 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Re-Search for The Truth: Multi-round Retrieval-augmented Large Language Models are Strong Fake News Detectors
Mar 14, 2024

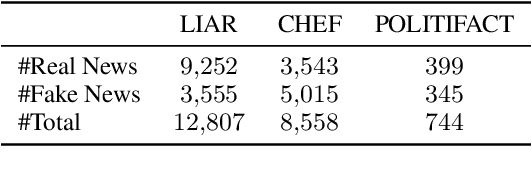
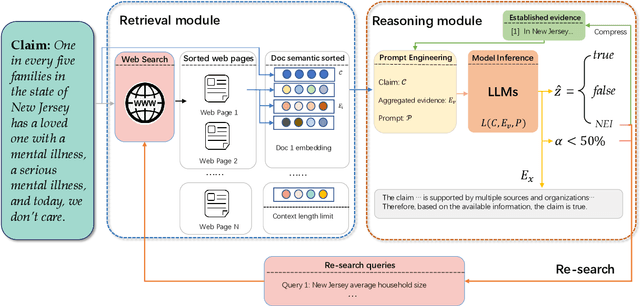
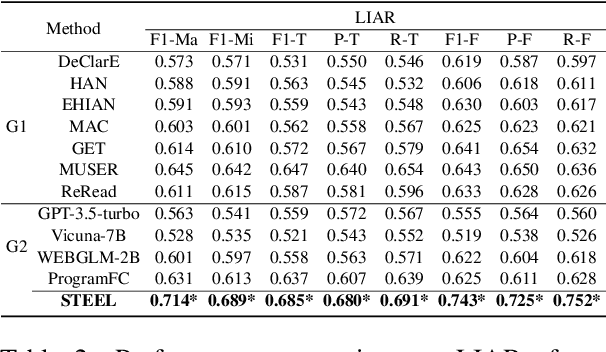
The proliferation of fake news has had far-reaching implications on politics, the economy, and society at large. While Fake news detection methods have been employed to mitigate this issue, they primarily depend on two essential elements: the quality and relevance of the evidence, and the effectiveness of the verdict prediction mechanism. Traditional methods, which often source information from static repositories like Wikipedia, are limited by outdated or incomplete data, particularly for emerging or rare claims. Large Language Models (LLMs), known for their remarkable reasoning and generative capabilities, introduce a new frontier for fake news detection. However, like traditional methods, LLM-based solutions also grapple with the limitations of stale and long-tail knowledge. Additionally, retrieval-enhanced LLMs frequently struggle with issues such as low-quality evidence retrieval and context length constraints. To address these challenges, we introduce a novel, retrieval-augmented LLMs framework--the first of its kind to automatically and strategically extract key evidence from web sources for claim verification. Employing a multi-round retrieval strategy, our framework ensures the acquisition of sufficient, relevant evidence, thereby enhancing performance. Comprehensive experiments across three real-world datasets validate the framework's superiority over existing methods. Importantly, our model not only delivers accurate verdicts but also offers human-readable explanations to improve result interpretability.
A Survey on Federated Learning in Intelligent Transportation Systems
Mar 14, 2024
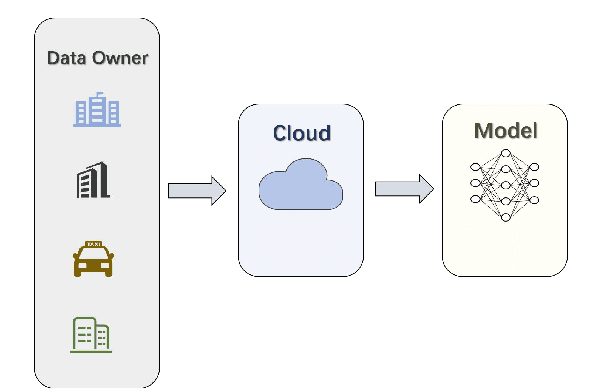
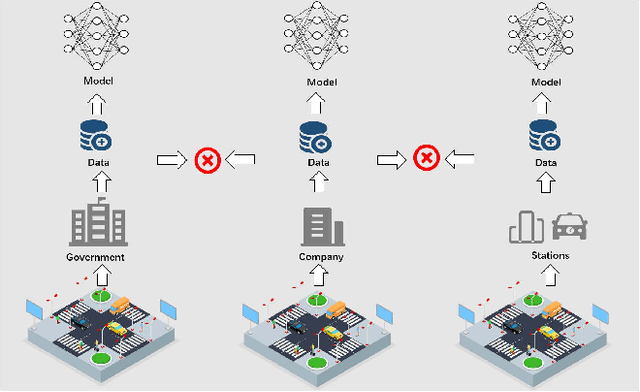
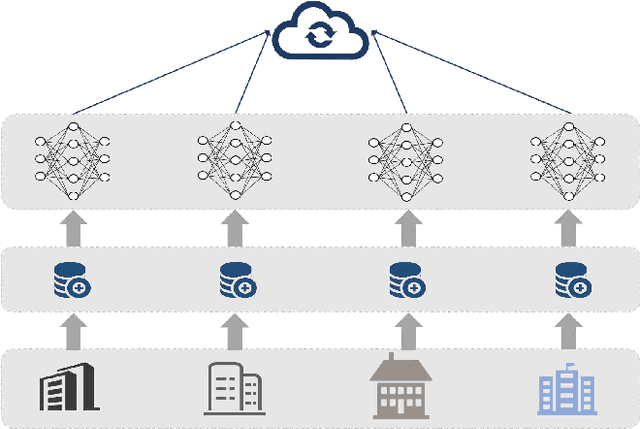
The development of Intelligent Transportation System (ITS) has brought about comprehensive urban traffic information that not only provides convenience to urban residents in their daily lives but also enhances the efficiency of urban road usage, leading to a more harmonious and sustainable urban life. Typical scenarios in ITS mainly include traffic flow prediction, traffic target recognition, and vehicular edge computing. However, most current ITS applications rely on a centralized training approach where users upload source data to a cloud server with high computing power for management and centralized training. This approach has limitations such as poor real-time performance, data silos, and difficulty in guaranteeing data privacy. To address these limitations, federated learning (FL) has been proposed as a promising solution. In this paper, we present a comprehensive review of the application of FL in ITS, with a particular focus on three key scenarios: traffic flow prediction, traffic target recognition, and vehicular edge computing. For each scenario, we provide an in-depth analysis of its key characteristics, current challenges, and specific manners in which FL is leveraged. Moreover, we discuss the benefits that FL can offer as a potential solution to the limitations of the centralized training approach currently used in ITS applications.
ADEdgeDrop: Adversarial Edge Dropping for Robust Graph Neural Networks
Mar 14, 2024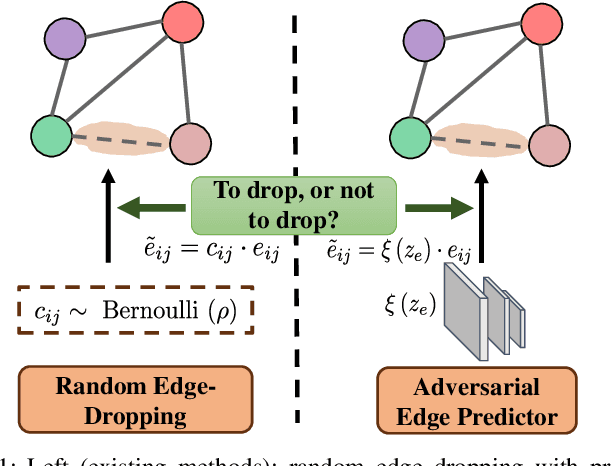
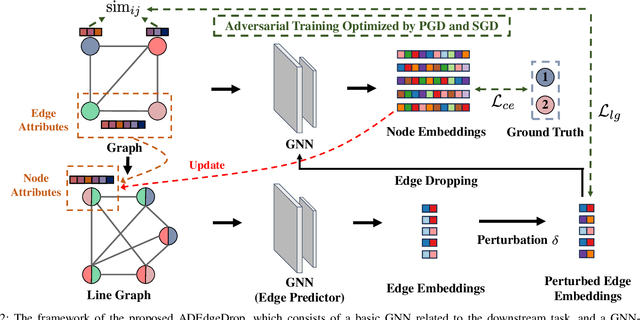
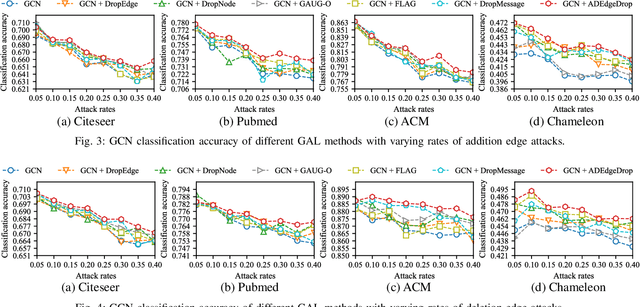
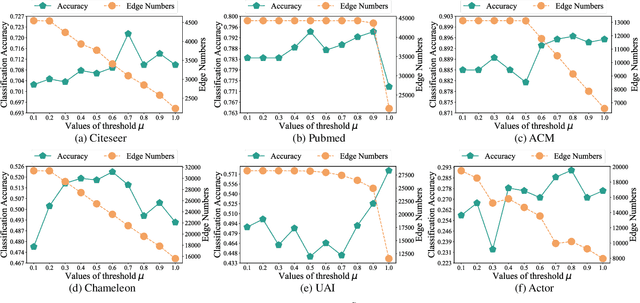
Although Graph Neural Networks (GNNs) have exhibited the powerful ability to gather graph-structured information from neighborhood nodes via various message-passing mechanisms, the performance of GNNs is limited by poor generalization and fragile robustness caused by noisy and redundant graph data. As a prominent solution, Graph Augmentation Learning (GAL) has recently received increasing attention. Among prior GAL approaches, edge-dropping methods that randomly remove edges from a graph during training are effective techniques to improve the robustness of GNNs. However, randomly dropping edges often results in bypassing critical edges, consequently weakening the effectiveness of message passing. In this paper, we propose a novel adversarial edge-dropping method (ADEdgeDrop) that leverages an adversarial edge predictor guiding the removal of edges, which can be flexibly incorporated into diverse GNN backbones. Employing an adversarial training framework, the edge predictor utilizes the line graph transformed from the original graph to estimate the edges to be dropped, which improves the interpretability of the edge-dropping method. The proposed ADEdgeDrop is optimized alternately by stochastic gradient descent and projected gradient descent. Comprehensive experiments on six graph benchmark datasets demonstrate that the proposed ADEdgeDrop outperforms state-of-the-art baselines across various GNN backbones, demonstrating improved generalization and robustness.
Towards Diverse Perspective Learning with Selection over Multiple Temporal Poolings
Mar 14, 2024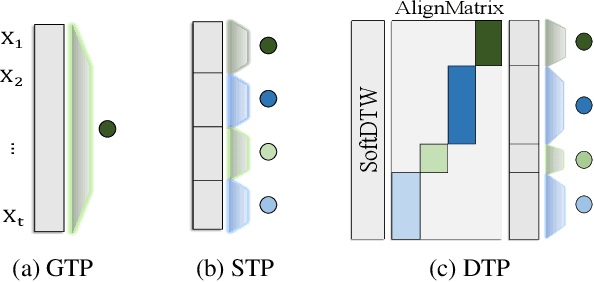
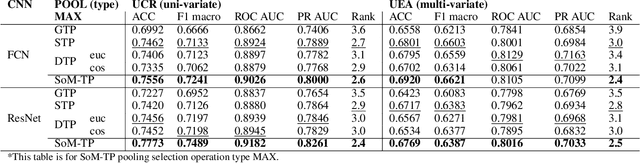
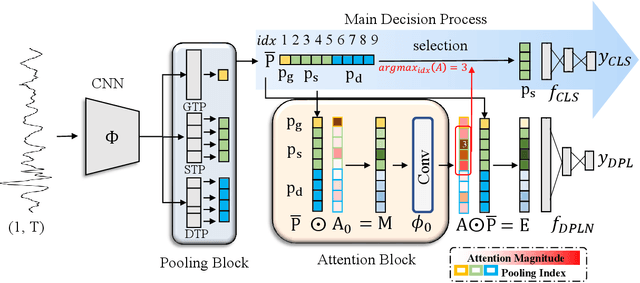
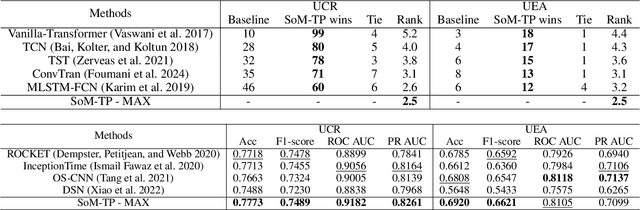
In Time Series Classification (TSC), temporal pooling methods that consider sequential information have been proposed. However, we found that each temporal pooling has a distinct mechanism, and can perform better or worse depending on time series data. We term this fixed pooling mechanism a single perspective of temporal poolings. In this paper, we propose a novel temporal pooling method with diverse perspective learning: Selection over Multiple Temporal Poolings (SoM-TP). SoM-TP dynamically selects the optimal temporal pooling among multiple methods for each data by attention. The dynamic pooling selection is motivated by the ensemble concept of Multiple Choice Learning (MCL), which selects the best among multiple outputs. The pooling selection by SoM-TP's attention enables a non-iterative pooling ensemble within a single classifier. Additionally, we define a perspective loss and Diverse Perspective Learning Network (DPLN). The loss works as a regularizer to reflect all the pooling perspectives from DPLN. Our perspective analysis using Layer-wise Relevance Propagation (LRP) reveals the limitation of a single perspective and ultimately demonstrates diverse perspective learning of SoM-TP. We also show that SoM-TP outperforms CNN models based on other temporal poolings and state-of-the-art models in TSC with extensive UCR/UEA repositories.
* 17 pages, 9 figures
VDNA-PR: Using General Dataset Representations for Robust Sequential Visual Place Recognition
Mar 14, 2024
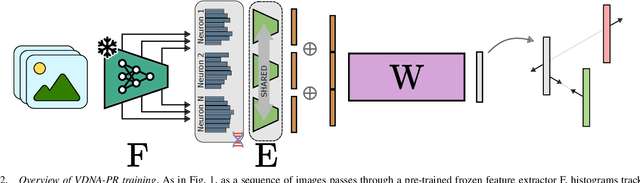

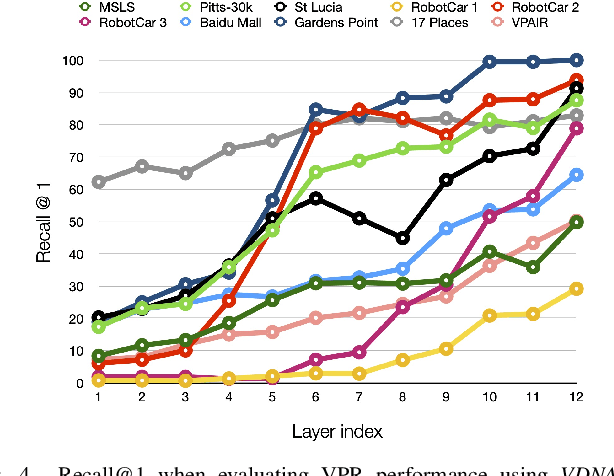
This paper adapts a general dataset representation technique to produce robust Visual Place Recognition (VPR) descriptors, crucial to enable real-world mobile robot localisation. Two parallel lines of work on VPR have shown, on one side, that general-purpose off-the-shelf feature representations can provide robustness to domain shifts, and, on the other, that fused information from sequences of images improves performance. In our recent work on measuring domain gaps between image datasets, we proposed a Visual Distribution of Neuron Activations (VDNA) representation to represent datasets of images. This representation can naturally handle image sequences and provides a general and granular feature representation derived from a general-purpose model. Moreover, our representation is based on tracking neuron activation values over the list of images to represent and is not limited to a particular neural network layer, therefore having access to high- and low-level concepts. This work shows how VDNAs can be used for VPR by learning a very lightweight and simple encoder to generate task-specific descriptors. Our experiments show that our representation can allow for better robustness than current solutions to serious domain shifts away from the training data distribution, such as to indoor environments and aerial imagery.
3D-VLA: A 3D Vision-Language-Action Generative World Model
Mar 14, 2024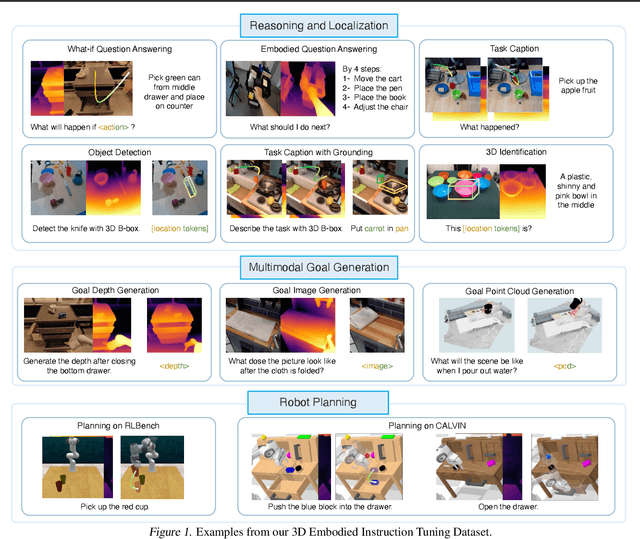
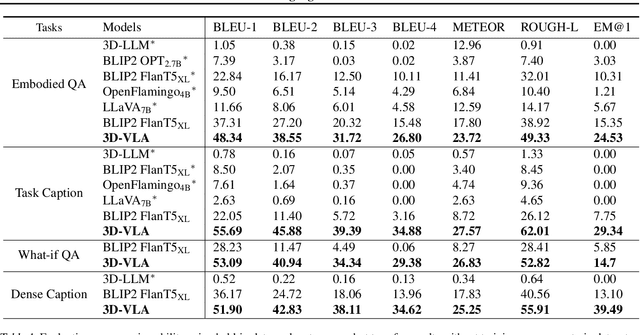
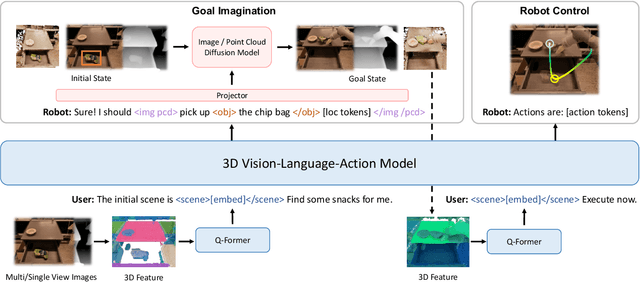
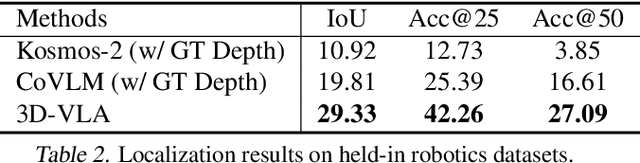
Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.
OneTracker: Unifying Visual Object Tracking with Foundation Models and Efficient Tuning
Mar 14, 2024
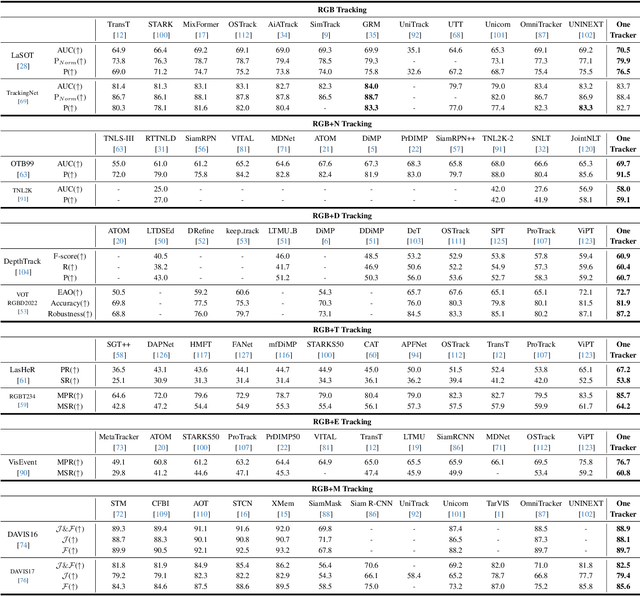
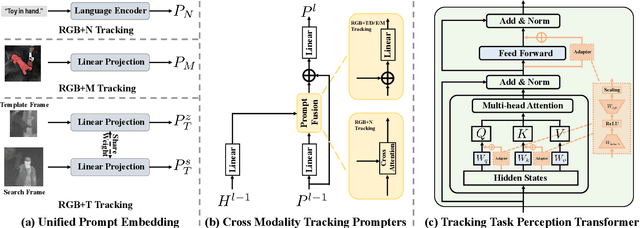

Visual object tracking aims to localize the target object of each frame based on its initial appearance in the first frame. Depending on the input modility, tracking tasks can be divided into RGB tracking and RGB+X (e.g. RGB+N, and RGB+D) tracking. Despite the different input modalities, the core aspect of tracking is the temporal matching. Based on this common ground, we present a general framework to unify various tracking tasks, termed as OneTracker. OneTracker first performs a large-scale pre-training on a RGB tracker called Foundation Tracker. This pretraining phase equips the Foundation Tracker with a stable ability to estimate the location of the target object. Then we regard other modality information as prompt and build Prompt Tracker upon Foundation Tracker. Through freezing the Foundation Tracker and only adjusting some additional trainable parameters, Prompt Tracker inhibits the strong localization ability from Foundation Tracker and achieves parameter-efficient finetuning on downstream RGB+X tracking tasks. To evaluate the effectiveness of our general framework OneTracker, which is consisted of Foundation Tracker and Prompt Tracker, we conduct extensive experiments on 6 popular tracking tasks across 11 benchmarks and our OneTracker outperforms other models and achieves state-of-the-art performance.
ChartInstruct: Instruction Tuning for Chart Comprehension and Reasoning
Mar 14, 2024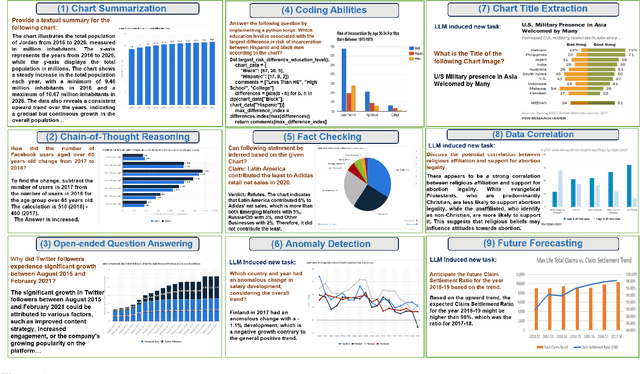
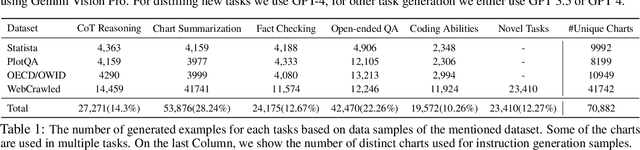

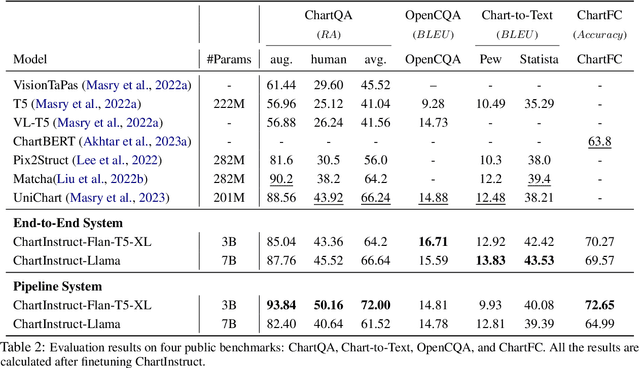
Charts provide visual representations of data and are widely used for analyzing information, addressing queries, and conveying insights to others. Various chart-related downstream tasks have emerged recently, such as question-answering and summarization. A common strategy to solve these tasks is to fine-tune various models originally trained on vision tasks language. However, such task-specific models are not capable of solving a wide range of chart-related tasks, constraining their real-world applicability. To overcome these challenges, we introduce ChartInstruct: a novel chart-specific vision-language Instruction-following dataset comprising 191K instructions generated with 71K charts. We then present two distinct systems for instruction tuning on such datasets: (1) an end-to-end model that connects a vision encoder for chart understanding with a LLM; and (2) a pipeline model that employs a two-step approach to extract chart data tables and input them into the LLM. In experiments on four downstream tasks, we first show the effectiveness of our model--achieving a new set of state-of-the-art results. Further evaluation shows that our instruction-tuning approach supports a wide array of real-world chart comprehension and reasoning scenarios, thereby expanding the scope and applicability of our models to new kinds of tasks.
Emerging Synergies Between Large Language Models and Machine Learning in Ecommerce Recommendations
Mar 12, 2024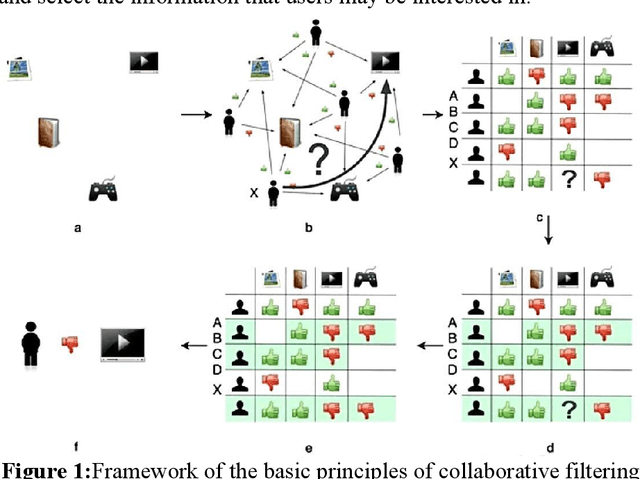

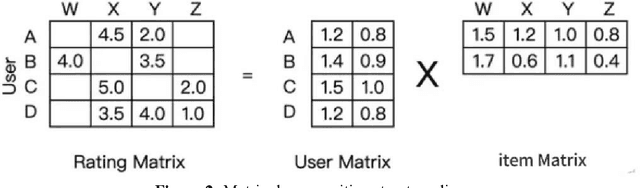
With the boom of e-commerce and web applications, recommender systems have become an important part of our daily lives, providing personalized recommendations based on the user's preferences. Although deep neural networks (DNNs) have made significant progress in improving recommendation systems by simulating the interaction between users and items and incorporating their textual information, these DNN-based approaches still have some limitations, such as the difficulty of effectively understanding users' interests and capturing textual information. It is not possible to generalize to different seen/unseen recommendation scenarios and reason about their predictions. At the same time, the emergence of large language models (LLMs), represented by ChatGPT and GPT-4, has revolutionized the fields of natural language processing (NLP) and artificial intelligence (AI) due to their superior capabilities in the basic tasks of language understanding and generation, and their impressive generalization and reasoning capabilities. As a result, recent research has sought to harness the power of LLM to improve recommendation systems. Given the rapid development of this research direction in the field of recommendation systems, there is an urgent need for a systematic review of existing LLM-driven recommendation systems for researchers and practitioners in related fields to gain insight into. More specifically, we first introduced a representative approach to learning user and item representations using LLM as a feature encoder. We then reviewed the latest advances in LLMs techniques for collaborative filtering enhanced recommendation systems from the three paradigms of pre-training, fine-tuning, and prompting. Finally, we had a comprehensive discussion on the future direction of this emerging field.
xMLP: Revolutionizing Private Inference with Exclusive Square Activation
Mar 12, 2024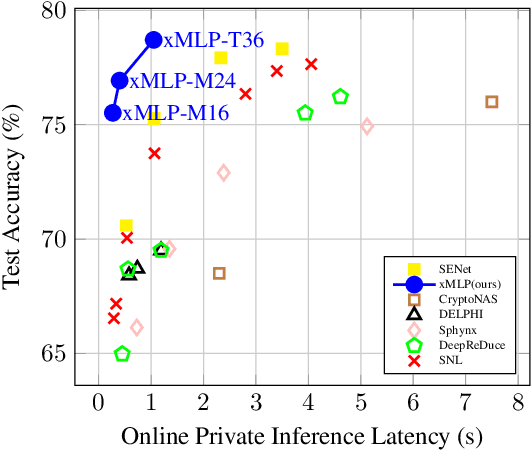
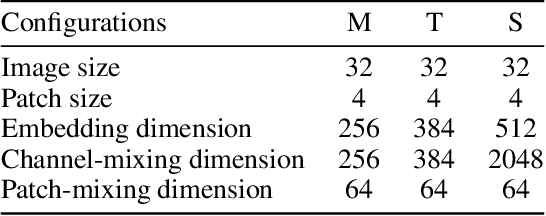
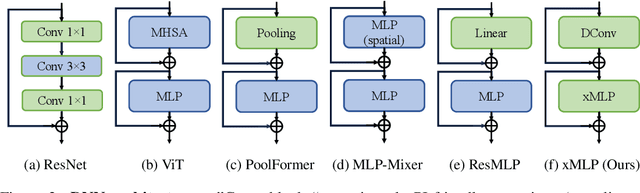
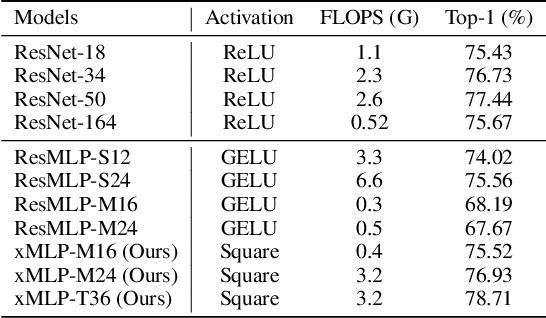
Private Inference (PI) enables deep neural networks (DNNs) to work on private data without leaking sensitive information by exploiting cryptographic primitives such as multi-party computation (MPC) and homomorphic encryption (HE). However, the use of non-linear activations such as ReLU in DNNs can lead to impractically high PI latency in existing PI systems, as ReLU requires the use of costly MPC computations, such as Garbled Circuits. Since square activations can be processed by Beaver's triples hundreds of times faster compared to ReLU, they are more friendly to PI tasks, but using them leads to a notable drop in model accuracy. This paper starts by exploring the reason for such an accuracy drop after using square activations, and concludes that this is due to an "information compounding" effect. Leveraging this insight, we propose xMLP, a novel DNN architecture that uses square activations exclusively while maintaining parity in both accuracy and efficiency with ReLU-based DNNs. Our experiments on CIFAR-100 and ImageNet show that xMLP models consistently achieve better performance than ResNet models with fewer activation layers and parameters while maintaining consistent performance with its ReLU-based variants. Remarkably, when compared to state-of-the-art PI Models, xMLP demonstrates superior performance, achieving a 0.58% increase in accuracy with 7x faster PI speed. Moreover, it delivers a significant accuracy improvement of 4.96% while maintaining the same PI latency. When offloading PI to the GPU, xMLP is up to 700x faster than the previous state-of-the-art PI model with comparable accuracy.