 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TF-GridNet: Making Time-Frequency Domain Models Great Again for Monaural Speaker Separation
Sep 08, 2022
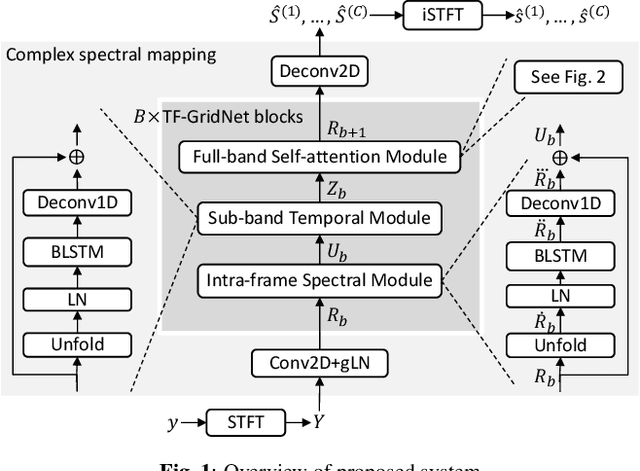
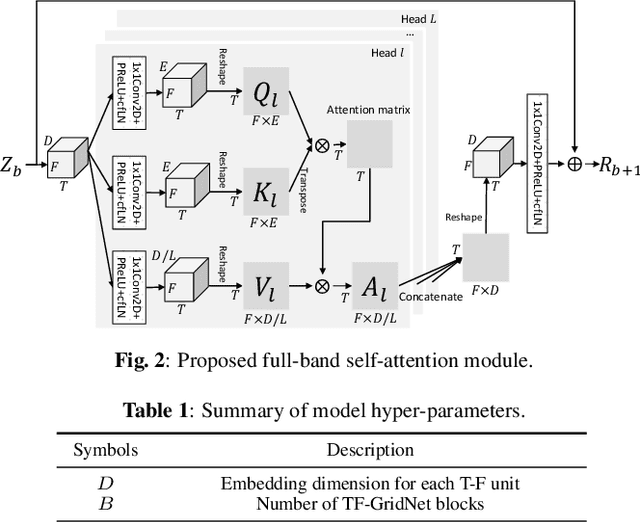


We propose TF-GridNet, a novel multi-path deep neural network (DNN) operating in the time-frequency (T-F) domain, for monaural talker-independent speaker separation in anechoic conditions. The model stacks several multi-path blocks, each consisting of an intra-frame spectral module, a sub-band temporal module, and a full-band self-attention module, to leverage local and global spectro-temporal information for separation. The model is trained to perform complex spectral mapping, where the real and imaginary (RI) components of the input mixture are stacked as input features to predict the target RI components. Besides using the scale-invariant signal-to-distortion ratio (SI-SDR) loss for model training, we include a novel loss term to encourage the separated sources to add up to the input mixture. Without using dynamic mixing, we obtain 23.4 dB SI-SDR improvement (SI-SDRi) on the WSJ0-2mix dataset, outperforming the previous best by a large margin.
Time-lapse image classification using a diffractive neural network
Aug 23, 2022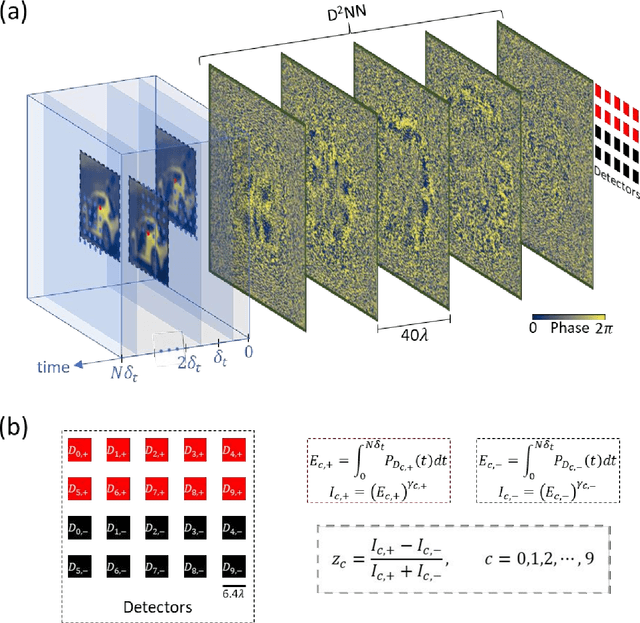
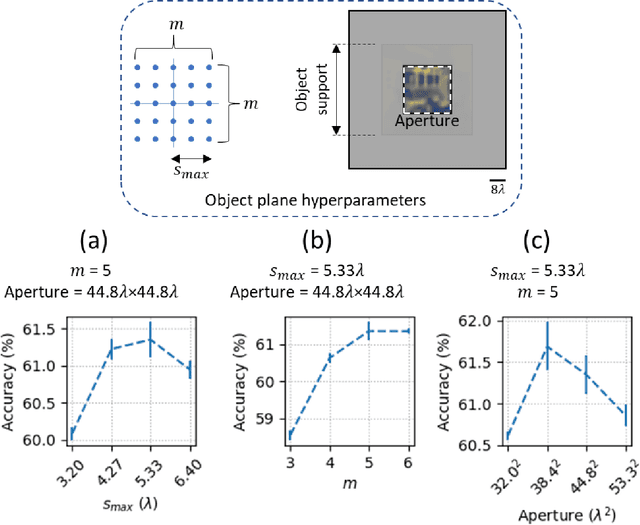
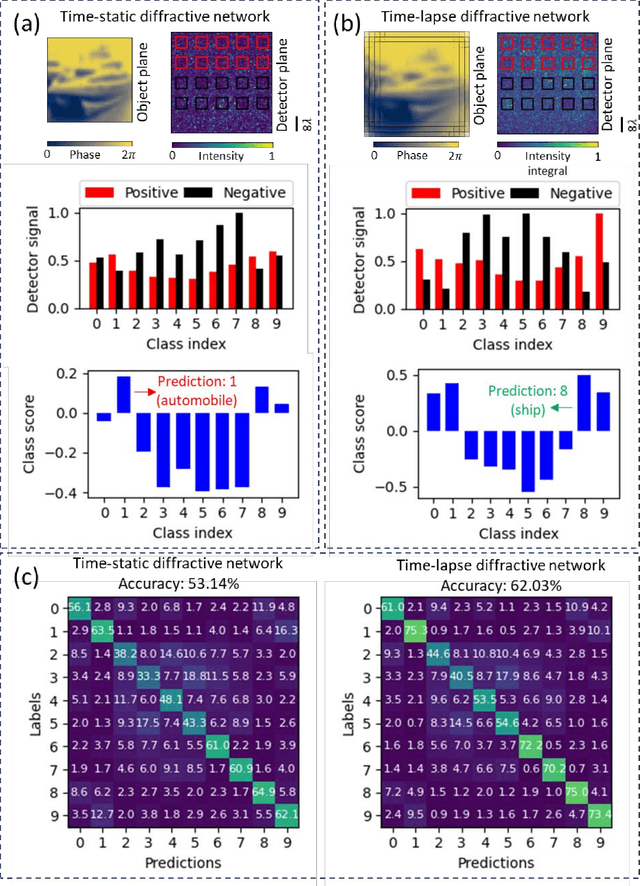
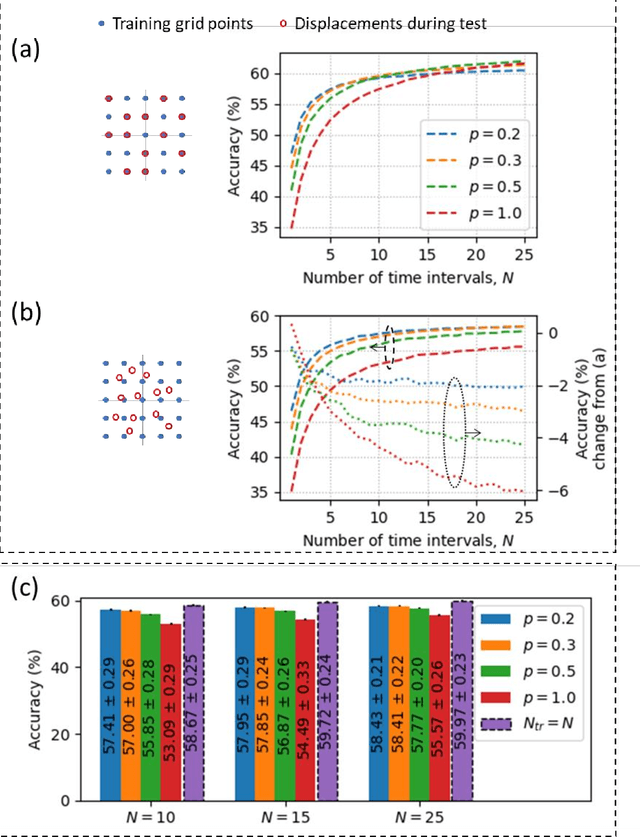
Diffractive deep neural networks (D2NNs) define an all-optical computing framework comprised of spatially engineered passive surfaces that collectively process optical input information by modulating the amplitude and/or the phase of the propagating light. Diffractive optical networks complete their computational tasks at the speed of light propagation through a thin diffractive volume, without any external computing power while exploiting the massive parallelism of optics. Diffractive networks were demonstrated to achieve all-optical classification of objects and perform universal linear transformations. Here we demonstrate, for the first time, a "time-lapse" image classification scheme using a diffractive network, significantly advancing its classification accuracy and generalization performance on complex input objects by using the lateral movements of the input objects and/or the diffractive network, relative to each other. In a different context, such relative movements of the objects and/or the camera are routinely being used for image super-resolution applications; inspired by their success, we designed a time-lapse diffractive network to benefit from the complementary information content created by controlled or random lateral shifts. We numerically explored the design space and performance limits of time-lapse diffractive networks, revealing a blind testing accuracy of 62.03% on the optical classification of objects from the CIFAR-10 dataset. This constitutes the highest inference accuracy achieved so far using a single diffractive network on the CIFAR-10 dataset. Time-lapse diffractive networks will be broadly useful for the spatio-temporal analysis of input signals using all-optical processors.
Legal Case Document Similarity: You Need Both Network and Text
Sep 26, 2022
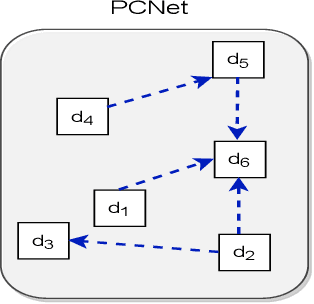

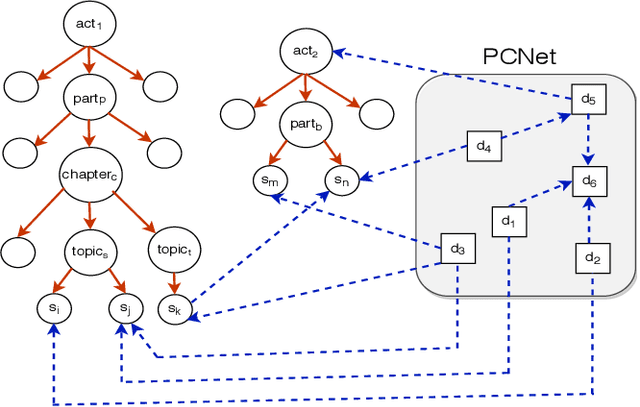
Estimating the similarity between two legal case documents is an important and challenging problem, having various downstream applications such as prior-case retrieval and citation recommendation. There are two broad approaches for the task -- citation network-based and text-based. Prior citation network-based approaches consider citations only to prior-cases (also called precedents) (PCNet). This approach misses important signals inherent in Statutes (written laws of a jurisdiction). In this work, we propose Hier-SPCNet that augments PCNet with a heterogeneous network of Statutes. We incorporate domain knowledge for legal document similarity into Hier-SPCNet, thereby obtaining state-of-the-art results for network-based legal document similarity. Both textual and network similarity provide important signals for legal case similarity; but till now, only trivial attempts have been made to unify the two signals. In this work, we apply several methods for combining textual and network information for estimating legal case similarity. We perform extensive experiments over legal case documents from the Indian judiciary, where the gold standard similarity between document-pairs is judged by law experts from two reputed Law institutes in India. Our experiments establish that our proposed network-based methods significantly improve the correlation with domain experts' opinion when compared to the existing methods for network-based legal document similarity. Our best-performing combination method (that combines network-based and text-based similarity) improves the correlation with domain experts' opinion by 11.8% over the best text-based method and 20.6\% over the best network-based method. We also establish that our best-performing method can be used to recommend / retrieve citable and similar cases for a source (query) case, which are well appreciated by legal experts.
A Multi-scale Video Denoising Algorithm for Raw Image
Sep 05, 2022
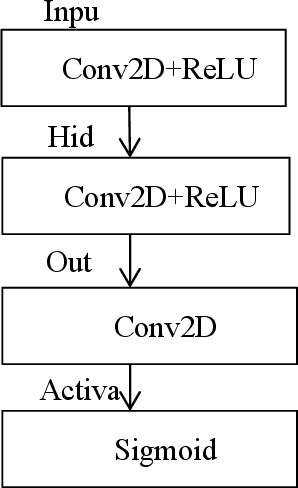
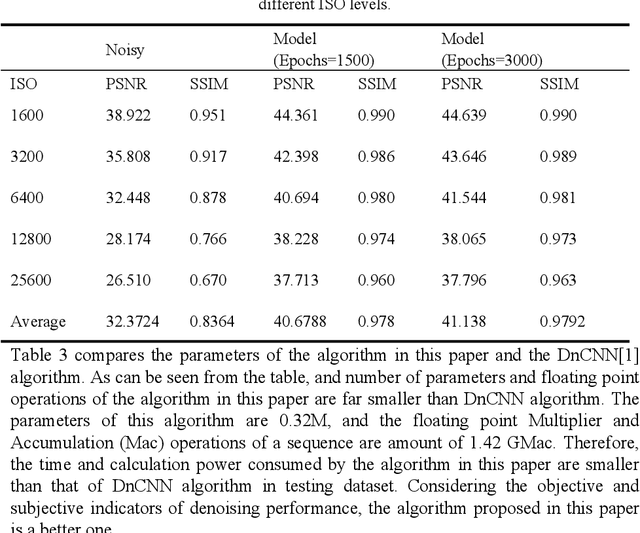
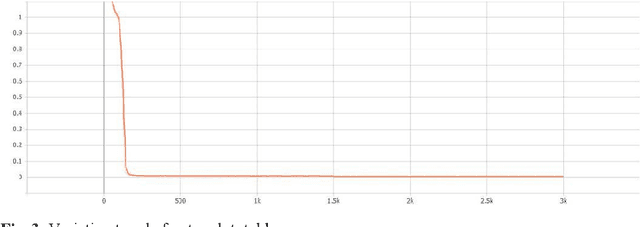
Video denoising for raw image has always been the difficulty of camera image processing. On the one hand, image denoising performance largely determines the image quality, moreover denoising effect in raw image will affect the accuracy of the following operations of ISP processing flow. On the other hand, compared with image, video have motion information in time sequence, thus motion estimation which is complex and computationally expensive is needed in video denoising. In view of the above problems, this paper proposes a video denoising algorithm for raw image, performing multiple cascading processing stages on raw-RGB image based on convolutional neural network, and carries out implicit motion estimation in the network. The denoising performance is far superior to that of traditional algorithms with minimal computation and bandwidth, and has computational advantages compared with most deep learning algorithms.
MM-GNN: Mix-Moment Graph Neural Network towards Modeling Neighborhood Feature Distribution
Aug 15, 2022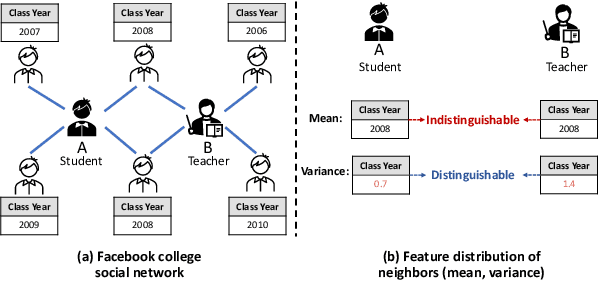

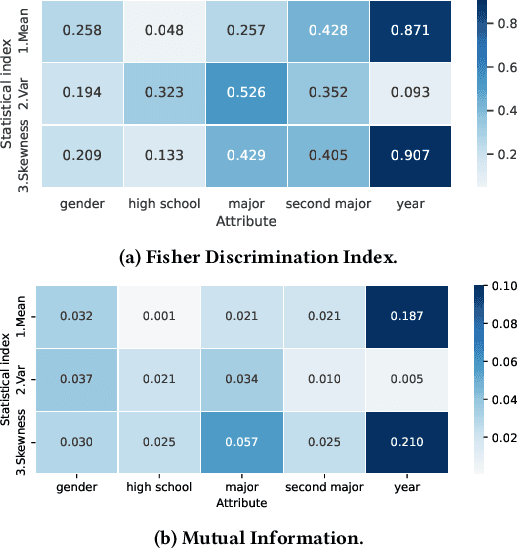
Graph Neural Networks (GNNs) have shown expressive performance on graph representation learning by aggregating information from neighbors. Recently, some studies have discussed the importance of modeling neighborhood distribution on the graph. However, most existing GNNs aggregate neighbors' features through single statistic (e.g., mean, max, sum), which loses the information related to neighbor's feature distribution and therefore degrades the model performance. In this paper, inspired by the method of moment in statistical theory, we propose to model neighbor's feature distribution with multi-order moments. We design a novel GNN model, namely Mix-Moment Graph Neural Network (MM-GNN), which includes a Multi-order Moment Embedding (MME) module and an Element-wise Attention-based Moment Adaptor module. MM-GNN first calculates the multi-order moments of the neighbors for each node as signatures, and then use an Element-wise Attention-based Moment Adaptor to assign larger weights to important moments for each node and update node representations. We conduct extensive experiments on 15 real-world graphs (including social networks, citation networks and web-page networks etc.) to evaluate our model, and the results demonstrate the superiority of MM-GNN over existing state-of-the-art models.
Multilingual ColBERT-X
Sep 03, 2022
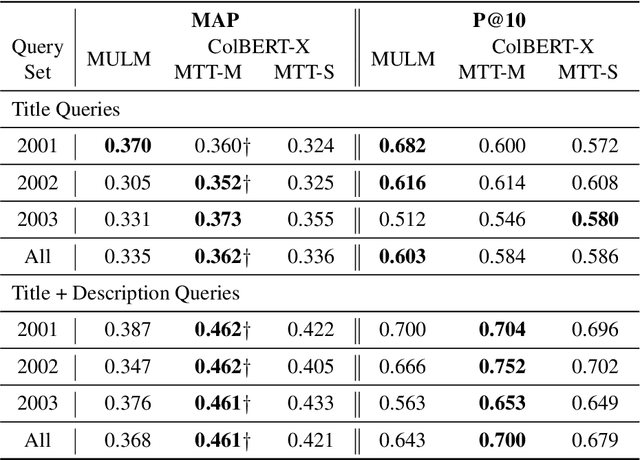
ColBERT-X is a dense retrieval model for Cross Language Information Retrieval (CLIR). In CLIR, documents are written in one natural language, while the queries are expressed in another. A related task is multilingual IR (MLIR) where the system creates a single ranked list of documents written in many languages. Given that ColBERT-X relies on a pretrained multilingual neural language model to rank documents, a multilingual training procedure can enable a version of ColBERT-X well-suited for MLIR. This paper describes that training procedure. An important factor for good MLIR ranking is fine-tuning XLM-R using mixed-language batches, where the same query is matched with documents in different languages in the same batch. Neural machine translations of MS MARCO passages are used to fine-tune the model.
Dense Cross-Query-and-Support Attention Weighted Mask Aggregation for Few-Shot Segmentation
Jul 18, 2022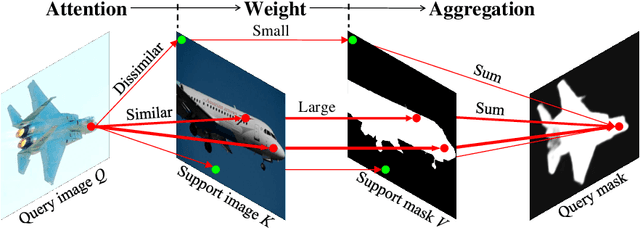
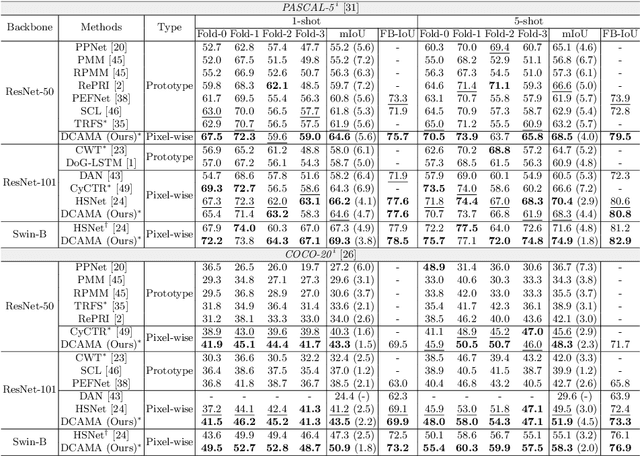
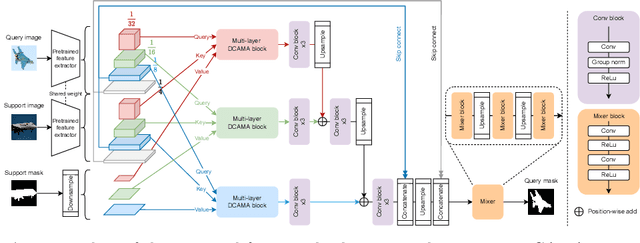
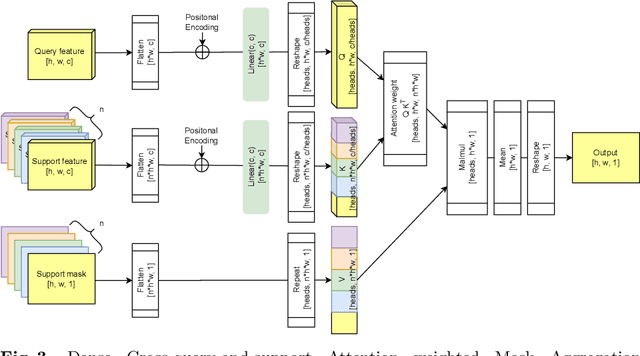
Research into Few-shot Semantic Segmentation (FSS) has attracted great attention, with the goal to segment target objects in a query image given only a few annotated support images of the target class. A key to this challenging task is to fully utilize the information in the support images by exploiting fine-grained correlations between the query and support images. However, most existing approaches either compressed the support information into a few class-wise prototypes, or used partial support information (e.g., only foreground) at the pixel level, causing non-negligible information loss. In this paper, we propose Dense pixel-wise Cross-query-and-support Attention weighted Mask Aggregation (DCAMA), where both foreground and background support information are fully exploited via multi-level pixel-wise correlations between paired query and support features. Implemented with the scaled dot-product attention in the Transformer architecture, DCAMA treats every query pixel as a token, computes its similarities with all support pixels, and predicts its segmentation label as an additive aggregation of all the support pixels' labels -- weighted by the similarities. Based on the unique formulation of DCAMA, we further propose efficient and effective one-pass inference for n-shot segmentation, where pixels of all support images are collected for the mask aggregation at once. Experiments show that our DCAMA significantly advances the state of the art on standard FSS benchmarks of PASCAL-5i, COCO-20i, and FSS-1000, e.g., with 3.1%, 9.7%, and 3.6% absolute improvements in 1-shot mIoU over previous best records. Ablative studies also verify the design DCAMA.
DPAUC: Differentially Private AUC Computation in Federated Learning
Aug 25, 2022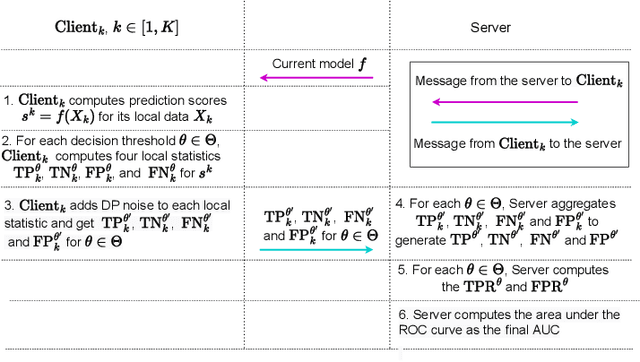

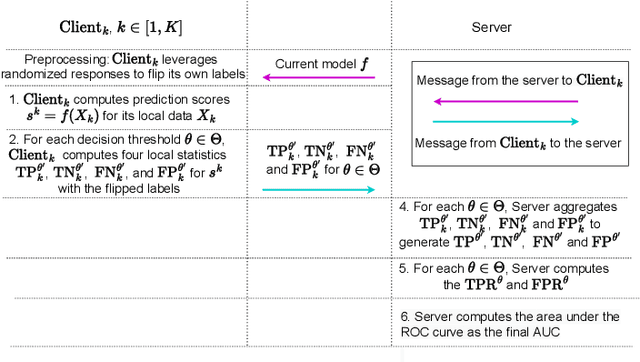
Federated learning (FL) has gained significant attention recently as a privacy-enhancing tool to jointly train a machine learning model by multiple participants. The prior work on FL has mostly studied how to protect label privacy during model training. However, model evaluation in FL might also lead to potential leakage of private label information. In this work, we propose an evaluation algorithm that can accurately compute the widely used AUC (area under the curve) metric when using the label differential privacy (DP) in FL. Through extensive experiments, we show our algorithms can compute accurate AUCs compared to the ground truth.
Structure Regularized Attentive Network for Automatic Femoral Head Necrosis Diagnosis and Localization
Aug 23, 2022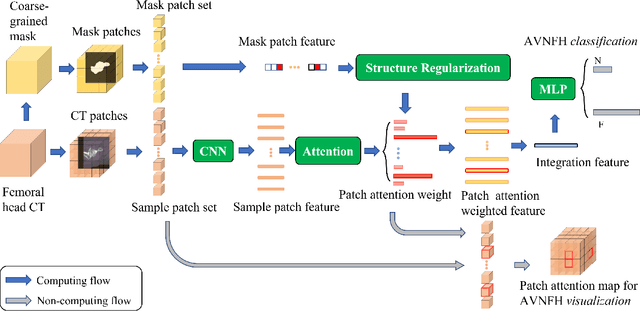
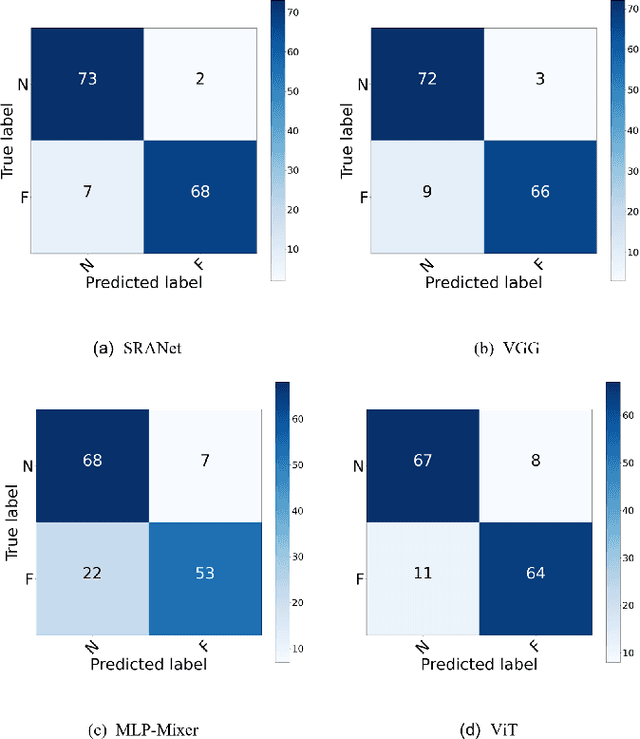
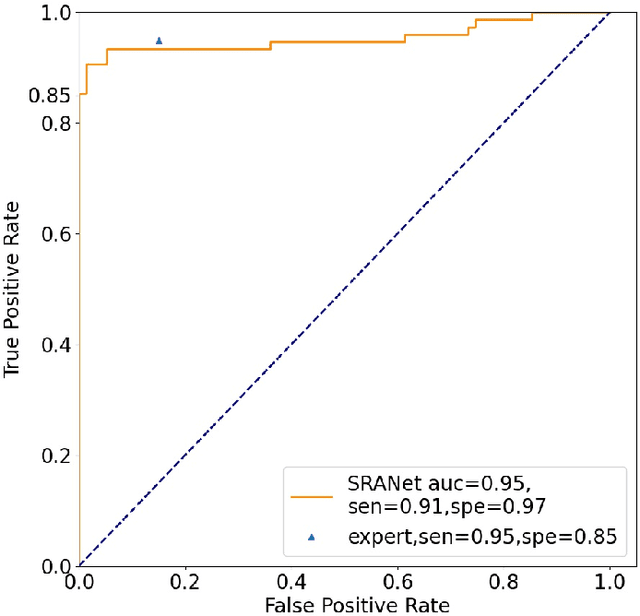
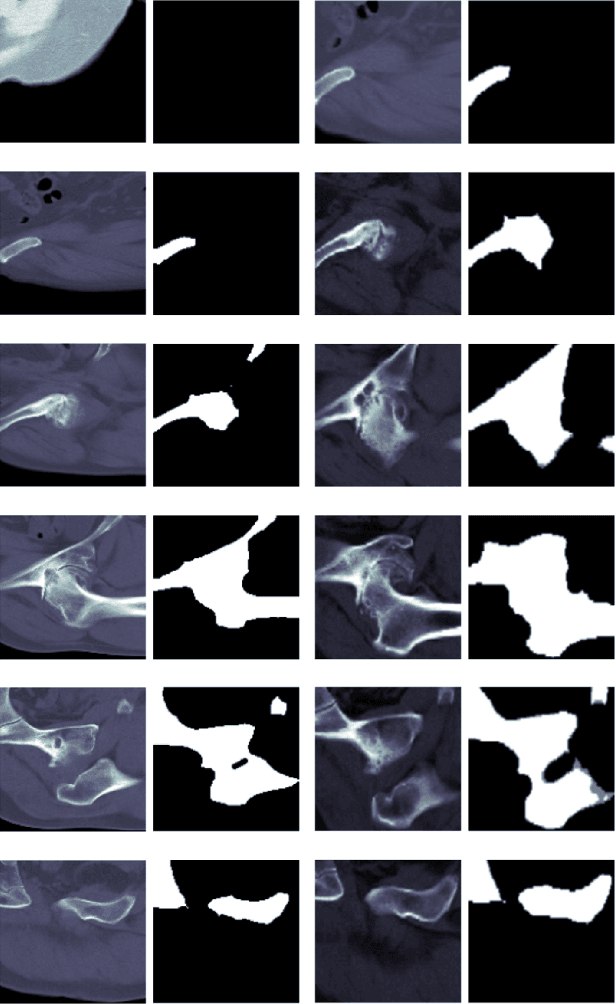
In recent years, several works have adopted the convolutional neural network (CNN) to diagnose the avascular necrosis of the femoral head (AVNFH) based on X-ray images or magnetic resonance imaging (MRI). However, due to the tissue overlap, X-ray images are difficult to provide fine-grained features for early diagnosis. MRI, on the other hand, has a long imaging time, is more expensive, making it impractical in mass screening. Computed tomography (CT) shows layer-wise tissues, is faster to image, and is less costly than MRI. However, to our knowledge, there is no work on CT-based automated diagnosis of AVNFH. In this work, we collected and labeled a large-scale dataset for AVNFH ranking. In addition, existing end-to-end CNNs only yields the classification result and are difficult to provide more information for doctors in diagnosis. To address this issue, we propose the structure regularized attentive network (SRANet), which is able to highlight the necrotic regions during classification based on patch attention. SRANet extracts features in chunks of images, obtains weight via the attention mechanism to aggregate the features, and constrains them by a structural regularizer with prior knowledge to improve the generalization. SRANet was evaluated on our AVNFH-CT dataset. Experimental results show that SRANet is superior to CNNs for AVNFH classification, moreover, it can localize lesions and provide more information to assist doctors in diagnosis. Our codes are made public at https://github.com/tomas-lilingfeng/SRANet.
Spiral Contrastive Learning: An Efficient 3D Representation Learning Method for Unannotated CT Lesions
Aug 23, 2022



Computed tomography (CT) samples with pathological annotations are difficult to obtain. As a result, the computer-aided diagnosis (CAD) algorithms are trained on small datasets (e.g., LIDC-IDRI with 1,018 samples), limiting their accuracies and reliability. In the past five years, several works have tailored for unsupervised representations of CT lesions via two-dimensional (2D) and three-dimensional (3D) self-supervised learning (SSL) algorithms. The 2D algorithms have difficulty capturing 3D information, and existing 3D algorithms are computationally heavy. Light-weight 3D SSL remains the boundary to explore. In this paper, we propose the spiral contrastive learning (SCL), which yields 3D representations in a computationally efficient manner. SCL first transforms 3D lesions to the 2D plane using an information-preserving spiral transformation, and then learn transformation-invariant features using 2D contrastive learning. For the augmentation, we consider natural image augmentations and medical image augmentations. We evaluate SCL by training a classification head upon the embedding layer. Experimental results show that SCL achieves state-of-the-art accuracy on LIDC-IDRI (89.72%), LNDb (82.09%) and TianChi (90.16%) for unsupervised representation learning. With 10% annotated data for fine-tune, the performance of SCL is comparable to that of supervised learning algorithms (85.75% vs. 85.03% on LIDC-IDRI, 78.20% vs. 73.44% on LNDb and 87.85% vs. 83.34% on TianChi, respectively). Meanwhile, SCL reduces the computational effort by 66.98% compared to other 3D SSL algorithms, demonstrating the efficiency of the proposed method in unsupervised pre-training.