 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards a Neural Era in Dialogue Management for Collaboration: A Literature Survey
Jul 18, 2023
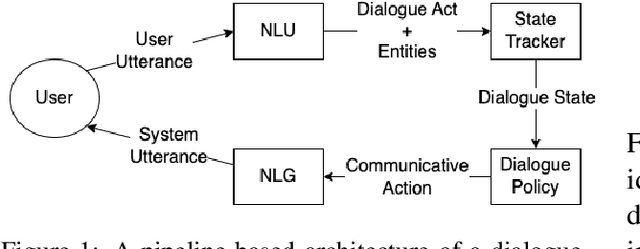
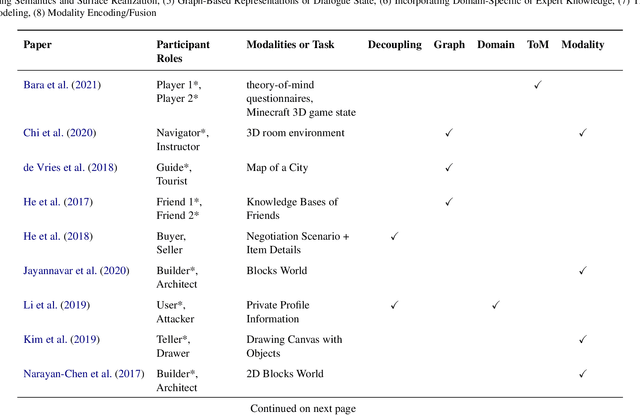
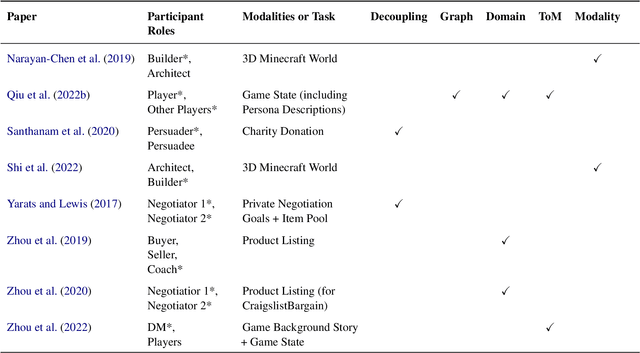
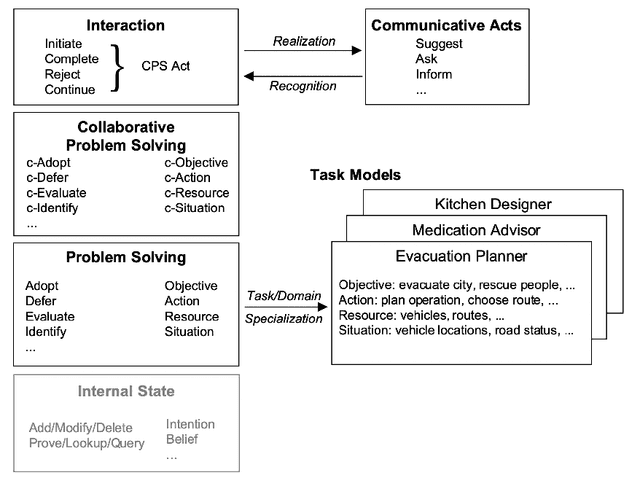
Dialogue-based human-AI collaboration can revolutionize collaborative problem-solving, creative exploration, and social support. To realize this goal, the development of automated agents proficient in skills such as negotiating, following instructions, establishing common ground, and progressing shared tasks is essential. This survey begins by reviewing the evolution of dialogue management paradigms in collaborative dialogue systems, from traditional handcrafted and information-state based methods to AI planning-inspired approaches. It then shifts focus to contemporary data-driven dialogue management techniques, which seek to transfer deep learning successes from form-filling and open-domain settings to collaborative contexts. The paper proceeds to analyze a selected set of recent works that apply neural approaches to collaborative dialogue management, spotlighting prevailing trends in the field. This survey hopes to provide foundational background for future advancements in collaborative dialogue management, particularly as the dialogue systems community continues to embrace the potential of large language models.
an integrated npl approach to sentiment analysis in satisfaction surveys
Jul 18, 2023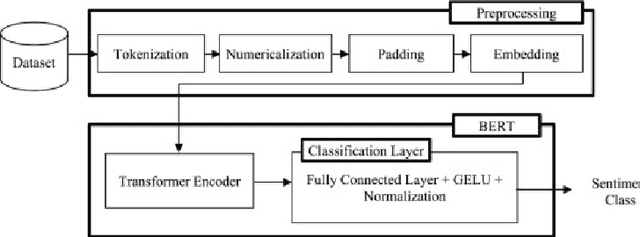
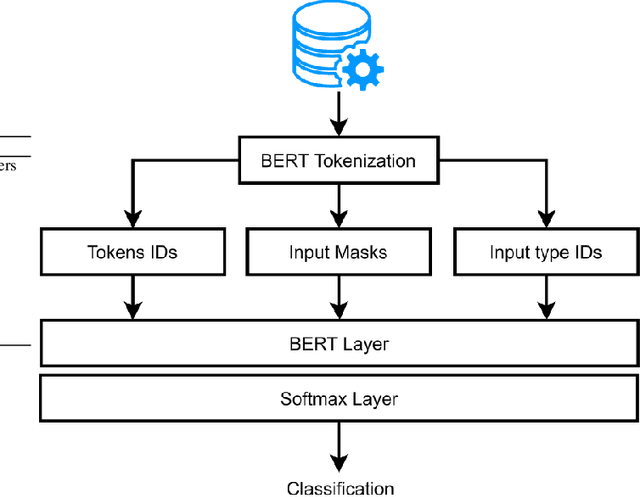
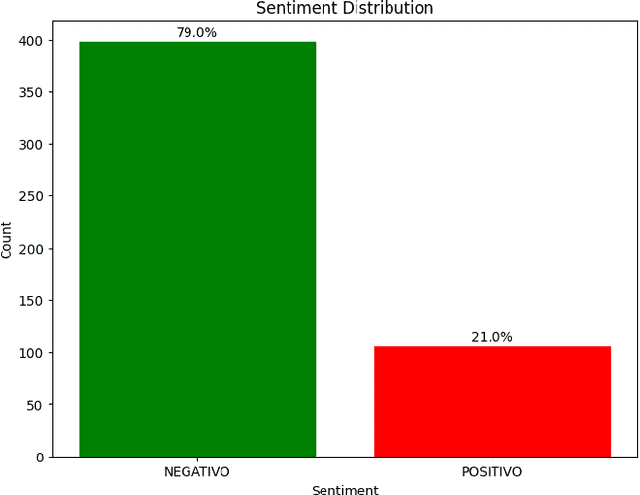

The research project aims to apply an integrated approach to natural language processing NLP to satisfaction surveys. It will focus on understanding and extracting relevant information from survey responses, analyzing feelings, and identifying recurring word patterns. NLP techniques will be used to determine emotional polarity, classify responses into positive, negative, or neutral categories, and use opinion mining to highlight participants opinions. This approach will help identify the most relevant aspects for participants and understand their opinions in relation to those specific aspects. A key component of the research project will be the analysis of word patterns in satisfaction survey responses using NPL. This analysis will provide a deeper understanding of feelings, opinions, and themes and trends present in respondents responses. The results obtained from this approach can be used to identify areas for improvement, understand respondents preferences, and make strategic decisions based on analysis to improve respondent satisfaction.
Filter Pruning based on Information Capacity and Independence
Mar 07, 2023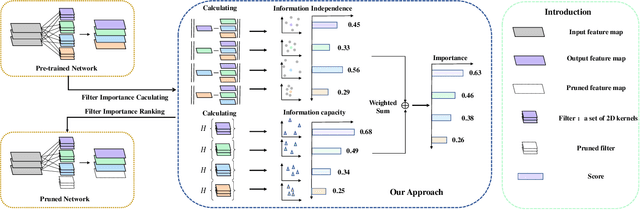
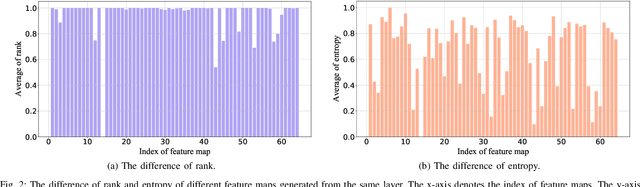
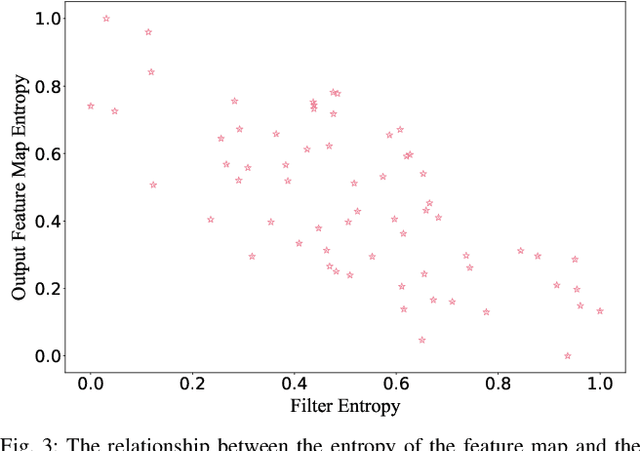
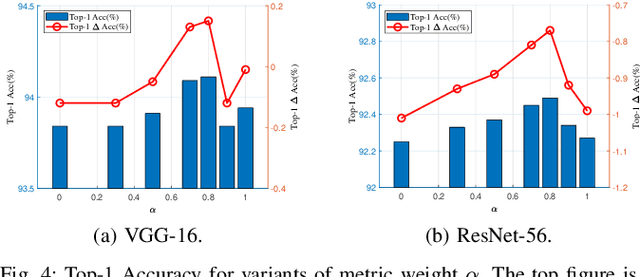
Filter pruning has been widely used in the compression and acceleration of convolutional neural networks (CNNs). However, most existing methods are still challenged by heavy compute cost and biased filter selection. Moreover, most designs for filter evaluation miss interpretability due to the lack of appropriate theoretical guidance. In this paper, we propose a novel filter pruning method which evaluates filters in a interpretable, multi-persepective and data-free manner. We introduce information capacity, a metric that represents the amount of information contained in a filter. Based on the interpretability and validity of information entropy, we propose to use that as a quantitative index of information quantity. Besides, we experimently show that the obvious correlation between the entropy of the feature map and the corresponding filter, so as to propose an interpretable, data-driven scheme to measure the information capacity of the filter. Further, we introduce information independence, another metric that represents the correlation among differrent filters. Consequently, the least impotant filters, which have less information capacity and less information independence, will be pruned. We evaluate our method on two benchmarks using multiple representative CNN architectures, including VGG-16 and ResNet. On CIFAR-10, we reduce 71.9% of floating-point operations (FLOPs) and 69.4% of parameters for ResNet-110 with 0.28% accuracy increase. On ILSVRC-2012, we reduce 76.6% of floating-point operations (FLOPs) and 68.6% of parameters for ResNet-50 with only 2.80% accuracy decrease, which outperforms the state-of-the-arts.
Multi-Granularity Prediction with Learnable Fusion for Scene Text Recognition
Jul 25, 2023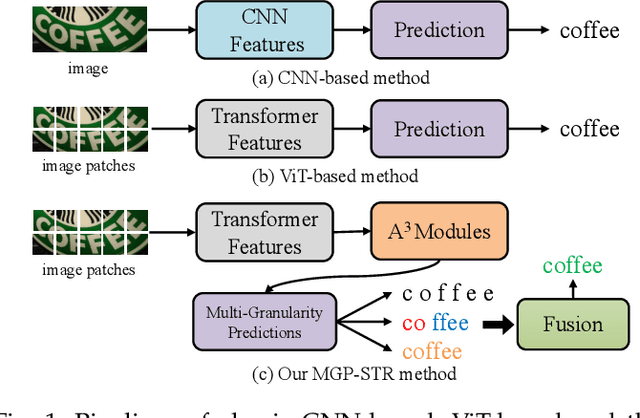
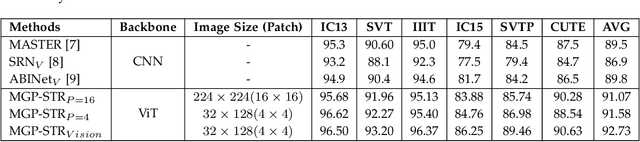
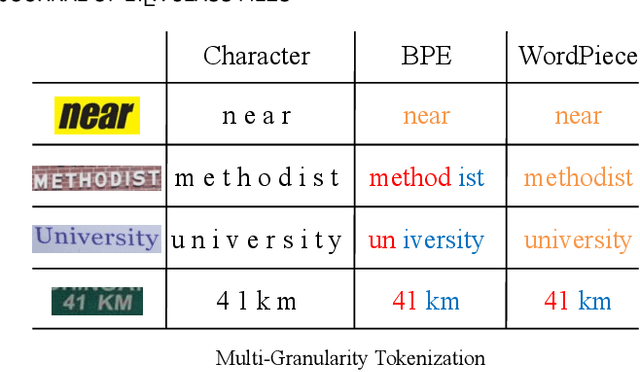
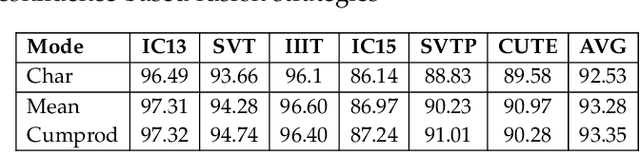
Due to the enormous technical challenges and wide range of applications, scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this tough problem, numerous innovative methods have been successively proposed, and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet functionally powerful vision STR model, which is built upon ViT and a tailored Adaptive Addressing and Aggregation (A$^3$) module. It already outperforms most previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, \ie, subword representations (BPE and WordPiece) widely used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. To produce the final recognition results, two strategies for effectively fusing the multi-granularity predictions are devised. The resultant algorithm (termed MGP-STR) is able to push the performance envelope of STR to an even higher level. Specifically, MGP-STR achieves an average recognition accuracy of $94\%$ on standard benchmarks for scene text recognition. Moreover, it also achieves state-of-the-art results on widely-used handwritten benchmarks as well as more challenging scene text datasets, demonstrating the generality of the proposed MGP-STR algorithm. The source code and models will be available at: \url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR}.
One for Multiple: Physics-informed Synthetic Data Boosts Generalizable Deep Learning for Fast MRI Reconstruction
Jul 25, 2023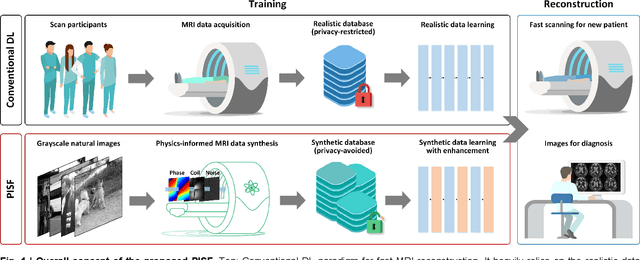

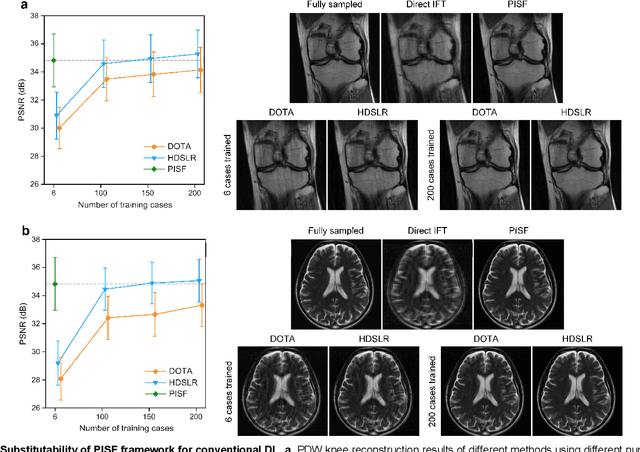
Magnetic resonance imaging (MRI) is a principal radiological modality that provides radiation-free, abundant, and diverse information about the whole human body for medical diagnosis, but suffers from prolonged scan time. The scan time can be significantly reduced through k-space undersampling but the introduced artifacts need to be removed in image reconstruction. Although deep learning (DL) has emerged as a powerful tool for image reconstruction in fast MRI, its potential in multiple imaging scenarios remains largely untapped. This is because not only collecting large-scale and diverse realistic training data is generally costly and privacy-restricted, but also existing DL methods are hard to handle the practically inevitable mismatch between training and target data. Here, we present a Physics-Informed Synthetic data learning framework for Fast MRI, called PISF, which is the first to enable generalizable DL for multi-scenario MRI reconstruction using solely one trained model. For a 2D image, the reconstruction is separated into many 1D basic problems and starts with the 1D data synthesis, to facilitate generalization. We demonstrate that training DL models on synthetic data, integrated with enhanced learning techniques, can achieve comparable or even better in vivo MRI reconstruction compared to models trained on a matched realistic dataset, reducing the demand for real-world MRI data by up to 96%. Moreover, our PISF shows impressive generalizability in multi-vendor multi-center imaging. Its excellent adaptability to patients has been verified through 10 experienced doctors' evaluations. PISF provides a feasible and cost-effective way to markedly boost the widespread usage of DL in various fast MRI applications, while freeing from the intractable ethical and practical considerations of in vivo human data acquisitions.
Distributed Graph Embedding with Information-Oriented Random Walks
Mar 28, 2023
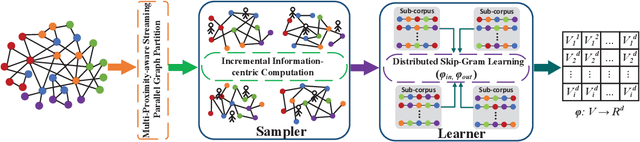
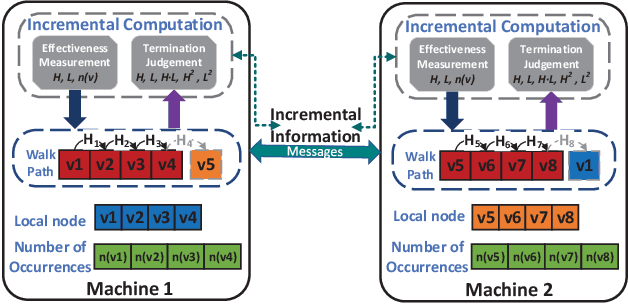
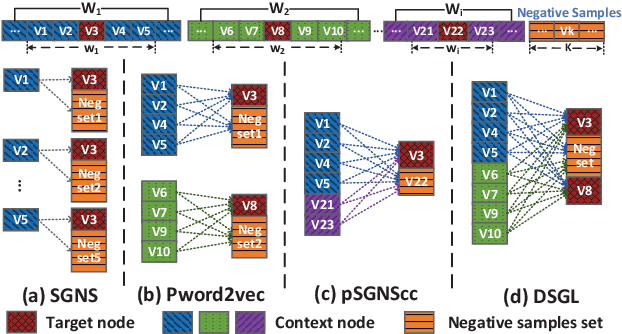
Graph embedding maps graph nodes to low-dimensional vectors, and is widely adopted in machine learning tasks. The increasing availability of billion-edge graphs underscores the importance of learning efficient and effective embeddings on large graphs, such as link prediction on Twitter with over one billion edges. Most existing graph embedding methods fall short of reaching high data scalability. In this paper, we present a general-purpose, distributed, information-centric random walk-based graph embedding framework, DistGER, which can scale to embed billion-edge graphs. DistGER incrementally computes information-centric random walks. It further leverages a multi-proximity-aware, streaming, parallel graph partitioning strategy, simultaneously achieving high local partition quality and excellent workload balancing across machines. DistGER also improves the distributed Skip-Gram learning model to generate node embeddings by optimizing the access locality, CPU throughput, and synchronization efficiency. Experiments on real-world graphs demonstrate that compared to state-of-the-art distributed graph embedding frameworks, including KnightKing, DistDGL, and Pytorch-BigGraph, DistGER exhibits 2.33x-129x acceleration, 45% reduction in cross-machines communication, and > 10% effectiveness improvement in downstream tasks.
Recommender Systems for Online and Mobile Social Networks: A survey
Jun 28, 2023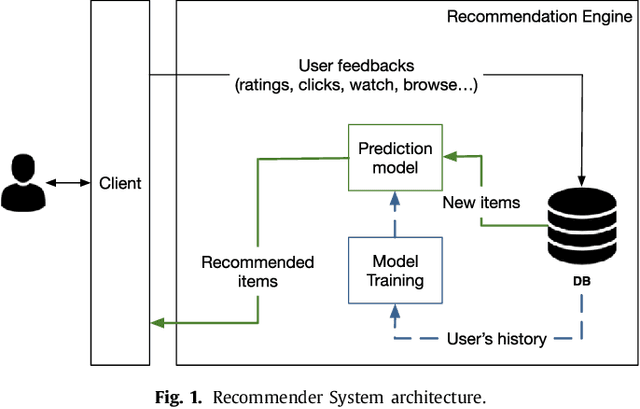
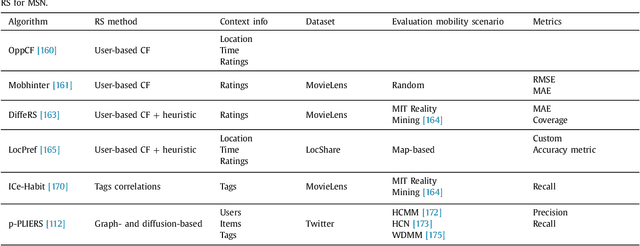

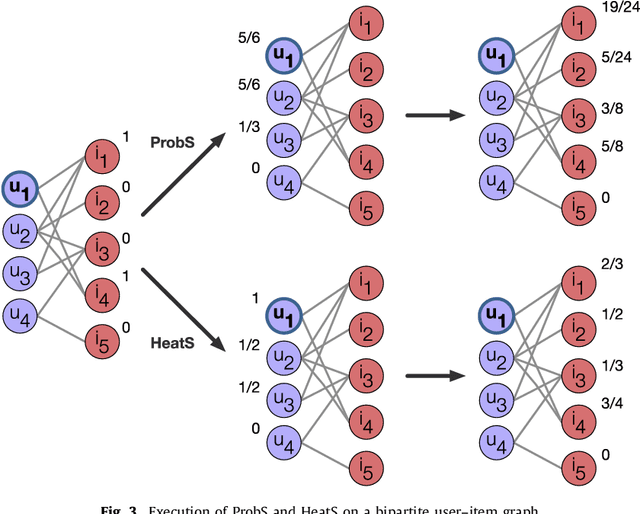
Recommender Systems (RS) currently represent a fundamental tool in online services, especially with the advent of Online Social Networks (OSN). In this case, users generate huge amounts of contents and they can be quickly overloaded by useless information. At the same time, social media represent an important source of information to characterize contents and users' interests. RS can exploit this information to further personalize suggestions and improve the recommendation process. In this paper we present a survey of Recommender Systems designed and implemented for Online and Mobile Social Networks, highlighting how the use of social context information improves the recommendation task, and how standard algorithms must be enhanced and optimized to run in a fully distributed environment, as opportunistic networks. We describe advantages and drawbacks of these systems in terms of algorithms, target domains, evaluation metrics and performance evaluations. Eventually, we present some open research challenges in this area.
Improving Translation Invariance in Convolutional Neural Networks with Peripheral Prediction Padding
Jul 15, 2023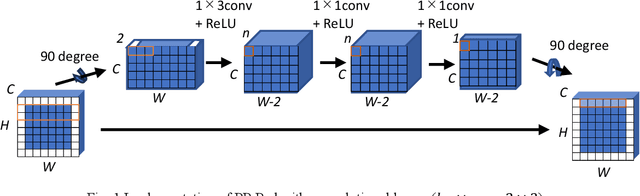
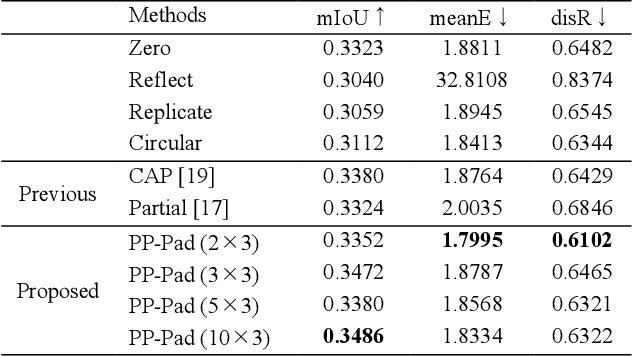
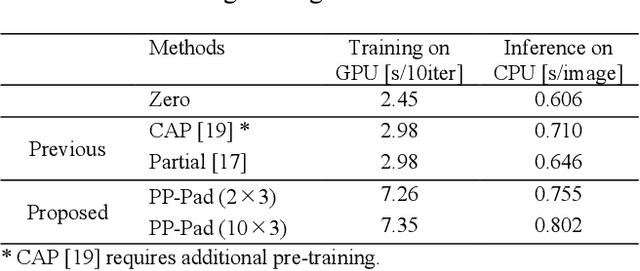

Zero padding is often used in convolutional neural networks to prevent the feature map size from decreasing with each layer. However, recent studies have shown that zero padding promotes encoding of absolute positional information, which may adversely affect the performance of some tasks. In this work, a novel padding method called Peripheral Prediction Padding (PP-Pad) method is proposed, which enables end-to-end training of padding values suitable for each task instead of zero padding. Moreover, novel metrics to quantitatively evaluate the translation invariance of the model are presented. By evaluating with these metrics, it was confirmed that the proposed method achieved higher accuracy and translation invariance than the previous methods in a semantic segmentation task.
DFA3D: 3D Deformable Attention For 2D-to-3D Feature Lifting
Jul 24, 2023In this paper, we propose a new operator, called 3D DeFormable Attention (DFA3D), for 2D-to-3D feature lifting, which transforms multi-view 2D image features into a unified 3D space for 3D object detection. Existing feature lifting approaches, such as Lift-Splat-based and 2D attention-based, either use estimated depth to get pseudo LiDAR features and then splat them to a 3D space, which is a one-pass operation without feature refinement, or ignore depth and lift features by 2D attention mechanisms, which achieve finer semantics while suffering from a depth ambiguity problem. In contrast, our DFA3D-based method first leverages the estimated depth to expand each view's 2D feature map to 3D and then utilizes DFA3D to aggregate features from the expanded 3D feature maps. With the help of DFA3D, the depth ambiguity problem can be effectively alleviated from the root, and the lifted features can be progressively refined layer by layer, thanks to the Transformer-like architecture. In addition, we propose a mathematically equivalent implementation of DFA3D which can significantly improve its memory efficiency and computational speed. We integrate DFA3D into several methods that use 2D attention-based feature lifting with only a few modifications in code and evaluate on the nuScenes dataset. The experiment results show a consistent improvement of +1.41\% mAP on average, and up to +15.1\% mAP improvement when high-quality depth information is available, demonstrating the superiority, applicability, and huge potential of DFA3D. The code is available at https://github.com/IDEA-Research/3D-deformable-attention.git.
3D-LLM: Injecting the 3D World into Large Language Models
Jul 24, 2023Large language models (LLMs) and Vision-Language Models (VLMs) have been proven to excel at multiple tasks, such as commonsense reasoning. Powerful as these models can be, they are not grounded in the 3D physical world, which involves richer concepts such as spatial relationships, affordances, physics, layout, and so on. In this work, we propose to inject the 3D world into large language models and introduce a whole new family of 3D-LLMs. Specifically, 3D-LLMs can take 3D point clouds and their features as input and perform a diverse set of 3D-related tasks, including captioning, dense captioning, 3D question answering, task decomposition, 3D grounding, 3D-assisted dialog, navigation, and so on. Using three types of prompting mechanisms that we design, we are able to collect over 300k 3D-language data covering these tasks. To efficiently train 3D-LLMs, we first utilize a 3D feature extractor that obtains 3D features from rendered multi- view images. Then, we use 2D VLMs as our backbones to train our 3D-LLMs. By introducing a 3D localization mechanism, 3D-LLMs can better capture 3D spatial information. Experiments on ScanQA show that our model outperforms state-of-the-art baselines by a large margin (e.g., the BLEU-1 score surpasses state-of-the-art score by 9%). Furthermore, experiments on our held-in datasets for 3D captioning, task composition, and 3D-assisted dialogue show that our model outperforms 2D VLMs. Qualitative examples also show that our model could perform more tasks beyond the scope of existing LLMs and VLMs. Project Page: : https://vis-www.cs.umass.edu/3dllm/.