 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Dynamic Bipedal Walking Across Stepping Stones
May 03, 2022
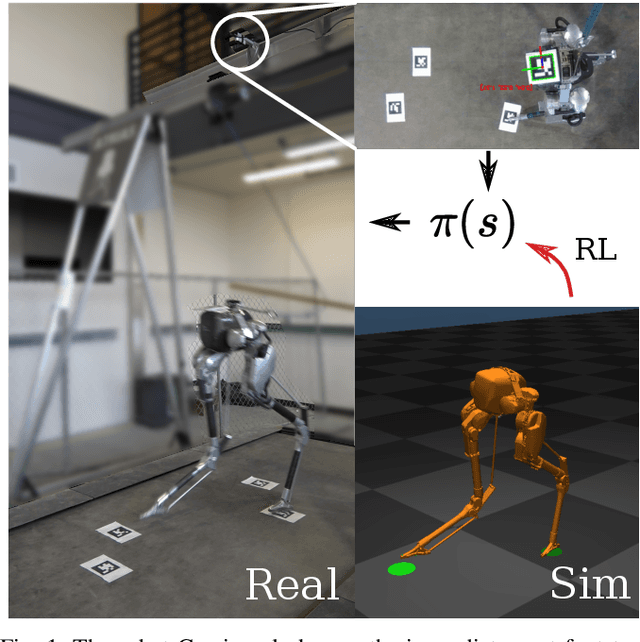
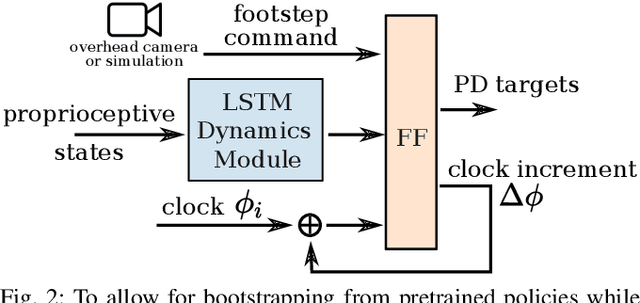
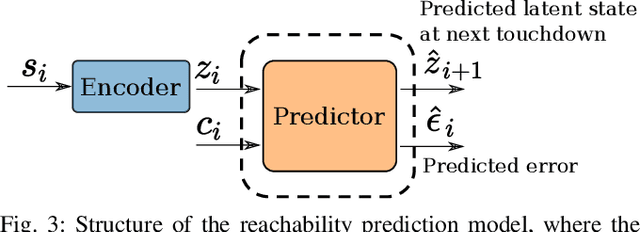
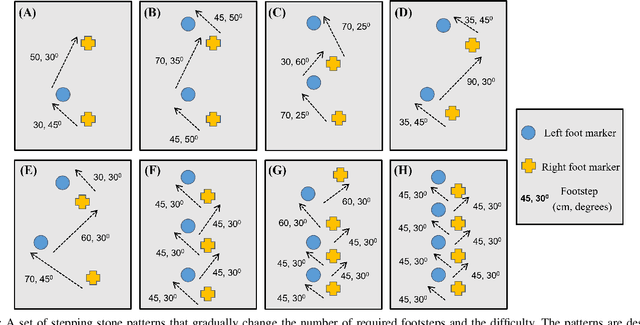
In this work, we propose a learning approach for 3D dynamic bipedal walking when footsteps are constrained to stepping stones. While recent work has shown progress on this problem, real-world demonstrations have been limited to relatively simple open-loop, perception-free scenarios. Our main contribution is a more advanced learning approach that enables real-world demonstrations, using the Cassie robot, of closed-loop dynamic walking over moderately difficult stepping-stone patterns. Our approach first uses reinforcement learning (RL) in simulation to train a controller that maps footstep commands onto joint actions without any reference motion information. We then learn a model of that controller's capabilities, which enables prediction of feasible footsteps given the robot's current dynamic state. The resulting controller and model are then integrated with a real-time overhead camera system for detecting stepping stone locations. For evaluation, we develop a benchmark set of stepping stone patterns, which are used to test performance in both simulation and the real world. Overall, we demonstrate that sim-to-real learning is extremely promising for enabling dynamic locomotion over stepping stones. We also identify challenges remaining that motivate important future research directions.
Adversarial Training-Aided Time-Varying Channel Prediction for TDD/FDD Systems
Apr 25, 2022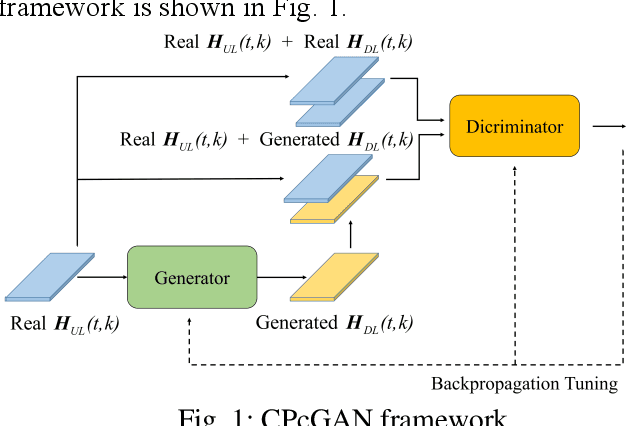
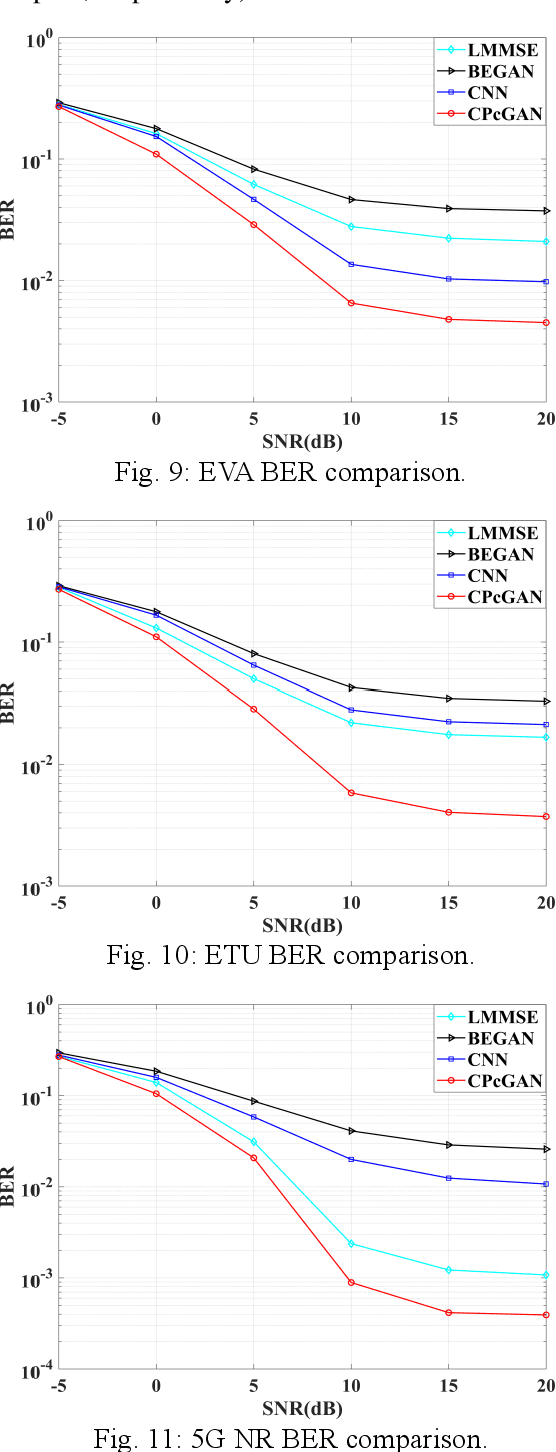
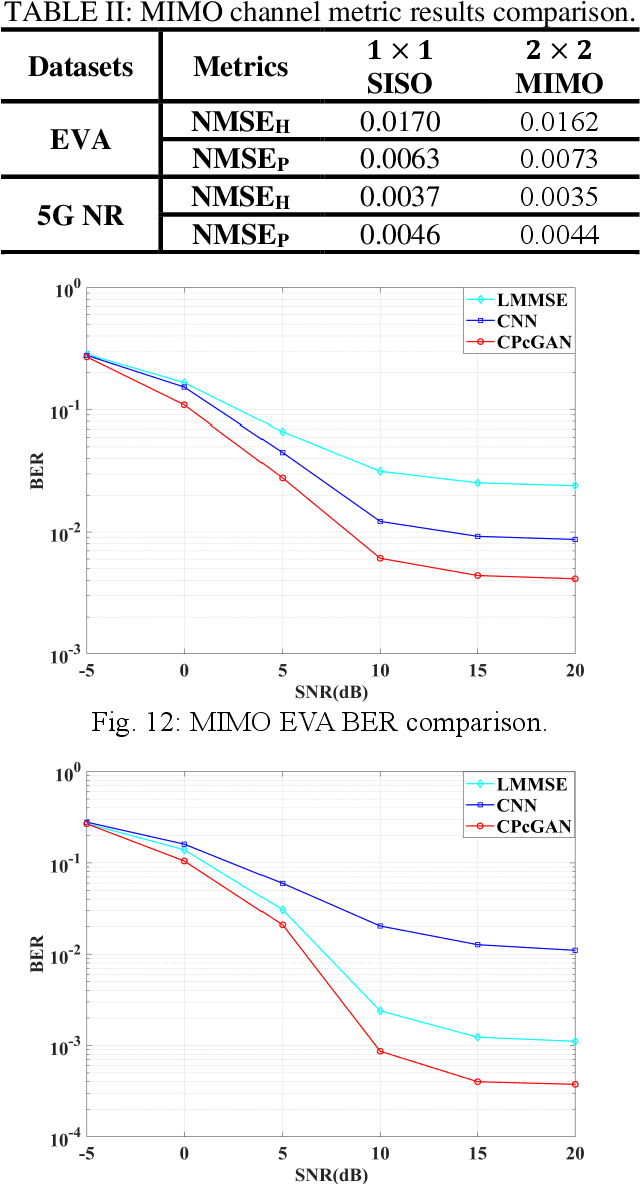
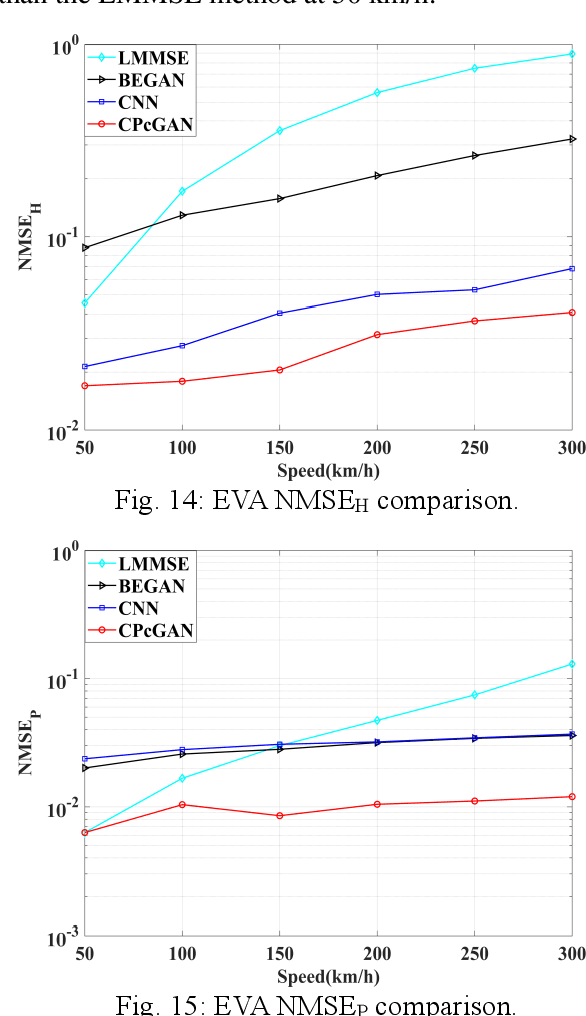
In this paper, a time-varying channel prediction method based on conditional generative adversarial network (CPcGAN) is proposed for time division duplexing/frequency division duplexing (TDD/FDD) systems. CPcGAN utilizes a discriminator to calculate the divergence between the predicted downlink channel state information (CSI) and the real sample distributions under a conditional constraint that is previous uplink CSI. The generator of CPcGAN learns the function relationship between the conditional constraint and the predicted downlink CSI and reduces the divergence between predicted CSI and real CSI. The capability of CPcGAN fitting data distribution can capture the time-varying and multipath characteristics of the channel well. Considering the propagation characteristics of real channel, we further develop a channel prediction error indicator to determine whether the generator reaches the best state. Simulations show that the CPcGAN can obtain higher prediction accuracy and lower system bit error rate than the existing methods under the same user speeds.
Vision-based system for a real-time detection and following of UAV
Apr 29, 2022
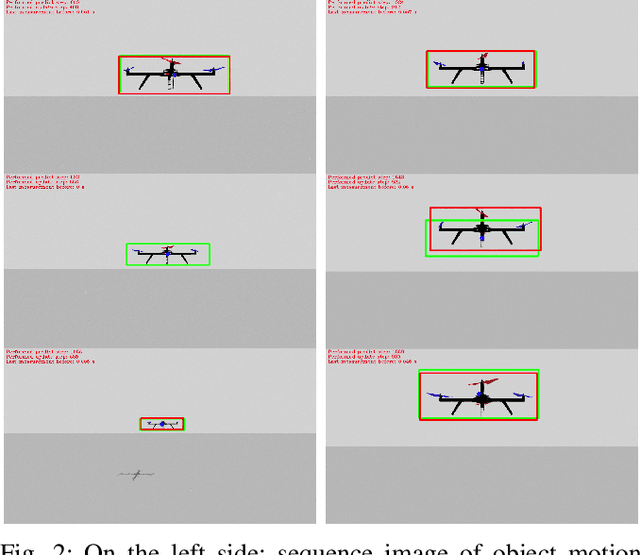
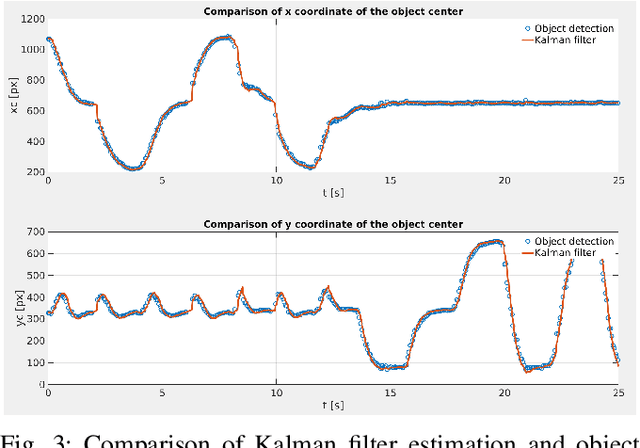
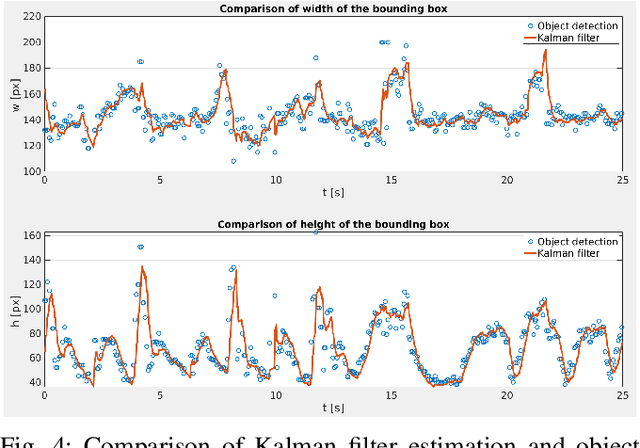
In this paper a vision-based system for detection, motion tracking and following of Unmanned Aerial Vehicle (UAV) with other UAV (follower) is presented. For detection of an airborne UAV we apply a convolutional neural network YOLO trained on a collected and processed dataset of 10,000 images. The trained network is capable of detecting various multirotor UAVs in indoor, outdoor and simulation environments. Furthermore, detection results are improved with Kalman filter which ensures steady and reliable information about position and velocity of a target UAV. Preserving the target UAV in the field of view (FOV) and at required distance is accomplished by a simple nonlinear controller based on visual servoing strategy. The proposed system achieves a real-time performance on Neural Compute Stick 2 with a speed of 20 frames per second (FPS) for the detection of an UAV. Justification and efficiency of the developed vision-based system are confirmed in Gazebo simulation experiment where the target UAV is executing a 3D trajectory in a shape of number eight.
CSI2Image: Image Reconstruction from Channel State Information Using Generative Adversarial Networks
Sep 16, 2020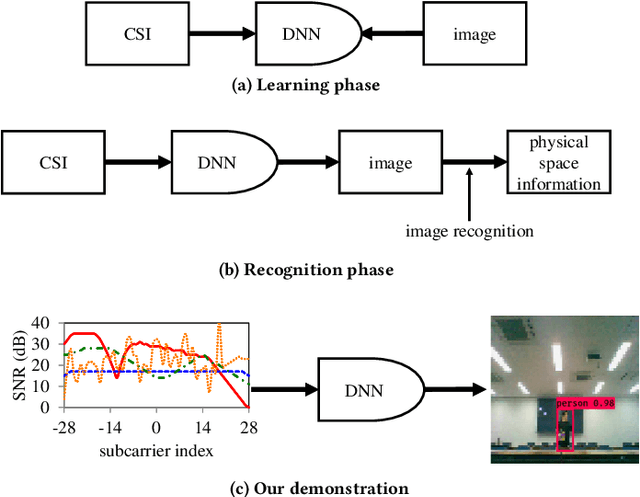

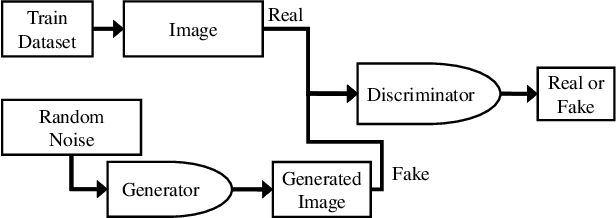

This study aims to find the upper limit of the wireless sensing capability of acquiring physical space information. This is a challenging objective, because at present, wireless sensing studies continue to succeed in acquiring novel phenomena. Thus, although a complete answer cannot be obtained yet, a step is taken towards it here. To achieve this, CSI2Image, a novel channel-state-information (CSI)-to-image conversion method based on generative adversarial networks (GANs), is proposed. The type of physical information acquired using wireless sensing can be estimated by checking wheth\-er the reconstructed image captures the desired physical space information. Three types of learning methods are demonstrated: gen\-er\-a\-tor-only learning, GAN-only learning, and hybrid learning. Evaluating the performance of CSI2Image is difficult, because both the clarity of the image and the presence of the desired physical space information must be evaluated. To solve this problem, a quantitative evaluation methodology using an object detection library is also proposed. CSI2Image was implemented using IEEE 802.11ac compressed CSI, and the evaluation results show that the image was successfully reconstructed. The results demonstrate that gen\-er\-a\-tor-only learning is sufficient for simple wireless sensing problems, but in complex wireless sensing problems, GANs are important for reconstructing generalized images with more accurate physical space information.
Neighbor Enhanced Graph Convolutional Networks for Node Classification and Recommendation
Mar 30, 2022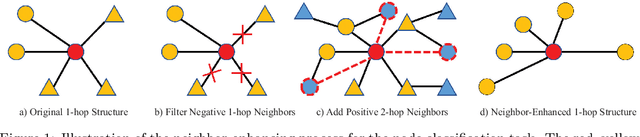
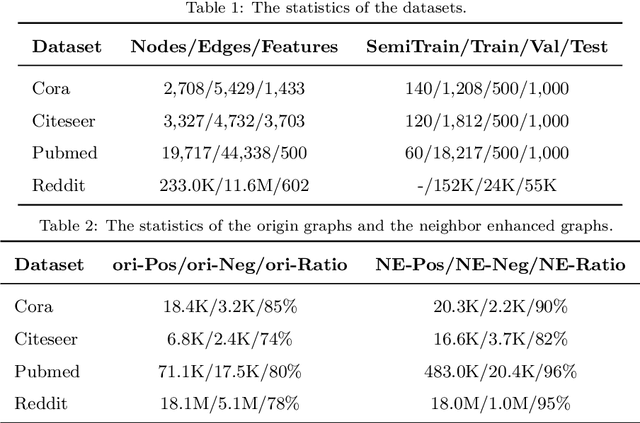

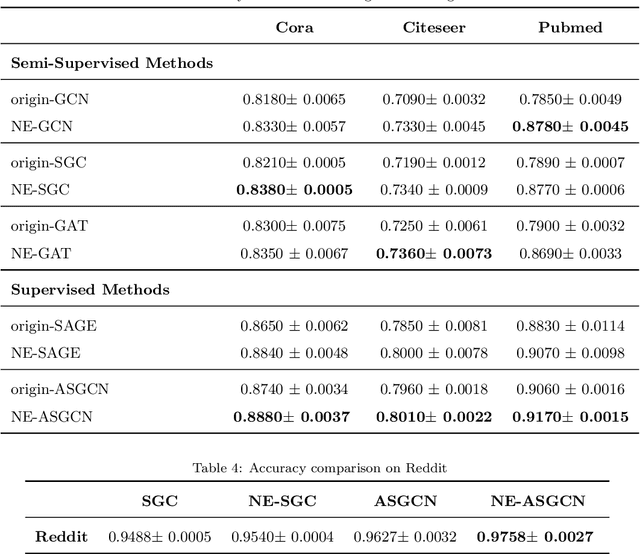
The recently proposed Graph Convolutional Networks (GCNs) have achieved significantly superior performance on various graph-related tasks, such as node classification and recommendation. However, currently researches on GCN models usually recursively aggregate the information from all the neighbors or randomly sampled neighbor subsets, without explicitly identifying whether the aggregated neighbors provide useful information during the graph convolution. In this paper, we theoretically analyze the affection of the neighbor quality over GCN models' performance and propose the Neighbor Enhanced Graph Convolutional Network (NEGCN) framework to boost the performance of existing GCN models. Our contribution is three-fold. First, we at the first time propose the concept of neighbor quality for both node classification and recommendation tasks in a general theoretical framework. Specifically, for node classification, we propose three propositions to theoretically analyze how the neighbor quality affects the node classification performance of GCN models. Second, based on the three proposed propositions, we introduce the graph refinement process including specially designed neighbor evaluation methods to increase the neighbor quality so as to boost both the node classification and recommendation tasks. Third, we conduct extensive node classification and recommendation experiments on several benchmark datasets. The experimental results verify that our proposed NEGCN framework can significantly enhance the performance for various typical GCN models on both node classification and recommendation tasks.
DAMO-NLP at SemEval-2022 Task 11: A Knowledge-based System for Multilingual Named Entity Recognition
Mar 01, 2022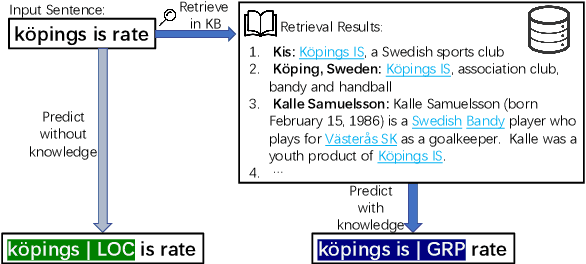

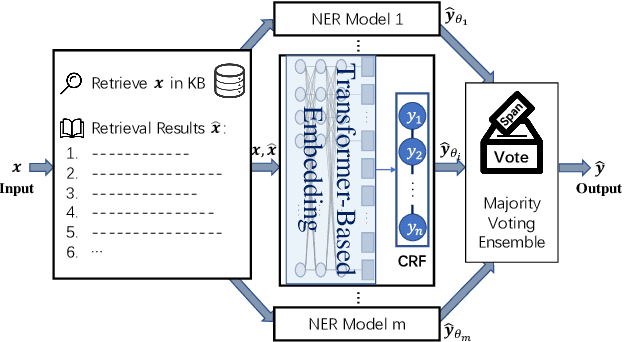
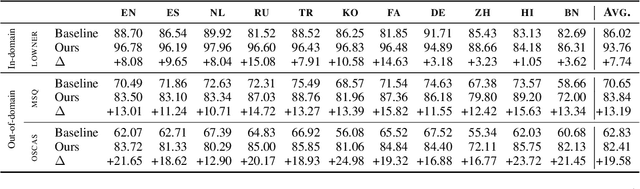
The MultiCoNER shared task aims at detecting semantically ambiguous and complex named entities in short and low-context settings for multiple languages. The lack of contexts makes the recognition of ambiguous named entities challenging. To alleviate this issue, our team DAMO-NLP proposes a knowledge-based system, where we build a multilingual knowledge base based on Wikipedia to provide related context information to the named entity recognition (NER) model. Given an input sentence, our system effectively retrieves related contexts from the knowledge base. The original input sentences are then augmented with such context information, allowing significantly better contextualized token representations to be captured. Our system wins 10 out of 13 tracks in the MultiCoNER shared task.
From Laser Speckle to Particle Size Distribution in drying powders: A Physics-Enhanced AutoCorrelation-based Estimator (PEACE)
Apr 20, 2022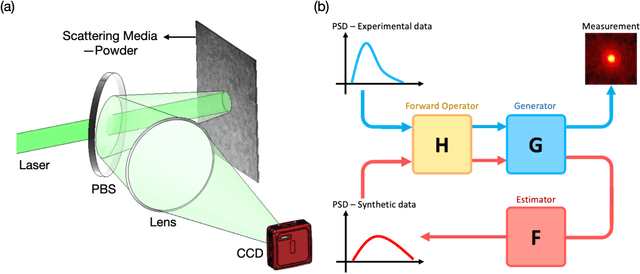
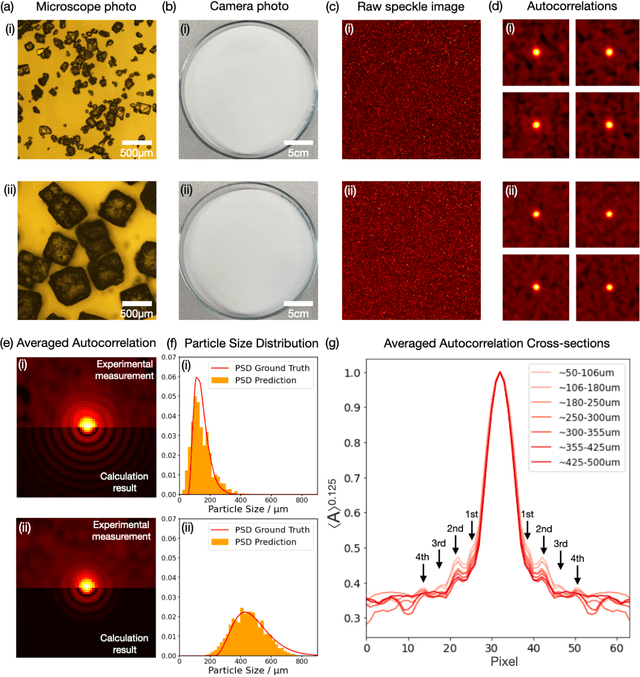
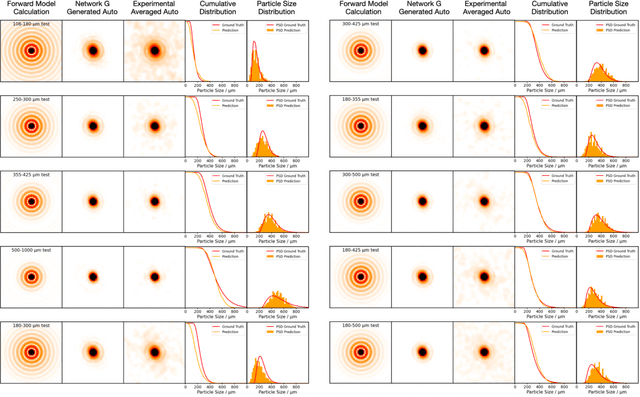
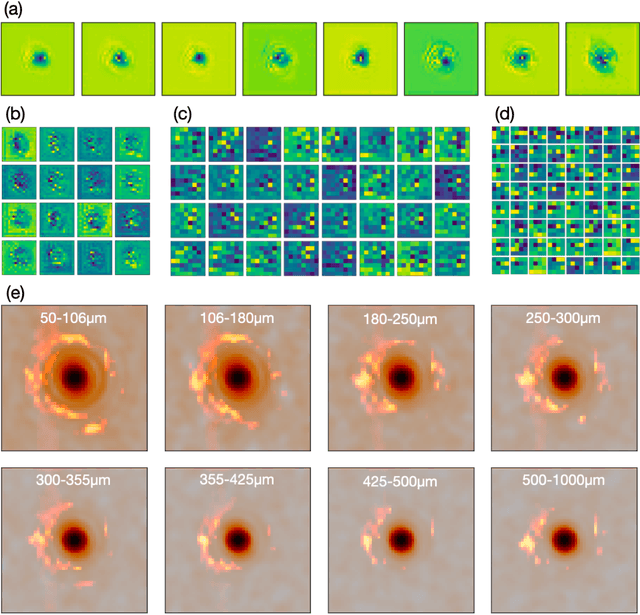
Extracting quantitative information about highly scattering surfaces from an imaging system is challenging because the phase of the scattered light undergoes multiple folds upon propagation, resulting in complex speckle patterns. One specific application is the drying of wet powders in the pharmaceutical industry, where quantifying the particle size distribution (PSD) is of particular interest. A non-invasive and real-time monitoring probe in the drying process is required, but there is no suitable candidate for this purpose. In this report, we develop a theoretical relationship from the PSD to the speckle image and describe a physics-enhanced autocorrelation-based estimator (PEACE) machine learning algorithm for speckle analysis to measure the PSD of a powder surface. This method solves both the forward and inverse problems together and enjoys increased interpretability, since the machine learning approximator is regularized by the physical law.
Neural Predictor for Black-Box Adversarial Attacks on Speech Recognition
Mar 18, 2022

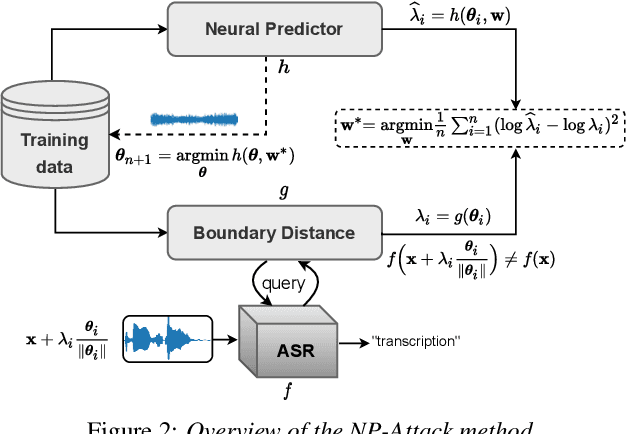
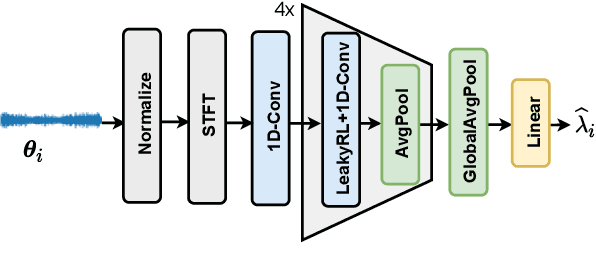
Recent works have revealed the vulnerability of automatic speech recognition (ASR) models to adversarial examples (AEs), i.e., small perturbations that cause an error in the transcription of the audio signal. Studying audio adversarial attacks is therefore the first step towards robust ASR. Despite the significant progress made in attacking audio examples, the black-box attack remains challenging because only the hard-label information of transcriptions is provided. Due to this limited information, existing black-box methods often require an excessive number of queries to attack a single audio example. In this paper, we introduce NP-Attack, a neural predictor-based method, which progressively evolves the search towards a small adversarial perturbation. Given a perturbation direction, our neural predictor directly estimates the smallest perturbation that causes a mistranscription. In particular, it enables NP-Attack to accurately learn promising perturbation directions via gradient-based optimization. Experimental results show that NP-Attack achieves competitive results with other state-of-the-art black-box adversarial attacks while requiring a significantly smaller number of queries. The code of NP-Attack is available online.
Object Class Aware Video Anomaly Detection through Image Translation
May 03, 2022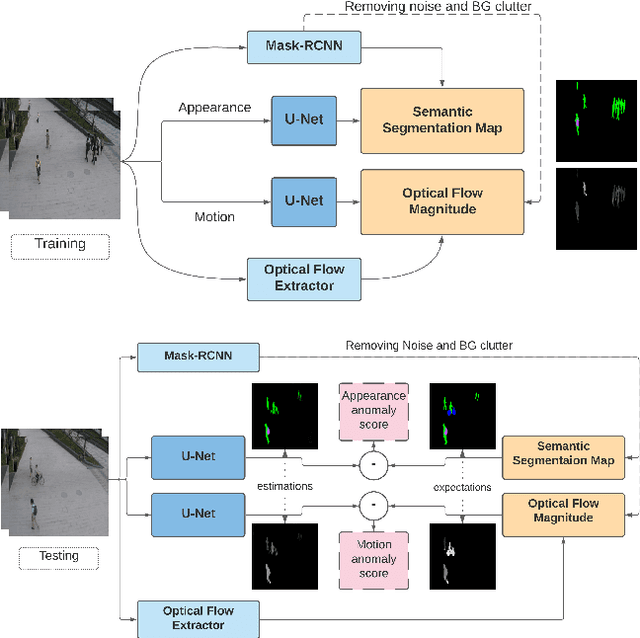
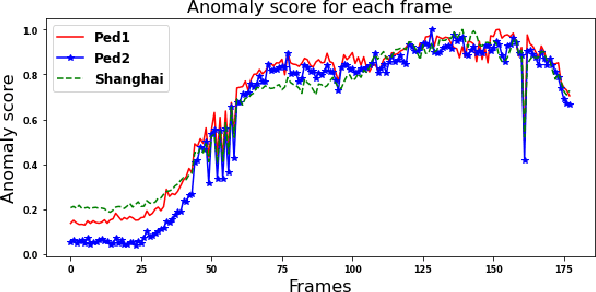
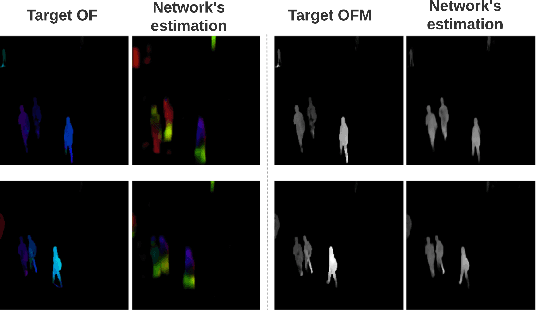
Semi-supervised video anomaly detection (VAD) methods formulate the task of anomaly detection as detection of deviations from the learned normal patterns. Previous works in the field (reconstruction or prediction-based methods) suffer from two drawbacks: 1) They focus on low-level features, and they (especially holistic approaches) do not effectively consider the object classes. 2) Object-centric approaches neglect some of the context information (such as location). To tackle these challenges, this paper proposes a novel two-stream object-aware VAD method that learns the normal appearance and motion patterns through image translation tasks. The appearance branch translates the input image to the target semantic segmentation map produced by Mask-RCNN, and the motion branch associates each frame with its expected optical flow magnitude. Any deviation from the expected appearance or motion in the inference stage shows the degree of potential abnormality. We evaluated our proposed method on the ShanghaiTech, UCSD-Ped1, and UCSD-Ped2 datasets and the results show competitive performance compared with state-of-the-art works. Most importantly, the results show that, as significant improvements to previous methods, detections by our method are completely explainable and anomalies are localized accurately in the frames.
MLP4Rec: A Pure MLP Architecture for Sequential Recommendations
Apr 25, 2022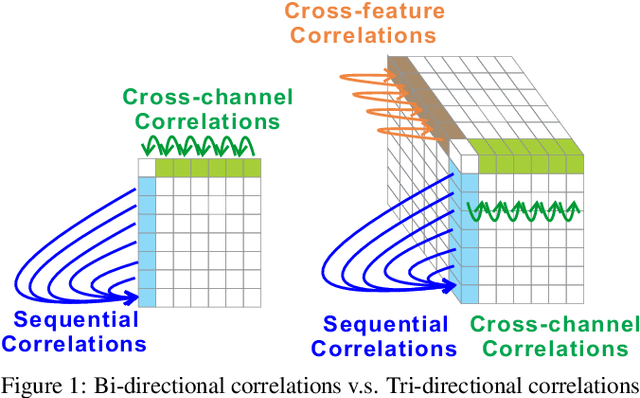
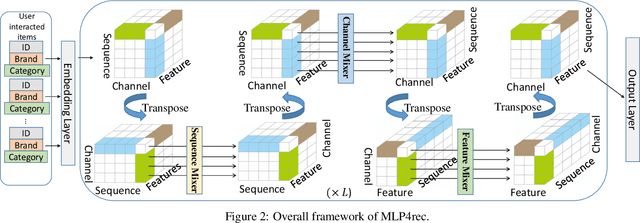
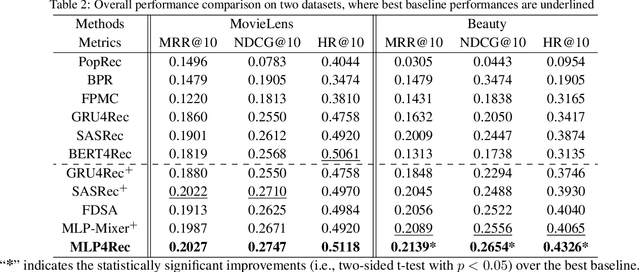
Self-attention models have achieved state-of-the-art performance in sequential recommender systems by capturing the sequential dependencies among user-item interactions. However, they rely on positional embeddings to retain the sequential information, which may break the semantics of item embeddings. In addition, most existing works assume that such sequential dependencies exist solely in the item embeddings, but neglect their existence among the item features. In this work, we propose a novel sequential recommender system (MLP4Rec) based on the recent advances of MLP-based architectures, which is naturally sensitive to the order of items in a sequence. To be specific, we develop a tri-directional fusion scheme to coherently capture sequential, cross-channel and cross-feature correlations. Extensive experiments demonstrate the effectiveness of MLP4Rec over various representative baselines upon two benchmark datasets. The simple architecture of MLP4Rec also leads to the linear computational complexity as well as much fewer model parameters than existing self-attention methods.