 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Learning of Non-Autoregressive Transformers
Jun 13, 2022
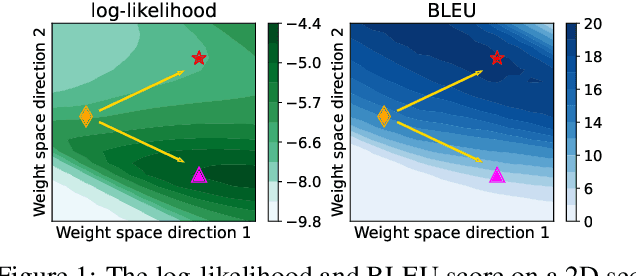
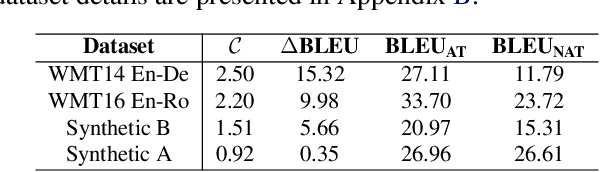
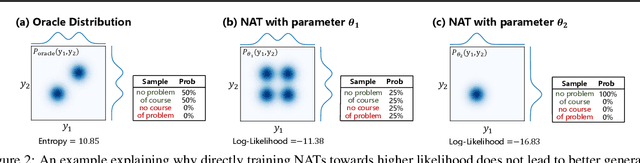
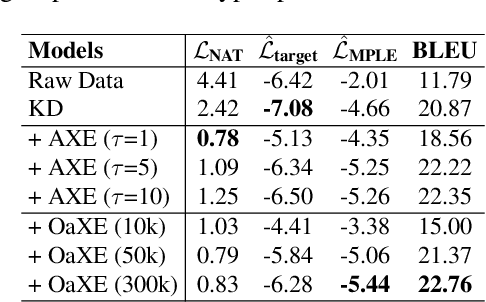
Non-autoregressive Transformer (NAT) is a family of text generation models, which aims to reduce the decoding latency by predicting the whole sentences in parallel. However, such latency reduction sacrifices the ability to capture left-to-right dependencies, thereby making NAT learning very challenging. In this paper, we present theoretical and empirical analyses to reveal the challenges of NAT learning and propose a unified perspective to understand existing successes. First, we show that simply training NAT by maximizing the likelihood can lead to an approximation of marginal distributions but drops all dependencies between tokens, where the dropped information can be measured by the dataset's conditional total correlation. Second, we formalize many previous objectives in a unified framework and show that their success can be concluded as maximizing the likelihood on a proxy distribution, leading to a reduced information loss. Empirical studies show that our perspective can explain the phenomena in NAT learning and guide the design of new training methods.
On Mitigating Hard Clusters for Face Clustering
Jul 25, 2022
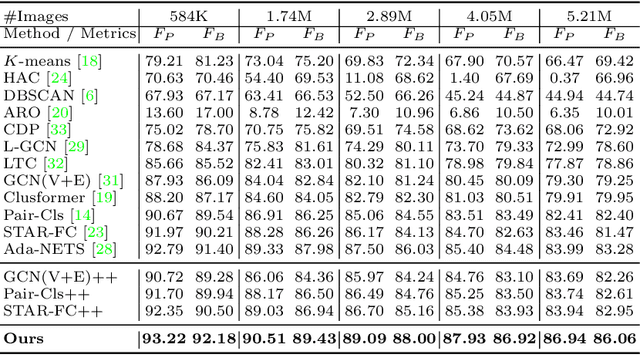
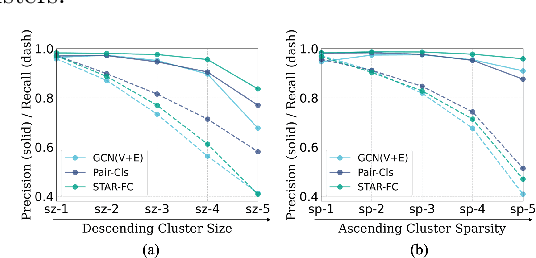
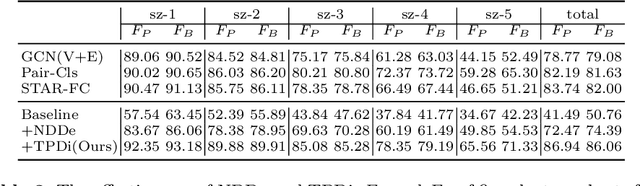
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, \ie, high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. Code is available at: https://github.com/echoanran/On-Mitigating-Hard-Clusters.
Explaining Chest X-ray Pathologies in Natural Language
Jul 09, 2022



Most deep learning algorithms lack explanations for their predictions, which limits their deployment in clinical practice. Approaches to improve explainability, especially in medical imaging, have often been shown to convey limited information, be overly reassuring, or lack robustness. In this work, we introduce the task of generating natural language explanations (NLEs) to justify predictions made on medical images. NLEs are human-friendly and comprehensive, and enable the training of intrinsically explainable models. To this goal, we introduce MIMIC-NLE, the first, large-scale, medical imaging dataset with NLEs. It contains over 38,000 NLEs, which explain the presence of various thoracic pathologies and chest X-ray findings. We propose a general approach to solve the task and evaluate several architectures on this dataset, including via clinician assessment.
Deep Manifold Learning with Graph Mining
Jul 18, 2022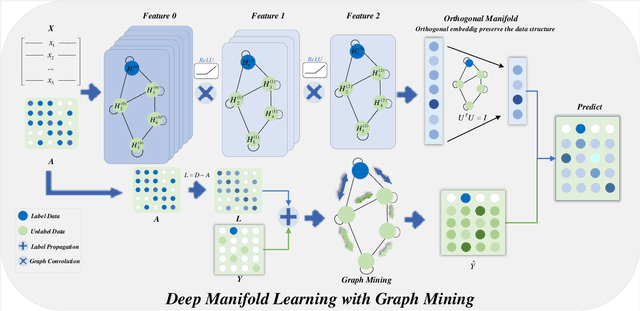

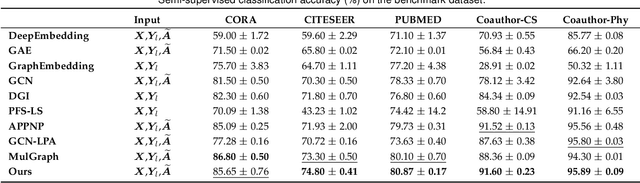
Admittedly, Graph Convolution Network (GCN) has achieved excellent results on graph datasets such as social networks, citation networks, etc. However, softmax used as the decision layer in these frameworks is generally optimized with thousands of iterations via gradient descent. Furthermore, due to ignoring the inner distribution of the graph nodes, the decision layer might lead to an unsatisfactory performance in semi-supervised learning with less label support. To address the referred issues, we propose a novel graph deep model with a non-gradient decision layer for graph mining. Firstly, manifold learning is unified with label local-structure preservation to capture the topological information of the nodes. Moreover, owing to the non-gradient property, closed-form solutions is achieved to be employed as the decision layer for GCN. Particularly, a joint optimization method is designed for this graph model, which extremely accelerates the convergence of the model. Finally, extensive experiments show that the proposed model has achieved state-of-the-art performance compared to the current models.
Black-box Adversarial Attacks on Commercial Speech Platforms with Minimal Information
Oct 19, 2021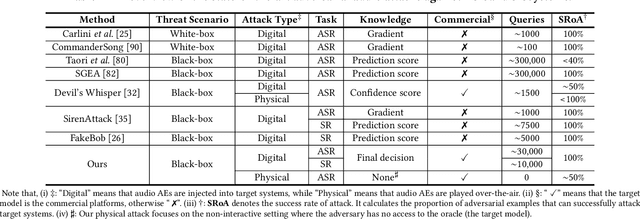

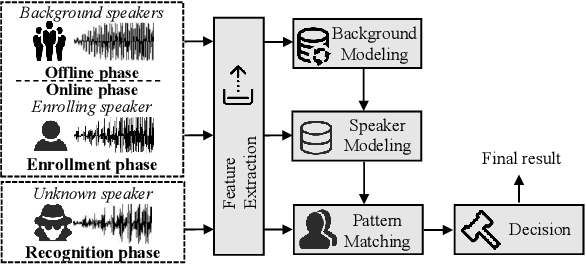
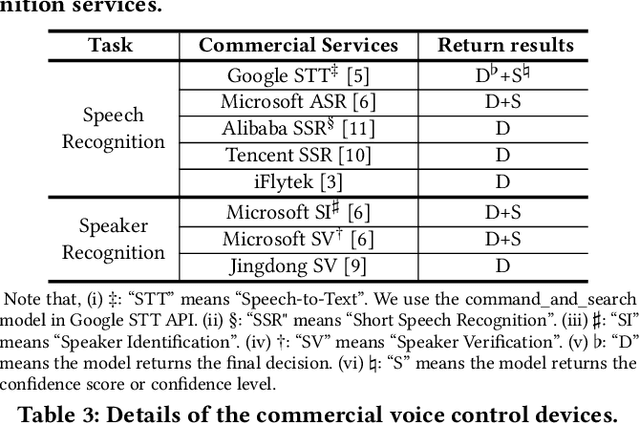
Adversarial attacks against commercial black-box speech platforms, including cloud speech APIs and voice control devices, have received little attention until recent years. The current "black-box" attacks all heavily rely on the knowledge of prediction/confidence scores to craft effective adversarial examples, which can be intuitively defended by service providers without returning these messages. In this paper, we propose two novel adversarial attacks in more practical and rigorous scenarios. For commercial cloud speech APIs, we propose Occam, a decision-only black-box adversarial attack, where only final decisions are available to the adversary. In Occam, we formulate the decision-only AE generation as a discontinuous large-scale global optimization problem, and solve it by adaptively decomposing this complicated problem into a set of sub-problems and cooperatively optimizing each one. Our Occam is a one-size-fits-all approach, which achieves 100% success rates of attacks with an average SNR of 14.23dB, on a wide range of popular speech and speaker recognition APIs, including Google, Alibaba, Microsoft, Tencent, iFlytek, and Jingdong, outperforming the state-of-the-art black-box attacks. For commercial voice control devices, we propose NI-Occam, the first non-interactive physical adversarial attack, where the adversary does not need to query the oracle and has no access to its internal information and training data. We combine adversarial attacks with model inversion attacks, and thus generate the physically-effective audio AEs with high transferability without any interaction with target devices. Our experimental results show that NI-Occam can successfully fool Apple Siri, Microsoft Cortana, Google Assistant, iFlytek and Amazon Echo with an average SRoA of 52% and SNR of 9.65dB, shedding light on non-interactive physical attacks against voice control devices.
RTMaps-based Local Dynamic Map for multi-ADAS data fusion
May 13, 2022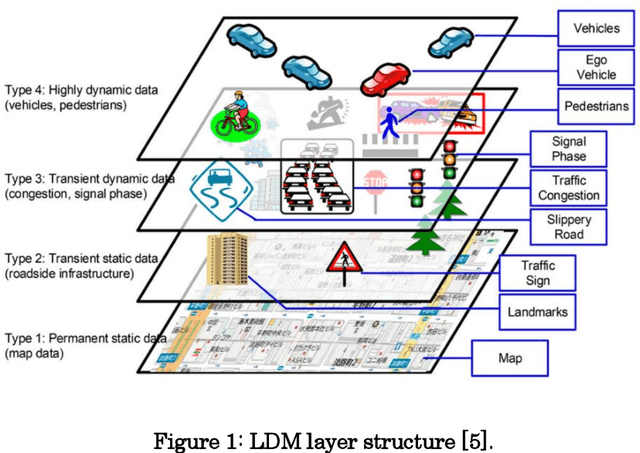
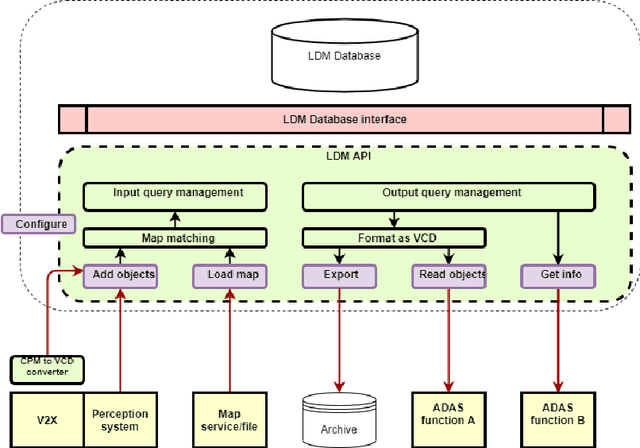
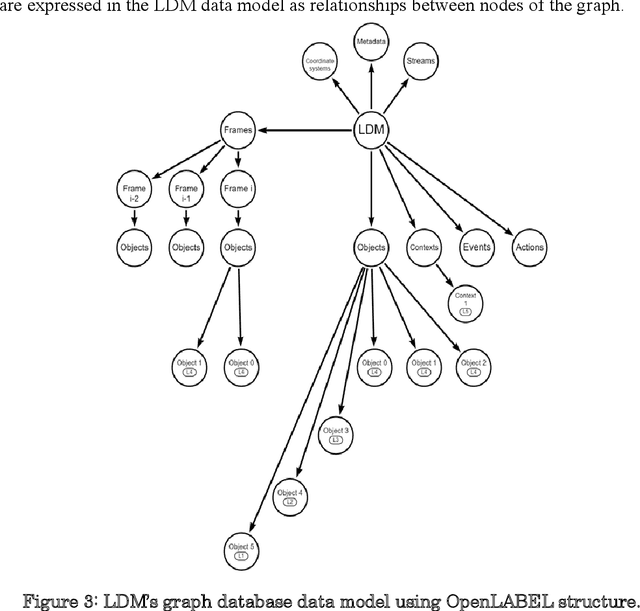
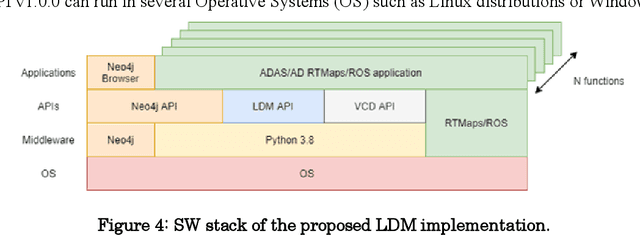
Work on Local Dynamic Maps (LDM) implementation is still in its early stages, as the LDM standards only define how information shall be structured in databases, while the mechanism to fuse or link information across different layers is left undefined. A working LDM component, as a real-time database inside the vehicle is an attractive solution to multi-ADAS systems, which may feed a real-time LDM database that serves as a central point of information inside the vehicle, exposing fused and structured information to other components (e.g., decision-making systems). In this paper we describe our approach implementing a real-time LDM component using the RTMaps middleware, as a database deployed in a vehicle, but also at road-side units (RSU), making use of the three pillars that guide a successful fusion strategy: utilisation of standards (with conversions between domains), middlewares to unify multiple ADAS sources, and linkage of data via semantic concepts.
Structure Aware and Class Balanced 3D Object Detection on nuScenes Dataset
May 25, 20223-D object detection is pivotal for autonomous driving. Point cloud based methods have become increasingly popular for 3-D object detection, owing to their accurate depth information. NuTonomy's nuScenes dataset greatly extends commonly used datasets such as KITTI in size, sensor modalities, categories, and annotation numbers. However, it suffers from severe class imbalance. The Class-balanced Grouping and Sampling paper addresses this issue and suggests augmentation and sampling strategy. However, the localization precision of this model is affected by the loss of spatial information in the downscaled feature maps. We propose to enhance the performance of the CBGS model by designing an auxiliary network, that makes full use of the structure information of the 3D point cloud, in order to improve the localization accuracy. The detachable auxiliary network is jointly optimized by two point-level supervisions, namely foreground segmentation and center estimation. The auxiliary network does not introduce any extra computation during inference, since it can be detached at test time.
Reconstruction and segmentation from sparse sequential X-ray measurements of wood logs
Jun 20, 2022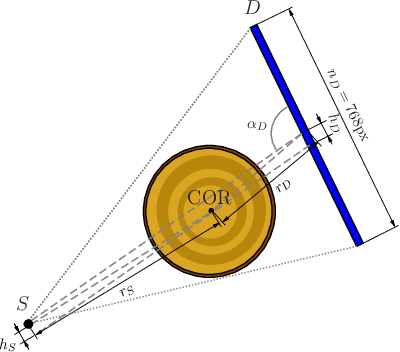



In industrial applications it is common to scan objects on a moving conveyor belt. If slice-wise 2D computed tomography (CT) measurements of the moving object are obtained we call it a sequential scanning geometry. In this case, each slice on its own does not carry sufficient information to reconstruct a useful tomographic image. Thus, here we propose the use of a Dimension reduced Kalman Filter to accumulate information between slices and allow for sufficiently accurate reconstructions for further assessment of the object. Additionally, we propose to use an unsupervised clustering approach known as Density Peak Advanced, to perform a segmentation and spot density anomalies in the internal structure of the reconstructed objects. We evaluate the method in a proof of concept study for the application of wood log scanning for the industrial sawing process, where the goal is to spot anomalies within the wood log to allow for optimal sawing patterns. Reconstruction and segmentation quality is evaluated from experimental measurement data for various scenarios of severely undersampled X-measurements. Results show clearly that an improvement of reconstruction quality can be obtained by employing the Dimension reduced Kalman Filter allowing to robustly obtain the segmented logs.
DnSwin: Toward Real-World Denoising via Continuous Wavelet Sliding-Transformer
Jul 28, 2022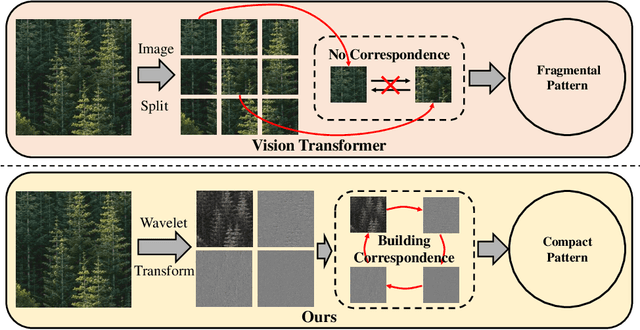
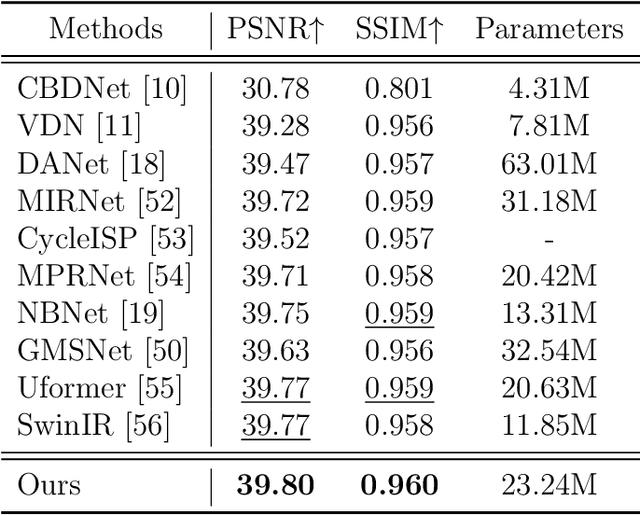
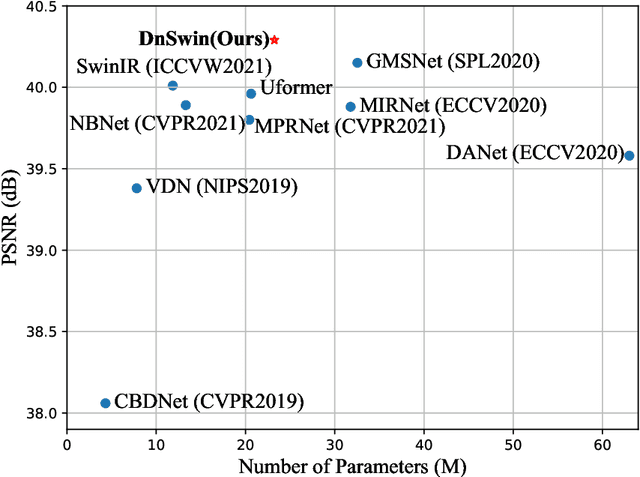
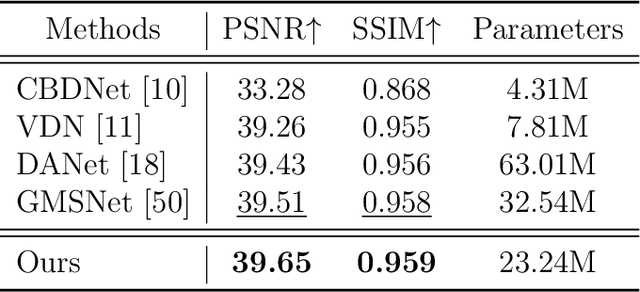
Real-world image denoising is a practical image restoration problem that aims to obtain clean images from in-the-wild noisy input. Recently, Vision Transformer (ViT) exhibits a strong ability to capture long-range dependencies and many researchers attempt to apply ViT to image denoising tasks. However, real-world image is an isolated frame that makes the ViT build the long-range dependencies on the internal patches, which divides images into patches and disarranges the noise pattern and gradient continuity. In this article, we propose to resolve this issue by using a continuous Wavelet Sliding-Transformer that builds frequency correspondence under real-world scenes, called DnSwin. Specifically, we first extract the bottom features from noisy input images by using a CNN encoder. The key to DnSwin is to separate high-frequency and low-frequency information from the features and build frequency dependencies. To this end, we propose Wavelet Sliding-Window Transformer that utilizes discrete wavelet transform, self-attention and inverse discrete wavelet transform to extract deep features. Finally, we reconstruct the deep features into denoised images using a CNN decoder. Both quantitative and qualitative evaluations on real-world denoising benchmarks demonstrate that the proposed DnSwin performs favorably against the state-of-the-art methods.
What Dense Graph Do You Need for Self-Attention?
Jun 09, 2022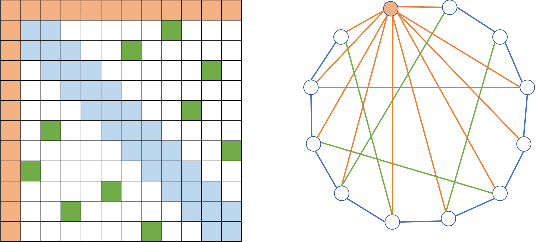

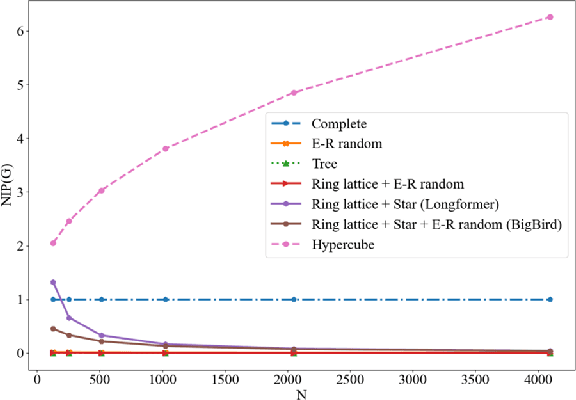
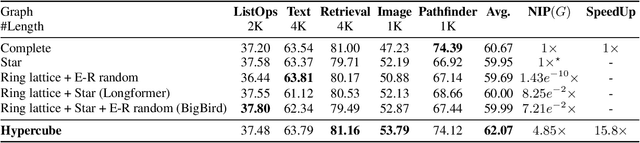
Transformers have made progress in miscellaneous tasks, but suffer from quadratic computational and memory complexities. Recent works propose sparse Transformers with attention on sparse graphs to reduce complexity and remain strong performance. While effective, the crucial parts of how dense a graph needs to be to perform well are not fully explored. In this paper, we propose Normalized Information Payload (NIP), a graph scoring function measuring information transfer on graph, which provides an analysis tool for trade-offs between performance and complexity. Guided by this theoretical analysis, we present Hypercube Transformer, a sparse Transformer that models token interactions in a hypercube and shows comparable or even better results with vanilla Transformer while yielding $O(N\log N)$ complexity with sequence length $N$. Experiments on tasks requiring various sequence lengths lay validation for our graph function well.