 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan-R1: Safe and Feasible Trajectory Planning as Language Modeling
May 23, 2025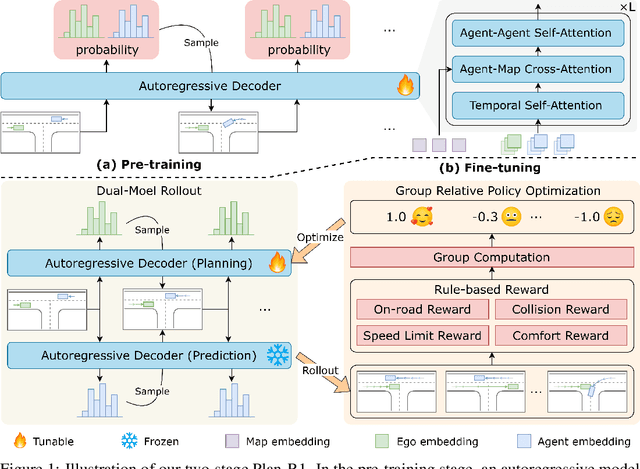
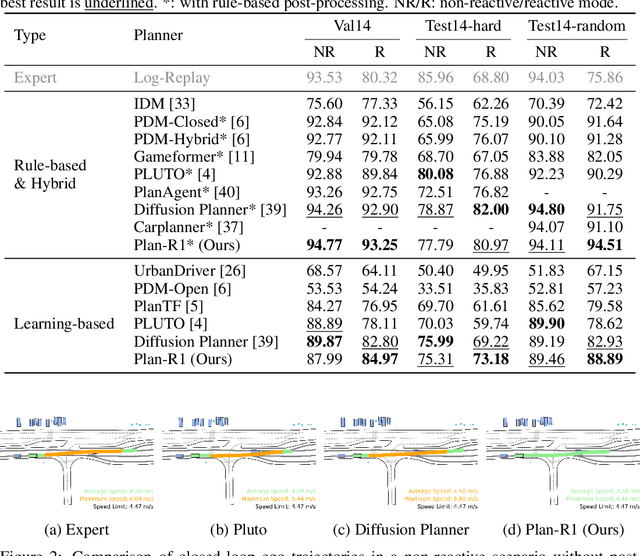
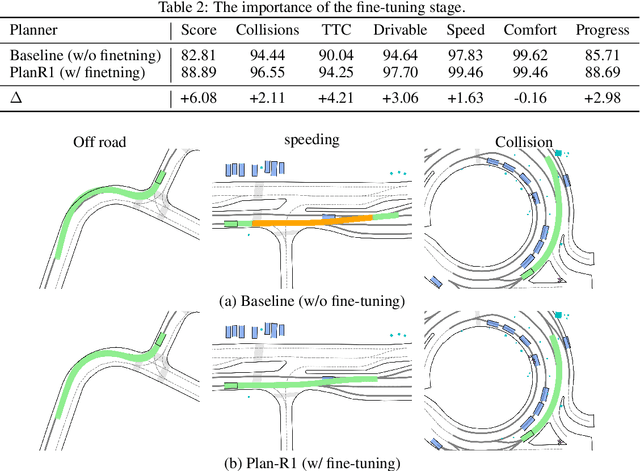
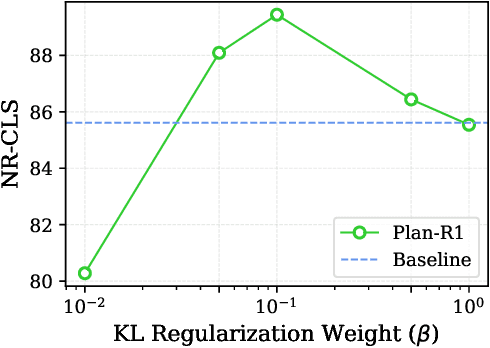
Safe and feasible trajectory planning is essential for real-world autonomous driving systems. However, existing learning-based planning methods often rely on expert demonstrations, which not only lack explicit safety awareness but also risk inheriting unsafe behaviors such as speeding from suboptimal human driving data. Inspired by the success of large language models, we propose Plan-R1, a novel two-stage trajectory planning framework that formulates trajectory planning as a sequential prediction task, guided by explicit planning principles such as safety, comfort, and traffic rule compliance. In the first stage, we train an autoregressive trajectory predictor via next motion token prediction on expert data. In the second stage, we design rule-based rewards (e.g., collision avoidance, speed limits) and fine-tune the model using Group Relative Policy Optimization (GRPO), a reinforcement learning strategy, to align its predictions with these planning principles. Experiments on the nuPlan benchmark demonstrate that our Plan-R1 significantly improves planning safety and feasibility, achieving state-of-the-art performance.
HPNet: Dynamic Trajectory Forecasting with Historical Prediction Attention
Apr 11, 2024



Predicting the trajectories of road agents is essential for autonomous driving systems. The recent mainstream methods follow a static paradigm, which predicts the future trajectory by using a fixed duration of historical frames. These methods make the predictions independently even at adjacent time steps, which leads to potential instability and temporal inconsistency. As successive time steps have largely overlapping historical frames, their forecasting should have intrinsic correlation, such as overlapping predicted trajectories should be consistent, or be different but share the same motion goal depending on the road situation. Motivated by this, in this work, we introduce HPNet, a novel dynamic trajectory forecasting method. Aiming for stable and accurate trajectory forecasting, our method leverages not only historical frames including maps and agent states, but also historical predictions. Specifically, we newly design a Historical Prediction Attention module to automatically encode the dynamic relationship between successive predictions. Besides, it also extends the attention range beyond the currently visible window benefitting from the use of historical predictions. The proposed Historical Prediction Attention together with the Agent Attention and Mode Attention is further formulated as the Triple Factorized Attention module, serving as the core design of HPNet.Experiments on the Argoverse and INTERACTION datasets show that HPNet achieves state-of-the-art performance, and generates accurate and stable future trajectories. Our code are available at https://github.com/XiaolongTang23/HPNet.
Filter Pruning based on Information Capacity and Independence
Mar 07, 2023



Filter pruning has been widely used in the compression and acceleration of convolutional neural networks (CNNs). However, most existing methods are still challenged by heavy compute cost and biased filter selection. Moreover, most designs for filter evaluation miss interpretability due to the lack of appropriate theoretical guidance. In this paper, we propose a novel filter pruning method which evaluates filters in a interpretable, multi-persepective and data-free manner. We introduce information capacity, a metric that represents the amount of information contained in a filter. Based on the interpretability and validity of information entropy, we propose to use that as a quantitative index of information quantity. Besides, we experimently show that the obvious correlation between the entropy of the feature map and the corresponding filter, so as to propose an interpretable, data-driven scheme to measure the information capacity of the filter. Further, we introduce information independence, another metric that represents the correlation among differrent filters. Consequently, the least impotant filters, which have less information capacity and less information independence, will be pruned. We evaluate our method on two benchmarks using multiple representative CNN architectures, including VGG-16 and ResNet. On CIFAR-10, we reduce 71.9% of floating-point operations (FLOPs) and 69.4% of parameters for ResNet-110 with 0.28% accuracy increase. On ILSVRC-2012, we reduce 76.6% of floating-point operations (FLOPs) and 68.6% of parameters for ResNet-50 with only 2.80% accuracy decrease, which outperforms the state-of-the-arts.