 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Invasive Reconstruction of Intracranial EEG Across the Deep Temporal Lobe from Scalp EEG based on Conditional Normalizing Flow
Feb 27, 2026Although obtaining deep brain activity from non-invasive scalp electroencephalography (sEEG) is crucial for neuroscience and clinical diagnosis, directly generating high-fidelity intracranial electroencephalography (iEEG) signals remains a largely unexplored field, limiting our understanding of deep brain dynamics. Current research primarily focuses on traditional signal processing or source localization methods, which struggle to capture the complex waveforms and random characteristics of iEEG. To address this critical challenge, this paper introduces NeuroFlowNet, a novel cross-modal generative framework whose core contribution lies in the first-ever reconstruction of iEEG signals from the entire deep temporal lobe region using sEEG signals. NeuroFlowNet is built on Conditional Normalizing Flow (CNF), which directly models complex conditional probability distributions through reversible transformations, thereby explicitly capturing the randomness of brain signals and fundamentally avoiding the pattern collapse issues common in existing generative models. Additionally, the model integrates a multi-scale architecture and self-attention mechanisms to robustly capture fine-grained temporal details and long-range dependencies. Validation results on a publicly available synchronized sEEG-iEEG dataset demonstrate NeuroFlowNet's effectiveness in terms of temporal waveform fidelity, spectral feature reproduction, and functional connectivity restoration. This study establishes a more reliable and scalable new paradigm for non-invasive analysis of deep brain dynamics. The code of this study is available in https://github.com/hdy6438/NeuroFlowNet
Spec2VolCAMU-Net: A Spectrogram-to-Volume Model for EEG-to-fMRI Reconstruction based on Multi-directional Time-Frequency Convolutional Attention Encoder and Vision-Mamba U-Net
May 14, 2025High-resolution functional magnetic resonance imaging (fMRI) is essential for mapping human brain activity; however, it remains costly and logistically challenging. If comparable volumes could be generated directly from widely available scalp electroencephalography (EEG), advanced neuroimaging would become significantly more accessible. Existing EEG-to-fMRI generators rely on plain CNNs that fail to capture cross-channel time-frequency cues or on heavy transformer/GAN decoders that strain memory and stability. We propose Spec2VolCAMU-Net, a lightweight spectrogram-to-volume generator that confronts these issues via a Multi-directional Time-Frequency Convolutional Attention Encoder, stacking temporal, spectral and joint convolutions with self-attention, and a Vision-Mamba U-Net decoder whose linear-time state-space blocks enable efficient long-range spatial modelling. Trained end-to-end with a hybrid SSI-MSE loss, Spec2VolCAMU-Net achieves state-of-the-art fidelity on three public benchmarks, recording SSIMs of 0.693 on NODDI, 0.725 on Oddball and 0.788 on CN-EPFL, representing improvements of 14.5%, 14.9%, and 16.9% respectively over previous best SSIM scores. Furthermore, it achieves competitive PSNR scores, particularly excelling on the CN-EPFL dataset with a 4.6% improvement over the previous best PSNR, thus striking a better balance in reconstruction quality. The proposed model is lightweight and efficient, making it suitable for real-time applications in clinical and research settings. The code is available at https://github.com/hdy6438/Spec2VolCAMU-Net.
CNNSum: Exploring Long-Context Summarization with Large Language Models in Chinese Novels
Dec 11, 2024



Large Language Models (LLMs) have been well-researched in many long-context tasks. However, due to high annotation costs, high-quality long-context summary datasets for training or evaluation are scarce, limiting further research. In this work, we introduce CNNSum, a new multi-scale Chinese long-context novel summarization benchmark, including four subsets, length covering 16k to 128k, 695 samples in total, the annotations are human-driven. We evaluate commercial and open-source models on CNNSum and conduct a detailed analysis. Based on the observations, we further conduct fine-tuning exploration with short-context summary data. In our study: (1) GPT-4o underperformed, due to excessive subjective commentary. (2) Currently, long-context summarization mainly relies on memory ability, small LLMs with stable longer context lengths are the most cost-effective. Using long data concatenated from short-context summaries makes a significant improvement. (3) Prompt templates may cause a large performance gap but can be mitigated through fine-tuning. (4) Fine-tuned Chat or Instruction versions may harm the Base model and further fine-tuning cannot bridge performance gap. (5) while models with RoPE base scaling exhibit strong extrapolation potential, their performance may vary significantly when combined with other interpolation methods and need careful selection. (6) CNNSum provides more reliable and insightful evaluation results than other benchmarks. We release CNNSum to advance research in this field (https://github.com/CxsGhost/CNNSum).
CNNSum: Exploring Long-Conext Summarization with Large Language Models in Chinese Novels
Dec 05, 2024Large Language Models (LLMs) have been well-researched in many long-context tasks. However, due to high annotation costs, high-quality long-context summary datasets for training or evaluation are scarce, limiting further research. In this work, we introduce CNNSum, a new multi-scale Chinese long-context novel summarization benchmark, including four subsets, length covering 16k\textasciitilde128k, 695 samples in total, the annotations are human-driven. We evaluate commercial and open-source models on CNNSum and conduct a detailed analysis. Based on the observations, we further conduct fine-tuning exploration with short-context summary data. In our study: (1) GPT-4o underperformed, due to excessive subjective commentary. (2) Currently, long-context summarization mainly relies on memory ability, small LLMs with stable longer context lengths are the most cost-effective. Using long data concatenated from short-context summaries makes a significant improvement. (3) Prompt templates may cause a large performance gap but can be mitigated through fine-tuning. (4) Fine-tuned Chat or Instruction versions may harm the Base model and further fine-tuning cannot bridge performance gap. (5) while models with RoPE base scaling exhibit strong extrapolation potential, their performance may vary significantly when combined with other interpolation methods and need careful selection. (6) CNNSum provides more reliable and insightful evaluation results than other benchmarks. We release CNNSum to advance research in this field.
LIFBench: Evaluating the Instruction Following Performance and Stability of Large Language Models in Long-Context Scenarios
Nov 11, 2024



As Large Language Models (LLMs) continue to advance in natural language processing (NLP), their ability to stably follow instructions in long-context inputs has become crucial for real-world applications. While existing benchmarks assess various LLM capabilities, they rarely focus on instruction-following in long-context scenarios or stability on different inputs. In response, we introduce the Long-context Instruction-Following Benchmark (LIFBench), a scalable dataset designed to evaluate LLMs' instruction-following capabilities and stability across long contexts. LIFBench comprises three long-context scenarios and eleven diverse tasks, supported by 2,766 instructions generated through an automated expansion method across three dimensions: length, expression, and variables. For evaluation, we propose LIFEval, a rubric-based assessment framework that provides precise, automated scoring of complex LLM responses without relying on LLM-assisted evaluations or human judgments. This approach facilitates a comprehensive analysis of model performance and stability across various perspectives. We conduct extensive experiments on 20 notable LLMs across six length intervals, analyzing their instruction-following capabilities and stability. Our work contributes LIFBench and LIFEval as robust tools for assessing LLM performance in complex, long-context settings, providing insights that can inform future LLM development.
Enhancing SPARQL Generation by Triplet-order-sensitive Pre-training
Oct 08, 2024



Semantic parsing that translates natural language queries to SPARQL is of great importance for Knowledge Graph Question Answering (KGQA) systems. Although pre-trained language models like T5 have achieved significant success in the Text-to-SPARQL task, their generated outputs still exhibit notable errors specific to the SPARQL language, such as triplet flips. To address this challenge and further improve the performance, we propose an additional pre-training stage with a new objective, Triplet Order Correction (TOC), along with the commonly used Masked Language Modeling (MLM), to collectively enhance the model's sensitivity to triplet order and SPARQL syntax. Our method achieves state-of-the-art performances on three widely-used benchmarks.
Inherent limitations of LLMs regarding spatial information
Dec 05, 2023



Despite the significant advancements in natural language processing capabilities demonstrated by large language models such as ChatGPT, their proficiency in comprehending and processing spatial information, especially within the domains of 2D and 3D route planning, remains notably underdeveloped. This paper investigates the inherent limitations of ChatGPT and similar models in spatial reasoning and navigation-related tasks, an area critical for applications ranging from autonomous vehicle guidance to assistive technologies for the visually impaired. In this paper, we introduce a novel evaluation framework complemented by a baseline dataset, meticulously crafted for this study. This dataset is structured around three key tasks: plotting spatial points, planning routes in two-dimensional (2D) spaces, and devising pathways in three-dimensional (3D) environments. We specifically developed this dataset to assess the spatial reasoning abilities of ChatGPT. Our evaluation reveals key insights into the model's capabilities and limitations in spatial understanding.
ClothFormer:Taming Video Virtual Try-on in All Module
Apr 26, 2022
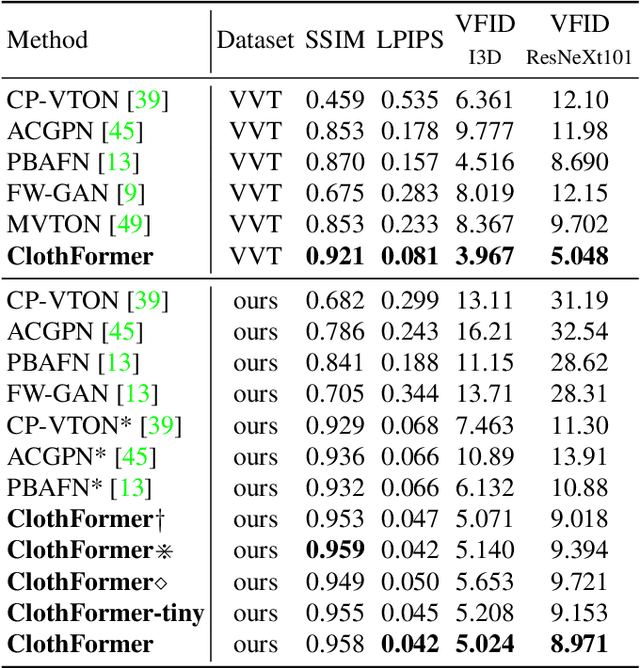
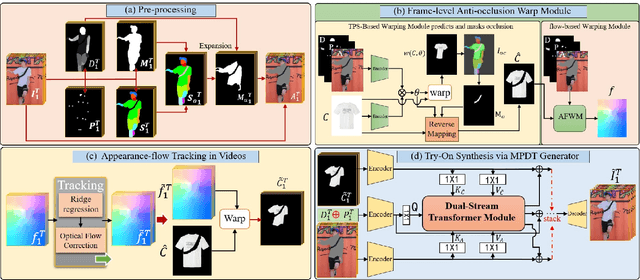
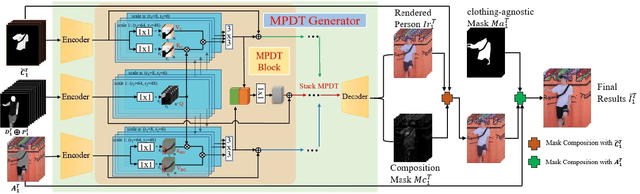
The task of video virtual try-on aims to fit the target clothes to a person in the video with spatio-temporal consistency. Despite tremendous progress of image virtual try-on, they lead to inconsistency between frames when applied to videos. Limited work also explored the task of video-based virtual try-on but failed to produce visually pleasing and temporally coherent results. Moreover, there are two other key challenges: 1) how to generate accurate warping when occlusions appear in the clothing region; 2) how to generate clothes and non-target body parts (e.g. arms, neck) in harmony with the complicated background; To address them, we propose a novel video virtual try-on framework, ClothFormer, which successfully synthesizes realistic, harmonious, and spatio-temporal consistent results in complicated environment. In particular, ClothFormer involves three major modules. First, a two-stage anti-occlusion warping module that predicts an accurate dense flow mapping between the body regions and the clothing regions. Second, an appearance-flow tracking module utilizes ridge regression and optical flow correction to smooth the dense flow sequence and generate a temporally smooth warped clothing sequence. Third, a dual-stream transformer extracts and fuses clothing textures, person features, and environment information to generate realistic try-on videos. Through rigorous experiments, we demonstrate that our method highly surpasses the baselines in terms of synthesized video quality both qualitatively and quantitatively.
Unknown Identity Rejection Loss: Utilizing Unlabeled Data for Face Recognition
Oct 24, 2019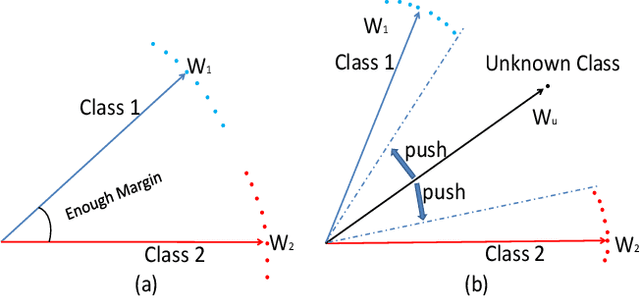
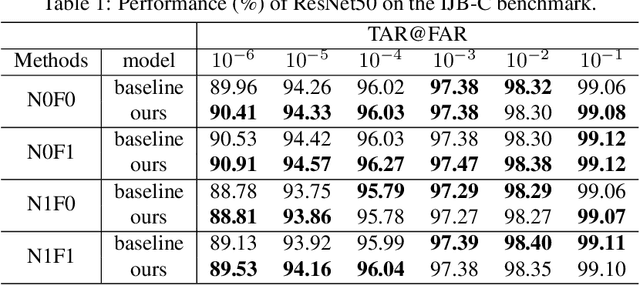
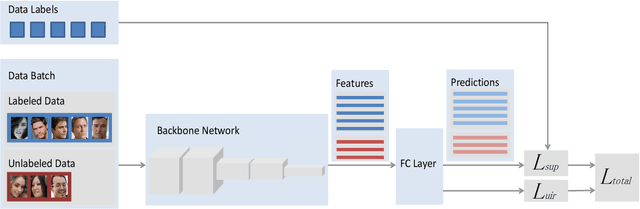
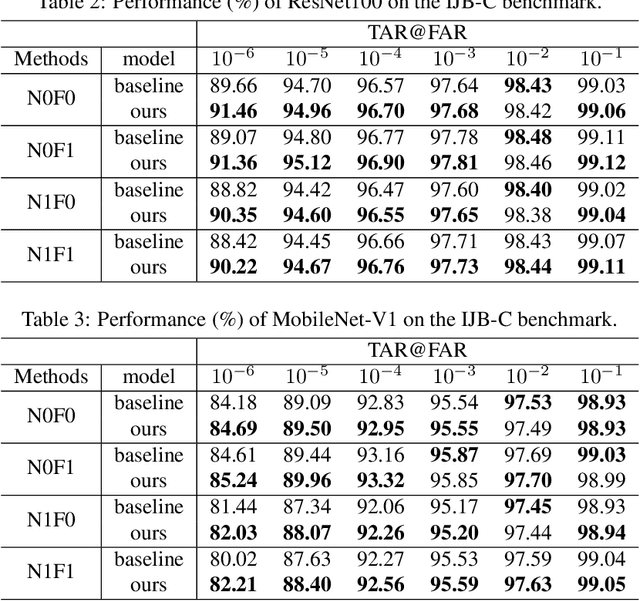
Face recognition has advanced considerably with the availability of large-scale labeled datasets. However, how to further improve the performance with the easily accessible unlabeled dataset remains a challenge. In this paper, we propose the novel Unknown Identity Rejection (UIR) loss to utilize the unlabeled data. We categorize identities in unconstrained environment into the known set and the unknown set. The former corresponds to the identities that appear in the labeled training dataset while the latter is its complementary set. Besides training the model to accurately classify the known identities, we also force the model to reject unknown identities provided by the unlabeled dataset via our proposed UIR loss. In order to 'reject' faces of unknown identities, centers of the known identities are forced to keep enough margin from centers of unknown identities which are assumed to be approximated by the features of their samples. By this means, the discriminativeness of the face representations can be enhanced. Experimental results demonstrate that our approach can provide obvious performance improvement by utilizing the unlabeled data.
iQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018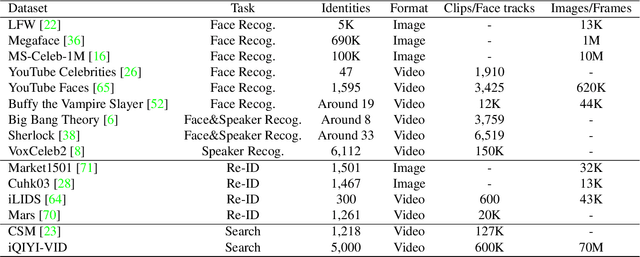

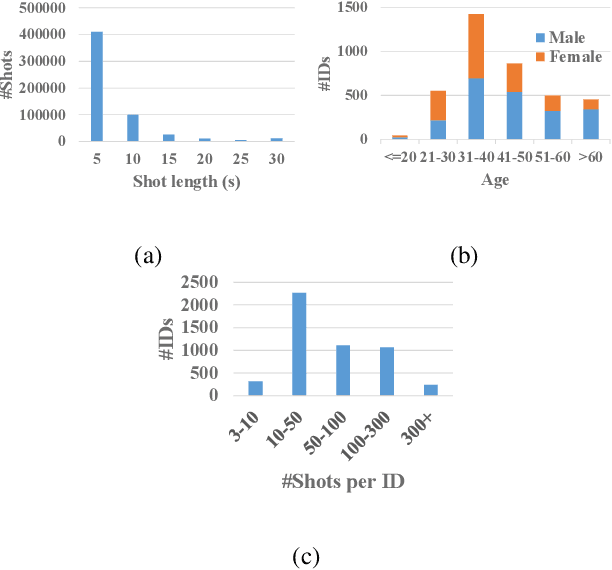
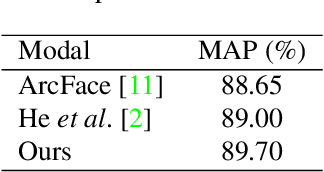
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.