 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathematical Foundations of Deep Learning
Mar 19, 2026This draft book offers a comprehensive and rigorous treatment of the mathematical principles underlying modern deep learning. The book spans core theoretical topics, from the approximation capabilities of deep neural networks, the theory and algorithms of optimal control and reinforcement learning integrated with deep learning techniques, to contemporary generative models that drive today's advances in artificial intelligence.
Transferable Optimization Network for Cross-Domain Image Reconstruction
Mar 08, 2026We develop a novel transfer learning framework to tackle the challenge of limited training data in image reconstruction problems. The proposed framework consists of two training steps, both of which are formed as bi-level optimizations. In the first step, we train a powerful universal feature-extractor that is capable of learning important knowledge from large, heterogeneous data sets in various domains. In the second step, we train a task-specific domain-adapter for a new target domain or task with only a limited amount of data available for training. Then the composition of the adapter and the universal feature-extractor effectively explores feature which serve as an important component of image regularization for the new domains, and this leads to high-quality reconstruction despite the data limitation issue. We apply this framework to reconstruct under-sampled MR images with limited data by using a collection of diverse data samples from different domains, such as images of other anatomies, measurements of various sampling ratios, and even different image modalities, including natural images. Experimental results demonstrate a promising transfer learning capability of the proposed method.
LAMA-Net: A Convergent Network Architecture for Dual-Domain Reconstruction
Jul 30, 2025We propose a learnable variational model that learns the features and leverages complementary information from both image and measurement domains for image reconstruction. In particular, we introduce a learned alternating minimization algorithm (LAMA) from our prior work, which tackles two-block nonconvex and nonsmooth optimization problems by incorporating a residual learning architecture in a proximal alternating framework. In this work, our goal is to provide a complete and rigorous convergence proof of LAMA and show that all accumulation points of a specified subsequence of LAMA must be Clarke stationary points of the problem. LAMA directly yields a highly interpretable neural network architecture called LAMA-Net. Notably, in addition to the results shown in our prior work, we demonstrate that the convergence property of LAMA yields outstanding stability and robustness of LAMA-Net in this work. We also show that the performance of LAMA-Net can be further improved by integrating a properly designed network that generates suitable initials, which we call iLAMA-Net. To evaluate LAMA-Net/iLAMA-Net, we conduct several experiments and compare them with several state-of-the-art methods on popular benchmark datasets for Sparse-View Computed Tomography.
* arXiv admin note: substantial text overlap with arXiv:2410.21111
Hamiltonian Theory and Computation of Optimal Probability Density Control in High Dimensions
May 23, 2025We develop a general theoretical framework for optimal probability density control and propose a numerical algorithm that is scalable to solve the control problem in high dimensions. Specifically, we establish the Pontryagin Maximum Principle (PMP) for optimal density control and construct the Hamilton-Jacobi-Bellman (HJB) equation of the value functional through rigorous derivations without any concept from Wasserstein theory. To solve the density control problem numerically, we propose to use reduced-order models, such as deep neural networks (DNNs), to parameterize the control vector-field and the adjoint function, which allows us to tackle problems defined on high-dimensional state spaces. We also prove several convergence properties of the proposed algorithm. Numerical results demonstrate promising performances of our algorithm on a variety of density control problems with obstacles and nonlinear interaction challenges in high dimensions.
LAMA: Stable Dual-Domain Deep Reconstruction For Sparse-View CT
Oct 28, 2024



Inverse problems arise in many applications, especially tomographic imaging. We develop a Learned Alternating Minimization Algorithm (LAMA) to solve such problems via two-block optimization by synergizing data-driven and classical techniques with proven convergence. LAMA is naturally induced by a variational model with learnable regularizers in both data and image domains, parameterized as composite functions of neural networks trained with domain-specific data. We allow these regularizers to be nonconvex and nonsmooth to extract features from data effectively. We minimize the overall objective function using Nesterov's smoothing technique and residual learning architecture. It is demonstrated that LAMA reduces network complexity, improves memory efficiency, and enhances reconstruction accuracy, stability, and interpretability. Extensive experiments show that LAMA significantly outperforms state-of-the-art methods on popular benchmark datasets for Computed Tomography.
Approximation of Solution Operators for High-dimensional PDEs
Jan 18, 2024We propose a finite-dimensional control-based method to approximate solution operators for evolutional partial differential equations (PDEs), particularly in high-dimensions. By employing a general reduced-order model, such as a deep neural network, we connect the evolution of the model parameters with trajectories in a corresponding function space. Using the computational technique of neural ordinary differential equation, we learn the control over the parameter space such that from any initial starting point, the controlled trajectories closely approximate the solutions to the PDE. Approximation accuracy is justified for a general class of second-order nonlinear PDEs. Numerical results are presented for several high-dimensional PDEs, including real-world applications to solving Hamilton-Jacobi-Bellman equations. These are demonstrated to show the accuracy and efficiency of the proposed method.
Approximating High-Dimensional Minimal Surfaces with Physics-Informed Neural Networks
Sep 07, 2023



In this paper, we compute numerical approximations of the minimal surfaces, an essential type of Partial Differential Equation (PDE), in higher dimensions. Classical methods cannot handle it in this case because of the Curse of Dimensionality, where the computational cost of these methods increases exponentially fast in response to higher problem dimensions, far beyond the computing capacity of any modern supercomputers. Only in the past few years have machine learning researchers been able to mitigate this problem. The solution method chosen here is a model known as a Physics-Informed Neural Network (PINN) which trains a deep neural network (DNN) to solve the minimal surface PDE. It can be scaled up into higher dimensions and trained relatively quickly even on a laptop with no GPU. Due to the inability to view the high-dimension output, our data is presented as snippets of a higher-dimension shape with enough fixed axes so that it is viewable with 3-D graphs. Not only will the functionality of this method be tested, but we will also explore potential limitations in the method's performance.
Learned Alternating Minimization Algorithm for Dual-domain Sparse-View CT Reconstruction
Jun 06, 2023



We propose a novel Learned Alternating Minimization Algorithm (LAMA) for dual-domain sparse-view CT image reconstruction. LAMA is naturally induced by a variational model for CT reconstruction with learnable nonsmooth nonconvex regularizers, which are parameterized as composite functions of deep networks in both image and sinogram domains. To minimize the objective of the model, we incorporate the smoothing technique and residual learning architecture into the design of LAMA. We show that LAMA substantially reduces network complexity, improves memory efficiency and reconstruction accuracy, and is provably convergent for reliable reconstructions. Extensive numerical experiments demonstrate that LAMA outperforms existing methods by a wide margin on multiple benchmark CT datasets.
Neural Control of Parametric Solutions for High-dimensional Evolution PDEs
Jan 31, 2023



We develop a novel computational framework to approximate solution operators of evolution partial differential equations (PDEs). By employing a general nonlinear reduced-order model, such as a deep neural network, to approximate the solution of a given PDE, we realize that the evolution of the model parameter is a control problem in the parameter space. Based on this observation, we propose to approximate the solution operator of the PDE by learning the control vector field in the parameter space. From any initial value, this control field can steer the parameter to generate a trajectory such that the corresponding reduced-order model solves the PDE. This allows for substantially reduced computational cost to solve the evolution PDE with arbitrary initial conditions. We also develop comprehensive error analysis for the proposed method when solving a large class of semilinear parabolic PDEs. Numerical experiments on different high-dimensional evolution PDEs with various initial conditions demonstrate the promising results of the proposed method.
A Learnable Variational Model for Joint Multimodal MRI Reconstruction and Synthesis
Apr 08, 2022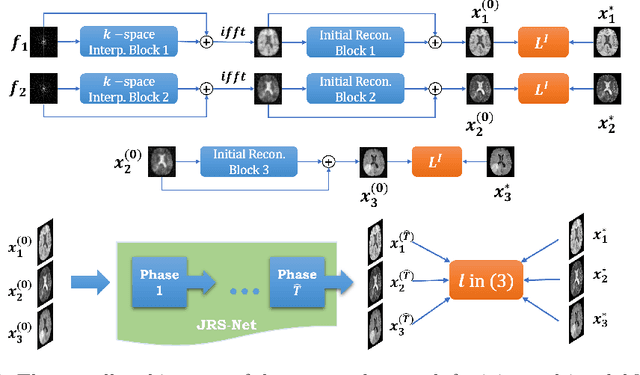
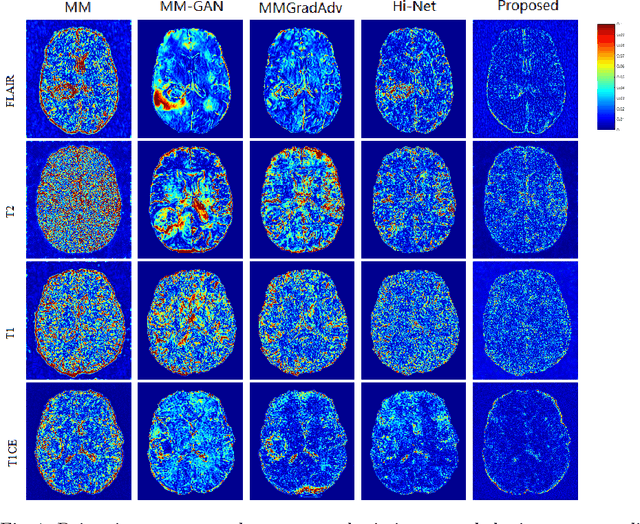

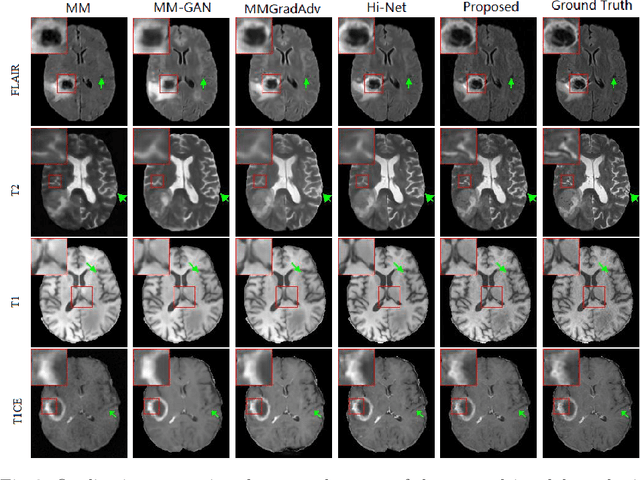
Generating multi-contrasts/modal MRI of the same anatomy enriches diagnostic information but is limited in practice due to excessive data acquisition time. In this paper, we propose a novel deep-learning model for joint reconstruction and synthesis of multi-modal MRI using incomplete k-space data of several source modalities as inputs. The output of our model includes reconstructed images of the source modalities and high-quality image synthesized in the target modality. Our proposed model is formulated as a variational problem that leverages several learnable modality-specific feature extractors and a multimodal synthesis module. We propose a learnable optimization algorithm to solve this model, which induces a multi-phase network whose parameters can be trained using multi-modal MRI data. Moreover, a bilevel-optimization framework is employed for robust parameter training. We demonstrate the effectiveness of our approach using extensive numerical experiments.