 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Token per Multimodal Evidence: Latent Memory for Resource-Constrained QA
Jun 09, 2026External memory effectively grounds large language models (LLMs) and vision-language models (VLMs)-based question answering (QA) in relevant multimodal evidence. However, existing memory paradigms represent each memory item in raw text and image forms, so retrieval-based systems must pass the retrieved text or images to the generation LLMs/VLMs, resulting in high token consumption and storage pressure, making it unaffordable for resource-constrained applications. We propose Latent Memory, a latent-space memory paradigm that replaces each raw text or image evidence item with a single high-dimensional latent token produced by a small compressor LLM/VLM. Rather than retrieving raw evidence for generation, Latent Memory operates in a unified latent representation space: the query is embedded into this space to retrieve relevant latent tokens, and the retrieved latent tokens are directly prompted to a pretrained LLM or VLM for answer generation. To make each latent token simultaneously informative for reconstruction, retrieval, and generation, we train the compressor with reconstruction, contrastive, and distillation objectives in a unified end-to-end manner. Latent Memory is evaluated on seven text-only QA benchmarks (e.g., HotpotQA) and multimodal QA benchmarks, where it achieves competitive QA performance compared to advanced RAG baselines while consuming 3x to 10x fewer generator tokens. It can also deliver the strongest image-grounded QA performance on WebQA. Code is available at https://github.com/zz1358m/Latent-Memory-Master.
Learning the Interaction Prior for Protein-Protein Interaction Prediction: A Model-Agnostic Approach
May 11, 2026Protein-protein interactions (PPIs) are fundamental to cellular function and disease mechanisms. Current learning-based PPI predictors focus on learning powerful protein representations but neglect designing specialized classification heads. They mainly rely on generic aggregating methods like concatenation or dot products, which lack biological insight. Motivated by the biological "L3 rule", where multiple length-3 paths between a pair of proteins indicate their interaction likelihood, our study addresses this gap by designing a biologically informed PPI classifier. In this paper, we provide empirical evidence that popular PPI datasets strongly support the L3 rule. We propose an L3-path-regularized graph prompt learning method called L3-PPI, which can generate a prompt graph with virtual L3 paths based on protein representations and controls the number of paths. L3-PPI reformulates the classification of protein embedding pairs into a graph-level classification task over the generated prompt graph. This lightweight module seamlessly integrates with PPI predictors as a plug-and-play component, injecting the interaction prior of complementarity to enhance performance. Extensive experiments show that L3-PPI achieves superior performance enhancements over advanced competitors.
3D Point Cloud Generation via Autoregressive Up-sampling
Mar 11, 2025We introduce a pioneering autoregressive generative model for 3D point cloud generation. Inspired by visual autoregressive modeling (VAR), we conceptualize point cloud generation as an autoregressive up-sampling process. This leads to our novel model, PointARU, which progressively refines 3D point clouds from coarse to fine scales. PointARU follows a two-stage training paradigm: first, it learns multi-scale discrete representations of point clouds, and then it trains an autoregressive transformer for next-scale prediction. To address the inherent unordered and irregular structure of point clouds, we incorporate specialized point-based up-sampling network modules in both stages and integrate 3D absolute positional encoding based on the decoded point cloud at each scale during the second stage. Our model surpasses state-of-the-art (SoTA) diffusion-based approaches in both generation quality and parameter efficiency across diverse experimental settings, marking a new milestone for autoregressive methods in 3D point cloud generation. Furthermore, PointARU demonstrates exceptional performance in completing partial 3D shapes and up-sampling sparse point clouds, outperforming existing generative models in these tasks.
Continual Optimization with Symmetry Teleportation for Multi-Task Learning
Mar 06, 2025



Multi-task learning (MTL) is a widely explored paradigm that enables the simultaneous learning of multiple tasks using a single model. Despite numerous solutions, the key issues of optimization conflict and task imbalance remain under-addressed, limiting performance. Unlike existing optimization-based approaches that typically reweight task losses or gradients to mitigate conflicts or promote progress, we propose a novel approach based on Continual Optimization with Symmetry Teleportation (COST). During MTL optimization, when an optimization conflict arises, we seek an alternative loss-equivalent point on the loss landscape to reduce conflict. Specifically, we utilize a low-rank adapter (LoRA) to facilitate this practical teleportation by designing convergent, loss-invariant objectives. Additionally, we introduce a historical trajectory reuse strategy to continually leverage the benefits of advanced optimizers. Extensive experiments on multiple mainstream datasets demonstrate the effectiveness of our approach. COST is a plug-and-play solution that enhances a wide range of existing MTL methods. When integrated with state-of-the-art methods, COST achieves superior performance.
VoxEval: Benchmarking the Knowledge Understanding Capabilities of End-to-End Spoken Language Models
Jan 09, 2025



With the growing demand for developing speech-based interaction models, end-to-end Spoken Language Models (SLMs) have emerged as a promising solution. When engaging in conversations with humans, it is essential for these models to comprehend a wide range of world knowledge. In this paper, we introduce VoxEval, a novel speech question-answering benchmark specifically designed to assess SLMs' knowledge understanding through purely speech-based interactions. Unlike existing AudioQA benchmarks, VoxEval maintains speech format for both questions and answers, evaluates model robustness across diverse audio conditions (varying timbres, audio qualities, and speaking styles), and pioneers the assessment of challenging domains like mathematical problem-solving in spoken format. Our comprehensive evaluation of recent SLMs using VoxEval reveals significant performance limitations in current models, highlighting crucial areas for future improvements.
Recent Advances in Speech Language Models: A Survey
Oct 01, 2024



Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)", where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) -- end-to-end models that generate speech without converting from text -- have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize the evaluation metrics for SpeechLMs, and discuss the challenges and future research directions in this rapidly evolving field.
Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping
Feb 22, 2024Self-alignment is an effective way to reduce the cost of human annotation while ensuring promising model capability. However, most current methods complete the data collection and training steps in a single round, which may overlook the continuously improving ability of self-aligned models. This gives rise to a key query: What if we do multi-time bootstrapping self-alignment? Does this strategy enhance model performance or lead to rapid degradation? In this paper, our pioneering exploration delves into the impact of bootstrapping self-alignment on large language models. Our findings reveal that bootstrapping self-alignment markedly surpasses the single-round approach, by guaranteeing data diversity from in-context learning. To further exploit the capabilities of bootstrapping, we investigate and adjust the training order of data, which yields improved performance of the model. Drawing on these findings, we propose Step-On-Feet Tuning (SOFT) which leverages model's continuously enhanced few-shot ability to boost zero or one-shot performance. Based on easy-to-hard training recipe, we propose SOFT+ which further boost self-alignment's performance. Our experiments demonstrate the efficiency of SOFT (SOFT+) across various classification and generation tasks, highlighting the potential of bootstrapping self-alignment on continually enhancing model alignment performance.
A Unified View of Deep Learning for Reaction and Retrosynthesis Prediction: Current Status and Future Challenges
Jun 28, 2023Reaction and retrosynthesis prediction are fundamental tasks in computational chemistry that have recently garnered attention from both the machine learning and drug discovery communities. Various deep learning approaches have been proposed to tackle these problems, and some have achieved initial success. In this survey, we conduct a comprehensive investigation of advanced deep learning-based models for reaction and retrosynthesis prediction. We summarize the design mechanisms, strengths, and weaknesses of state-of-the-art approaches. Then, we discuss the limitations of current solutions and open challenges in the problem itself. Finally, we present promising directions to facilitate future research. To our knowledge, this paper is the first comprehensive and systematic survey that seeks to provide a unified understanding of reaction and retrosynthesis prediction.
Doubly Stochastic Graph-based Non-autoregressive Reaction Prediction
Jun 05, 2023Organic reaction prediction is a critical task in drug discovery. Recently, researchers have achieved non-autoregressive reaction prediction by modeling the redistribution of electrons, resulting in state-of-the-art top-1 accuracy, and enabling parallel sampling. However, the current non-autoregressive decoder does not satisfy two essential rules of electron redistribution modeling simultaneously: the electron-counting rule and the symmetry rule. This violation of the physical constraints of chemical reactions impairs model performance. In this work, we propose a new framework called that combines two doubly stochastic self-attention mappings to obtain electron redistribution predictions that follow both constraints. We further extend our solution to a general multi-head attention mechanism with augmented constraints. To achieve this, we apply Sinkhorn's algorithm to iteratively update self-attention mappings, which imposes doubly conservative constraints as additional informative priors on electron redistribution modeling. We theoretically demonstrate that our can simultaneously satisfy both rules, which the current decoder mechanism cannot do. Empirical results show that our approach consistently improves the predictive performance of non-autoregressive models and does not bring an unbearable additional computational cost.
Graph-adaptive Rectified Linear Unit for Graph Neural Networks
Feb 13, 2022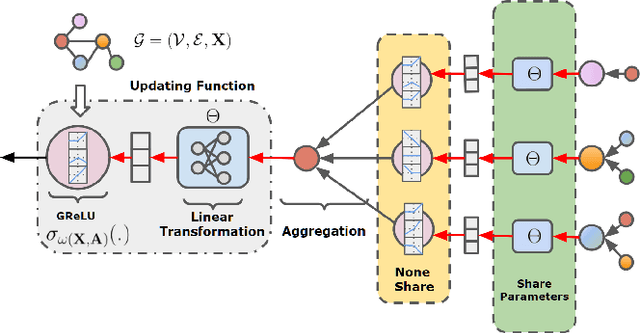

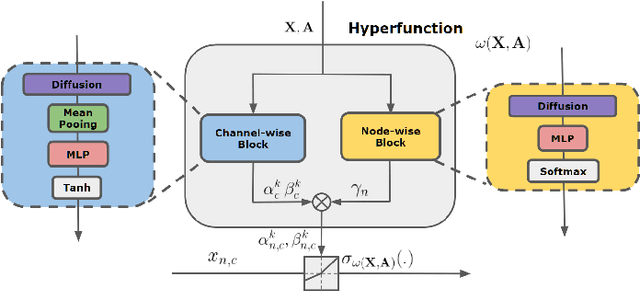
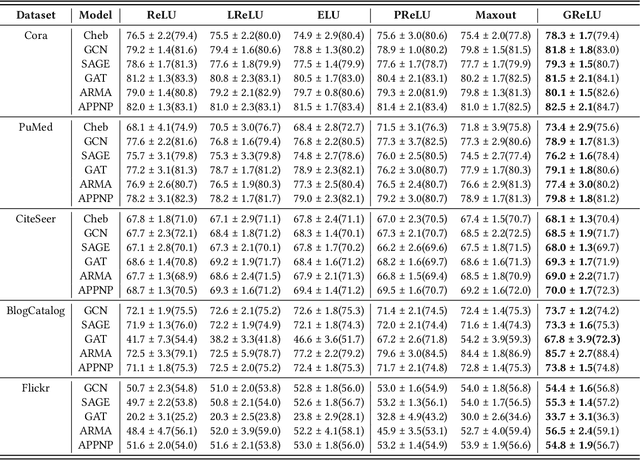
Graph Neural Networks (GNNs) have achieved remarkable success by extending traditional convolution to learning on non-Euclidean data. The key to the GNNs is adopting the neural message-passing paradigm with two stages: aggregation and update. The current design of GNNs considers the topology information in the aggregation stage. However, in the updating stage, all nodes share the same updating function. The identical updating function treats each node embedding as i.i.d. random variables and thus ignores the implicit relationships between neighborhoods, which limits the capacity of the GNNs. The updating function is usually implemented with a linear transformation followed by a non-linear activation function. To make the updating function topology-aware, we inject the topological information into the non-linear activation function and propose Graph-adaptive Rectified Linear Unit (GReLU), which is a new parametric activation function incorporating the neighborhood information in a novel and efficient way. The parameters of GReLU are obtained from a hyperfunction based on both node features and the corresponding adjacent matrix. To reduce the risk of overfitting and the computational cost, we decompose the hyperfunction as two independent components for nodes and features respectively. We conduct comprehensive experiments to show that our plug-and-play GReLU method is efficient and effective given different GNN backbones and various downstream tasks.