 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTT: Augmented Reverberant-Target Training for Unsupervised Monaural Speech Dereverberation
Mar 19, 2026Due to the absence of clean reference signals and spatial cues, monaural unsupervised speech dereverberation is a challenging ill-posed inverse problem. To realize it, we propose augmented reverberant-target training (ARTT), which consists of two stages. In the first stage, reverberant-target training (RTT) is proposed to first further reverberate the observed reverberant mixture signal, and then train a deep neural network (DNN) to recover the observed reverberant mixture via discriminative training. Although the target signal to fit is reverberant, we find that the resulting DNN can effectively reduce reverberation. In the second stage, an online self-distillation mechanism based on the mean-teacher algorithm is proposed to further improve dereverberation. Evaluation results demonstrate that ARTT achieves strong unsupervised dereverberation performance, significantly outperforming previous baselines.
ARiSE: Auto-Regressive Multi-Channel Speech Enhancement
May 28, 2025We propose ARiSE, an auto-regressive algorithm for multi-channel speech enhancement. ARiSE improves existing deep neural network (DNN) based frame-online multi-channel speech enhancement models by introducing auto-regressive connections, where the estimated target speech at previous frames is leveraged as extra input features to help the DNN estimate the target speech at the current frame. The extra input features can be derived from (a) the estimated target speech in previous frames; and (b) a beamformed mixture with the beamformer computed based on the previous estimated target speech. On the other hand, naively training the DNN in an auto-regressive manner is very slow. To deal with this, we propose a parallel training mechanism to speed up the training. Evaluation results in noisy-reverberant conditions show the effectiveness and potential of the proposed algorithms.
Multi-Channel Acoustic Echo Cancellation Based on Direction-of-Arrival Estimation
May 26, 2025Acoustic echo cancellation (AEC) is an important speech signal processing technology that can remove echoes from microphone signals to enable natural-sounding full-duplex speech communication. While single-channel AEC is widely adopted, multi-channel AEC can leverage spatial cues afforded by multiple microphones to achieve better performance. Existing multi-channel AEC approaches typically combine beamforming with deep neural networks (DNN). This work proposes a two-stage algorithm that enhances multi-channel AEC by incorporating sound source directional cues. Specifically, a lightweight DNN is first trained to predict the sound source directions, and then the predicted directional information, multi-channel microphone signals, and single-channel far-end signal are jointly fed into an AEC network to estimate the near-end signal. Evaluation results show that the proposed algorithm outperforms baseline approaches and exhibits robust generalization across diverse acoustic environments.
ArrayDPS: Unsupervised Blind Speech Separation with a Diffusion Prior
May 17, 2025



Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
Unsupervised Blind Speech Separation with a Diffusion Prior
May 08, 2025Blind Speech Separation (BSS) aims to separate multiple speech sources from audio mixtures recorded by a microphone array. The problem is challenging because it is a blind inverse problem, i.e., the microphone array geometry, the room impulse response (RIR), and the speech sources, are all unknown. We propose ArrayDPS to solve the BSS problem in an unsupervised, array-agnostic, and generative manner. The core idea builds on diffusion posterior sampling (DPS), but unlike DPS where the likelihood is tractable, ArrayDPS must approximate the likelihood by formulating a separate optimization problem. The solution to the optimization approximates room acoustics and the relative transfer functions between microphones. These approximations, along with the diffusion priors, iterate through the ArrayDPS sampling process and ultimately yield separated voice sources. We only need a simple single-speaker speech diffusion model as a prior along with the mixtures recorded at the microphones; no microphone array information is necessary. Evaluation results show that ArrayDPS outperforms all baseline unsupervised methods while being comparable to supervised methods in terms of SDR. Audio demos are provided at: https://arraydps.github.io/ArrayDPSDemo/.
Listen to Extract: Onset-Prompted Target Speaker Extraction
May 08, 2025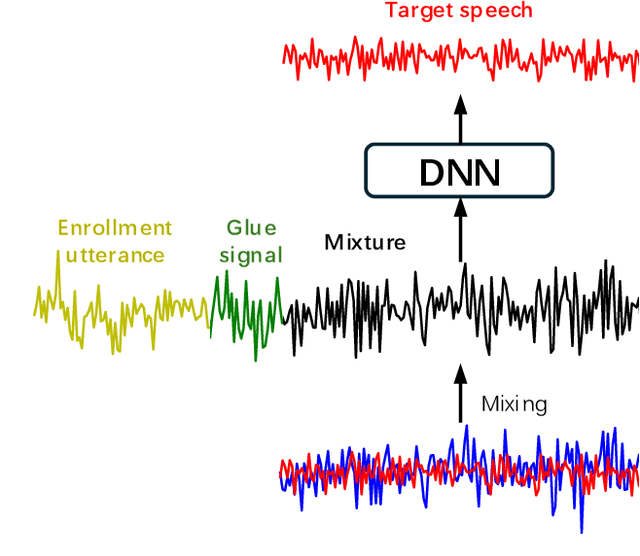
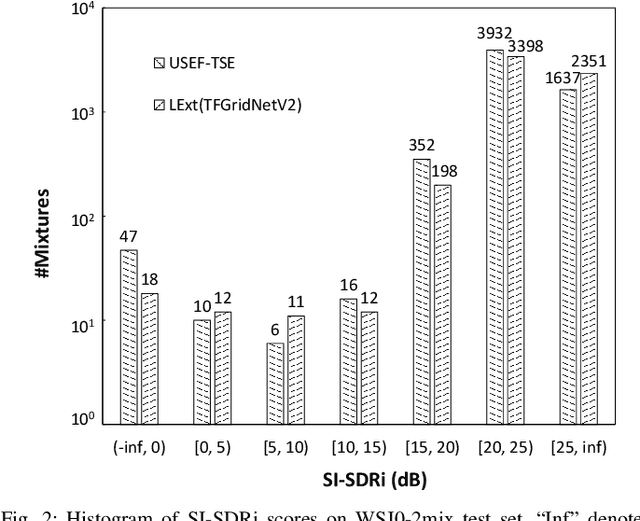
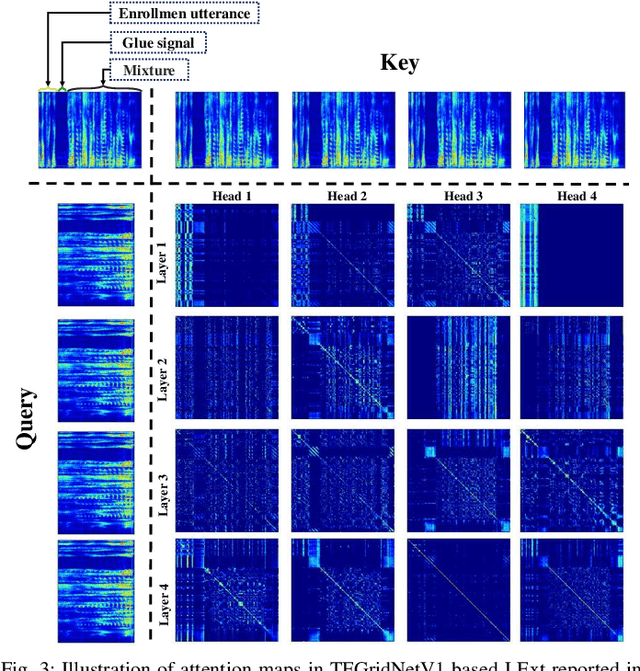
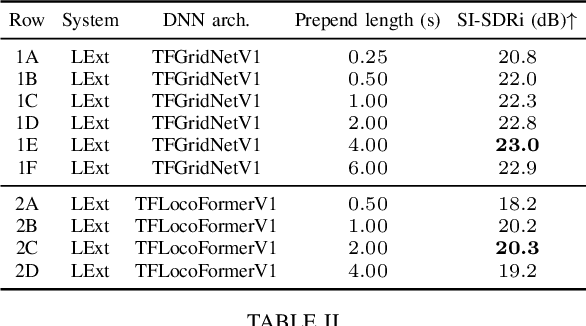
We propose $\textit{listen to extract}$ (LExt), a highly-effective while extremely-simple algorithm for monaural target speaker extraction (TSE). Given an enrollment utterance of a target speaker, LExt aims at extracting the target speaker from the speaker's mixed speech with other speakers. For each mixture, LExt concatenates an enrollment utterance of the target speaker to the mixture signal at the waveform level, and trains deep neural networks (DNN) to extract the target speech based on the concatenated mixture signal. The rationale is that, this way, an artificial speech onset is created for the target speaker and it could prompt the DNN (a) which speaker is the target to extract; and (b) spectral-temporal patterns of the target speaker that could help extraction. This simple approach produces strong TSE performance on multiple public TSE datasets including WSJ0-2mix, WHAM! and WHAMR!.
30+ Years of Source Separation Research: Achievements and Future Challenges
Jan 21, 2025Source separation (SS) of acoustic signals is a research field that emerged in the mid-1990s and has flourished ever since. On the occasion of ICASSP's 50th anniversary, we review the major contributions and advancements in the past three decades in the speech, audio, and music SS research field. We will cover both single- and multi-channel SS approaches. We will also look back on key efforts to foster a culture of scientific evaluation in the research field, including challenges, performance metrics, and datasets. We will conclude by discussing current trends and future research directions.
ctPuLSE: Close-Talk, and Pseudo-Label Based Far-Field, Speech Enhancement
Jul 28, 2024The current dominant approach for neural speech enhancement is via purely-supervised deep learning on simulated pairs of far-field noisy-reverberant speech (i.e., mixtures) and clean speech. The trained models, however, often exhibit limited generalizability to real-recorded mixtures. To deal with this, this paper investigates training enhancement models directly on real mixtures. However, a major difficulty challenging this approach is that, since the clean speech of real mixtures is unavailable, there lacks a good supervision for real mixtures. In this context, assuming that a training set consisting of real-recorded pairs of close-talk and far-field mixtures is available, we propose to address this difficulty via close-talk speech enhancement, where an enhancement model is first trained on simulated mixtures to enhance real-recorded close-talk mixtures and the estimated close-talk speech can then be utilized as a supervision (i.e., pseudo-label) for training far-field speech enhancement models directly on the paired real-recorded far-field mixtures. We name the proposed system $\textit{ctPuLSE}$. Evaluation results on the CHiME-4 dataset show that ctPuLSE can derive high-quality pseudo-labels and yield far-field speech enhancement models with strong generalizability to real data.
Evolutionary Prompt Design for LLM-Based Post-ASR Error Correction
Jul 23, 2024



Building upon the strength of modern large language models (LLMs), generative error correction (GEC) has emerged as a promising paradigm that can elevate the performance of modern automatic speech recognition (ASR) systems. One representative approach is to leverage in-context learning to prompt LLMs so that a better hypothesis can be generated by the LLMs based on a carefully-designed prompt and an $N$-best list of hypotheses produced by ASR systems. However, it is yet unknown whether the existing prompts are the most effective ones for the task of post-ASR error correction. In this context, this paper first explores alternative prompts to identify an initial set of effective prompts, and then proposes to employ an evolutionary prompt optimization algorithm to refine the initial prompts. Evaluations results on the CHiME-4 subset of the Task $1$ of the SLT $2024$ GenSEC challenge show the effectiveness and potential of the proposed algorithms.
Cross-Talk Reduction
May 30, 2024



While far-field multi-talker mixtures are recorded, each speaker can wear a close-talk microphone so that close-talk mixtures can be recorded at the same time. Although each close-talk mixture has a high signal-to-noise ratio (SNR) of the wearer, it has a very limited range of applications, as it also contains significant cross-talk speech by other speakers and is not clean enough. In this context, we propose a novel task named cross-talk reduction (CTR) which aims at reducing cross-talk speech, and a novel solution named CTRnet which is based on unsupervised or weakly-supervised neural speech separation. In unsupervised CTRnet, close-talk and far-field mixtures are stacked as input for a DNN to estimate the close-talk speech of each speaker. It is trained in an unsupervised, discriminative way such that the DNN estimate for each speaker can be linearly filtered to cancel out the speaker's cross-talk speech captured at other microphones. In weakly-supervised CTRnet, we assume the availability of each speaker's activity timestamps during training, and leverage them to improve the training of unsupervised CTRnet. Evaluation results on a simulated two-speaker CTR task and on a real-recorded conversational speech separation and recognition task show the effectiveness and potential of CTRnet.