 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Augmented Hierarchical Agents
Nov 09, 2023



Solving long-horizon, temporally-extended tasks using Reinforcement Learning (RL) is challenging, compounded by the common practice of learning without prior knowledge (or tabula rasa learning). Humans can generate and execute plans with temporally-extended actions and quickly learn to perform new tasks because we almost never solve problems from scratch. We want autonomous agents to have this same ability. Recently, LLMs have been shown to encode a tremendous amount of knowledge about the world and to perform impressive in-context learning and reasoning. However, using LLMs to solve real world problems is hard because they are not grounded in the current task. In this paper we exploit the planning capabilities of LLMs while using RL to provide learning from the environment, resulting in a hierarchical agent that uses LLMs to solve long-horizon tasks. Instead of completely relying on LLMs, they guide a high-level policy, making learning significantly more sample efficient. This approach is evaluated in simulation environments such as MiniGrid, SkillHack, and Crafter, and on a real robot arm in block manipulation tasks. We show that agents trained using our approach outperform other baselines methods and, once trained, don't need access to LLMs during deployment.
ReProHRL: Towards Multi-Goal Navigation in the Real World using Hierarchical Agents
Aug 17, 2023



Robots have been successfully used to perform tasks with high precision. In real-world environments with sparse rewards and multiple goals, learning is still a major challenge and Reinforcement Learning (RL) algorithms fail to learn good policies. Training in simulation environments and then fine-tuning in the real world is a common approach. However, adapting to the real-world setting is a challenge. In this paper, we present a method named Ready for Production Hierarchical RL (ReProHRL) that divides tasks with hierarchical multi-goal navigation guided by reinforcement learning. We also use object detectors as a pre-processing step to learn multi-goal navigation and transfer it to the real world. Empirical results show that the proposed ReProHRL method outperforms the state-of-the-art baseline in simulation and real-world environments in terms of both training time and performance. Although both methods achieve a 100% success rate in a simple environment for single goal-based navigation, in a more complex environment and multi-goal setting, the proposed method outperforms the baseline by 18% and 5%, respectively. For the real-world implementation and proof of concept demonstration, we deploy the proposed method on a nano-drone named Crazyflie with a front camera to perform multi-goal navigation experiments.
Towards an Interpretable Hierarchical Agent Framework using Semantic Goals
Oct 16, 2022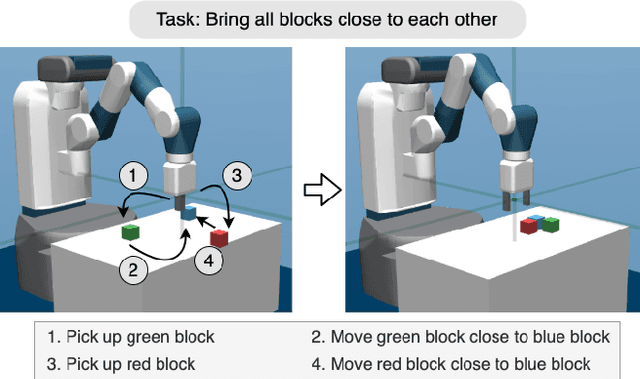

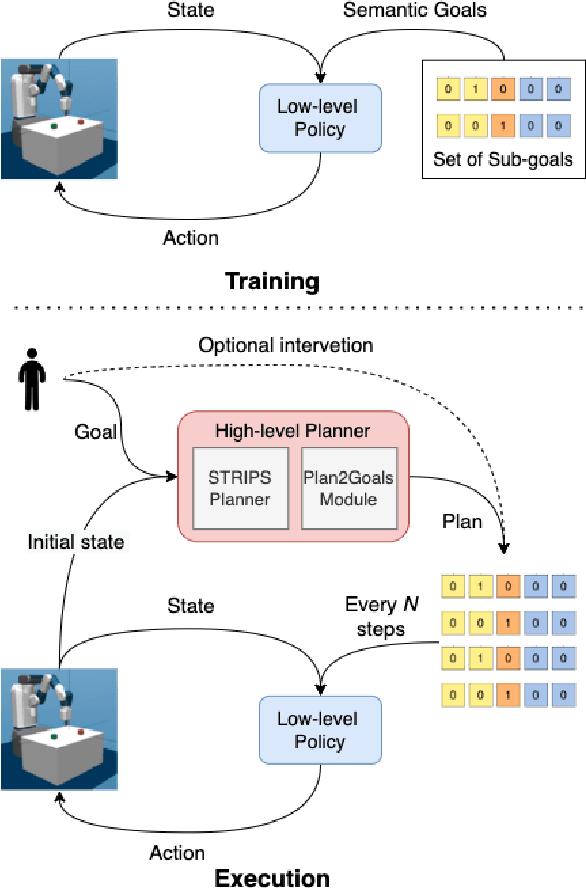

Learning to solve long horizon temporally extended tasks with reinforcement learning has been a challenge for several years now. We believe that it is important to leverage both the hierarchical structure of complex tasks and to use expert supervision whenever possible to solve such tasks. This work introduces an interpretable hierarchical agent framework by combining planning and semantic goal directed reinforcement learning. We assume access to certain spatial and haptic predicates and construct a simple and powerful semantic goal space. These semantic goal representations are more interpretable, making expert supervision and intervention easier. They also eliminate the need to write complex, dense reward functions thereby reducing human engineering effort. We evaluate our framework on a robotic block manipulation task and show that it performs better than other methods, including both sparse and dense reward functions. We also suggest some next steps and discuss how this framework makes interaction and collaboration with humans easier.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022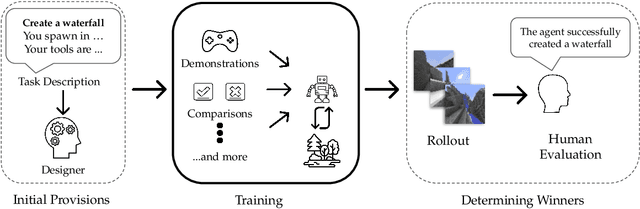
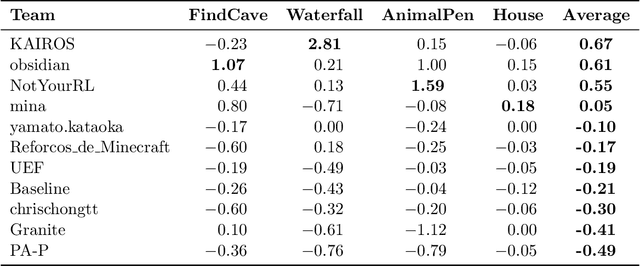
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.
Combining Learning from Human Feedback and Knowledge Engineering to Solve Hierarchical Tasks in Minecraft
Dec 07, 2021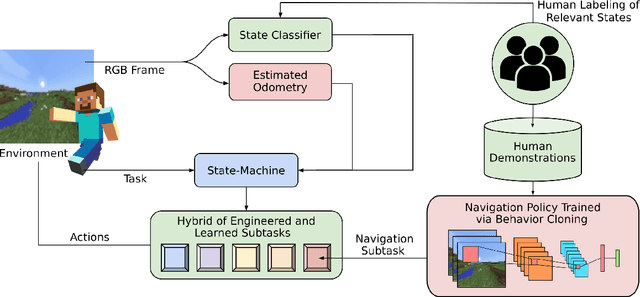
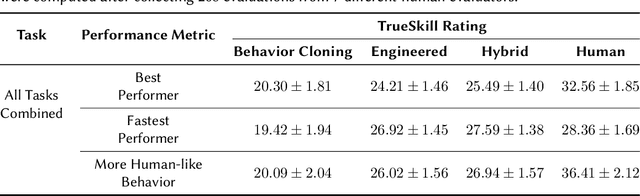

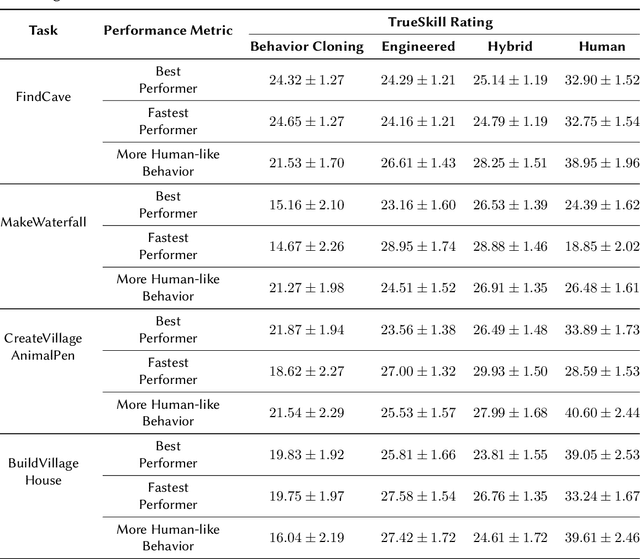
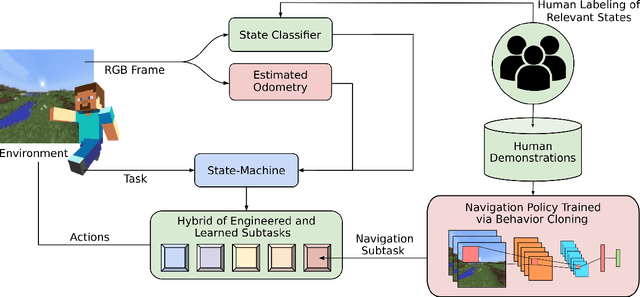
Real-world tasks of interest are generally poorly defined by human-readable descriptions and have no pre-defined reward signals unless it is defined by a human designer. Conversely, data-driven algorithms are often designed to solve a specific, narrowly defined, task with performance metrics that drives the agent's learning. In this work, we present the solution that won first place and was awarded the most human-like agent in the 2021 NeurIPS Competition MineRL BASALT Challenge: Learning from Human Feedback in Minecraft, which challenged participants to use human data to solve four tasks defined only by a natural language description and no reward function. Our approach uses the available human demonstration data to train an imitation learning policy for navigation and additional human feedback to train an image classifier. These modules, together with an estimated odometry map, are then combined into a state-machine designed based on human knowledge of the tasks that breaks them down in a natural hierarchy and controls which macro behavior the learning agent should follow at any instant. We compare this hybrid intelligence approach to both end-to-end machine learning and pure engineered solutions, which are then judged by human evaluators. Codebase is available at https://github.com/viniciusguigo/kairos_minerl_basalt.
Automatic Goal Generation using Dynamical Distance Learning
Nov 07, 2021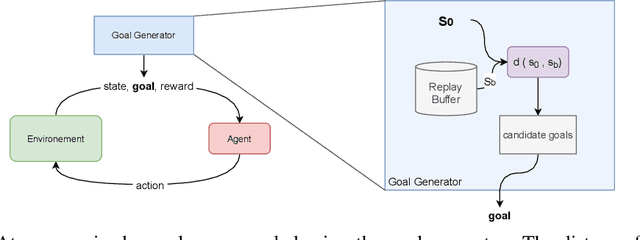
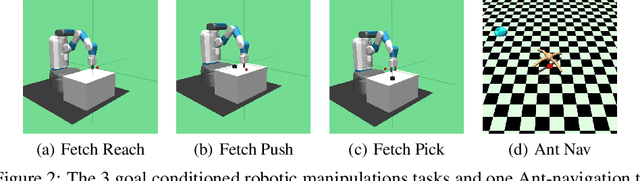
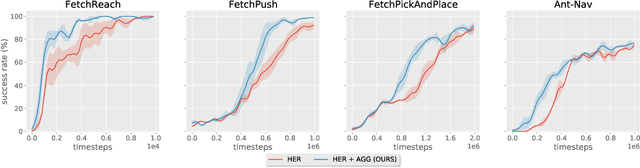

Reinforcement Learning (RL) agents can learn to solve complex sequential decision making tasks by interacting with the environment. However, sample efficiency remains a major challenge. In the field of multi-goal RL, where agents are required to reach multiple goals to solve complex tasks, improving sample efficiency can be especially challenging. On the other hand, humans or other biological agents learn such tasks in a much more strategic way, following a curriculum where tasks are sampled with increasing difficulty level in order to make gradual and efficient learning progress. In this work, we propose a method for automatic goal generation using a dynamical distance function (DDF) in a self-supervised fashion. DDF is a function which predicts the dynamical distance between any two states within a markov decision process (MDP). With this, we generate a curriculum of goals at the appropriate difficulty level to facilitate efficient learning throughout the training process. We evaluate this approach on several goal-conditioned robotic manipulation and navigation tasks, and show improvements in sample efficiency over a baseline method which only uses random goal sampling.
Interactive Hierarchical Guidance using Language
Oct 09, 2021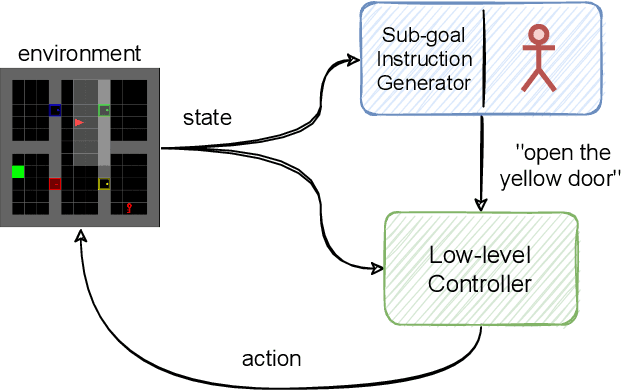
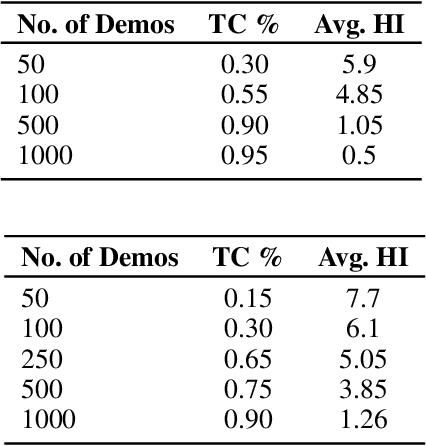


Reinforcement learning has been successful in many tasks ranging from robotic control, games, energy management etc. In complex real world environments with sparse rewards and long task horizons, sample efficiency is still a major challenge. Most complex tasks can be easily decomposed into high-level planning and low level control. Therefore, it is important to enable agents to leverage the hierarchical structure and decompose bigger tasks into multiple smaller sub-tasks. We introduce an approach where we use language to specify sub-tasks and a high-level planner issues language commands to a low level controller. The low-level controller executes the sub-tasks based on the language commands. Our experiments show that this method is able to solve complex long horizon planning tasks with limited human supervision. Using language has added benefit of interpretability and ability for expert humans to take over the high-level planning task and provide language commands if necessary.
Neural Networks for Pulmonary Disease Diagnosis using Auditory and Demographic Information
Nov 26, 2020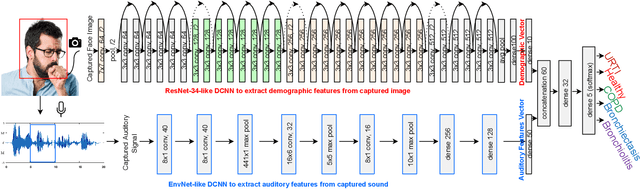
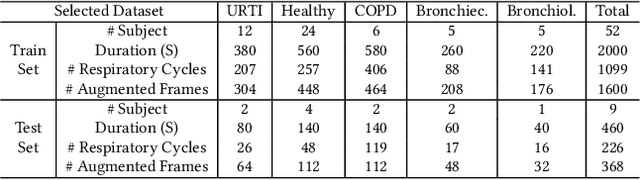


Pulmonary diseases impact millions of lives globally and annually. The recent outbreak of the pandemic of the COVID-19, a novel pulmonary infection, has more than ever brought the attention of the research community to the machine-aided diagnosis of respiratory problems. This paper is thus an effort to exploit machine learning for classification of respiratory problems and proposes a framework that employs as much correlated information (auditory and demographic information in this work) as a dataset provides to increase the sensitivity and specificity of a diagnosing system. First, we use deep convolutional neural networks (DCNNs) to process and classify a publicly released pulmonary auditory dataset, and then we take advantage of the existing demographic information within the dataset and show that the accuracy of the pulmonary classification increases by 5% when trained on the auditory information in conjunction with the demographic information. Since the demographic data can be extracted using computer vision, we suggest using another parallel DCNN to estimate the demographic information of the subject under test visioned by the processing computer. Lastly, as a proposition to bring the healthcare system to users' fingertips, we measure deployment characteristics of the auditory DCNN model onto processing components of an NVIDIA TX2 development board.
On the use of Deep Autoencoders for Efficient Embedded Reinforcement Learning
Mar 25, 2019
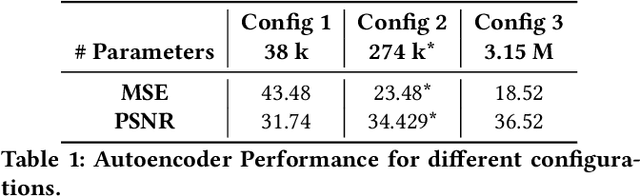
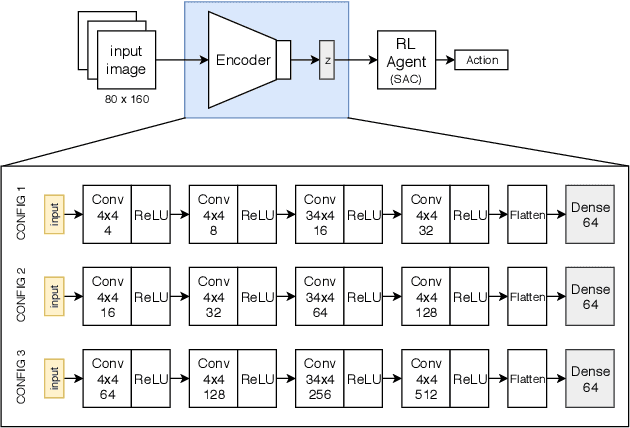
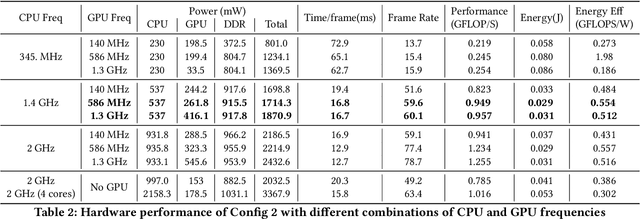
In autonomous embedded systems, it is often vital to reduce the amount of actions taken in the real world and energy required to learn a policy. Training reinforcement learning agents from high dimensional image representations can be very expensive and time consuming. Autoencoders are deep neural network used to compress high dimensional data such as pixelated images into small latent representations. This compression model is vital to efficiently learn policies, especially when learning on embedded systems. We have implemented this model on the NVIDIA Jetson TX2 embedded GPU, and evaluated the power consumption, throughput, and energy consumption of the autoencoders for various CPU/GPU core combinations, frequencies, and model parameters. Additionally, we have shown the reconstructions generated by the autoencoder to analyze the quality of the generated compressed representation and also the performance of the reinforcement learning agent. Finally, we have presented an assessment of the viability of training these models on embedded systems and their usefulness in developing autonomous policies. Using autoencoders, we were able to achieve 4-5 $\times$ improved performance compared to a baseline RL agent with a convolutional feature extractor, while using less than 2W of power.
Improving Safety in Reinforcement Learning Using Model-Based Architectures and Human Intervention
Mar 22, 2019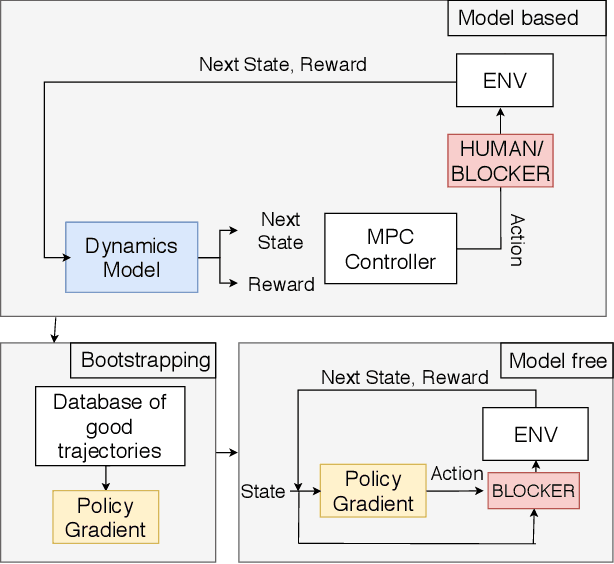
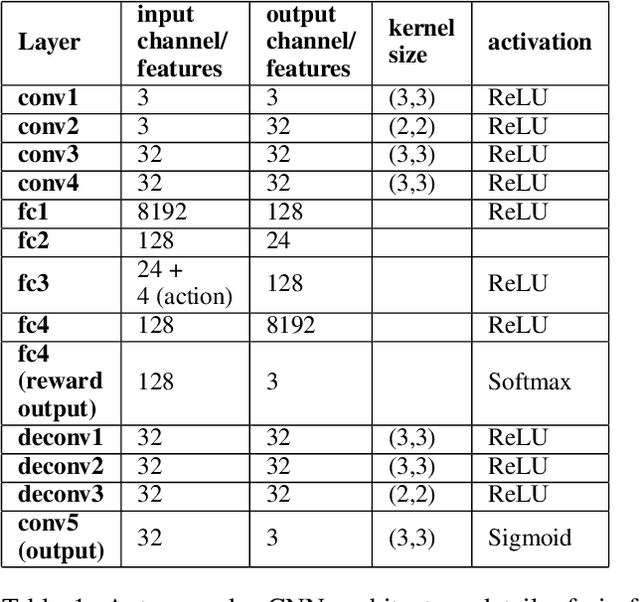
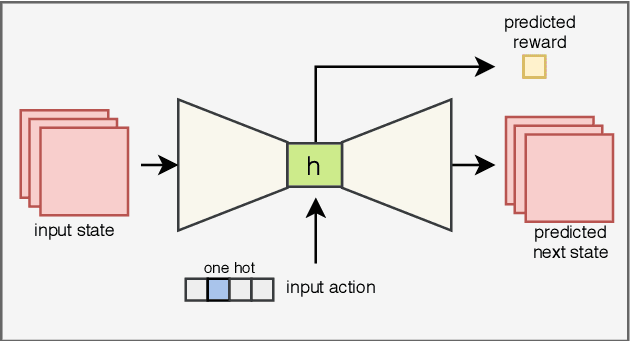
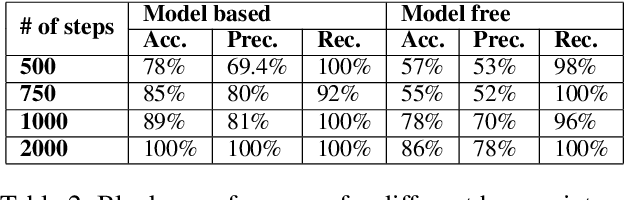
Recent progress in AI and Reinforcement learning has shown great success in solving complex problems with high dimensional state spaces. However, most of these successes have been primarily in simulated environments where failure is of little or no consequence. Most real-world applications, however, require training solutions that are safe to operate as catastrophic failures are inadmissible especially when there is human interaction involved. Currently, Safe RL systems use human oversight during training and exploration in order to make sure the RL agent does not go into a catastrophic state. These methods require a large amount of human labor and it is very difficult to scale up. We present a hybrid method for reducing the human intervention time by combining model-based approaches and training a supervised learner to improve sample efficiency while also ensuring safety. We evaluate these methods on various grid-world environments using both standard and visual representations and show that our approach achieves better performance in terms of sample efficiency, number of catastrophic states reached as well as overall task performance compared to traditional model-free approaches