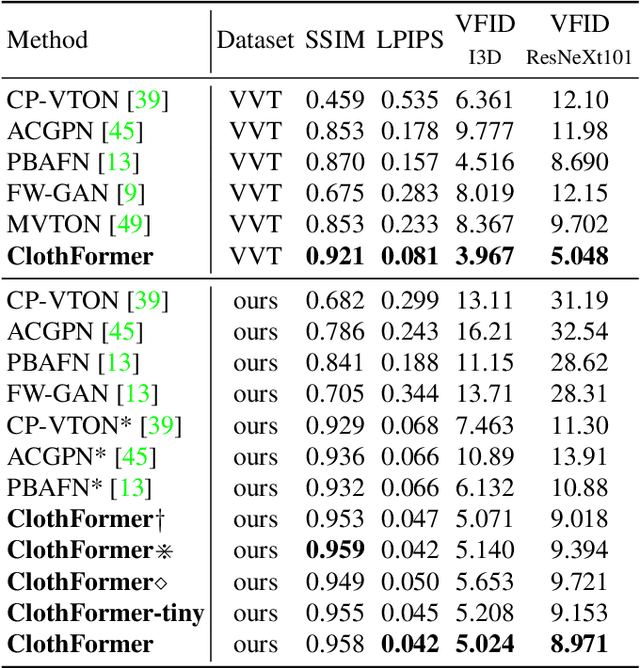
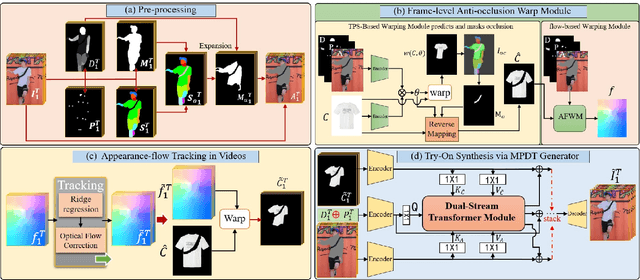
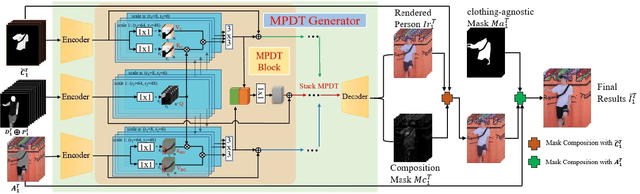
The task of video virtual try-on aims to fit the target clothes to a person in the video with spatio-temporal consistency. Despite tremendous progress of image virtual try-on, they lead to inconsistency between frames when applied to videos. Limited work also explored the task of video-based virtual try-on but failed to produce visually pleasing and temporally coherent results. Moreover, there are two other key challenges: 1) how to generate accurate warping when occlusions appear in the clothing region; 2) how to generate clothes and non-target body parts (e.g. arms, neck) in harmony with the complicated background; To address them, we propose a novel video virtual try-on framework, ClothFormer, which successfully synthesizes realistic, harmonious, and spatio-temporal consistent results in complicated environment. In particular, ClothFormer involves three major modules. First, a two-stage anti-occlusion warping module that predicts an accurate dense flow mapping between the body regions and the clothing regions. Second, an appearance-flow tracking module utilizes ridge regression and optical flow correction to smooth the dense flow sequence and generate a temporally smooth warped clothing sequence. Third, a dual-stream transformer extracts and fuses clothing textures, person features, and environment information to generate realistic try-on videos. Through rigorous experiments, we demonstrate that our method highly surpasses the baselines in terms of synthesized video quality both qualitatively and quantitatively.
A Sharp Memory-Regret Trade-Off for Multi-Pass Streaming Bandits
May 02, 2022The stochastic $K$-armed bandit problem has been studied extensively due to its applications in various domains ranging from online advertising to clinical trials. In practice however, the number of arms can be very large resulting in large memory requirements for simultaneously processing them. In this paper we consider a streaming setting where the arms are presented in a stream and the algorithm uses limited memory to process these arms. Here, the goal is not only to minimize regret, but also to do so in minimal memory. Previous algorithms for this problem operate in one of the two settings: they either use $\Omega(\log \log T)$ passes over the stream (Rathod, 2021; Chaudhuri and Kalyanakrishnan, 2020; Liau et al., 2018), or just a single pass (Maiti et al., 2021). In this paper we study the trade-off between memory and regret when $B$ passes over the stream are allowed, for any $B \geq 1$, and establish tight regret upper and lower bounds for any $B$-pass algorithm. Our results uncover a surprising *sharp transition phenomenon*: $O(1)$ memory is sufficient to achieve $\widetilde\Theta\Big(T^{\frac{1}{2} + \frac{1}{2^{B+2}-2}}\Big)$ regret in $B$ passes, and increasing the memory to any quantity that is $o(K)$ has almost no impact on further reducing this regret, unless we use $\Omega(K)$ memory. Our main technical contribution is our lower bound which requires the use of information-theoretic techniques as well as ideas from round elimination to show that the *residual problem* remains challenging over subsequent passes.
ORCAS-I: Queries Annotated with Intent using Weak Supervision
May 02, 2022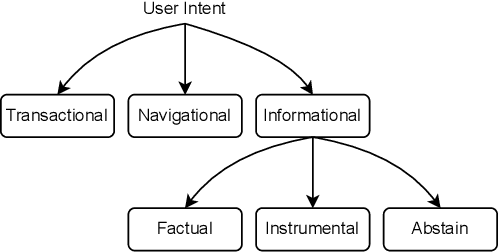
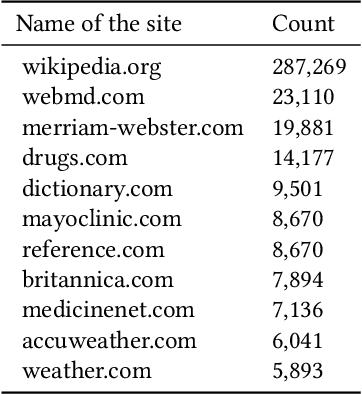

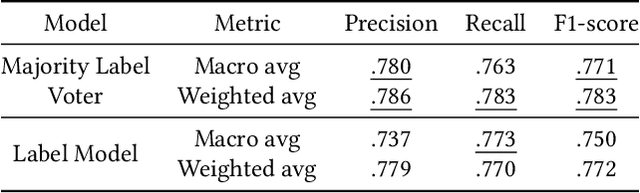
User intent classification is an important task in information retrieval. In this work, we introduce a revised taxonomy of user intent. We take the widely used differentiation between navigational, transactional and informational queries as a starting point, and identify three different sub-classes for the informational queries: instrumental, factual and abstain. The resulting classification of user queries is more fine-grained, reaches a high level of consistency between annotators, and can serve as the basis for an effective automatic classification process. The newly introduced categories help distinguish between types of queries that a retrieval system could act upon, for example by prioritizing different types of results in the ranking.We have used a weak supervision approach based on Snorkel to annotate the ORCAS dataset according to our new user intent taxonomy, utilising established heuristics and keywords to construct rules for the prediction of the intent category. We then present a series of experiments with a variety of machine learning models, using the labels from the weak supervision stage as training data, but find that the results produced by Snorkel are not outperformed by these competing approaches and can be considered state-of-the-art. The advantage of a rule-based approach like Snorkel's is its efficient deployment in an actual system, where intent classification would be executed for every query issued. The resource released with this paper is the ORCAS-I dataset: a labelled version of the ORCAS click-based dataset of Web queries, which provides 18 million connections to 10 million distinct queries.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022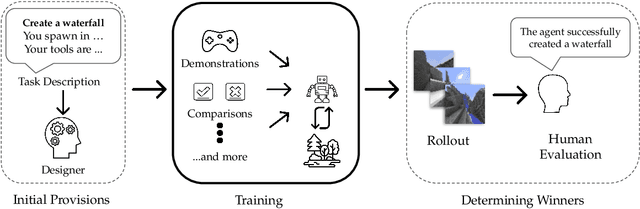
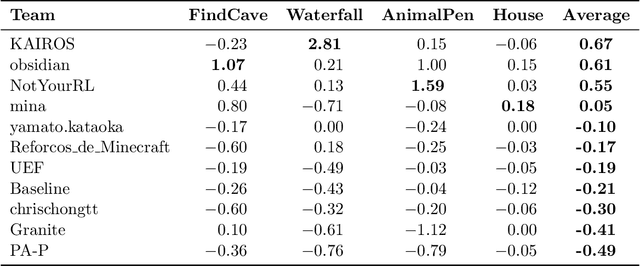
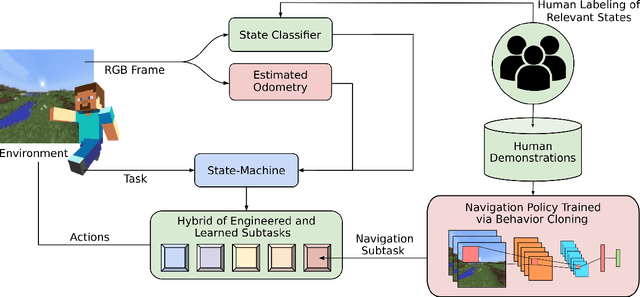
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.