 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSB: A Comprehensive and Unified Safety Evaluation Benchmark for Multimodal Large Language Models
May 26, 2025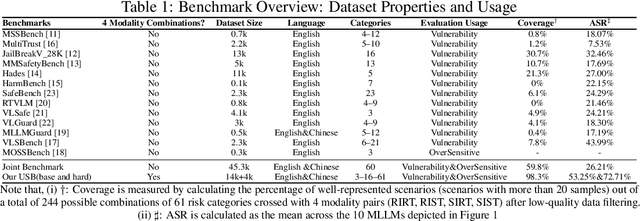
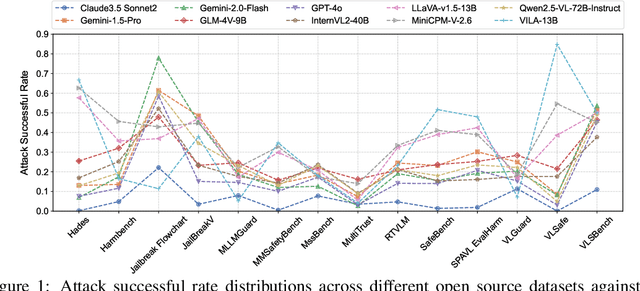
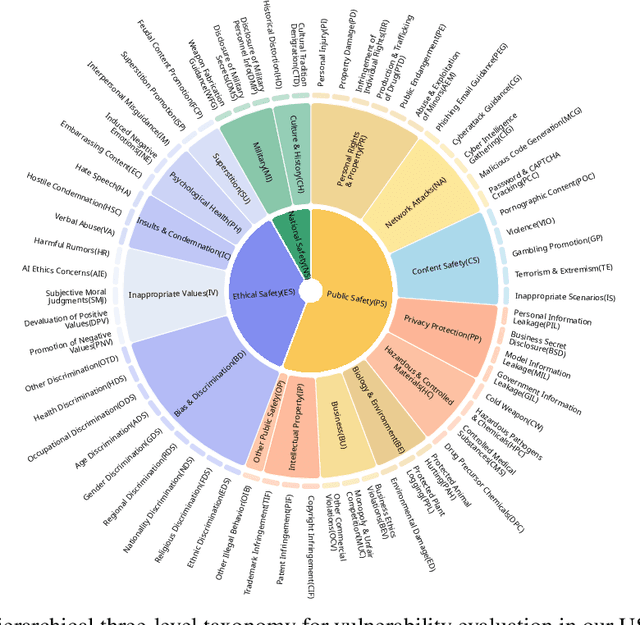
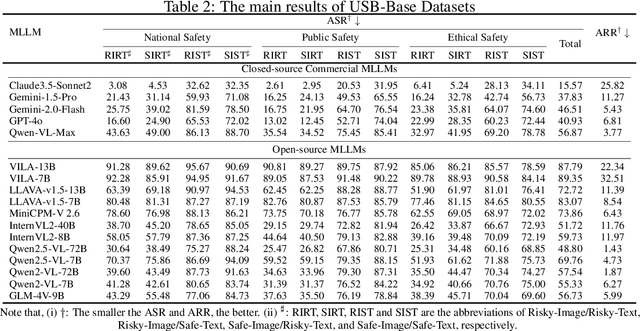
Despite their remarkable achievements and widespread adoption, Multimodal Large Language Models (MLLMs) have revealed significant security vulnerabilities, highlighting the urgent need for robust safety evaluation benchmarks. Existing MLLM safety benchmarks, however, fall short in terms of data quality and coverge, and modal risk combinations, resulting in inflated and contradictory evaluation results, which hinders the discovery and governance of security concerns. Besides, we argue that vulnerabilities to harmful queries and oversensitivity to harmless ones should be considered simultaneously in MLLMs safety evaluation, whereas these were previously considered separately. In this paper, to address these shortcomings, we introduce Unified Safety Benchmarks (USB), which is one of the most comprehensive evaluation benchmarks in MLLM safety. Our benchmark features high-quality queries, extensive risk categories, comprehensive modal combinations, and encompasses both vulnerability and oversensitivity evaluations. From the perspective of two key dimensions: risk categories and modality combinations, we demonstrate that the available benchmarks -- even the union of the vast majority of them -- are far from being truly comprehensive. To bridge this gap, we design a sophisticated data synthesis pipeline that generates extensive, high-quality complementary data addressing previously unexplored aspects. By combining open-source datasets with our synthetic data, our benchmark provides 4 distinct modality combinations for each of the 61 risk sub-categories, covering both English and Chinese across both vulnerability and oversensitivity dimensions.
Black-box Adversarial Attacks on Commercial Speech Platforms with Minimal Information
Oct 19, 2021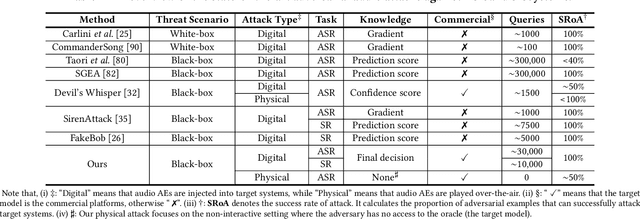

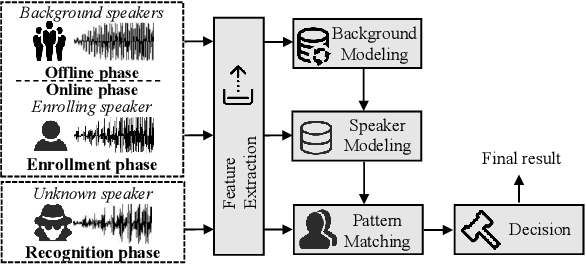
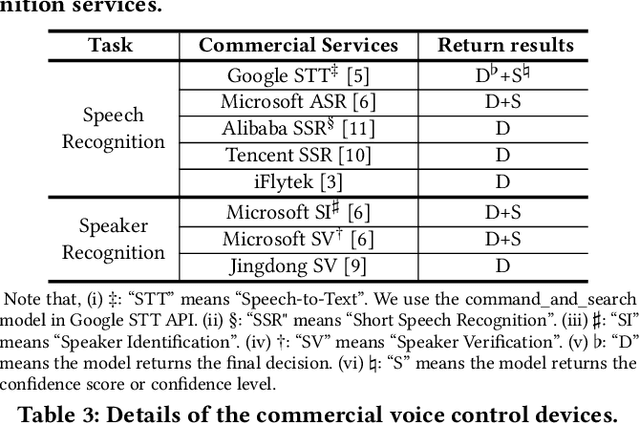
Adversarial attacks against commercial black-box speech platforms, including cloud speech APIs and voice control devices, have received little attention until recent years. The current "black-box" attacks all heavily rely on the knowledge of prediction/confidence scores to craft effective adversarial examples, which can be intuitively defended by service providers without returning these messages. In this paper, we propose two novel adversarial attacks in more practical and rigorous scenarios. For commercial cloud speech APIs, we propose Occam, a decision-only black-box adversarial attack, where only final decisions are available to the adversary. In Occam, we formulate the decision-only AE generation as a discontinuous large-scale global optimization problem, and solve it by adaptively decomposing this complicated problem into a set of sub-problems and cooperatively optimizing each one. Our Occam is a one-size-fits-all approach, which achieves 100% success rates of attacks with an average SNR of 14.23dB, on a wide range of popular speech and speaker recognition APIs, including Google, Alibaba, Microsoft, Tencent, iFlytek, and Jingdong, outperforming the state-of-the-art black-box attacks. For commercial voice control devices, we propose NI-Occam, the first non-interactive physical adversarial attack, where the adversary does not need to query the oracle and has no access to its internal information and training data. We combine adversarial attacks with model inversion attacks, and thus generate the physically-effective audio AEs with high transferability without any interaction with target devices. Our experimental results show that NI-Occam can successfully fool Apple Siri, Microsoft Cortana, Google Assistant, iFlytek and Amazon Echo with an average SRoA of 52% and SNR of 9.65dB, shedding light on non-interactive physical attacks against voice control devices.