 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Concept Extraction Based on Compositional Interpretability
Mar 12, 2026Unsupervised Concept Extraction aims to extract concepts from a single image; however, existing methods suffer from the inability to extract composable intrinsic concepts. To address this, this paper introduces a new task called Compositional and Interpretable Intrinsic Concept Extraction (CI-ICE). The CI-ICE task aims to leverage diffusion-based text-to-image models to extract composable object-level and attribute-level concepts from a single image, such that the original concept can be reconstructed through the combination of these concepts. To achieve this goal, we propose a method called HyperExpress, which addresses the CI-ICE task through two core aspects. Specifically, first, we propose a concept learning approach that leverages the inherent hierarchical modeling capability of hyperbolic space to achieve accurate concept disentanglement while preserving the hierarchical structure and relational dependencies among concepts; second, we introduce a concept-wise optimization method that maps the concept embedding space to maintain complex inter-concept relationships while ensuring concept composability. Our method demonstrates outstanding performance in extracting compositionally interpretable intrinsic concepts from a single image.
ClothFormer:Taming Video Virtual Try-on in All Module
Apr 26, 2022
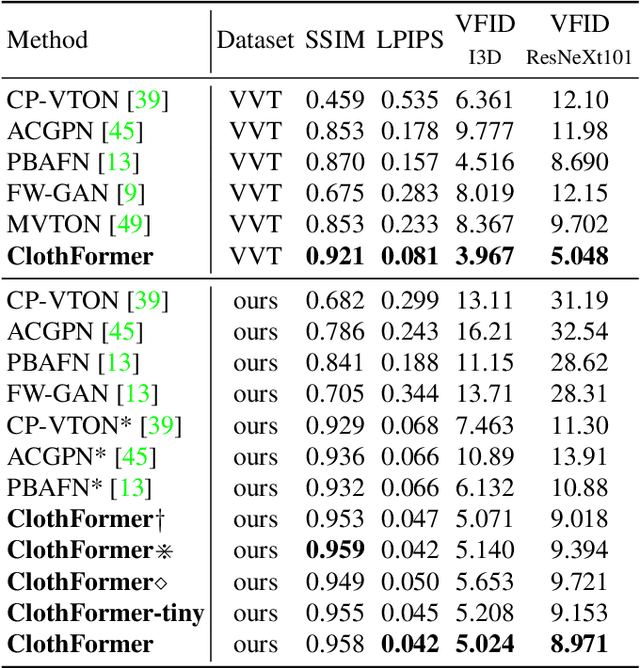
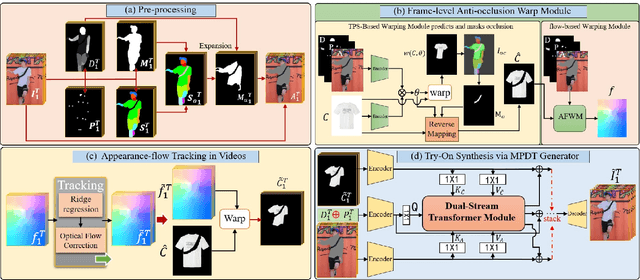
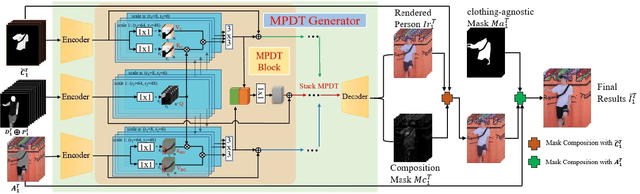
The task of video virtual try-on aims to fit the target clothes to a person in the video with spatio-temporal consistency. Despite tremendous progress of image virtual try-on, they lead to inconsistency between frames when applied to videos. Limited work also explored the task of video-based virtual try-on but failed to produce visually pleasing and temporally coherent results. Moreover, there are two other key challenges: 1) how to generate accurate warping when occlusions appear in the clothing region; 2) how to generate clothes and non-target body parts (e.g. arms, neck) in harmony with the complicated background; To address them, we propose a novel video virtual try-on framework, ClothFormer, which successfully synthesizes realistic, harmonious, and spatio-temporal consistent results in complicated environment. In particular, ClothFormer involves three major modules. First, a two-stage anti-occlusion warping module that predicts an accurate dense flow mapping between the body regions and the clothing regions. Second, an appearance-flow tracking module utilizes ridge regression and optical flow correction to smooth the dense flow sequence and generate a temporally smooth warped clothing sequence. Third, a dual-stream transformer extracts and fuses clothing textures, person features, and environment information to generate realistic try-on videos. Through rigorous experiments, we demonstrate that our method highly surpasses the baselines in terms of synthesized video quality both qualitatively and quantitatively.
iQIYI-VID: A Large Dataset for Multi-modal Person Identification
Nov 19, 2018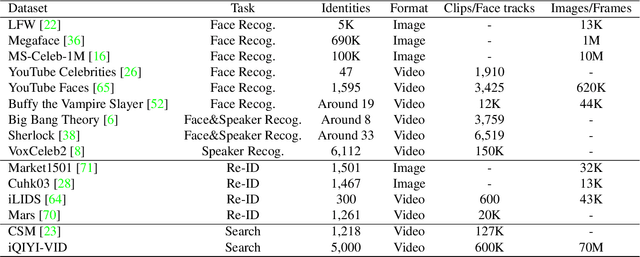

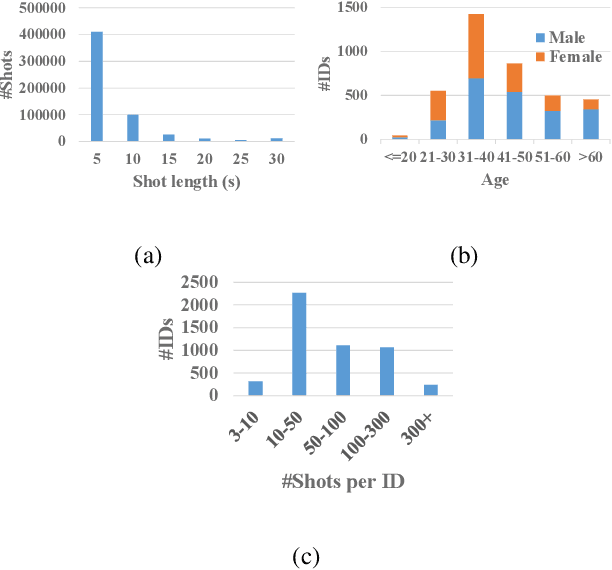
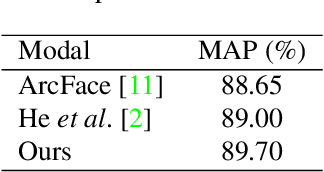
Person identification in the wild is very challenging due to great variation in poses, face quality, clothes, makeup and so on. Traditional research, such as face recognition, person re-identification, and speaker recognition, often focuses on a single modal of information, which is inadequate to handle all the situations in practice. Multi-modal person identification is a more promising way that we can jointly utilize face, head, body, audio features, and so on. In this paper, we introduce iQIYI-VID, the largest video dataset for multi-modal person identification. It is composed of 600K video clips of 5,000 celebrities. These video clips are extracted from 400K hours of online videos of various types, ranging from movies, variety shows, TV series, to news broadcasting. All video clips pass through a careful human annotation process, and the error rate of labels is lower than 0.2%. We evaluated the state-of-art models of face recognition, person re-identification, and speaker recognition on the iQIYI-VID dataset. Experimental results show that these models are still far from being perfect for task of person identification in the wild. We further demonstrate that a simple fusion of multi-modal features can improve person identification considerably. We have released the dataset online to promote multi-modal person identification research.