 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMil-SCORE: Benchmarking Long-Context Geospatial Reasoning and Planning in Large Language Models
Jan 29, 2026As large language models (LLMs) are applied to increasingly longer and more complex tasks, there is a growing need for realistic long-context benchmarks that require selective reading and integration of heterogeneous, multi-modal information sources. This need is especially acute for geospatial planning problems, such as those found in planning for large-scale military operations, which demand fast and accurate reasoning over maps, orders, intelligence reports, and other distributed data. To address this gap, we present MilSCORE (Military Scenario Contextual Reasoning), to our knowledge the first scenario-level dataset of expert-authored, multi-hop questions grounded in a complex, simulated military planning scenario used for training. MilSCORE is designed to evaluate high-stakes decision-making and planning, probing LLMs' ability to combine tactical and spatial reasoning across multiple sources and to reason over long-horizon, geospatially rich context. The benchmark includes a diverse set of question types across seven categories targeting both factual recall and multi-step reasoning about constraints, strategy, and spatial analysis. We provide an evaluation protocol and report baseline results for a range of contemporary vision-language models. Our findings highlight substantial headroom on MilSCORE, indicating that current systems struggle with realistic, scenario-level long-context planning, and positioning MilSCORE as a challenging testbed for future work.
Atari-GPT: Investigating the Capabilities of Multimodal Large Language Models as Low-Level Policies for Atari Games
Aug 28, 2024Recent advancements in large language models (LLMs) have expanded their capabilities beyond traditional text-based tasks to multimodal domains, integrating visual, auditory, and textual data. While multimodal LLMs have been extensively explored for high-level planning in domains like robotics and games, their potential as low-level controllers remains largely untapped. This paper explores the application of multimodal LLMs as low-level controllers in the domain of Atari video games, introducing Atari game performance as a new benchmark for evaluating the ability of multimodal LLMs to perform low-level control tasks. Unlike traditional reinforcement learning (RL) and imitation learning (IL) methods that require extensive computational resources as well as reward function specification, these LLMs utilize pre-existing multimodal knowledge to directly engage with game environments. Our study assesses multiple multimodal LLMs performance against traditional RL agents, human players, and random agents, focusing on their ability to understand and interact with complex visual scenes and formulate strategic responses. Additionally, we examine the impact of In-Context Learning (ICL) by incorporating human-demonstrated game-play trajectories to enhance the models contextual understanding. Through this investigation, we aim to determine the extent to which multimodal LLMs can leverage their extensive training to effectively function as low-level controllers, thereby redefining potential applications in dynamic and visually complex environments. Additional results and videos are available at our project webpage: https://sites.google.com/view/atari-gpt/.
Re-Envisioning Command and Control
Feb 09, 2024Future warfare will require Command and Control (C2) decision-making to occur in more complex, fast-paced, ill-structured, and demanding conditions. C2 will be further complicated by operational challenges such as Denied, Degraded, Intermittent, and Limited (DDIL) communications and the need to account for many data streams, potentially across multiple domains of operation. Yet, current C2 practices -- which stem from the industrial era rather than the emerging intelligence era -- are linear and time-consuming. Critically, these approaches may fail to maintain overmatch against adversaries on the future battlefield. To address these challenges, we propose a vision for future C2 based on robust partnerships between humans and artificial intelligence (AI) systems. This future vision is encapsulated in three operational impacts: streamlining the C2 operations process, maintaining unity of effort, and developing adaptive collective knowledge systems. This paper illustrates the envisaged future C2 capabilities, discusses the assumptions that shaped them, and describes how the proposed developments could transform C2 in future warfare.
Scalable Interactive Machine Learning for Future Command and Control
Feb 09, 2024
Future warfare will require Command and Control (C2) personnel to make decisions at shrinking timescales in complex and potentially ill-defined situations. Given the need for robust decision-making processes and decision-support tools, integration of artificial and human intelligence holds the potential to revolutionize the C2 operations process to ensure adaptability and efficiency in rapidly changing operational environments. We propose to leverage recent promising breakthroughs in interactive machine learning, in which humans can cooperate with machine learning algorithms to guide machine learning algorithm behavior. This paper identifies several gaps in state-of-the-art science and technology that future work should address to extend these approaches to function in complex C2 contexts. In particular, we describe three research focus areas that together, aim to enable scalable interactive machine learning (SIML): 1) developing human-AI interaction algorithms to enable planning in complex, dynamic situations; 2) fostering resilient human-AI teams through optimizing roles, configurations, and trust; and 3) scaling algorithms and human-AI teams for flexibility across a range of potential contexts and situations.
COA-GPT: Generative Pre-trained Transformers for Accelerated Course of Action Development in Military Operations
Feb 01, 2024



The development of Courses of Action (COAs) in military operations is traditionally a time-consuming and intricate process. Addressing this challenge, this study introduces COA-GPT, a novel algorithm employing Large Language Models (LLMs) for rapid and efficient generation of valid COAs. COA-GPT incorporates military doctrine and domain expertise to LLMs through in-context learning, allowing commanders to input mission information - in both text and image formats - and receive strategically aligned COAs for review and approval. Uniquely, COA-GPT not only accelerates COA development, producing initial COAs within seconds, but also facilitates real-time refinement based on commander feedback. This work evaluates COA-GPT in a military-relevant scenario within a militarized version of the StarCraft II game, comparing its performance against state-of-the-art reinforcement learning algorithms. Our results demonstrate COA-GPT's superiority in generating strategically sound COAs more swiftly, with added benefits of enhanced adaptability and alignment with commander intentions. COA-GPT's capability to rapidly adapt and update COAs during missions presents a transformative potential for military planning, particularly in addressing planning discrepancies and capitalizing on emergent windows of opportunities.
DIP-RL: Demonstration-Inferred Preference Learning in Minecraft
Jul 22, 2023

In machine learning for sequential decision-making, an algorithmic agent learns to interact with an environment while receiving feedback in the form of a reward signal. However, in many unstructured real-world settings, such a reward signal is unknown and humans cannot reliably craft a reward signal that correctly captures desired behavior. To solve tasks in such unstructured and open-ended environments, we present Demonstration-Inferred Preference Reinforcement Learning (DIP-RL), an algorithm that leverages human demonstrations in three distinct ways, including training an autoencoder, seeding reinforcement learning (RL) training batches with demonstration data, and inferring preferences over behaviors to learn a reward function to guide RL. We evaluate DIP-RL in a tree-chopping task in Minecraft. Results suggest that the method can guide an RL agent to learn a reward function that reflects human preferences and that DIP-RL performs competitively relative to baselines. DIP-RL is inspired by our previous work on combining demonstrations and pairwise preferences in Minecraft, which was awarded a research prize at the 2022 NeurIPS MineRL BASALT competition, Learning from Human Feedback in Minecraft. Example trajectory rollouts of DIP-RL and baselines are located at https://sites.google.com/view/dip-rl.
DisasterResponseGPT: Large Language Models for Accelerated Plan of Action Development in Disaster Response Scenarios
Jun 29, 2023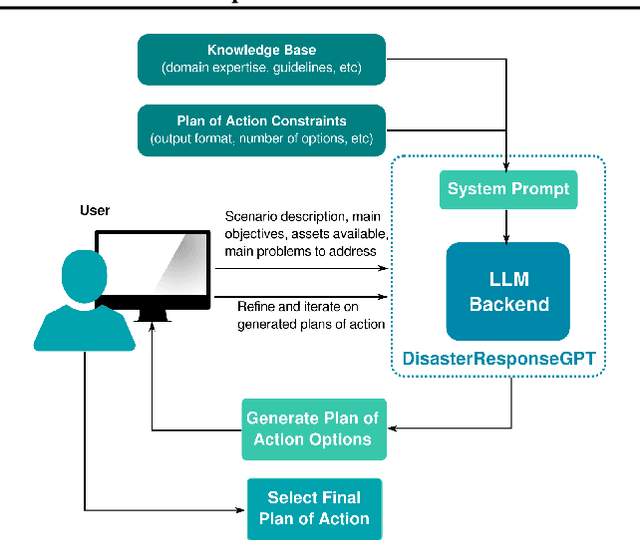
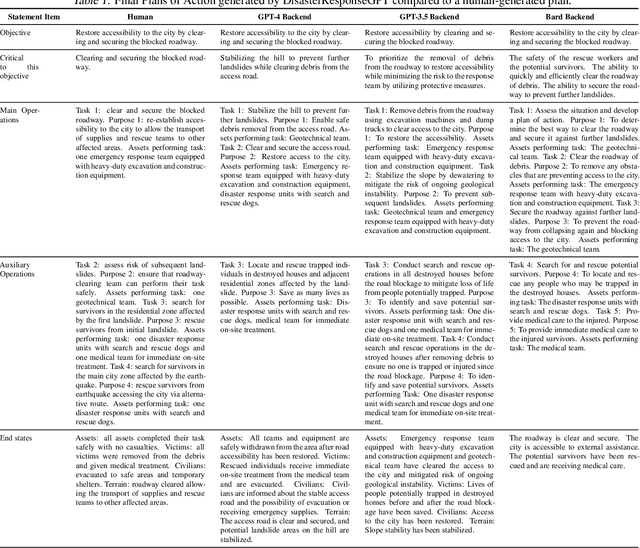
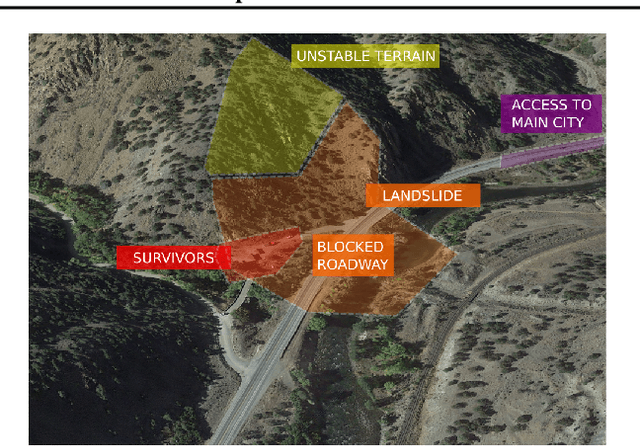
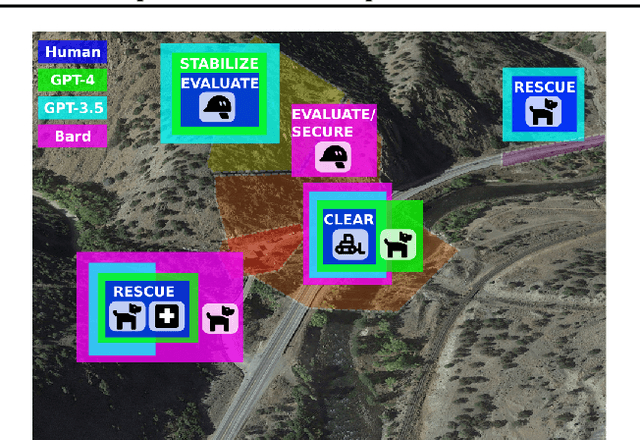
The development of plans of action in disaster response scenarios is a time-consuming process. Large Language Models (LLMs) offer a powerful solution to expedite this process through in-context learning. This study presents DisasterResponseGPT, an algorithm that leverages LLMs to generate valid plans of action quickly by incorporating disaster response and planning guidelines in the initial prompt. In DisasterResponseGPT, users input the scenario description and receive a plan of action as output. The proposed method generates multiple plans within seconds, which can be further refined following the user's feedback. Preliminary results indicate that the plans of action developed by DisasterResponseGPT are comparable to human-generated ones while offering greater ease of modification in real-time. This approach has the potential to revolutionize disaster response operations by enabling rapid updates and adjustments during the plan's execution.
Learning Flight Control Systems from Human Demonstrations and Real-Time Uncertainty-Informed Interventions
May 01, 2023



This paper describes a methodology for learning flight control systems from human demonstrations and interventions while considering the estimated uncertainty in the learned models. The proposed approach uses human demonstrations to train an initial model via imitation learning and then iteratively, improve its performance by using real-time human interventions. The aim of the interventions is to correct undesired behaviors and adapt the model to changes in the task dynamics. The learned model uncertainty is estimated in real-time via Monte Carlo Dropout and the human supervisor is cued for intervention via an audiovisual signal when this uncertainty exceeds a predefined threshold. This proposed approach is validated in an autonomous quadrotor landing task on both fixed and moving platforms. It is shown that with this algorithm, a human can rapidly teach a flight task to an unmanned aerial vehicle via demonstrating expert trajectories and then adapt the learned model by intervening when the learned controller performs any undesired maneuver, the task changes, and/or the model uncertainty exceeds a threshold
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023



To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Learning to Guide Multiple Heterogeneous Actors from a Single Human Demonstration via Automatic Curriculum Learning in StarCraft II
May 11, 2022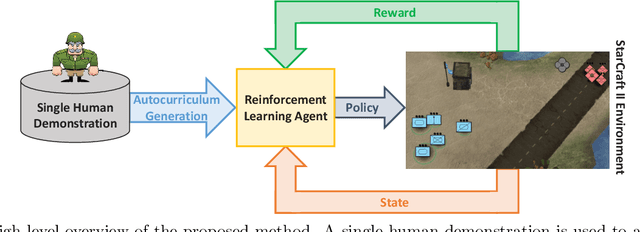


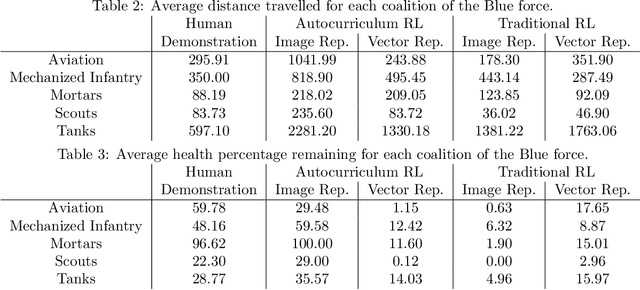
Traditionally, learning from human demonstrations via direct behavior cloning can lead to high-performance policies given that the algorithm has access to large amounts of high-quality data covering the most likely scenarios to be encountered when the agent is operating. However, in real-world scenarios, expert data is limited and it is desired to train an agent that learns a behavior policy general enough to handle situations that were not demonstrated by the human expert. Another alternative is to learn these policies with no supervision via deep reinforcement learning, however, these algorithms require a large amount of computing time to perform well on complex tasks with high-dimensional state and action spaces, such as those found in StarCraft II. Automatic curriculum learning is a recent mechanism comprised of techniques designed to speed up deep reinforcement learning by adjusting the difficulty of the current task to be solved according to the agent's current capabilities. Designing a proper curriculum, however, can be challenging for sufficiently complex tasks, and thus we leverage human demonstrations as a way to guide agent exploration during training. In this work, we aim to train deep reinforcement learning agents that can command multiple heterogeneous actors where starting positions and overall difficulty of the task are controlled by an automatically-generated curriculum from a single human demonstration. Our results show that an agent trained via automated curriculum learning can outperform state-of-the-art deep reinforcement learning baselines and match the performance of the human expert in a simulated command and control task in StarCraft II modeled over a real military scenario.